
前言:
上一章,我们介绍了高手级别使用的一体化提示词插件,让我们像学会了九阳神功一般。
本章,我们介绍一个非常细的细节技术。让我们微调大模型的一些特性和能力。
在大模型的AI套路演化过程中,其实经历了太多的技术革新和方式变化,Embedding其实也可能是其中一个高速湮灭的技术点之一。
对比LoRA现在大红大紫,我们不得不面对众多技术细节点,在各个方向,不同阶段的优势和劣势。多了解下对你更好的使用AIGC有帮助。
知识点:
- Embedding模型使用
- 微调大模型


關鍵字的集合
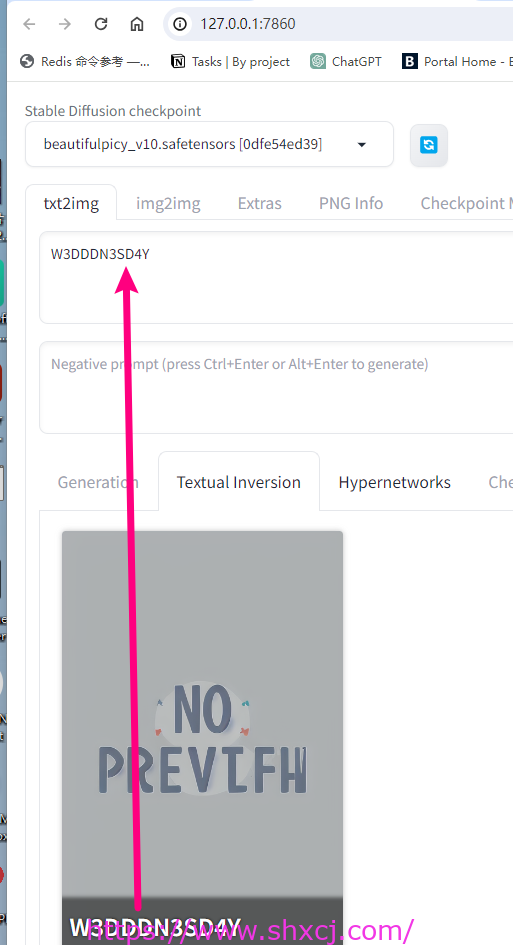
Embedding可以认为是一系列关键字的集合。
比如到C站下載一個Embedding類型的,放到SD根目錄下的embeddings目錄下,界面上刷新下就看到。點擊后在關鍵字這裏就出現了對應的ID。
自己創建Embedding
見下圖
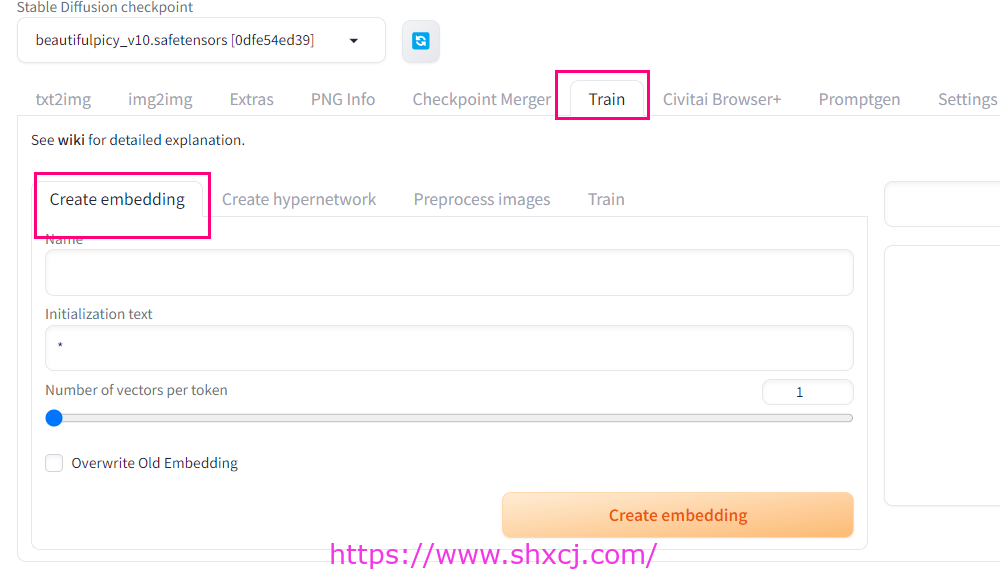
參數含義
- Name: filename for the created embedding. You will also use this text in prompts when referring to the embedding.
所创建嵌入的文件名。在引用嵌入时,您还将在提示中使用此文本。 - Initialization text: the embedding you create will initially be filled with vectors of this text. If you create a one vector embedding named “zzzz1234” with “tree” as initialization text, and use it in prompt without training, then prompt “a zzzz1234 by monet” will produce same pictures as “a tree by monet”.
初始化文本:您创建的嵌入最初将使用此文本的向量填充。如果您创建一个名为“zzzz1234”的向量嵌入,并使用“tree”作为初始化文本,并在提示中使用它而无需训练,则提示“a zzzz1234 by monet”将产生与“a tree by monet”相同的图片。 - Number of vectors per token: the size of embedding. The larger this value, the more information about subject you can fit into the embedding, but also the more words it will take away from your prompt allowance. With stable diffusion, you have a limit of 75 tokens in the prompt. If you use an embedding with 16 vectors in a prompt, that will leave you with space for 75 – 16 = 59. Also from my experience, the larger the number of vectors, the more pictures you need to obtain good results.
