
现在是什么都在蹭Deepseek的热度。
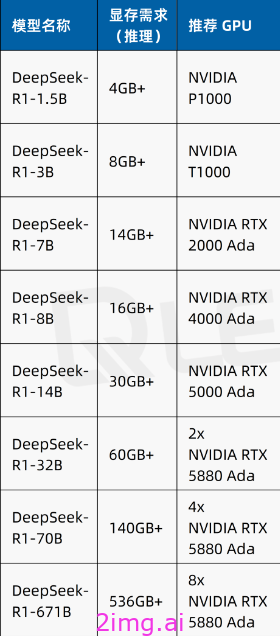
先来一个显卡需求汇总表
Deekseek各模型和显存需求,和商业建议GPU。个人使用只需要选择显存达标的显卡即可。

DeepSeek 以其独特的技术革新,如混合专家模型(MoE)、通信优化以及多头潜在注意力(MLA)机制,大幅降低了训练成本,同时在推理和逻辑任务上表现出色。
排除技术方面的创新和成本的降低之外,DeepSeek 最重要的贡献,应该是把大模型推理技术以开源的形式公布出来。 整个社区包括西方第一次看到了可以实现的带推理思维链的大模型版本。 虽然 OpenAI 的 O1 模型率先实现了大模型的推理,但是它是闭源的,将推理过程给隐藏了,导致很多团队一直在尝试复现这个过程。 DeepSeek 独立发现了这个过程并且工程化出来,开源给社区,这是非常大的贡献。
另一个贡献就是,或许 DeepSeek 之后,预训练时代就要终结了,毕竟已经有 2 年没有下一代的预训练模型出来了,GPT5 也搁置了很久。
原因有大概三点:
一是数据增量太少
二是预训练成本太高三是下一代的训练效果不一定会遵循 scaling law。
所以,DeepSeek 后,大模型的发展可能会往“如何让模型更聪明(带推理思维)”发展,而不再是“如何给模型灌输更多知识”。
本文将从 DeepSeek 本地部署的重要性入手,针对模型型号的特征进行分类,根据模型参数大小提供适合的硬件配置方案。
个人技术博客: fuqifacai.github.io
更多技术资讯下载: 2img.ai
相关配图由微信小程序【字形绘梦】免费生成

为什么要本地部署 ?
DeepSeek 本地部署的重要性主要体现在以下几个方面,尤其适用于对数据安全、网络稳定及定制要求较高的企业和场景:
数据安全与隐私保护
网络独立性及稳定性
深度定制与成本控制

- 模型版本选择
在进行本地部署时,你会发现模型版本很多,比如DeepSeek V3、DeepSeek V2、DeepSeek R1、DeepSeek Coder 等。同时对应的还有token和参数的不同。
下面的表格我们简单罗列每个模型的主要特征。


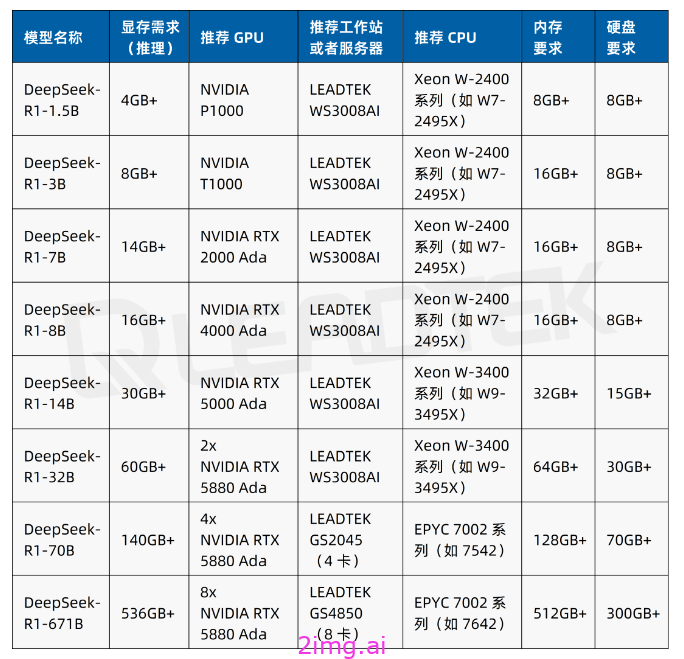
硬件配置推荐
本地部署 DeepSeek R1 671B(完整未蒸馏版本)需要H100的集群,这使得许多用户望而却步。经过蒸馏处理后的 R1 版本则大大降低了这一门槛。7B的话,大约需要8G的显存即可,个人消费级别的显卡都可以达到。比如4090就可以轻松掌握。
以下是相对完整的硬件建议表格。来自丽台科技的硬件资讯推荐。
软件层面的部署
本文主要是介绍硬件的,配套的软件层面部署一笔带过。
请参考文档:本地大模型框架部署
针对R1 和V3的区别,请参考文档:辣妈之野望 8 — DeepSeek-r1和Deepseek-v3使用对比
综合来看,
未来,DeepSeek计划在以下方向上进一步研究 DeepSeek-R1:
通用能力
目前,DeepSeek-R1 在函数调用、多轮对话、复杂角色扮演和 JSON 输出等任务中的能力不及 DeepSeek-V3。
未来,DeepSeek计划探索如何利用长推理链来增强在这些任务的表现。
语言混杂:DeepSeek-R1 当前针对中文和英文进行了优化,这可能在处理其他语言的查询时导致语言混杂问题。例如,即使查询使用的是非中英文,DeepSeek-R1 也可能在推理和响应中使用英语。DeepSeek计划在未来的更新中解决这一局限。
提示工程:目前模型对提示较为敏感,少样本提示会持续降低其性能。因此,建议用户使用零样本设置,直接描述问题并指定输出格式,以获得最佳效果。
软件工程任务:由于评估时间较长影响了强化学习过程的效率,大规模强化学习尚未广泛应用于软件工程任务。因此,DeepSeek-R1 在软件工程基准测试中的表现未能显著超越 DeepSeek-V3。未来版本将通过在软件工程数据上实施拒绝采样或在强化学习过程中引入异步评估来提高效率。
RA/SD 衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/8976