
最新的AI框架Ollama配合使用最新的Open-WebUI 界面框架是最好的本地部署大模型方式。之前我们也介绍过使用webui-lite版本,参考文档:辣妈之野望 1 — 部署个人大模型框架
本文开始,我们介绍最新的完整版本的Open WebUI 框架。本文主要介绍该框架的白皮书。包含了核心的设计思路,值得开发者学习。英文原版链接:https://openwebui.com/assets/files/whitepaper.pdf
完整框架文档地址:https://docs.openwebui.com/
完整框架开源代码库地址:https://github.com/open-webui/open-webui
更多技术资讯下载: 2img.ai
相关配图由微信小程序【字形绘梦】免费生成


Open-WebUI 主要目的是设计一个开源的 LLM 界面和社交平台,用于集体驱动的 LLM 评估和审计
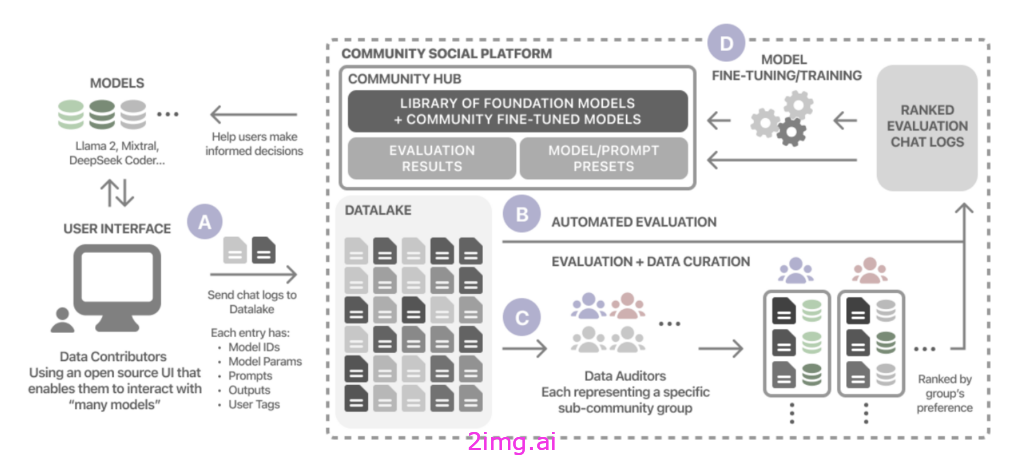
图 1:我们用于 LLM 评估和审计的社交平台概述。
(A) 用户与开源用户界面交互,
这使他们能够轻松地在许多模型之间切换,并将他们的聊天记录(包括模型详细信息和用户信息)提交到社区数据湖。
(B) 自动评估管道分析收集到的聊天记录,根据用户反馈进行比较分析,从而对模型性能和满意度进行初步的定量评估。
(C)专业子社区中的众包对聊天记录进行双盲评估,征求对所需模型行为的反馈,促进定性分析,并使模型开发与子社区偏好保持一致。
(D)来自自动化和众包管道的汇总评估为社区特定模型配置的开发提供信息,并提供精选的数据集,从而实现量身定制的 LLM 解决方案。 用户收到全面的评估结果和有效模型和提示配置的建议,并根据实际使用情况和社区反馈促进持续改进。
摘要
在大型语言模型 (LLM) 的新兴领域中,建立强大的评估和审计机制至关重要,以确保其符合道德规范并符合用户需求。
本研讨会论文提出了一个以人为本的 LLM 评估和审计新框架,该框架以开源聊天用户界面 (UI) 为中心,方便与各种模型进行直接交互。
这种方法允许从各种用户交互中收集丰富的数据集,这些数据集对于细致入微的评估至关重要。在此基础上,我们提出了一个社交平台,旨在通过众包利用用户的集体智慧,实现跨各个领域的 LLM 评估和审计。
该平台支持双层评估流程:基于用户反馈的自动初步评估和领域特定子社区内更深入的社区驱动分析。
这一过程的最终结果为定制模型配置和精选数据集的开发提供了信息,确保 LLM 满足不同用户群体的特定需求。通过将开源 UI与社会驱动的评估平台相结合,我们的方法培育了以社区为中心的生态系统,以持续改进 LLM,强调透明度、包容性和与人类价值观的一致性。
引言
大型语言模型 (LLM) 的快速发展表明迫切需要以人为本的交互式评估和审计方法,以掌握这些系统的运行情况 [6]。
到目前为止,LLM 评估在很大程度上依赖于总结LLM 性能的基准,但往往无法捕捉到不同用户环境和需求的细微要求,因为每个评估集都代表了一组用户和环境的观点,这使得它们在某些方面受到限制。
除了创建评估集需要优先考虑观点和价值观这一核心挑战之外,当前评估范式还存在其他问题,包括数据集泄漏问题以及由此导致的对评估数据的过度拟合 [17]。
实现 LLM 评估和审计改进的一种途径是设计新的界面和平台,允许用户选择共享“野生”数据。
已经有一些将评估界面与众包平台集成的尝试。例如,Lmsys 的 Chatbot Arena [15] 借鉴了社交计算 [12] 的游戏化模式。然而,现有的实现存在许多缺点:设计一个生态有效的环境具有挑战性,参与度更高的用户可能比其他用户高得多。这种代表性的缺乏对于使用众包数据评估和审计 LLM 在工作场所和教育环境等领域的使用情况尤其重要,因为在这些领域,使用环境至关重要。
