
自动语音识别ASR(Automatic speech recognition),也称为语音转文本 (STT),已经存在了几十年,但过去二十年硬件和软件方面的进步,尤其是人工智能方面的进步,使得这项技术比以往任何时候都更加强大和易于使用。
开源 STT 模型的出现大大普及了高级 ASR 功能的使用。如今,这些模型可以提供可定制且经济高效的解决方案,用于将语音识别集成到应用程序中。
在本文中,我们将介绍目前最先进的开源 ASR 模型,包括 Whisper ASR、DeepSpeech、Kaldi、Wav2vec 或 SpeechBrain,重点介绍它们的主要优势和技术要求,


什么是语音转文本模型?
现代 ASR 可以非常可靠地将口语单词转录为数字文本格式,从而可以更轻松地分析、存储和处理音频数据,以供电信、医疗保健、教育、客户服务和娱乐等行业的广泛应用。
当今大多数领先的 ASR 模型都是围绕编码器-解码器架构构建的。编码器从输入中提取听觉特征,解码器将这些特征重构为自然语言序列。
利用这种架构,这些模型可以实现接近人类水平的音频和视频记录转录,例如采访、会议和讲座,甚至是实时的;它有助于将语音查询或命令转换为可操作的数据,从而增强用户体验和客户服务应用程序的效率。
更广泛地说,ASR 系统有助于开发语音控制应用程序、虚拟助手和智能设备,实现通过语音驱动命令实现免提交互。
最佳语音转文本开源模型
在选择企业使用的最佳开源语音转文本模型时,我们试图寻找准确且性能良好(即在实际场景中运行良好)的模型,以及具有高灵活性、可定制性和可集成性的开发工具包。在我们的选择中,重要的是观察良好的社区支持和发展,尽量避免“死亡”项目。
更多资讯 2img.ai
相关配图由微信小程序【字形绘梦】免费生成,直接扫码进入免费使用
- WhisperASR
Whisper是 OpenAI 推出的一款开源语音识别系统,它基于从网络收集的 68 万小时多语言和多任务监督数据组成的庞大而多样化的数据集进行训练。Whisper 可以将英语和其他几种语言的语音转录成文字,还可以将几种非英语语言直接翻译成英语。
Whisper 使用基于编码器-解码器转换器架构的端到端方法,将音频分割成 30 秒的片段,然后将其转换为对数梅尔频谱图,然后传入编码器,解码器根据该编码器预测相应的文本。此文本实际上与特殊标记混合在一起,这些标记指示模型执行语言识别、短语级时间戳、多语言语音转录和翻译成英语等任务。

Whisper ASR。来源:OpenAI
Whisper 被广泛认为是最好的开源 ASR,它具有多种优势,使其成为强大且实用的语音识别系统。
首先,其默认准确率位居前列。得益于其庞大而多样的训练数据,它可以处理各种口音、背景噪音和技术语言。它还可以使用单个模型执行多项任务,例如转录和翻译语音,这减少了对大多数其他模型所需的单独模型和管道的需求——例如,如果您想转录法语文本并实时将其翻译成英语。此外,Whisper 可以在不同的语音领域和语言上实现高精度和高性能,甚至无需额外的微调。
缺点是,OpenAI 提供的 Whisper “原始”版本旨在用作研究工具,并且存在一些限制,使其不适合大多数需要企业规模和多功能性的项目。
