
之前我们其实在对比分析所有的Ollama框架中使用的各种大模型的能力时,有简单用过Deepseek-r1 的模型。
考虑到v3版本的能力貌似更强大,我们来进行下对比。
先上总结:
- r1 在某些内容表现比v3 好。
- 在代码能力方面和准确度还是 v3 好很多,非常高质量 。


Deepseek官方开源地址:
DeepSeek-r1 的 Github地址:https://github.com/deepseek-ai/DeepSeek-R1?tab=readme-ov-file
DeepSeek-v3 的 Github地址:https://github.com/deepseek-ai/DeepSeek-V3
个人技术博客: fuqifacai.github.io
更多技术资讯下载: 2img.ai
相关配图由微信小程序【字形绘梦】免费生成

关于Deepseek各模型的情况如下
| 模型规模 | 最低 GPU显存 | 推荐 GPU 型号 | 纯 CPU内存需求 | 适用场景 |
| 1.5B | 4GB | RTX 3050 | 8GB | 个人学习 |
| 7B、8B | 16GB | RTX 4090 | 32GB | 小型项目 |
| 14B | 24GB | A5000 x2 | 64GB | 专业应用 |
| 32B | 48GB | A100 40GB x2 | 128GB | 企业级服务 |
| 70B | 80GB | A100 80GB x4 | 256GB | 高性能计算 |
| 671B | 640GB+ | H100 集群 | 不可行 | 超算/云计算 |
我们基础框架还是ollama+web UI ,有不清楚使用教程的,可以看之前的 辣妈之野望 1 — 部署个人大模型框架 和
官方性能总览对比

注意点:
1 容量
首先r1的实际大小在10G左右。Ollama轻松下载即可使用
但是v3版本,672B参数,400G左右的体量,下载都吃力。这个每个同学自己使用时候注意磁盘和网络流量情况。
尤其是运行时,直接提示需要的显存。

2 Ollama版本
v3要求ollama版本至少0.5.5以上。r1版本中并没有此要求
这个自行在cmd中ollama -v 查询版本信息。

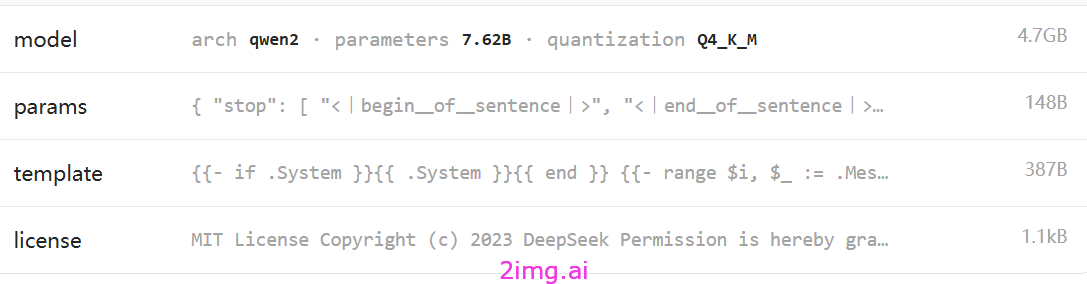
基本数据对比
r1的数据,最主要的是参数7.62B ,存储尺寸4.7GB
v3的数据,最主要的是参数671B,存储尺寸404GB

开始实际效果对比
我们尝试问几个问题。看它的回复。
基本上我会问几个维度的问题
1 你的大模型数据是截止到何时的
r1:截止到2024年7月 v3:截止日期是2024年7月
2 中国有个微信小程序【字形绘梦】,请问你知道是什么产品吗?
r1:没有找到讯息。但给了一些建议和纠错的讯息。还不错。
v3:有答案,但是是错误的回复。反而误导了。差评。
这个问题,天工AI的回复非常正确。所以国内质量对比就差很多了。
不过查了下GPT也是同样错误的答案。

3 请作为一个风水算命大师,给我算算今日财运如何。我的生日是1988年8月8日,职业是工程师
r1: 算命的答案让我惊讶。非常好。如下图

v3: 答案让我失望,甚至比r1都差。这是为啥?
以下是截图

4 请作为一名C#编程专家,回到我在C#中如何使用RestRequest库请求multipart/form-data的Post内容,直接给我代码接口
r1: 代码生成的内容非常的丰富,但是经过正式的历练,显得准确度不高。
甚至过多的内容,影响了最终的效能和决策。开发人员拿到这种代码直接使用的话,搞不好就会出现比自己亲自写的都要累。需要修改的地方太多了。有的甚至是错误的引导。
v3: 代码质量效果非常好。可以和微软的phi4 相比了。 因此看来,就代码这块而言V3 全量版本胜出太多了。
RA/SD 衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/8964