在本次研讨会论文中,我们描述了旨在将开源用户界面 (UI) 和社交平台应用于LLM 评估和审计问题的早期研究。我们描述了设计社交平台的潜力,该平台允许运营本地、分散的 LLM 的社区或个人选择共享数据以进行评估和审计。我们讨论了与审计相关的本地 LLM 接口的两个方面,并提出了一套初步的社交平台设计目标,该平台为高质量数据共享提供激励,并描述了实现这些设计目标的正在进行的工作。我们强调了对 HCI 和 ML 来说将变得越来越突出的核心挑战
研究人员
随着“本地 LLM”产品的激增,并为用户提供了分散和选择退出数据收集的机会,我们如何提供促进共生关系的中心?
换句话说,需要哪些界面和平台设计考虑因素,以便个人 LLM 用户、用户社区和 LLM研究社区都能受益?
我们的工作大量借鉴了社交计算和众包,旨在整合许多用户的观点。通过收集更丰富、更具代表性的数据集,反映不同社区与 LLM 交互的不同方式,我们可以更细致地了解不同环境和用例中的模型性能。这种使用开源用户界面的方法还提供了将评估更无缝地集成到出于工作或个人原因使用 LLM 的人的工作流程中的潜力,从而允许评估指标根据不断变化的用户需求和偏好不断发展。
1.1贡献本研讨会论文有两个主要贡献。
首先,我们描述了 LLM 的开源、可扩展和本地接口(而不是通过私有服务操作的接口)如何帮助支持评估。
其次,我们描述了融合众包和数据共享元素的社交平台如何实现高度多元化的评估研究和审计(即具有更多观点和价值观的评估)。
此外,我们提出了数据收集方面的道德挑战以及这种方法固有的人们价值观冲突的可能性。
我们的论文旨在支持向 LLM 评估的范式转变,强调 HCI 和社交计算的见解和框架。通过适当设计的界面和社交平台,研究界可以从在线社区中受益,这些社区选择以新数据集的形式共享数据以供评估和审计,这些数据代表了更广泛的用户需求和人类价值观。
在随后的部分中,我们将深入探讨利用用户界面交互对评估 LLM 的重要性。
这里,重点是利用开源用户界面的重要性,它不仅促进了与许多模型的无缝交互,而且是使用众包作为克服 LLM评估方法现有局限性的工具的基石。至关重要的是,开源软件贡献者已经开展了多条工作,我们描述研究界如何利用这些努力。
在开源用户界面奠定的基础之上,下一节将探讨社交平台在 LLM 评估领域的作用。这一讨论不仅限于用户界面和众包技术之间的共生关系,还扩展到通过社区驱动评估进行数据管理的概念。我们强调在集中式和分散式评估实践之间取得平衡的必要性,并探索未来的潜力以及在培养致力于对LLM 进行细致入微评估的社交网络生态系统方面所固有的挑战。
2 通过用户
界面交互评估 LLMS
2.1 界面作为评估工具
某人用来与 LLM 交互的界面会极大地影响底层系统的评估方式。用户界面本质上与用户体验有着内在联系。
它是用户与 LLM 交互的主要媒介,从而在塑造他们对该模型的看法和整体满意度方面发挥着关键作用。每次LLM评估(隐式或显式)都涉及一个界面,通过该界面可以访问和判断模型的功能。
因此,界面成为评估的一个基本方面,为用户如何自然地与模型互动提供了一个窗口。通过将界面评估整合到 LLM 评估中,我们确保对这些模型的理解以现实世界的使用为基础,从而增强了研究结果的相关性和适用性。
本节深入探讨了将用户界面视为评估 LLM 的重要组成部分的理由和优势。
LLM评估的一个关键挑战是确保结果反映现实世界的使用情况并且生态有效。
广泛使用的开源聊天界面 [1、7、10、13] 使我们能够更真实地了解 LLM 在各种情况下的使用方式。
例如,用户出于教育目的与 LLM 交互的方式可能与他们在工作场所环境中将其用于创意写作或编码帮助的方式大不相同 [14]。
用户界面的动态特性还支持持续和不断发展的评估。随着用户与 LLM 的互动,他们的需求和期望可能会发生变化,并且可能会出现新的挑战。
一次性的评估过程无法捕捉到这种演变。但是,通过利用用户界面,我们可以不断收集数据和反馈,调整评估过程以适应不断变化的 LLM 使用格局。这种方法可确保评估保持相关性并与当前用户的需求
