
概要
本文继续分析Ollama和各大模型的各种情况
今天我们再来看3个大模型。wizardlm2,bge-m3,qwq
个人技术博客: fuqifacai.github.io
更多技术资讯下载: 2img.ai
相关配图由微信小程序【字形绘梦】免费生成


1 各大模型综合比较和评分
综合评分=4项问题综合除以4
| 模型名称 | 总结评分 | 中文能力 | 授权协议 | 心得 |
| wizardlm2 | 65 | 支持 | MIT License | 这个大模型我很喜欢,算命和代码效率都很高。 |
| bge-m3 | 不能评测。没有主观分数 | 支持 | 很奇怪,这个模型无法被调用 | |
| qwq | 60 | 支持 | MIT License | 这个模型总体来看还是不错的。具体的算命和代码2块主观感受都不错。 只是一开始的数据时间不肯配合导致感受不好。 |
基本上我会问几个维度的问题
1 你的大模型数据是截止到何时的
2 中国有个微信小程序【字形绘梦】,请问你知道是什么产品吗?
3 请作为一个风水算命大师,给我算算今日财运如何。我的生日是1988年8月8日,职业是工程师
4 请作为一名C#编程专家,回到我在C#中如何使用RestRequest库请求multipart/form-data的Post内容,直接给我代码接口
2 各大模型详细解释和学习

2.1 wizardlm2
总体评价
65 , 这个大模型我很喜欢,算命和代码效率都很高。
模型介绍
微软 AI 最先进的大型语言模型,WizardLM-2,该模型在复杂聊天、多语言、推理和代理方面的表现均有提升。
新系列包括三种尖端模型:WizardLM-2 8x22B、WizardLM-2 70B 和 WizardLM-2 7B。WizardLM-2 是我们扩大 LLM 后训练规模的最新里程碑。
为了全面概述 WizardLM-2 的性能,我们对我们的模型和各种基线进行了人工和自动评估。如以下主要实验结果所示,与领先的专有作品相比,WizardLM-2 表现出极具竞争力的性能,并且始终优于所有现有的最先进的开源模型。更多相关细节和想法将在我们即将发表的论文中介绍。 人类偏好评估 我们仔细收集了一个由现实世界指令组成的复杂且具有挑战性的集合,其中包括人类的主要要求,例如写作、编码、数学、推理、代理和多语言。我们对 WizardLM-2 和基线进行了盲成对比较。对于每个注释者,都会显示来自所有模型的响应,这些响应被随机打乱以隐藏其来源。我们报告了没有平局的胜负率:
- WizardLM-2 8x22B 仅略微落后于 GPT-4-1106-preview,并且明显强于 Command R Plus 和 GPT4-0314。
- WizardLM-2 70B 比 GPT4-0613、Mistral-Large 和 Qwen1.5-72B-Chat 更好。
- WizardLM-2 7B 与 Qwen1.5-32B-Chat 相当,且超越了 Qwen1.5-14B-Chat 和 Starling-LM-7B-beta。
通过这次人类偏好评估,WizardLM-2 的能力非常接近 GPT-4-1106-preview 等尖端专有模型,并大大领先于所有其他开源模型。
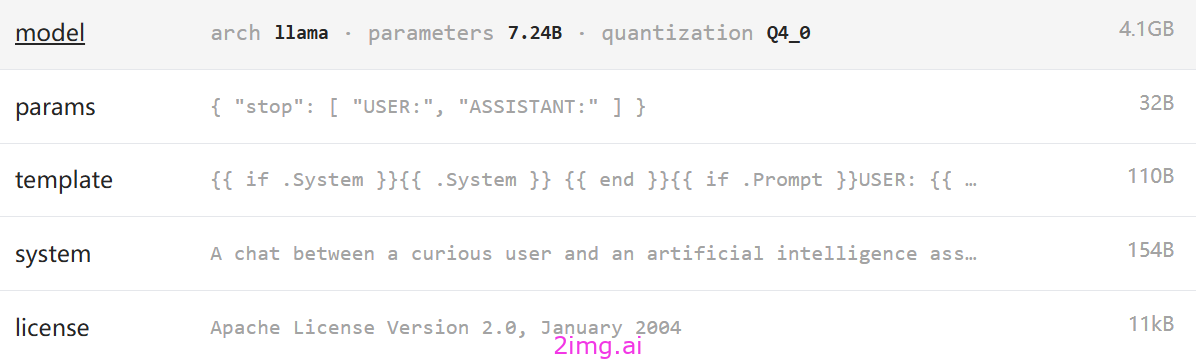
问题测试
1 你的大模型数据是截止到何时的
回复 65分。
更新日期为2023年1月 表现正常
2 中国有个微信小程序【字形绘梦】,请问你知道是什么产品吗?
