
前言
上一节课程中我们完成了训练SDXL-LoRA模型
本节,我们介绍下LoRA模型的评估和优化内容
通过测试我们可以对比大模型、不同阶段LoRA、迭代步数、采样方法等生图效果,从而帮助我们对比生成的模型,选择更好的LoRA模型。
本文知识点
- 为什么要做模型评估和优化?
- 参考Loss损失函数值
- LoRA模型的可用性和拟合度评估
为什么要做模型评估和优化?
1.1 最终的LoRA模型并非是最优秀的模型
我们每训练一个总轮次,都会有对应的数据和对应的模型保存下来,但是全部的总轮次跑下来之后,得到的最终的模型并非是最优秀的模型。
比如说我们训练总轮次是10次,设置每个轮次保存一个模型,那么就会有10个模型保存下来。
到底哪个模型好一些,我们需要经过测试评估才能知道。
就像给所有的模型设置一场考试,这10个模型同学统一参加这场考试,但是,考试的考点可能刚好是其中某几个模型同学熟知和擅长的,能够直接得到90分以上甚至100分。那你就能说剩下的模型同学就是差的吗?并不能,我们没办法只根据一场考试就给它们定性是否优良,最终的实际效果还是需要眼见为实。
1.2 防止模型出现过拟合或欠拟合的情况
我们之前讲过过拟合和欠拟合的情况,为了尽量避免这种情况对模型的质量影响,也需要通过模型评估和优化,做进一步处理。这里不再赘述。
1.3 方便自己,也为方便他人使用。
我们训练好的模型,自己需要使用,同时也可能会上传至某些AI平台分享给他人使用,一个调用性好、泛化性好的优秀LoRA模型很容易得到大家的认可和传播。
参考Loss损失函数值
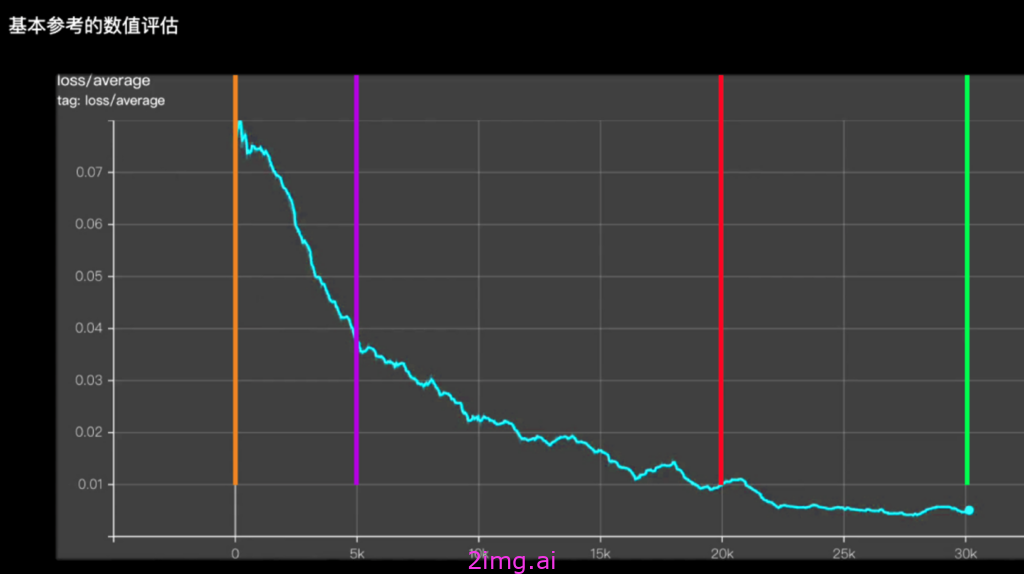

2.1 观察Loss损失函数值的变化。
如上图所示,假设训练总步数30K步,Loss损失值从总步数0-30K(X轴数据)的变化梯度一直在下降,但是:
0-5K步,可以看到下降坡度较陡,Loss损失值下降较快。
5K-20k步,可以看到下降坡度较缓,Loss损失值下降较为缓和。
20K-30K,可以看到下降基本成为平坡,Loss损失值基本躺平,不再下降。
如果理论上Loss值在0-1之间,我们希望Loss值越小越好。损失值越小,说明我们的模型越接近数据集中的素材图,当理论上Loss值为0时,就是没有任何损失,直接还原了我们的数据集素材,当理论上Loss值为1时,就是模型完全和我们的数据集素材没有关系。
但是实际情况中,我们无法做到Loss损失值降到0,也不会让它直接降到0。如果直接降到0或者接近0的结果就是,模型过拟合,无论如何调整参数和提示词,它只会出数据集中的图或者是崩坏的图。
因此,我们要注意Loss损失值躺平前或者接近0值之前的数据作为参考标准。如图中示例,就是0-20K步之间训练出的每个模型。
2.2 观察Loss损失函数值的数值。
再如上图所示,假设Loss值是从0.07-0(Y轴数据),它在5K步时降到了0.038左右,出现了一个大拐点,在20K步时降到了0.01,又出现了一个大拐点。那么每次出现大拐点的时候,说明机器模型在学习的过程中可能主动找到了一种更适合学习的方式。