和期望保持一致。通过界面与 LLM 交互的用户的多样性确保评估能够捕捉到广泛的观点和用例。这种多样性对于开发公平、公正和广泛适用的 LLM 至关重要。
通过分析来自不同用户的数据,我们可以识别和解决模型性能中的偏差或差距,确保 LLM 有效且适用于广泛的用户和场景。
2.2 可扩展评估界面案例研究
:Open WebUI
LLM 的评估已到了一个关键时刻,传统的指标和基准已不再足够 [17]。
Open WebUI [13] 是一个用于本地(例如 Meta 的可下载 Llama 2)和/或私有(例如 OpenAI 的 GPT)LLM 的开源软件 (OSS) 界面。
它的设计和功能提供了一种新颖的范例,与 LLM 的实际使用和期望更加契合。
在随后的段落中,我们将深入探讨使 Open WebUI 成为 LLM 评估领域中不可或缺的工具的各个方面。
像 Open WebUI 这样的开源 UI 的主要优势在于它们能够从用户和 LLM 之间的真实交互中获取数据。
Open WebUI 是一个完全在本地运行的开源 LLM UI ,与在集中式服务器上运行的平台(如 ChatGPT )[8] 不同,它为最终用户提供了与他们习惯的 ChatGPT 类似的体验。
这种本地部署功能允许 Open WebUI 在各种环境中使用,从高安全性环境到互联网访问有限的远程位置。
它的开源性质不仅使评估过程民主化,而且还促进了以社区为主导的方法来理解和改进 LLM。
此外,Open WebUI 允许用户在同一个 UI中以各种配置与多个 LLM 交互,包括 OpenAI API 。这种灵活性对于评估模型在不同设置和用例中的性能至关重要。它为在相同条件下比较不同模型或在不同条件下比较同一模型开辟了途径,为细致入微的分析提供了丰富的数据集。这种定制和灵活性传统的评估方法无法实现评估。与孤立的测试环境不同,包括 Open WebUI 在内的开源 UI使用户能够在其自然的数字环境中使用 LLM——无论是用于工作、教育还是个人用途。
这些现实世界的交互数据非常宝贵,可以深入了解LLM 在各种且通常不可预测的条件下的表现。通过分析这些交互,我们可以衡量LLM 在实际使用场景中的实用性、适应性和可靠性。此外,Open WebUI 的本地执行允许收集有关各种硬件配置的模型速度和性能的数据。这一方面对于需要了解不同硬件环境中 LLM 的操作要求和限制的利益相关者至关重要。通过提供有关LLM 在不同硬件上的表现的见解,Open WebUI可以进行更全面的分析,帮助优化 LLM以适应广泛的应用。
Open WebUI 的一个显著优势是其简化的数据可导出性,它也可以轻松扩展和实施到其他开源 UI项目。
此功能极大地方便了使用现有用户群进行评估数据收集。Open WebUI 可以无缝聚合用户交互数据,这对于进行准确且能反映各种现实场景的评估至关重要。
从历史上看,这种深入而多样的数据收集只能在行业环境中实现,在这种环境中,公司可以利用其集中式系统吸引其忠实受众 [2、3、8]。相比之下,Open WebUI 提供了一种更透明、更易于访问的选项,打破了以前通过众包将研究限制在行业范围内的障碍。
这不仅使研究人员能够开发更强大的评估指标,而且还为使用实际使用数据进行实验和分析开辟了大量机会。这种方法的潜在应用非常广泛,远远超出了单纯的评估,可以探索 LLM 应用和性能中的未知领域。
2.3众包作为评估方法
众包在 LLM 评估中的一个基本优势是它能够捕捉广泛的用户交互,涵盖不同的语言、文化背景和应用领域。
传统的评估方法通常依赖于一组有限的基准或数据集,这些基准或数据集可能无法充分代表广泛的大量潜在 LLM 用户。开源 UI 通过促进来自不同背景和具有不同需求的用户交互,可以收集更能代表全球用户群的数据。这种包容性数据收集对于识别和解决 LLM 中的偏见至关重要,可确保这些模型对广泛的用户公平有效。
