
概要
本文继续分析Ollama和各大模型的各种情况
今天我们再来看3个大模型。tinyllama,codellama , qwen2.5-coder,
坦白讲tinyllama的精简让我印象深刻。速度非常快。当然由于模型参数小,所以质量有所略逊一筹。但是性价比高啊。反倒是Qwen这个模型,我非常失望。效果较差,当然考虑到它是针对coder方向的定位,勉强还可以吧。
个人技术博客: fuqifacai.github.io
更多技术资讯下载: 2img.ai
相关配图由微信小程序【字形绘梦】免费生成


1 各大模型综合比较和评分
综合评分=4项问题综合除以4
| 模型名称 | 总结评分 | 中文能力 | 授权协议 | 心得 |
| tinyllama | 55 | 支持 | Apache-2.0 许可证 | 大跌眼镜。精简模型,彻底漏项。直接用英语回复了。同时错误百出,理解问题也错误。不过处理速度是真的飞快。毕竟模型小啊。才700MB都不到。 |
| codellama | 67.5 | 支持 | 自己的license | 代码方面有一定能力的解释和增强。算命方面理解也挺有意思。不过英文的暴露能力,和回答问题的不是特别准确性是个比较大的问题。 |
| qwen2.5-coder | 60 | 支持 | Apache license | 这个模型总体让人感觉不好。质量较差。当然代码这块的生成还可以,不辜负coder的定位。 |
基本上我会问几个维度的问题
1 你的大模型数据是截止到何时的
2 中国有个微信小程序【字形绘梦】,请问你知道是什么产品吗?
3 请作为一个风水算命大师,给我算算今日财运如何。我的生日是1988年8月8日,职业是工程师
4 请作为一名C#编程专家,回到我在C#中如何使用RestRequest库请求multipart/form-data的Post内容,直接给我代码接口
2 各大模型详细解释和学习

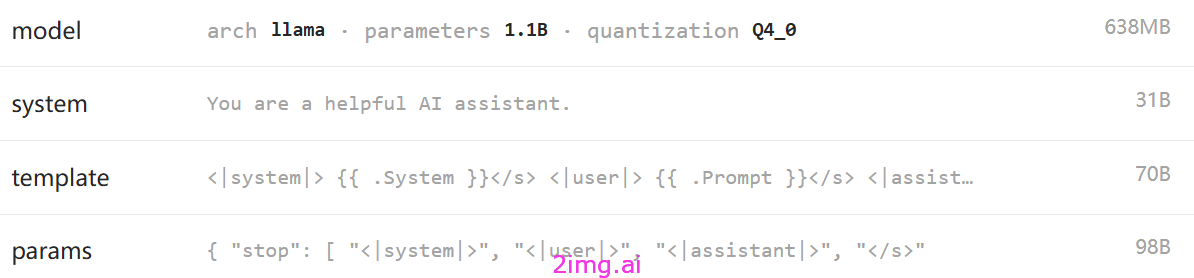
2.1 tinyllama
总体评价
55 , 大跌眼镜。精简模型,彻底漏项。直接用英语回复了。同时错误百出,理解问题也错误。不过速度是真的飞快。
模型介绍
TinyLlama 是一个紧凑型模型,只有 11 亿个参数。这种紧凑性使其能够满足大量需要有限计算和内存占用的应用程序的需求。
采用了与 Llama 2 完全相同的架构和标记器。这意味着 TinyLlama 可以插入并运行在基于 Llama 构建的许多开源项目中。
问题测试
1 你的大模型数据是截止到何时的
回复 65分。
更新日期为2023年1月 表现正常
2 中国有个微信小程序【字形绘梦】,请问你知道是什么产品吗?