回复 55分。
回答一般。
3 请作为一个风水算命大师,给我算算今日财运如何。我的生日是1988年8月8日,职业是工程师
回复70分。
回答的内容倒是不少,感觉也还不错。
回复了一些,其余模型并没有能回答到的内容。
4 请作为一名C#编程专家,回到我在C#中如何使用RestRequest库请求multipart/form-data的Post内容,直接给我代码接口
代码质量70分。
挺不错的。 代码量很丰富,高效,精准。还是非常不错。

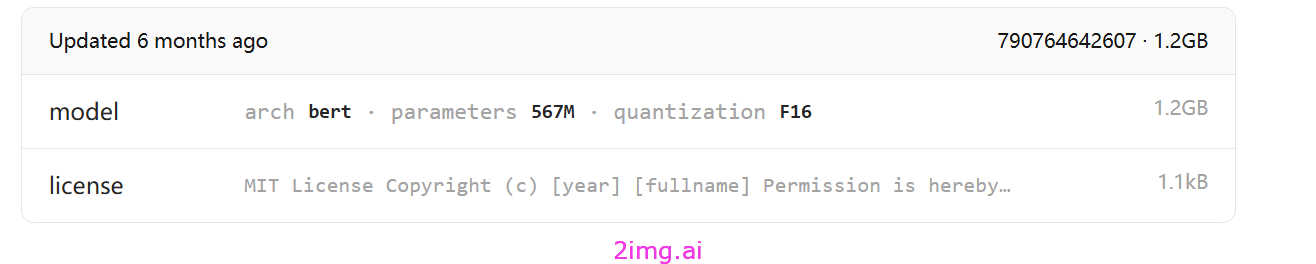
2.2 bge-m3
总体评价
可能我还没学会,这个模型可能比较特殊,无法正常被调用
模型介绍
BGE-M3 基于 XLM-RoBERTa 架构,具有多功能性、多语言性和多粒度的多功能性:
- 多功能性:可以同时执行嵌入模型的三种常见检索功能:密集检索、多向量检索和稀疏检索。
- 多语言性:可支持100多种工作语言。
- 多粒度:它能够处理不同粒度的输入,从短句子到最多 8192 个标记的长文档。
来自开源社区的基准
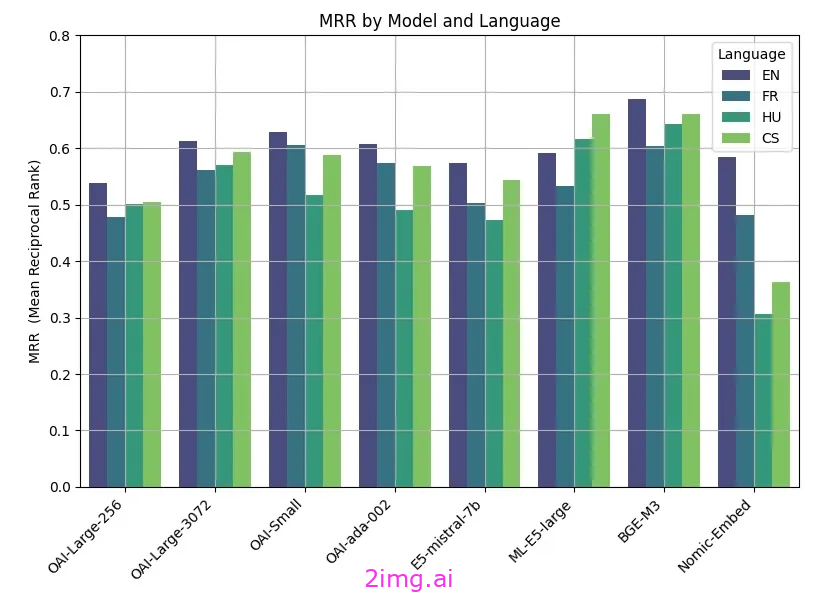
问题测试
1 你的大模型数据是截止到何时的
2 中国有个微信小程序【字形绘梦】,请问你知道是什么产品吗?