众包方法还可以快速识别LLM 中的问题和挑战。
在传统的评估环境中,识别缺陷或偏见的过程通常很慢且反复,通常局限于一小群开发人员或评估人员的观点。相比之下,众包允许从庞大而多样化的用户群中获得即时反馈。这种反馈不仅限于技术性能,还包括LLM 响应的道德和社会影响。用户可以报告不适当或有偏见的响应、异常行为或其他问题,然后开发人员可以快速解决这些问题。匿名。
2.4 增强众包 LLM 评估
用户参与度通过 Open WebUI 等用户界面评估 LLM 的成功,关键在于利益相关者的积极参与。这种参与不仅仅是让用户与模型互动;而是让他们深入参与评估过程,从而将他们从被动消费者转变为主动贡献者。因此,鼓励广泛的用户参与不仅仅是一个补充目标;这是这种评估方法有效性和有效性的基本要求。
2.4.1 创建以社区为中心的评估生态系统
增强用户参与度的第一步是围绕 LLM 培养一个社区。这个社区应该建立在合作、共享学习和互惠互利的原则之上。通过参与评估过程,用户不仅可以为 LLM 的改进做出贡献,还可以深入了解其能力和局限性。这种双向道路在用户中创造了一种主人翁意识和责任感,这对于持续参与至关重要。
2.4.2 游戏化和认可
游戏化元素可以显著提高用户参与度 [4, 12]。加入徽章、排行榜或活跃贡献者积分等元素可以创造更具吸引力和回报性的体验。在社区内公开表彰顶级贡献者不仅可以激励他们,还可以激励其他人积极参与。
2.4.3 促进同伴学习和分享
鼓励用户分享他们的最佳实践、有趣的发现和自定义提示可以促进社区内的学习环境 [5]。这种点对点交互可确保用户不仅为评估贡献数据,而且还相互学习,从而使他们的参与更有价值。
2.4.4开放问题:持续参与的有效策略
上述策略为通过 Open WebUI 促进用户积极、有意义地参与 LLM 评估奠定了基础。然而,问题仍然存在:我们如何才能最有效地实施这些策略?这不仅仅是后勤规划的问题,也是了解潜在用户的不同动机和限制的问题。什么样的激励措施最引人注目?我们如何平衡对高质量、有意义的互动的需求与让尽可能多的用户参与的愿望?这些问题将我们引向下一节,该节将探讨激励参与的潜在解决方案和蓝图,确保用户不仅愿意而且渴望为这一关键的评估工作做出贡献。
3 评估及其他领域的社交平台
用于评估及其他领域的社交平台将社交平台纳入大语言模型评估标志着我们理解和改进这些技术的方法发生了重大转变。
本节深入探讨社交平台在大语言模型评估中的多方面作用,强调用户界面、众包方法和社区驱动的数据管理之间的动态相互作用。
首先,我们强调集中式和分散式评估生态系统之间所需的微妙平衡,提倡一条中间道路,利用两者的优势来促进开放研究和多样化观点。
随后,我们探讨了现有的格局、未来的可能性以及构建类似社交网络的大语言模型评估生态系统所面临的挑战。
3.1 驾驭集中化-分散化频谱
我们提出的社交平台的运作原则是在大语言模型运营的总体环境的集中化和分散化之间找到最佳平衡(例如,参见关于分散化作为一个概念和修辞策略的复杂性的讨论[9])。
这种平衡对于获取广泛而多样的数据和观点至关重要,这对于有效评估大语言模型至关重要。
集中式方法虽然在数据收集方面很有效,但可能无法捕捉到不同用户群的细微需求和背景。
纯粹的集中式方法还存在使收集的数据同质化的风险,主要代表活跃用户群,而忽略潜在用户和非用户的观点。
这种狭隘的数据捕获可能无法反映 LLM 运行的不同背景,从而限制了模型在不同人群和用例中推广的能力。
此外,集中化通常会给开放科学设置障碍,使学术界难以访问、利用和贡献数据集,从而扼杀LLM 开发中的协作创新和透明度。
另一方面,分散化提供了一种分布式数据收集和管理模型,其中控制权和所有权分散在更广泛的参与者中。这种方法自然有助于更广泛地捕获数据和观点,因为它使来自不同背景的用户能够贡献他们独特的互动和反馈。