每个标记的向量数:嵌入的大小。此值越大,您可以在嵌入中容纳的主题信息就越多,但也会从提示限额中拿走更多的单词。在稳定扩散的情况下,提示中的标记数限制为 75 个。如果您在提示中使用包含 16 个向量的嵌入,则将为您留下 75 – 16 = 59 的空间。此外,根据我的经验,向量数量越多,获得良好结果所需的图片就越多。
官方指引文檔
https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Textual-Inversion
更为详细的解释有:
“embedding”是一个重要的概念,用于表示输入数据(例如文本或图像)的向量化表示。具体来说,embedding是一个将离散输入(如单词或图像的特征)转换为连续向量空间中的点的过程。这些向量捕捉了输入数据中的语义或特征信息,使得模型可以在这个连续空间中进行计算和推理。以下是有关Stable Diffusion中embedding的一些关键点:
- 文本嵌入(Text Embeddings):
- 在Stable Diffusion中,文本描述(如提示或标签)需要被转换为向量表示。通常,使用预训练的语言模型(如BERT、GPT等)将文本转化为向量,这些向量保留了文本的语义信息。
- 这些文本向量(embeddings)然后被输入到扩散模型中,指导图像生成过程。
- 图像嵌入(Image Embeddings):
- 类似地,图像的特征也可以被表示为向量。这些向量可以通过卷积神经网络(CNN)等深度学习模型来提取,捕捉图像的视觉特征。
- 图像嵌入可以在扩散模型中用于条件生成,即根据特定图像特征生成新图像。
- 条件生成(Conditional Generation):
- 在Stable Diffusion模型中,embedding用于条件生成(conditional generation)。这意味着模型不仅根据噪声生成图像,还根据输入的条件(如文本描述或图像特征)生成符合条件的图像。
- 条件生成过程中,模型将条件embedding与噪声向量结合,指导图像的逐步生成。
- 多模态嵌入(Multimodal Embeddings):
- Stable Diffusion可以处理多模态数据(即同时处理文本和图像)。在这种情况下,文本和图像的embedding可以被联合使用,以生成与文本描述一致的图像,或根据图像生成文本描述。
Embedding在扩散模型中的作用
在扩散模型(Diffusion Models)中,embedding的主要作用是提供附加的信息,使生成过程更加有条件和可控。扩散模型通过逐步去噪的过程生成数据(如图像),embedding在每一步去噪过程中提供指导,使生成的图像更符合输入条件。
实战在RA/SD中使用,效果情况如下:
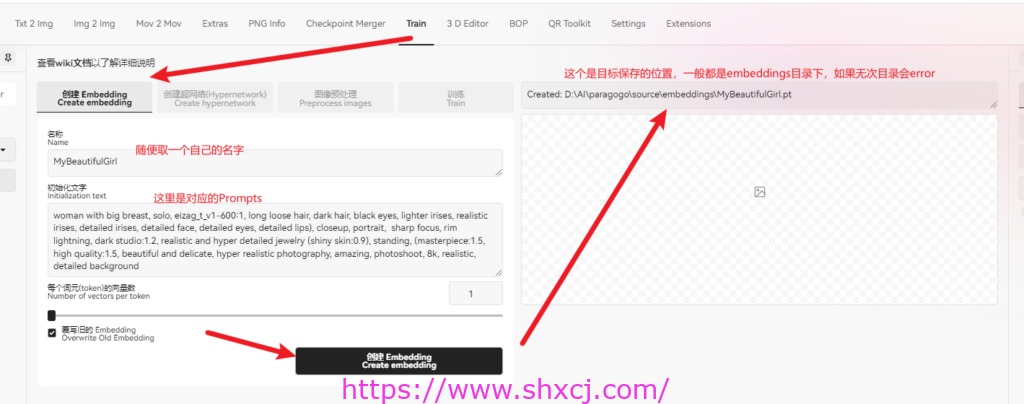
Textual Inversion 就是Embedding . 用一个名字,保存多个你的Prompts,后续用的时候方便。
创建方式如下:
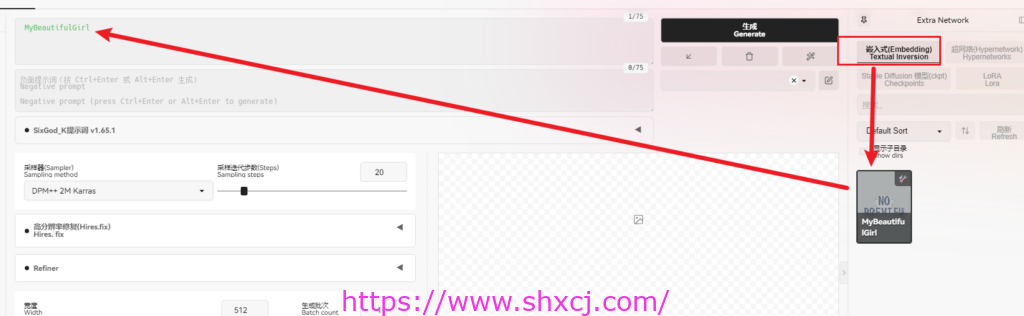
使用方式:
点选 Embedding内容, 双击使用即可。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/84