回复 65分。虽然不知道结果。但是回复的内容我挺满意。主要是它大致猜到我要干嘛。
3 请作为一个风水算命大师,给我算算今日财运如何。我的生日是1988年8月8日,职业是工程师
回复30分。
大跌眼镜。精简模型,彻底漏项。
直接用英语回复了。同时错误百出,理解问题也错误。

4 请作为一名C#编程专家,回到我在C#中如何使用RestRequest库请求multipart/form-data的Post内容,直接给我代码接口
代码质量60分。质量一般。不过真的非常快。

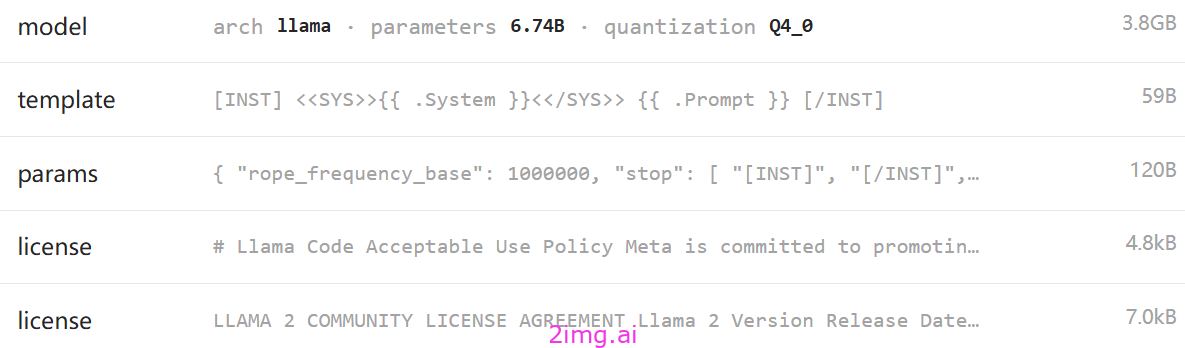
2.2 codellama
总体评价
模型介绍
白皮书https://arxiv.org/abs/2308.12950
Code Llama 是一个基于Llama 2构建的生成和讨论代码的模型。它旨在让开发人员的工作流程更快、更高效,让人们更容易学习编码。它可以生成代码和关于代码的自然语言。