然而,分散化的挑战在于汇总足够的数据以获得有意义的见解和评估。如果没有足够的参与,收集的数据可能过于稀疏,无法为稳健的 LLM 评估提供信息,也无法全面理解复杂的用户交互。
我们的平台旨在通过鼓励广泛参与和允许用户控制其数据来调解这一问题,从而确保数据集丰富,涵盖广泛的交互和观点。
为了确保平台成功吸引和留住多样化的用户群,必须创造参与激励措施。表彰贡献者的宝贵见解或数据,从而改进模型,可以激励持续参与。
此外,该平台必须吸引各种用户,从休闲对话者到需要可靠决策支持工具的专业人士。这种多样性对于评估不同场景中的 LLM 至关重要,确保开发出稳健、可靠且广泛适用的模型。
3.2当前形势和未来愿景
目前Open WebUI 的社交平台站在将 LLM 交互与社交平台动态相结合的最前沿,创建了一个用户可以积极参与LLM 评估和增强的生态系统 [13]。这种整合不仅增强了用户参与度,还营造了一个集体空间设计一个开源的 LLM 界面和社交平台,用于集体驱动的 LLM 评估和审核,以学习、共享和定制模型交互。该平台的功能(例如共享模型配置以及聊天记录以及参与协作提示工程)展示了这种混合模型对 LLM 评估领域产生重大影响的潜力。
展望未来,我们设想一个社交平台,它不仅支持与 LLM 的交互,还使用户能够积极参与评估和开发过程并做出贡献。这个未来的平台将像一个社交网络一样运作,但有一个重点:协作改进 LLM。这一愿景的一个关键方面是承认社区参与策划和评估数据集会带来更精细、更具代表性和社区主导的方法 [11]。
这种参与极大地丰富了人工智能评估过程,确保开发的技术不仅技术先进,而且符合用户社区的不同需求和观点。通过采用社区驱动的评估和数据集管理,我们的社交平台可以利用用户的集体智慧和多样性来培育更具包容性、准确性和有效性的 LLM 评估生态系统。
3.3 众包评估方法
我们的社交平台引入了双轨评估流程,旨在利用众包的力量对LLM 进行细致入微的评估。这种新颖的方法将自动评估与深度社区驱动的审计相结合,提供了一个全面的评估框架,该框架既可扩展又能适应不同的用户需求和偏好。自动评估流程:我们的评估框架的基础是自动流程,它利用从用户与 LLM 的交互中收集的原始聊天记录。
每次互动都标有所使用的模型及其 ID,允许根据用户反馈进行有组织的比较分析,例如“竖起大拇指”或“竖起大拇指”评级或响应再生历史等机制。该系统有助于对模型性能和用户满意度进行初步的定量评估,作为我们综合评估框架中至关重要的初始过滤器。
自动化管道的效率在于它能够快速汇总和分析大量反馈,从而提供对模型优势和改进领域的基础了解。社区驱动的评估流程:在自动评估的基础上,我们通过强大的众包流程进一步完善了评估流程。该流程利用了平台多样化子社区的内在价值——具有专业兴趣或专业知识的群体,例如专注于医疗、法律或编程领域的群体。通过让这些群体参与聊天记录和模型交互的双盲审查,我们征求了对模型性能的更深入的定性见解。
向这些社区提出的关键问题,例如“您希望您的模型以这种方式表现更多吗?”,有助于进行更细致的评估。这种方法不仅可以评估模型的充分性,还可以使未来的模型开发与不同用户组的特定需求和偏好保持一致,从而促进高度定制和以社区为中心的 LLM 改进方法。
角色和职责:
(1) 数据贡献者:这些用户是我们评估生态系统的核心,直接与 LLM 交互并贡献宝贵的交互日志。这个角色对于生成为两个评估轨道提供信息的原始数据至关重要。贡献者可以使用标签和注释来增强其提交的内容,从而提供关键的元数据,丰富数据集并指导后续评估和模型改进。