通过学习方式的转变,它能够使得Loss损失值出现较大的波动,偏向更优秀的学习训练。
通过大量的LoRA模型训练数据和经验总结,一般人物训练Loss损失值最终降至0.07-0.09之间比较好一些,画风训练Loss损失值最终降至0.08-0.11之间好一些。
而在RA/SD中的LoRA模型的调用权重指数在0.6左右比较好一些,权重0.7-0.9可以尝试使用,权重1作为备用。如<LoRA:xxx:0.6>,指的是调用名称为xxx的LoRA模型,权重为0.6的情况下进行出图,可能就已经能够出很好的效果图了。
另外,如果训练时Loss损失值不降反升,最后出现Loss=NAN的情况怎么办?可能是因为机器模型学的太快了,需要降低unet学习率和文本编码学习率,可以先尝试降低一点学习率,不行,就再降低一点。
让我们再回到之前所述,Loss损失值的数据图参考只是模型测评的一部分,我们并不能通过这一次的训练结果就给出某个模型是其中的最佳模型。比如,你并不能说在20K步时所出的模型就一定比5K步时出的模型好,我们还要通过眼见为实进一步评测。
LoRA模型的可用性和拟合度评估
3.1利用XYZ轴脚本的出图效果观察和对比进行评估
对比不同版本LoRA模型和不同权重下的出图效果。如果是训练的真实人物LoRA模型,就选用一个真实性大模型底模,如果训练的是二次元LoRA模型,就选用一个二次元大模型底模,画风亦是如此。
接下来的操作教程,才是我们的模型测评过程,要重点记忆的:
版本号和权重也可以用其他字母代替。
- 迭代步数、采样方法等其他参数保持不变。
- 如上图所示,找到最下方的“脚本”——“XYZ图表”。
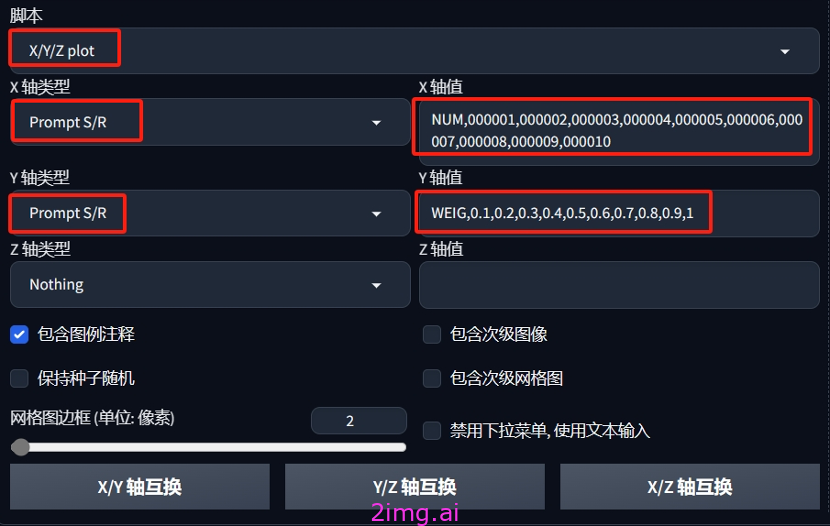
- 如上图所示,将X、Y轴类型均设置为Prompt S/R模式(Z轴类型保持默认Nothing不变)。
- 将后面对应的X轴值写为:
NUM,000001,000002,000003,000004,000005,000006,000007,000008,000009,000010,这里的分割逗号为英文输入法下的逗号。即X轴的值代表了我们需要测试的每个LoRA模型版本号,需要依次输入NUM+对应的版本号。
- 将后面对应的Y轴值写为:WEIG,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1,这里的分割逗号也是英文输入法下的逗号。即Y轴的值代表了我们需要测试的每个LoRA模型版本的权重值,需要依次输入WEIG+对应的权重值。
- Z轴值保持默认空及下面其他参数保持默认即可。
- 网格图边框(单位:像素):指每张示例图之间的空白间隔,可以保持默认0,可以调节为2或者5,让每张图之间保持2或者5个像素单位空白间隔。
- 所有的参数设置完成后,即可直接点击“生成”,预览XYZ脚本测试模型出图效果了。