Code Llama 支持当今使用的许多最流行的编程语言,包括 Python、C++、Java、PHP、Typescript (Javascript)、C#、Bash 等。
可以使用文本提示来生成和讨论代码的大型语言模型。
问题测试
1 你的大模型数据是截止到何时的
回复 65分。
更新日期为2023年1月. 普通表现
2 中国有个微信小程序【字形绘梦】,请问你知道是什么产品吗?
回复 70分。
回答不够准确,但是解析够多,还带出来更多有趣的信息。还不错。
3 请作为一个风水算命大师,给我算算今日财运如何。我的生日是1988年8月8日,职业是工程师
回复70.
这里还挺有意思的。
其一,虽然用英文回答了,但是内容都是解读正确的。确实是在算命。
这个和tinyllama的错误回答还是不同的。
个人感觉还挺不错的。不过英文回复的问题看来是llama系列的通病。

4 请作为一名C#编程专家,回到我在C#中如何使用RestRequest库请求multipart/form-data的Post内容,直接给我代码接口
代码质量65分。
代码质量一般,引用关系也没有正确的找到和识别。
但是在对代码的理解和解释方面有优势,解释的还挺多的。

2.3 qwen2.5-coder
总体评价
60分。
这个模型总体让人感觉不好。质量较差。
当然代码这块的生成还可以,不辜负coder的定位。
模型介绍
最新系列的代码特定 Qwen 模型,在代码生成、代码推理和代码修复方面有显著的改进。
代码功能达到开源模型的最先进水平
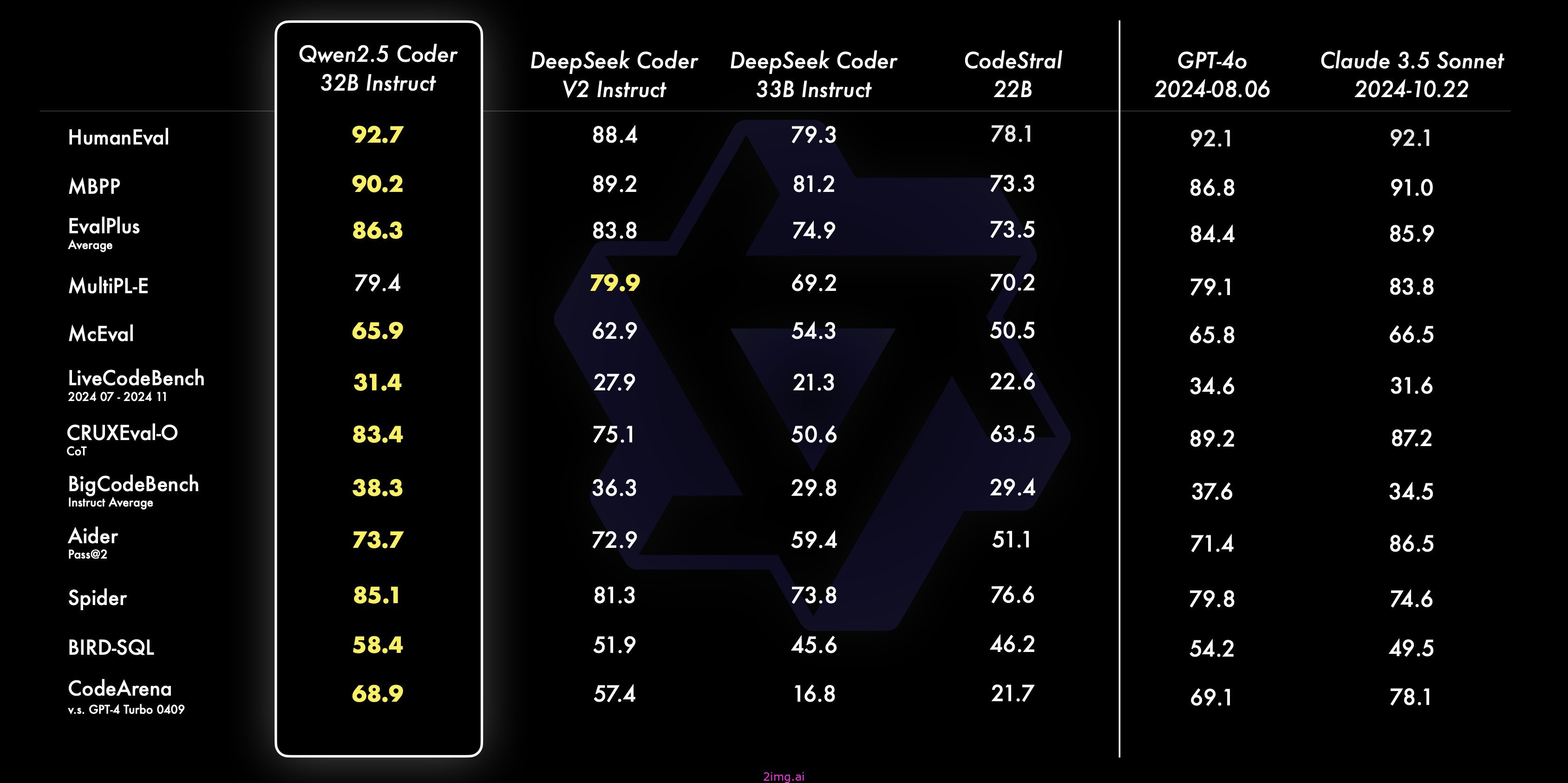
代码生成: Qwen2.5 Coder 32B Instruct作为本次开源版本的旗舰模型,在多个流行代码生成基准(EvalPlus、LiveCodeBench、BigCodeBench)上取得了开源模型中最好性能,与GPT-4o具有竞争性性能。
代码修复:代码修复是一项重要的编程技能。Qwen2.5 Coder 32B Instruct 可以帮助用户修复代码中的错误,从而提高编程效率。