


自动语音识别 (ASR) 是呼叫中心、智能设备工程等领域众多商业应用的基石。ASR 模型(也称为语音转文本 (STT))的核心是智能识别人类语音并将其转换为书面格式。
现代ASR 引擎综合运用了多项突破性技术,包括自然语言处理 (NLP)、AI、ML 和 LLM。虽然 ASR 依赖于所有这些技术,但它在根本上与每一项技术都有很大不同。
以 NLP 为例,它经常与 ASR 混淆。该技术旨在理解自然语言模式并利用这些模式从头开始创建新内容,而 ASR 则专注于转录口语。因此,了解语音识别的工作原理对于为您的客户和团队打造更好的产品和体验至关重要。
在本文中,我们将探索 ASR 模型的内部工作原理,并将传统方法与当今最先进的序列到序列模型进行比较。如果您是开发人员、AI 工程师、CTO 或 CPO,您将发现有关 Whisper seq2seq 等 ASR 模型的大量见解,以及它们对于商业环境中的转录、字幕和内容创建的重要性。
语音识别如何工作?
在将语音识别技术融入您的业务和客户工作流程时,了解它们的工作原理会有所帮助。有了这些见解,您将能够更好地选择最符合您特定要求的 ASR 模型。如果您是语音识别新手,请在深入了解之前先查看我们的语音转文本 AI 入门指南。
传统的语音识别方法
让我们来看看语音识别的历史工作原理。传统的 ASR 系统最早于 20 世纪 70 年代推出,其工作原理是将模拟音频信号转换为数字位,并用解码器对其进行处理,根据数据序列和上下文创建包含单词的句子。在过去的四十年里,它们一直是主流,直到端到端 ASR 模型的推出。
传统语音识别系统中的解码器结合多个 ML 模型分析输入数据。
