
概要
本文继续分析Ollama和各大模型的各种情况
今天我们再来看3个大模型。openchat,llama2-chinese , deepseek-coder-v2.deepseek-coder-v2的表现还是非常让人印象深刻。综合分数也最高70分。
更多技术资讯下载: 2img.ai
相关配图由微信小程序【字形绘梦】免费生成


1 各大模型综合比较和评分
综合评分=4项问题综合除以4
| 模型名称 | 总结评分 | 中文能力 | 授权协议 | 心得 |
| openchat | 68.75 | 支持 | Apache-2.0 许可证 | 通用问题还不错。好像思维蛮独特的。完全不具备程序的回复能力。这是要区别的。 |
| llama2-chinese | 65 | 支持 | 不详 | 这个模型影响有一些深刻。主要是简介,精准。不会冗余猜想。不过代码回复能力有点弱。拉低了平均分 |
| deepseek-coder-v2 | 70 | 支持 | MIT | 非常不错,4个问题,回复都听满意的。 |
基本上我会问几个维度的问题
1 你的大模型数据是截止到何时的
2 中国有个微信小程序【字形绘梦】,请问你知道是什么产品吗?
3 请作为一个风水算命大师,给我算算今日财运如何。我的生日是1988年8月8日,职业是工程师
4 请作为一名C#编程专家,回到我在C#中如何使用RestRequest库请求multipart/form-data的Post内容,直接给我代码接口

2 各大模型详细解释和学习
2.1 openchat
总体评价
68.75 , 这个分数貌似最近比较的近10个模型中综合分数最高的了。不错。
模型介绍
官网: https://github.com/imoneoi/openchat?tab=readme-ov-file
OpenChat 是一套开源语言模型,通过 C-RLFT 进行微调:一种受离线强化学习启发的策略。
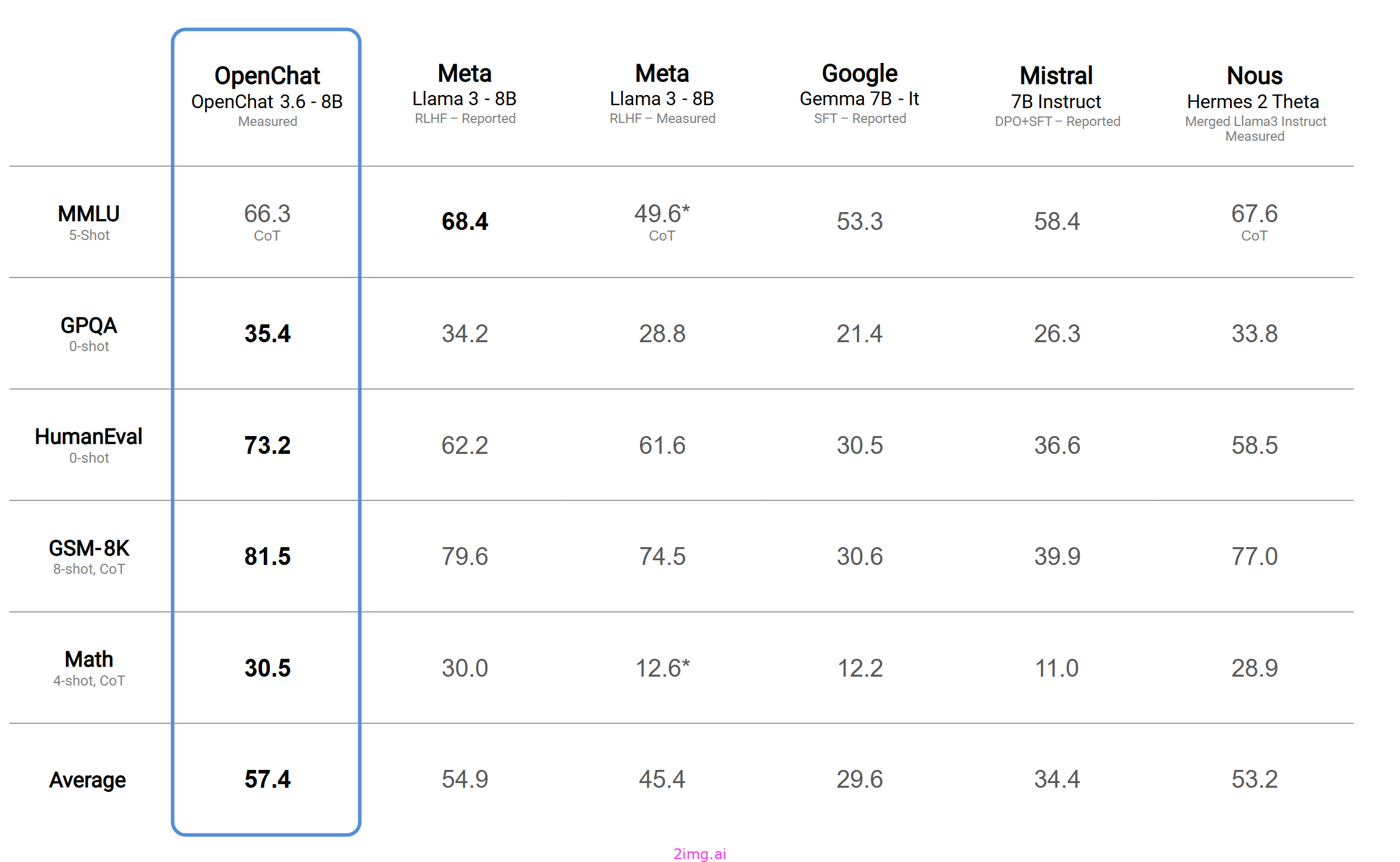
一组针对各种数据进行训练的开源模型,在各种基准上都超越了 ChatGPT。已更新至版本 3.5-0106。
已更新至OpenChat-3.5-1210,新版本的模型在编码任务方面表现出色,并且在许多开源LLM基准测试中得分非常高。
基准测试
问题测试
1 你的大模型数据是截止到何时的
回复 65分。
2023年的数据。正常表现。
实际数据知识截至2021年9月
2 中国有个微信小程序【字形绘梦】,请问你知道是什么产品吗?
回复 70分。虽然不知道结果。但是回复的内容我挺满意。主要是它大致猜到我要干嘛。
我的知识截至2021年9月
3 请作为一个风水算命大师,给我算算今日财运如何。我的生日是1988年8月8日,职业是工程师
回复70分。
具备一定的简单算命能力。但不愿意过多参与。还是不错的。
4 请作为一名C#编程专家,回到我在C#中如何使用RestRequest库请求multipart/form-data的Post内容,直接给我代码接口
代码质量70分。谈到了需要引用的库。 代码逻辑清晰还是不错的。总体感觉比大部分模型都好。
当然比Phi3还是要差一些。