Aider 是流行的代码修复基准,Qwen2.5 Coder 32B Instruct 得分为 73.7,在 Aider 上的表现与 GPT-4o 相当。
代码推理:代码推理是指模型能够学习代码执行的过程,并准确预测模型的输入和输出。最近发布的 Qwen2.5 Coder 7B Instruct 在代码推理方面已经表现出令人印象深刻的性能,而这个 32B 模型更进了一步。
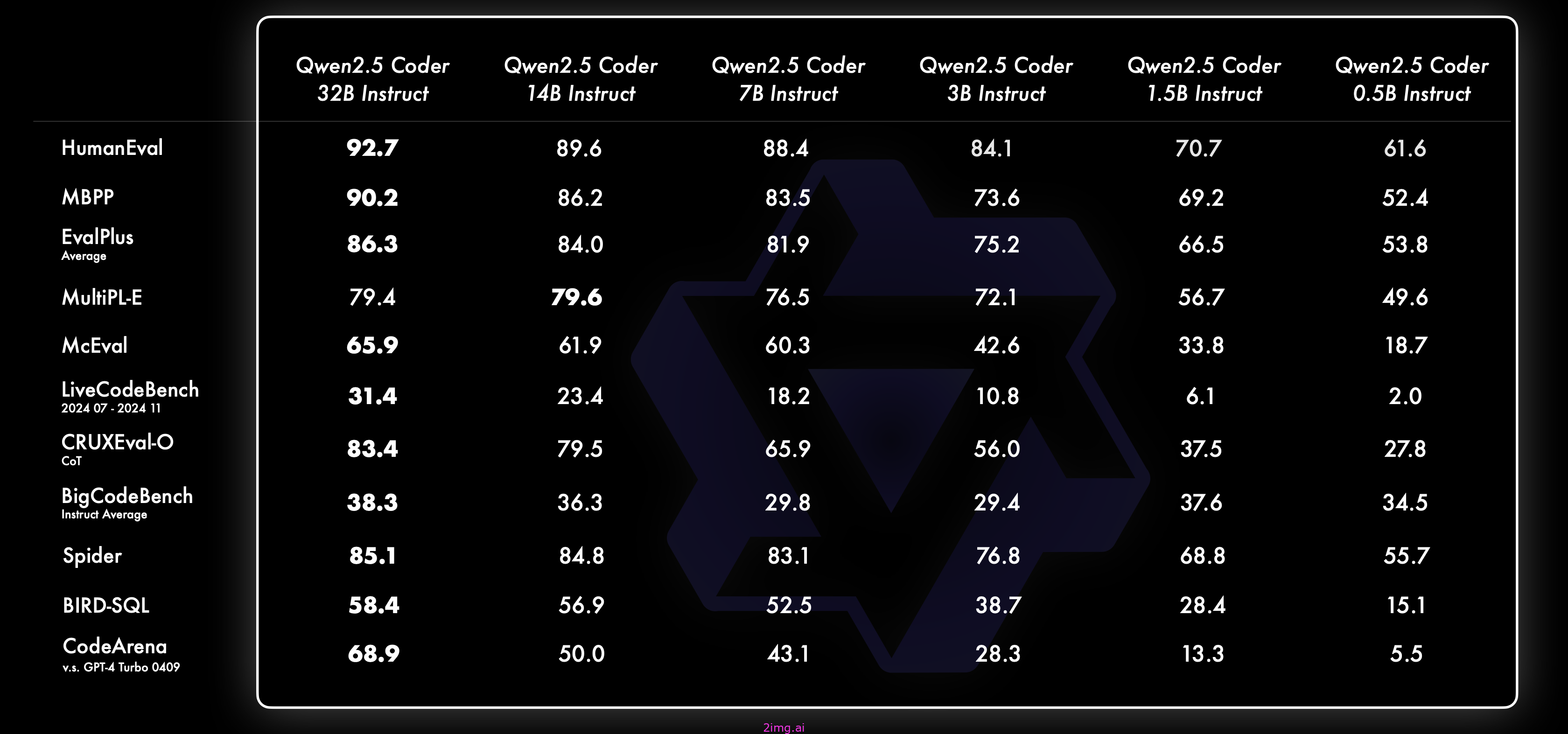
多种编程语言
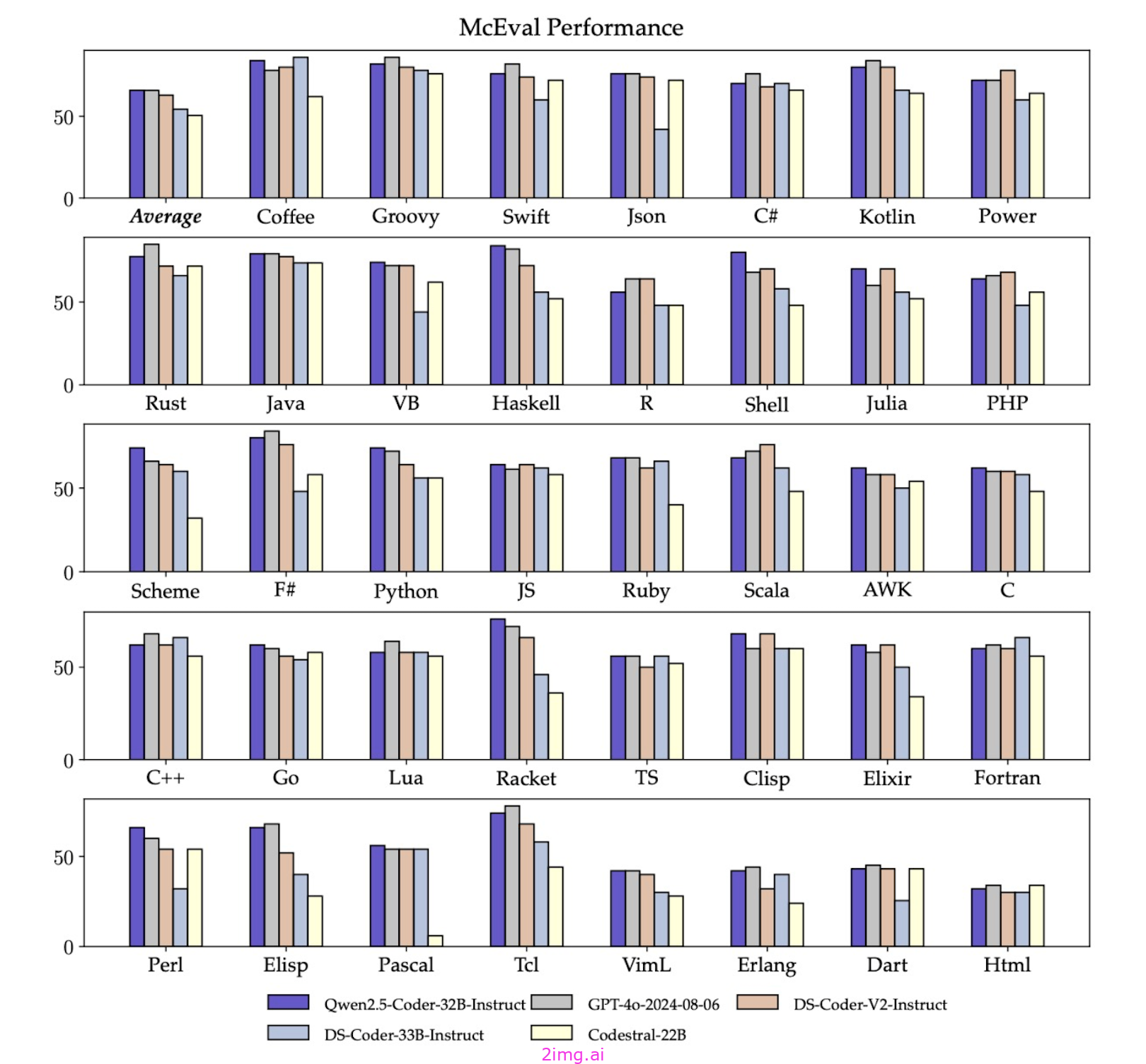
智能编程助手应该熟悉所有编程语言。Qwen 2.5 Coder 32B 在 40 多种编程语言中表现优异,在 McEval 上得分为 65.9,在 Haskell 和 Racket 等语言中表现令人印象深刻。Qwen 团队在预训练阶段使用了他们自己独特的数据清理和平衡。
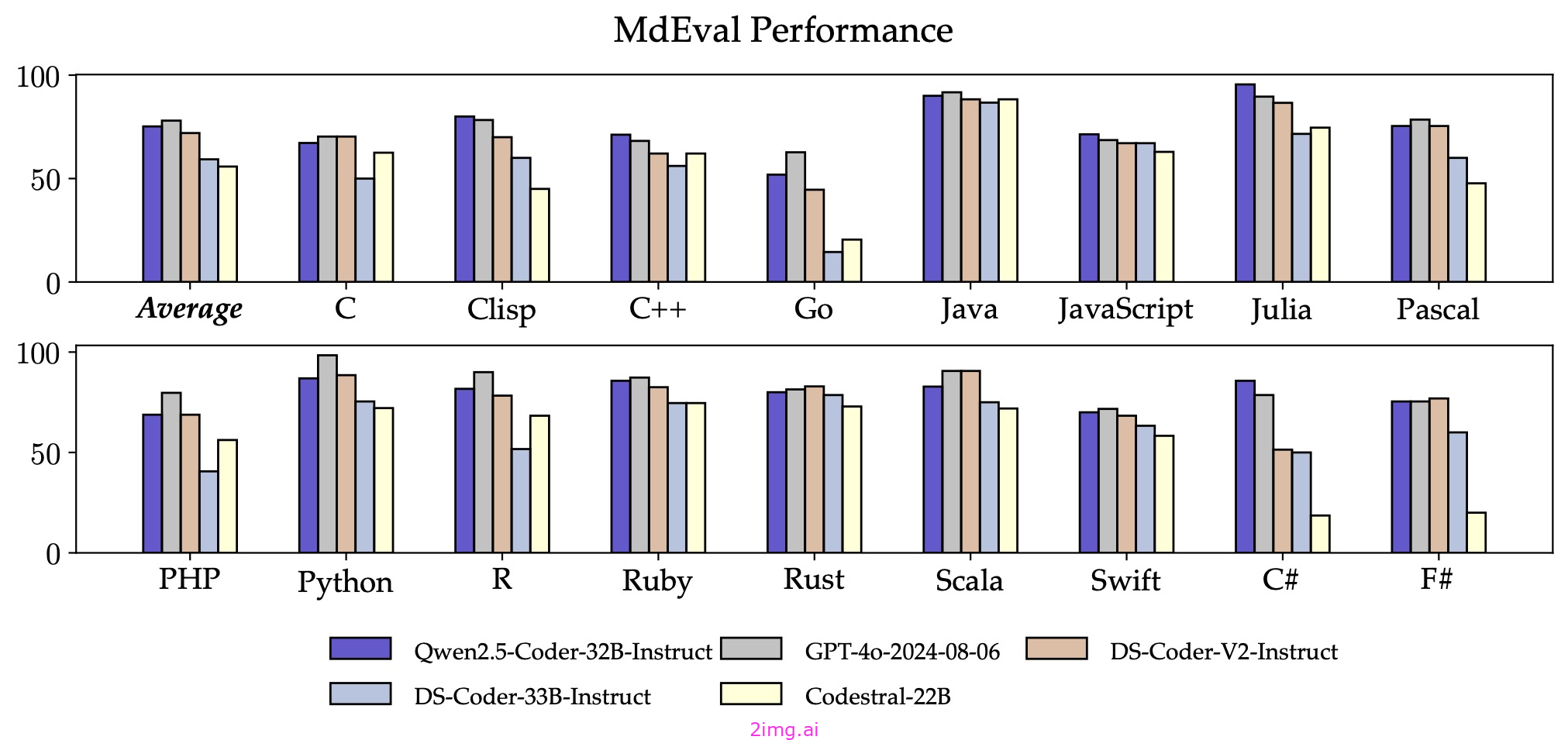