该模型存在输入限制,不包含说话人分类和单词级时间戳等基本功能,并且往往会产生幻觉,使其输出不适合高精度CRM 丰富和 LLM 支持的任务。
- DeepSpeech
DeepSpeech是Mozilla于2017年开发的一款开源语音识别系统,基于百度的同音算法。
DeepSpeech 使用深度神经网络将音频转换为文本,并使用 N-gram 语言模型来提高转录的准确性和流畅性。这两个模块都是从独立数据中训练出来的,可以作为转录器与拼写和语法检查器结合使用。DeepSpeech 既可用于训练,也可用于推理,并且支持多种语言和平台。除了支持多种语言之外,DeepSpeech 还具有相当灵活、尤其是可重新训练的优势。
尽管如此,与后来出现的 Whisper 等最先进的技术相比,DeepSpeech 存在严重的实际限制, 它的录音时间限制为 10 秒,这限制了它只能用于命令处理等应用,而不能用于长篇转录。
此外,此限制还会影响文本语料库,结果非常小,每句约 14 个单词/~100 个字符。开发人员随后报告称,需要拆分句子并删除常用单词和子句子以加速训练。截至 2024 年 4 月,有人提议将录音时间延长至 20 秒,但即使这样,似乎也与最先进的水平相差甚远。
DeepSpeech。
- Wav2vec
Wav2vec来自巨头 Meta,是一个语音识别工具包,专门用于使用未标记的数据进行训练,试图覆盖尽可能多的语言空间,包括通常用于监督训练的带注释的数据集中表现不佳的语言。
Wav2vec 背后的动机是,ASR 技术仅适用于全球数千种语言和方言中的一小部分,因为传统系统需要对大量带有转录注释的语音音频进行训练,而对于每一种可能的语音形式来说,不可能获得足够的数量。
为了实现其目标,wav2vec 模型是围绕一个自监督模型构建的,该模型经过训练可以将微小(25 毫秒)的掩蔽音频单元预测为标记,类似于大型语言模型经过训练可以预测短音节标记,但目标是与单个声音相对应的单元。由于可能的单个声音集比音节声音集小得多,因此该模型可以专注于语言的构成要素,并使用单个处理核心“理解”更多语言。
根据 Meta 的 AI 团队的研究,上述音频无监督预训练可以很好地跨语言迁移。然后,在将音频处理链接到实际文本的最后一步,Wav2vec 模型需要使用标记数据进行微调。但在这个阶段,它需要的音频转录对数量减少了大约 2 个数量级。
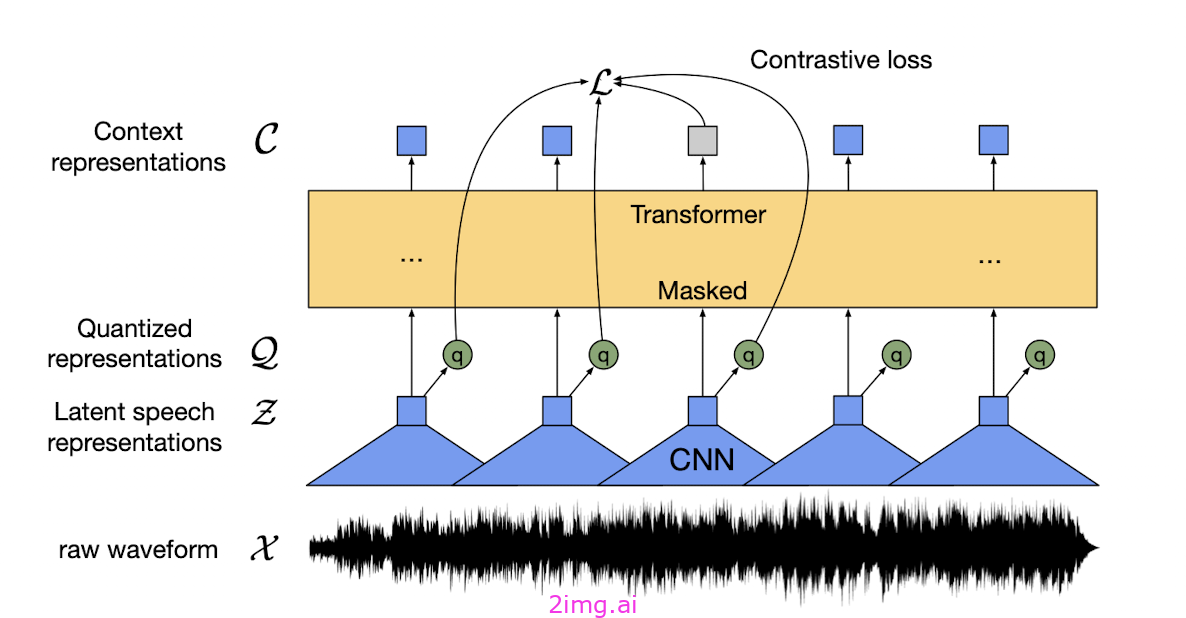
Wav2vec。来源:Facebook AI
据称,以这种方式训练的 ASR 系统可以超越截至 2020 年的最佳半监督方法,即使标记训练数据少 100 倍。虽然与新模型进行更现代的比较是可取的,但这仍然令人印象深刻,并且可能会找到应用,尤其是作为处理代表性不足的语言的音频的开源解决方案。
实际操作中,您可以使用自定义标记或未标记的数据训练 Wav2vec 模型,或者简单地使用其预制模型,这些模型已经覆盖大约 40 种语言。
- 卡尔迪
Kaldi是一个用 C++ 编写的语音识别工具包,其诞生的初衷是提供易于修改和扩展的现代灵活代码。重要的是,Kaldi 工具包试图以最通用和模块化的形式提供其算法,以最大限度地提高灵活性和可重用性(甚至对 Kaldi 自身范围之外的其他基于 AI 的代码也是如此)。