- 声学模型 (AM):解码器需要隐马尔可夫模型 (HMM) 和高斯混合模型 (GMM) 等声学模型,这些模型能够理解自然语音模式以预测准确的语音。
- 语言模型:仅仅估计声音(表型)是不够的。您需要一个能够根据语言的统计分析预测正确单词序列的语言模型。
- 词典模型:词典模型决定语言中的语音变化。这有助于区分口音和发音相似的短语。这些模型协同工作以创建所需的输出(书面文本)。词典模型的一个例子是有限状态转换器 (FST),其发音词典将单词“SPEECH”映射到“SP IY CH”。所有自然语言单词在 FST 中都表示为子词单元。
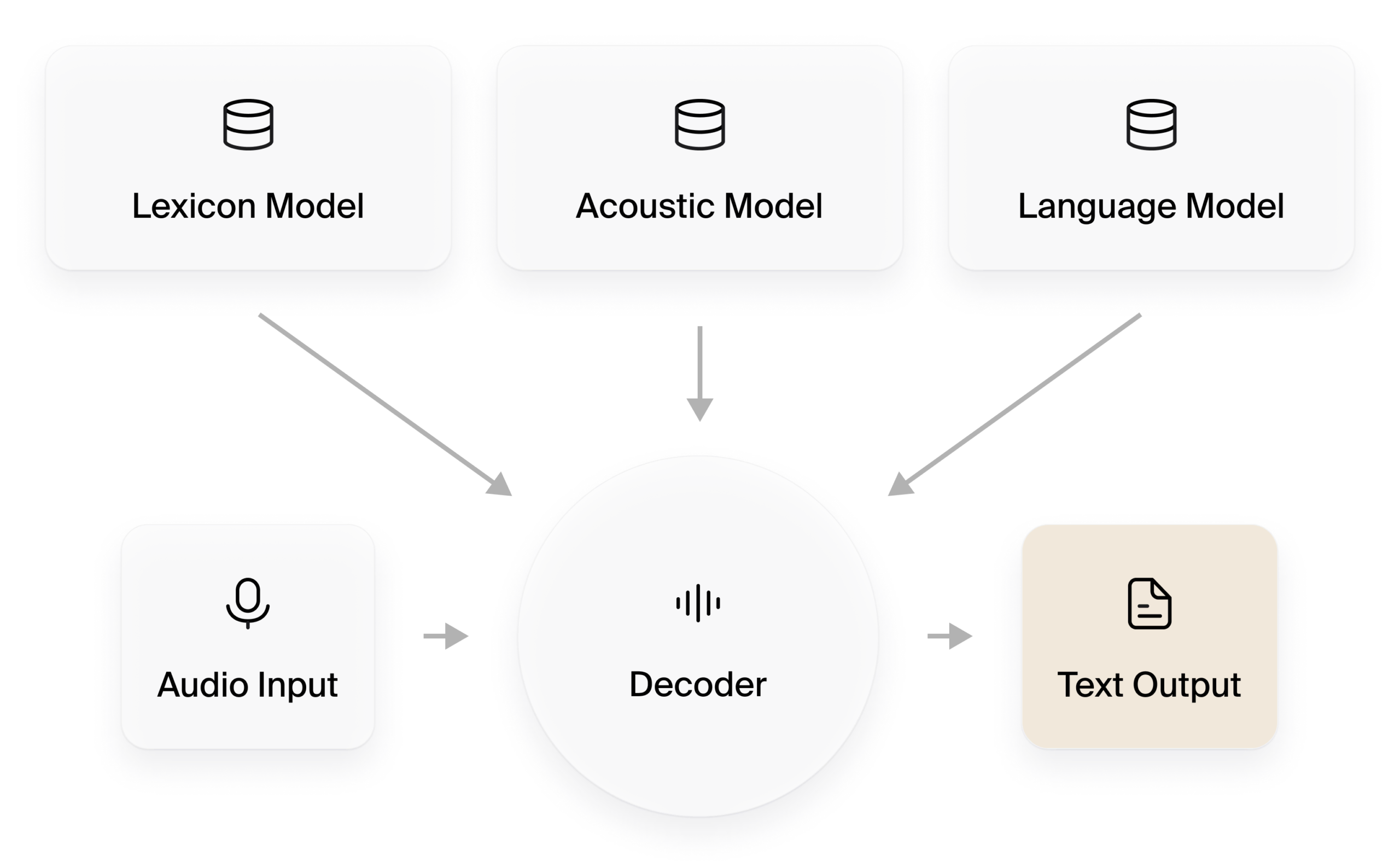
传统 ASR 模型的主要组件
您可能已经猜到了,这种方法需要独立训练多个模型,这既耗时又昂贵。然而,最显著的缺点之一是对词典模型的依赖。
传统语音识别模型的成功在很大程度上取决于词典模型的制作水平。经验丰富的语音学家合作为手头的语言创建自定义集。对于模型旨在支持的每种语言,都必须重复该过程。这使得实施具有挑战性,尤其是在向新市场扩张的动态商业环境中。
具有端到端 (E2E) 深度学习的现代 ASR 模型
现代 ASR 模型采用端到端深度学习的颠覆性语音处理方法。构建端到端系统的早期方法之一是由 Google DeepMind 的研究人员 Alex Graves 和多伦多大学的 Navdeep Jaitly 于 2014 年提出的。
本质上,现代 ASR 模型中的复杂神经网络取代了传统系统中的多阶段模型,从而最大限度地减少了延迟并大幅提高了性能和准确性。
该架构还摒弃了独立的语言、声学和词汇模型,由此产生的现代 ASR 系统可作为单个神经网络运行(与传统系统中的多个模型不同),从而缩短了开发时间和成本。此外,由于其先进的神经架构,它们还实现了无与伦比的准确度水平并支持多种语言。