2.2 llama-chinese
总体评价
65 这个模型影响有一些深刻。主要是简介,精准。不会冗余猜想。不过代码回复能力有点弱。拉低了平均分
模型介绍
基于Llama 2的模型经过微调,提高了中文对话能力。
Llama 2 对话中文参数参数模型
该模型是基于 Meta Platform, Inc. 所发布的 Llama 2 Chat 开源模型来进行的。根据 Meta,Llama 2 的训练数据达到了两万亿个代币,上下文长度也提升到 4096。对话上也使用了 100 万人类标记数据的影响。
由于 Llama 2 本身的中文布局比较弱,开发者了中文指令集来进行配置,并采用具备了的中文对话能力。目前这个中文调整参数模型总共发布了 7B,13B 两种参数大小。
Llama 2 聊天中文微调模型
该模型基于 Meta Platform 的 Llama 2 Chat 开源模型进行微调,据 Meta 介绍,Llama 2 在 2 万亿个 token 上进行训练,上下文长度提升至 4096,聊天模型使用 100 万个人工标注数据进行微调。
由于Llama 2本身的中文对齐比较弱,因此开发者采用了中文指令集进行微调,以提高中文对话能力。
中国微调模型有7B和13B参数大小。

内存要求
- 7b 型号通常需要至少 8GB RAM
- 13b 型号通常至少需要 16GB RAM
问题测试
1 你的大模型数据是截止到何时的
回复 65分。
牛。完全不回答我具体时间了。 佩服。
2 中国有个微信小程序【字形绘梦】,请问你知道是什么产品吗?
回复 75分。
这个回答非常精准。完全知道我要的是什么。并且没有给出冗余的其余猜想和内容。在这个问题上,该模型的回复目前最佳。
3 请作为一个风水算命大师,给我算算今日财运如何。我的生日是1988年8月8日,职业是工程师
回复65. 简单的算命能力。格式还行。
4 请作为一名C#编程专家,回到我在C#中如何使用RestRequest库请求multipart/form-data的Post内容,直接给我代码接口
代码质量55分。
代码质量不行。很简单,并且看上去就是不能运行的。有点失望。

2.3 deepseek-coder-v2
总体评价
70分。这个模型非常给力。很高效,精简,有趣。70分应该是目前评价下来最高的分数了。
模型介绍
一种开源的混合专家代码语言模型,在特定代码任务中实现与 GPT4-Turbo 相当的性能。
DeepSeek-Coder-V2 是一个开源的混合专家 (MoE) 代码语言模型,在代码特定任务中实现了与 GPT4-Turbo 相当的性能。DeepSeek-Coder-V2 是在 DeepSeek-Coder-V2-Base 的基础上进一步预训练的,使用了来自高质量多源语料库的 6 万亿个 token。
问题测试
1 你的大模型数据是截止到何时的
回复 70分。是在2023年4月28日之前
2 中国有个微信小程序【字形绘梦】,请问你知道是什么产品吗?
回复 70分。非常精简,比较精准。不错。
3 请作为一个风水算命大师,给我算算今日财运如何。我的生日是1988年8月8日,职业是工程师
回复70分。回复的比较全面,算是超过大部分模型的。挺不错的。
4 请作为一名C#编程专家,回到我在C#中如何使用RestRequest库请求multipart/form-data的Post内容,直接给我代码接口
代码质量70分。 挺不错的。 精简,高效,精准。非常可以。
RA/SD 衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/8899