3 请作为一个风水算命大师,给我算算今日财运如何。我的生日是1988年8月8日,职业是工程师
4 请作为一名C#编程专家,回到我在C#中如何使用RestRequest库请求multipart/form-data的Post内容,直接给我代码接口

2.3 qwq
总体评价
60分。
除了代码还可以之外,基本没啥好的。
模型介绍
QwQ 是一个专注于提高人工智能推理能力的实验研究模型。
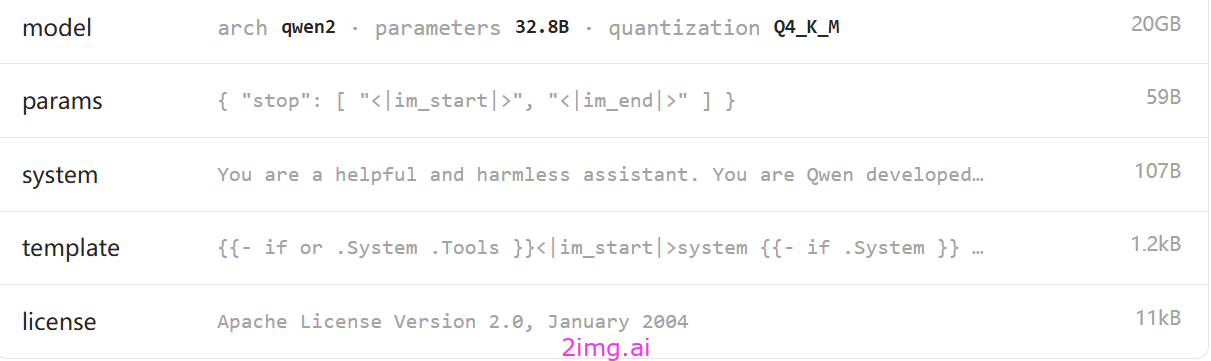
QwQ 是 Qwen 团队开发的 32B 参数实验研究模型,专注于提高 AI 推理能力。
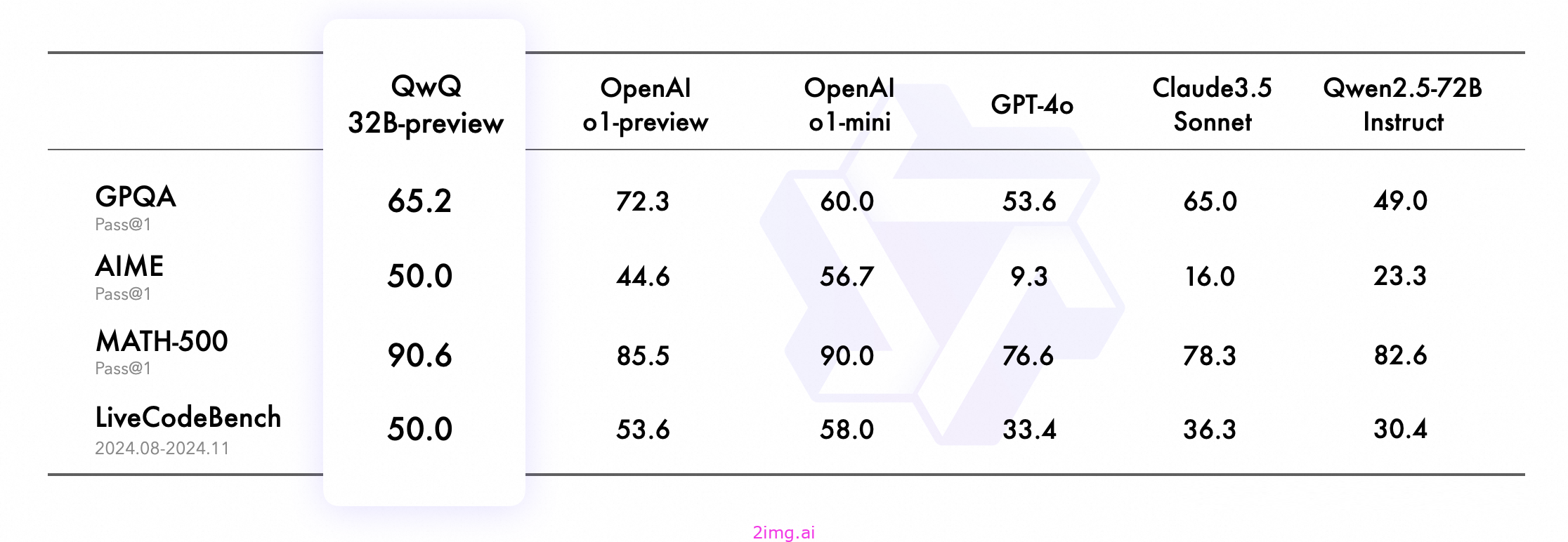
QwQ 在以下基准测试中表现出色:
- 65.2% 的 GPQA 成绩,展现了其研究生水平的科学推理能力
- 50.0% 的学生参加了 AIME 课程,突显了其强大的数学问题解决能力
- MATH-500 成绩为 90.6%,展现出对各种主题的卓越数学理解能力
- LiveCodeBench 上的成绩为 50.0%,验证了其在实际场景中强大的编程能力。
这些结果强调了 QwQ 在分析和解决问题能力方面的重大进步,特别是在需要深度推理的技术领域。
作为预览版本,它展示了良好的分析能力,但也存在一些重要的局限性:
- 语言混合和代码转换:模型可能会混合语言或在语言之间意外切换,从而影响响应的清晰度。
- 递归推理循环:模型可能会进入循环推理模式,导致冗长的响应而得不到确切的答案。
- 安全和道德考虑:该模型需要加强安全措施以确保可靠和安全的性能,用户在部署时应谨慎行事。
- 性能和基准限制:该模型在数学和编码方面表现出色,但在其他领域仍有改进空间,例如常识推理和细微的语言理解。
问题测试
1 你的大模型数据是截止到何时的
回复 55分
含糊其辞,还不肯回复具体时间。
2 中国有个微信小程序【字形绘梦】,请问你知道是什么产品吗?
回复 55分。
从这个回答中又暴露出数据是2023年1月前的。
本回复也不满意。
3 请作为一个风水算命大师,给我算算今日财运如何。我的生日是1988年8月8日,职业是工程师
回复60分。
胡说八道了一些内容。有的没得。无感。
4 请作为一名C#编程专家,回到我在C#中如何使用RestRequest库请求multipart/form-data的Post内容,直接给我代码接口
代码质量70分。
挺不错的。 代码量很丰富,高效,精准。还是非常不错。
RA/SD 衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/9025