(2)数据审计员:与贡献者并行的是负责管理数据集的数据审计员。他们根据质量、相关性和对道德标准的遵守情况审查提交的内容,使用赞成或反对来表明每个贡献的价值。此过程不仅维护了数据集的完整性,而且还使评估过程民主化,使社区就LLM 性能的标准和基准达成共识。这种双轨方法为 LLM 评估提供了一个动态而灵活的框架,将自动化过程的可扩展性与人类判断的深度和背景性相结合。通过利用我们平台子社区的集体智慧,我们实现了更民主、更包容的评估过程。这不仅提高了数据集的质量,而且还确保模型开发不断受到现实世界反馈和不断变化的用户需求的影响。这种众包方法不仅通过为用户提供对模型开发的切实影响来激励参与,而且符合创建更可靠、更合乎道德、以用户为中心的 LLM 的更广泛目标。
3.4数据管理作为评估的副产品
数据管理是专为 LLM 审计而设计的社交平台上评估过程的自然副产品。这凸显了一个经常被忽视的机会,即通过战略性地收集和组织评估数据来提高模型性能。当用户与 LLM 交互并对其进行评估时,他们的输入、反馈和交互背景会产生大量数据,如果经过适当管理,这些数据可以极大地指导和改进模型训练过程。评估行为本身,尤其是在参考了多样化的用户体验和见解的情况下,会产生高度相关且情境化的数据集。这些数据集不仅反映了广泛的用户需求和偏好,还体现了不同领域和人口统计数据中语言和交互模式的细微差别。通过管理这些数据,平台可以创建丰富的带注释的资源,为 LLM 的微调提供宝贵的见解。有效的数据管理需要对评估活动和平台 UI 的设计采取深思熟虑的方法。鼓励用户提供详细的反馈、提出问题并分享他们的交互背景有助于收集更细致和可操作的数据。此外,集成提示或问题来引导用户反思他们与 LLM 交互的特定方面,可以丰富数据集,提供关于模型行为、用户期望和潜在改进的有针对性的见解。这种方法不仅通过增强的训练数据集促进了 LLM 的直接改进 [16],而且还通过生成公开可用的Anon.数据集来为更广泛的人工智能研究领域做出贡献,这些数据集捕捉了广泛的人机交互。这样的数据集对于开发更符合人类需求、道德标准和社会价值观的模型非常有价值。
3.5 挑战和道德
考虑在我们探索这一新领域时,出现了几个挑战。确保用户贡献的真实性、激励利益相关者从用户分布的各个方面参与以减轻代表性损害、建立有效的审核系统以保持数据质量、确定社区投票的适当权重以及构建足够直观的用户界面以促进整个过程都是关键的考虑因素。此外,必须严格处理数据收集的道德影响、隐私问题以及对匿名敏感信息的机制的需求。将社交平台整合到大语言模型评估中,代表了我们理解和改进这些复杂系统的方法的重大进步。通过利用广泛用户群的集体智慧和多样化经验,我们可以开发更细致入微、更贴近情境、更符合道德规范的模型。这种范式转变不仅丰富了评估过程,而且使其更加民主化,为大语言模型发展营造了一个更具包容性和参与性的生态系统。
- 参考
[1] Yuvanesh Anand, Zach Nussbaum, Adam Treat, Aaron Miller, Richard Guo, Ben Schmidt, GPT4All Community, Brandon Duderstadt, and Andriy Mulyar. 2023. GPT4All: An Ecosystem of Open Source Compressed Language Models. arXiv:2311.04931 [cs.CL]
[2] Anthropic. 2024. Claude. https://claude.ai/
[3] Google. 2024. Gemini – chat to supercharge your ideas. https://gemini.google. com/
[4] Juho Hamari, Jonna Koivisto, and Harri Sarsa. 2014. Does gamification work?– a literature review of empirical studies on gamification. In 2014 47th Hawaii international conference on system sciences. Ieee, 3025–3034.