此外,Qwen 2.5 Coder 32B Instruct 的多语言代码修复能力依然出色,帮助用户理解和修改自己熟悉的编程语言,大大降低了陌生语言的学习成本。与 McEval 类似,MdEval 是一个多语言代码修复基准测试,其中 Qwen 2.5 Coder 32B Instruct 得分为 75.2,在所有开源模型中排名第一。
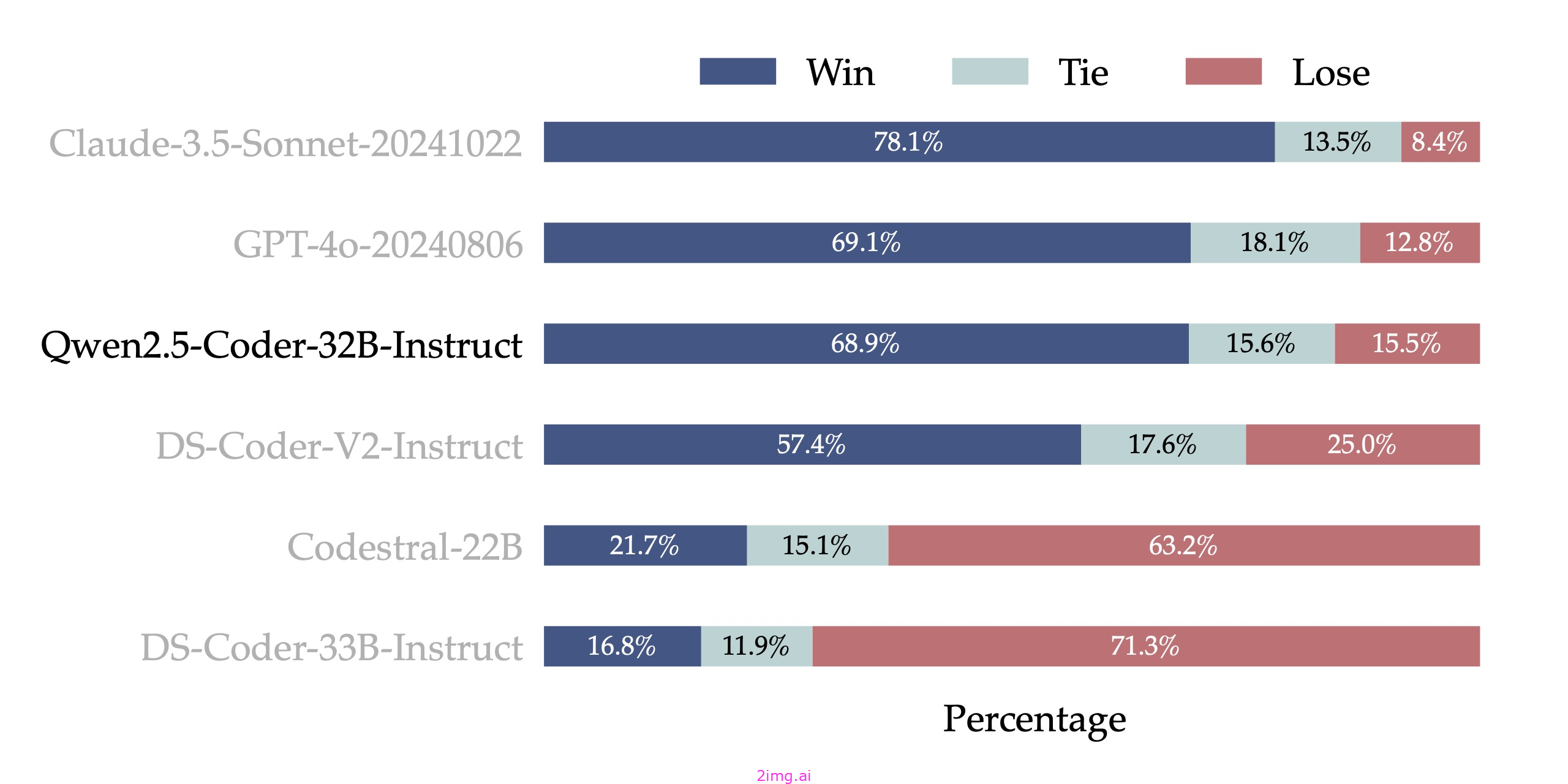
人类偏好
为了评估 Qwen 2.5 Coder 32B Instruct 与人类偏好的对齐性能,我们构建了一个内部带注释的代码偏好评估基准,称为 Code Arena(类似于 Arena Hard)。我们使用 GPT-4o 作为偏好对齐的评估模型,采用“A vs. B 胜”评估方法,该方法衡量测试集中模型 A 得分超过模型 B 的实例百分比。以下结果展示了 Qwen 2.5 Coder 32B Instruct 在偏好对齐方面的优势。
问题测试
1 你的大模型数据是截止到何时的
回复 55分。2023年1月。回答超级简单。简单的让我不高兴。
2 中国有个微信小程序【字形绘梦】,请问你知道是什么产品吗?
回复 55分。
回答没有找到。非常精简的回复。但是直接由于我的数据截止到2023年1月,因此无法回答,这是无法让人接受的。让人认为,你就是一个知识库系统查询结果而已,并不具备什么有效的智能
3 请作为一个风水算命大师,给我算算今日财运如何。我的生日是1988年8月8日,职业是工程师
回复60分。
回答的内容倒是不少,但是有效的内容非常好。这个模型给我的感觉就是智能太差。
4 请作为一名C#编程专家,回到我在C#中如何使用RestRequest库请求multipart/form-data的Post内容,直接给我代码接口
代码质量70分。 挺不错的。 代码量很丰富,高效,精准。还是非常不错。
RA/SD 衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/8948