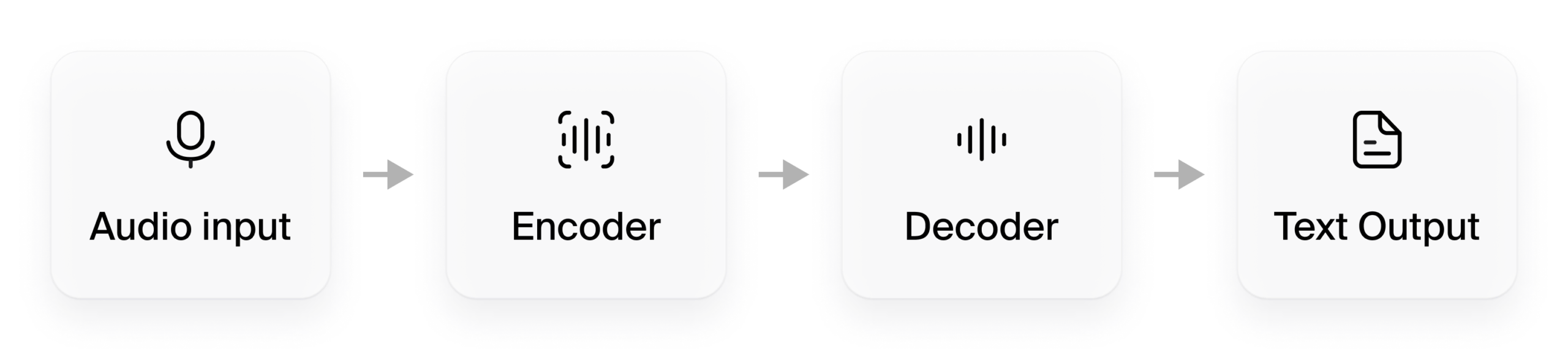
现代 ASR 模型的基本架构
现代 ASR 模型是在大型数据集上进行训练的,并且通常需要自监督深度学习,因为对于人类操作员来说,手动处理大量数据极具挑战性。工程师使用大量未标记的数据来构建基础模型,然后对其进行微调以实现所需的字错误率 (WER)。还可以根据此指标对模型进行基准测试,以比较性能。
OpenAI 的 Whisper seq2seq 模型是现代 ASR 模型的一个很好的例子,该模型基于来自多种语言的超过 680,000 小时音频数据的庞大数据集进行训练。这使得它比在较小、更专业的数据集上训练的模型更强大。seq2seq 模型本质上是一种针对涉及顺序数据(如语音和文本)的任务进行优化的 ML 架构。它包含两个核心组件,将序列作为输入并生成相关序列输出。
- 编码器:编码器使用神经网络处理输入序列并创建固定大小的向量表示。编码器还将从输入序列中捕获上下文并将其传递给解码器。
- 解码器:解码器模块接收编码器输出向量并创建输出序列。解码器将根据接收到的上下文及其自身的先前预测来预测输出序列的下一个标记。
- Transformers: Whisper seq2seq 模型使用端到端 Transformer 架构来理解输入音频中的上下文和含义。该模型首先将输入音频分割成小块,然后将其传递给编码器。解码器预测文本字幕。
- 循环神经网络 (RNN):有时编码器和解码器都使用循环神经网络 (RNN),这是一种非常适合序列预测的特定类型的神经网络。RNN 单元可以通过其内部记忆记住有关序列中先前看到的元素的信息,并使用它来确定当前输出。与 Transformer 不同,RNN 是顺序模型。例如,LSTM(长短期记忆)模型使用 RNN 架构。