[5] Noriko Hara. 2008. Communities of practice: Fostering peer-to-peer learning and informal knowledge sharing in the work place. Vol. 13. Springer Science & Business Media.
[6] Mina Lee, Megha Srivastava, Amelia Hardy, John Thickstun, Esin Durmus, Ashwin Paranjape, Ines Gerard-Ursin, Xiang Lisa Li, Faisal Ladhak, Frieda Rong, Rose E. Wang, Minae Kwon, Joon Sung Park, Hancheng Cao, Tony Lee, Rishi Bommasani, Michael Bernstein, and Percy Liang. 2024. Evaluating Human-Language Model Interaction. arXiv:2212.09746 [cs.CL]
[7] oobabooga. 2024. oobabooga/text-generation-webui. https://github.com/ oobabooga/text-generation-webui original-date: 2022-12-21T04:17:37Z.
[8] OpenAI. 2024. ChatGPT. https://chat.openai.com/
[9] Nathan Schneider. 2019. Decentralization: an incomplete ambition. Journal of cultural economy 12, 4 (2019), 265–285.
[10] SillyTavern. 2024. SillyTavern/SillyTavern. https://github.com/SillyTavern/ SillyTavern original-date: 2023-02-09T10:19:24Z.
[11] Zirui Cheng Jiwoo Kim Meng-Hsin Wu Tongshuang Wu Kenneth Holstein Haiyi Zhu Tzu-Sheng Kuo, Aaron Halfaker. 2024. Wikibench: Community-Driven Data Curation for AI Evaluation on Wikipedia. arXiv preprint arXiv:2402.14147 (2024).
[12] Luis Von Ahn and Laura Dabbish. 2008. Designing games with a purpose. Commun. ACM 51, 8 (2008), 58–67.
[13] Open WebUI. 2024. open-webui/open-webui. https://openwebui.com/
[14] Lixiang Yan, Lele Sha, Linxuan Zhao, Yuheng Li, Roberto Martinez-Maldonado, Guanliang Chen, Xinyu Li, Yueqiao Jin, and Dragan Gašević. 2024. Practical and ethical challenges of large language models in education: A systematic scoping review. British Journal of Educational Technology 55, 1 (2024), 90–112.
[15] Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. 2024. Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in Neural Information Processing Systems 36 (2024).
[16] Chunting Zhou, Pengfei Liu, Puxin Xu, Srini Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, Lili Yu, Susan Zhang, Gargi Ghosh, Mike Lewis, Luke Zettlemoyer, and Omer Levy. 2023. LIMA: Less Is More for Alignment. arXiv:2305.11206 [cs.CL]
[17] Kun Zhou, Yutao Zhu, Zhipeng Chen, Wentong Chen, Wayne Xin Zhao, Xu Chen, Yankai Lin, Ji-Rong Wen, and Jiawei Han. 2023. Don’t Make Your LLM an Evaluation Benchmark Cheater. arXiv:2311.01964 [cs.CL]
RA/SD 衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/8872