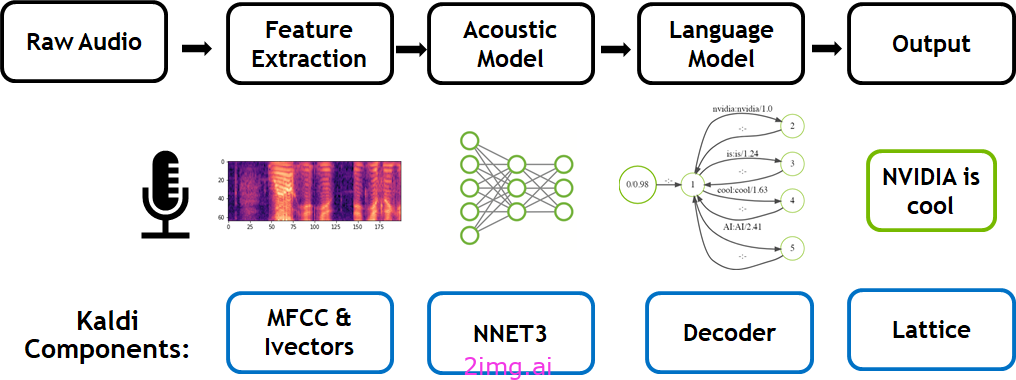
Kaldi。来源:Nvidia
Kaldi 并非完全是开箱即用的 ASR 系统,而是帮助开发人员构建语音识别系统,这些系统可以利用广泛可用的数据库,例如语言数据联盟 (LDC) 提供的数据库。因此,基于 Kaldi 的 ASR 程序可以构建在普通计算机、Android 设备甚至通过 Web Assembly 在 Web 浏览器内运行。后者可能有些受限,但很有趣,因为它可以为完全跨设备兼容的 ASR 系统铺平道路,该系统内置于 Web 客户端中,根本不需要任何服务器端处理。
- SpeechBrain
SpeechBrain是一款“一体化”语音工具包。这意味着它不仅可以执行 ASR,还可以执行与对话式 AI 相关的整套任务:语音识别、语音合成、大型语言模型以及与计算机或聊天机器人进行自然语音交互所需的其他元素。
虽然 Python 和 Pytorch 在 OS ASR 生态系统中很常见(例如,Whisper 本身就是在 Pytorch 上训练的),但 SpeechBrain 是作为开源 PyTorch 工具包设计的,旨在更轻松地开发对话式 AI。
SpeechBrain。来源:idem
与大多数替代方案(尽管是开源的,但主要由私营部门推动)不同,SpeechBrain 源自全球 30 多所大学的强大学术背景,并拥有庞大的支持社区。该社区在 40 多个数据集上分享了 200 多个竞争性训练方案,支持 20 个语音和文本处理任务。HuggingFace上预先训练的 100 多个模型可以轻松插入和使用或微调。
重要的是,SpeechBrain 既支持从头开始训练,也支持微调预训练模型,例如 OpenAI 的 Whisper ASR 和 GPT2 大型语言模型,或 Meta 的 Wav2vec ASR 模型及其 Llama2 大型语言模型。
缺乏太多控制的社区贡献的一个缺点是许多模型的质量可能值得怀疑;因此,可能需要进行广泛的测试以确保在企业环境中安全且可扩展地使用。
开源语音转文本:实际考虑
虽然开源 ASR 模型提供了无与伦比的灵活性和可访问性,但部署它们需要开发人员和组织仔细评估实际问题。
- 需要考虑的一个重要因素是部署成本,它涵盖了硬件要求、对 AI 专业知识的需求以及扩展限制等各个方面。与可能带有专门支持和优化的专有解决方案不同,开源模型通常需要大量计算资源进行训练和推理。除此之外,通常还需要一定程度的 AI 专业知识来优化适合特定用例和需求的通用开源模型。
- 另一个需要考虑的重要问题是,大多数(如果不是全部)开源模型都具有有限的功能集,并且需要对其核心架构进行进一步优化,以使其适合企业环境。对于寻求无忧体验的公司来说,开源几乎不是最佳选择。
简而言之,开源模型的总拥有成本不容小觑,而当将 ASR 嵌入到您的应用中时,支持 API 的混合架构实际上可能会为您带来更好的投资回报。
RA/SD 衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/9175