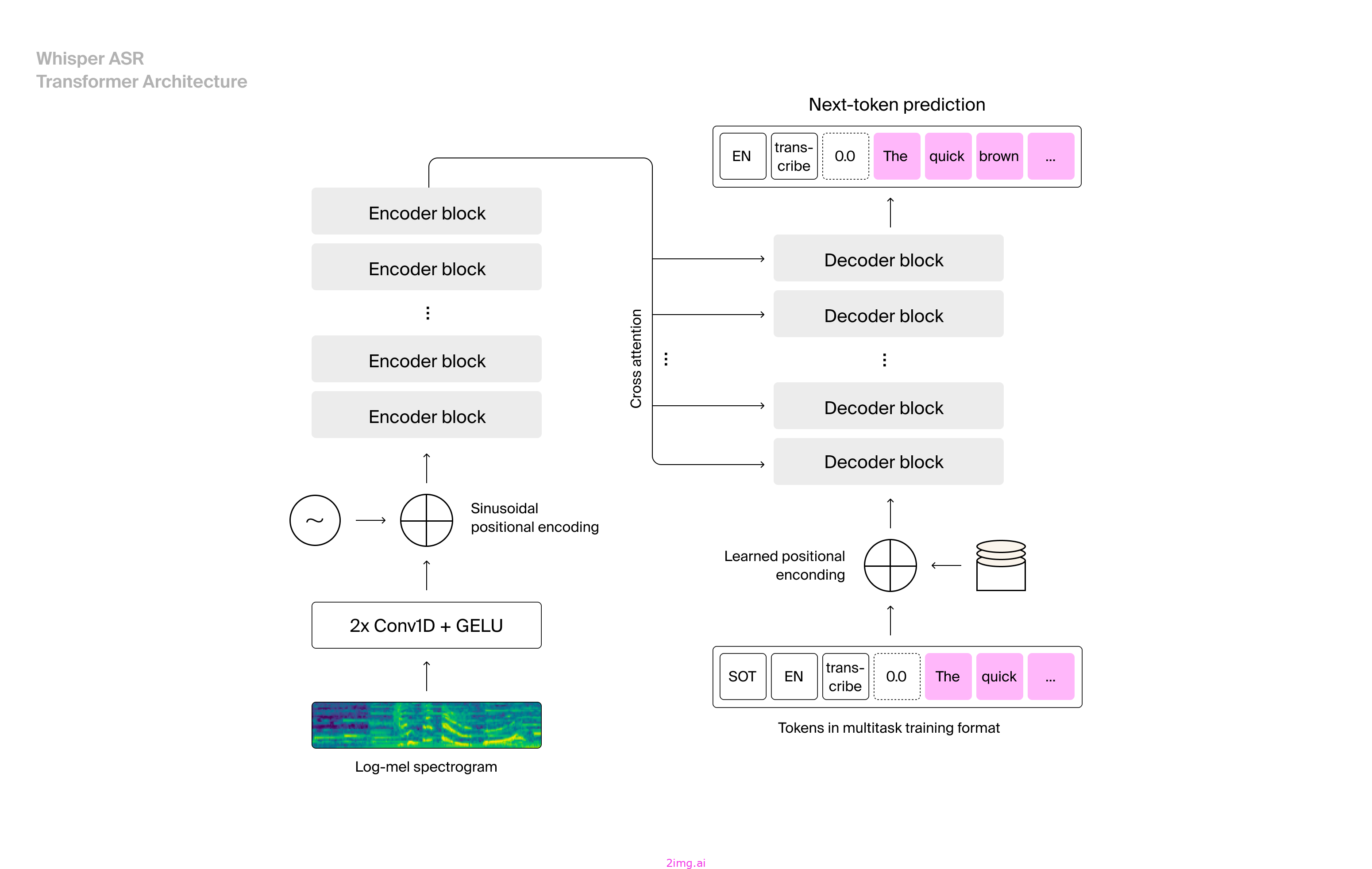
来源:OpenAI
传统 ASR 模型与 seq2seq 架构
为了方便参考,我们总结了传统和现代 ASR 方法之间的主要区别。
| 特征 | 旧式 ASR 模型 | Seq2Seq 模型 |
| 内部结构 | 具有声学模型、词汇模型和语言模型的模块化管道 | 使用具有编码器-解码器架构的端到端神经网络将语音直接转换为文本 |
| 准确性 | 准确度有限,无法达到人类的准确度水平 | 精度高,可达到甚至超越人类水平 |
| 多功能性 | 对不同输入的适应性有限(某些口音可能会影响转录) | 高度适应不同的口音和语言 |
| 训练数据类型 | 需要标记的语音数据才能正常运行 | 适用于未标记或标记较少的数据 |
| 训练技巧 | 每个模型都需要独立训练 | 整个模型一次性训练完成 |
| 适应性 | 最适合简单的语音转文本功能 | 最适合复杂且实时的语音转文本应用程序 |
| 速度 | 由于多阶段组件交互,通常速度较慢 | 由于并行处理,通常速度更快 |
| 错误检测和纠正 | 纠错能力有限 | 复杂的纠错和控制机制 |
| 可扩展性 | 可扩展性有限 | 高度可扩展 |
| 语言支持 | 支持有限数量的语言 | 可以支持大量语言 |
| 情境感知 | 语境感知有限。概率语言模型通过分析语境来预测下一个单词,但对机器学习的使用有限。 | 高度情境感知,利用深度学习进行全面的情境分析 |
RA/SD 衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/9196