这里要提醒一下,最终的测试图会将所有的出图效果汇总至一张图中,所以需要等待一段时间(设备性能一般的同学可能等待的时间会更长,有的甚至要2-4个小时左右),才能看到最终的测试结果。因此,根据以往的数据和经验总结,NUM1-3版本测试模型下的WEIG0.1-0.4权重值,大多会出现崩图或者欠拟合的图。这里建议大家如果是训练了10个轮次的模型,可以用下面的数据作为参考:
X轴值设置为:NUM,000004,000005,000006,000007,000008,000009,000010
Y轴值设置为:WEIG,0.5,0.6,0.7,0.8,0.9,1
即我们只测试第4-10个版本模型下的0.5-1的权重范围效果图,这样可以省去很多跑图测试时间。
最终的测试图结果剖析
最终的测试图结果如下所示:

从图示中可以看到:
白色框选区域之外的测试图,有的是LoRA色彩风格基本不明显,有的是出现了严重的崩图,我们直接将此区域的测试模型毙掉。
白色框选区域内:LoRA色彩风格已经明显作用于效果图中。
黄色框选区域内:随着权重值的提高,LoRA模型风格开始更加清晰明亮,特别是人物头发细节已经明显多起来。
红色框选区域内:当前权重值为0.6时,LoRA风格较为明显,而且人物表现较好。
0.7和0.8权重区域:人物已经出现略微的崩脸,但是因为我们只是512px小尺寸的批量测试效果图,后期跑大图或者开启高清修复基本上崩图的概率是很小的。因此0.7和0.8的权重值也在我们考虑留用的范围内。
由此可以得出:
000005-000010这5个版本的LoRA模型都可以使用,可以从这5个版本中选出一个你最满意的作为最终LoRA模型。
权重值推荐0.6,0.7-0.8可以尝试,0.9-1备选。
另外,在测试图中基本都出现了红色头发的人物,确定模型的泛化性比较好。
我们直接毙掉那些不适用的模型版本之后,你可以保留剩下的所有符合预期的待选模型,直接在SD中通过不同的模型版本和不同的权重值以及不同的采样方法,直接再次测试效果图。也可以在待选的版本中直接选择其中一个作为最终的LoRA模型,其余的全部删除即可。
如果你感觉最后的成品模型附带着版本号00000X不简洁,也可以直接更名为文件名称即可,如dreamgirl.safetensors,那么在SD中调用此LoRA模型时,显示的应是<LoRA:dreamgirl:0.6>。
最终LoRA模型调整优化建议
| 问题现象 | 主要原因 | 优化建议 |
| 异常特征多、崩图坏图多 | 素材质量分辨率低,出图尺寸过大,训练次数少。 | 优化图片素材质量分辨率,删除劣质充数的素材图片,增加训练次数。 |
| 素材特征少、相似度低 | 欠拟合,训练素材少,训练次数少,标签处理有问题。 | 增加训练素材,提高训练次数,修改优化标签。 |
| 泛用性弱,无法调整 | 过拟合,训练素材相似或单一。标签处理有问题 | 丰富素材图种类、角度等,修改优化标签。 |
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/8399