
前言
上一节课程中介绍下面我们就进入到数据集预处理步骤的实操阶段。 介绍5种超好用的tag工具,下面我们就开始介绍如何训练LoRA模型。·
如果电脑配置完全符合炼丹需求的同学,可以直接在自己电脑上本地训练,当然我们还可以有一些其他的常用线上炼丹平台(如AutoDL-AI算力云,阿里云、青椒云等),这类在线租用服务器主机,一般几毛钱-2元多/小时就可开始炼丹。
知识点
- Lora模型的训练
实战
1.开始训练
目前网上有很多训练LoRA的项目,比如Koyha_ss,LoRA_Easy_Training_Scripts等。由于只是训练LoRA的任务,故不需要掌握所有训练LoRA的项目,这里仅介绍下lora-scripts训练Lora的方式。
1 参考训练Lora选择kohya_ss项目,支持win平台
这里我们提供 离线下载包:
在中国区的用户,首先运行install-cn.ps1 ,其余地区运行install.ps1
打开powershell.exe程序,执行


如果遇到执行脚本错误,请以管理员权限打开Power Shell,执行set-ExecutionPolicy RemoteSigned ,在提示后输入Y,即可。
安装完成后,执行run_gui.ps1
如果一切成功,会自动拉起页面,见下图:
http://127.0.0.1:28000/lora/basic.html
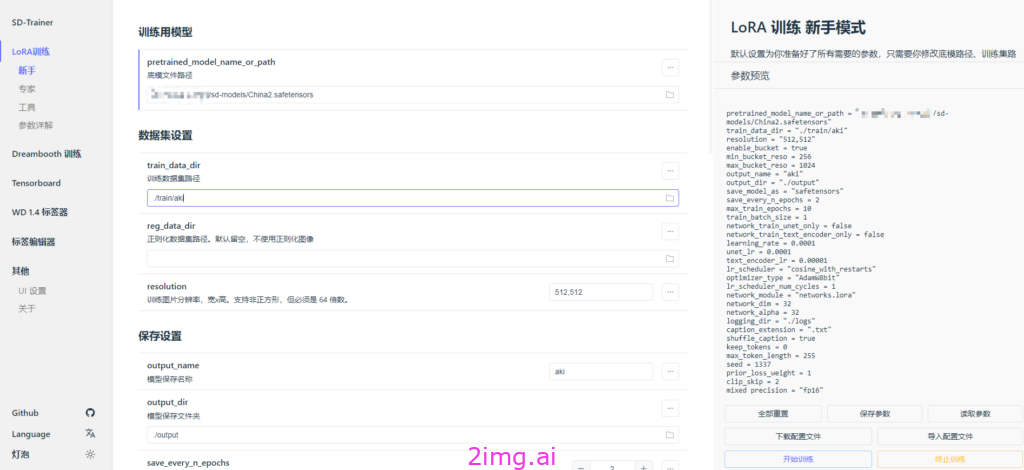
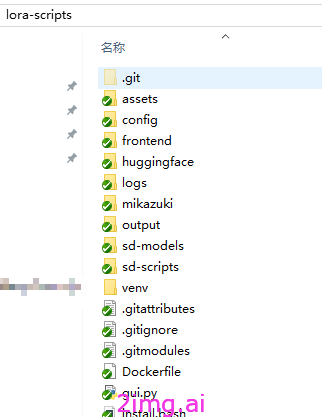
进入到“lora-scripts”文件夹内,其中:
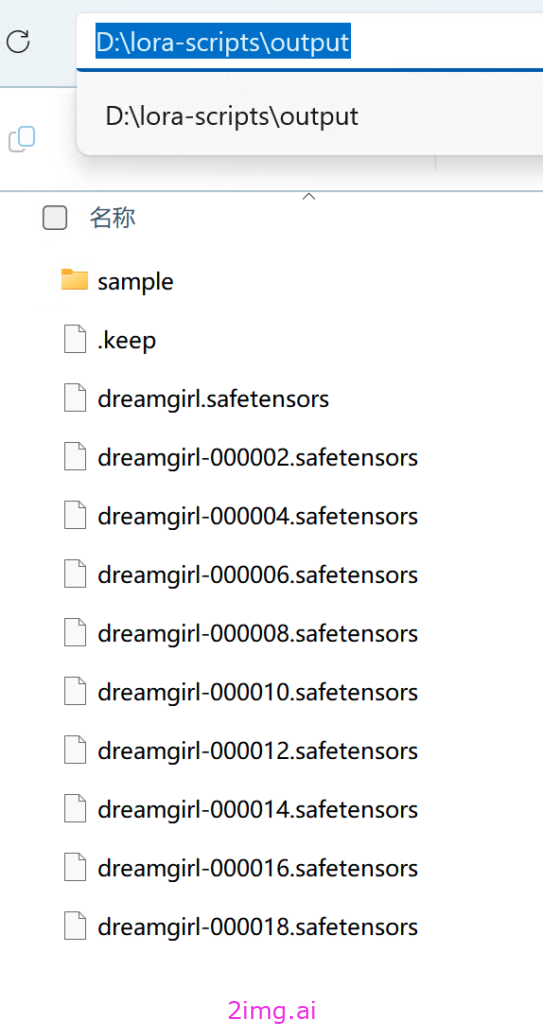
output文件夹:训练好的每一轮Lora模型会自动存放在此文件夹内。
sd-models文件夹:将训练使用的大模型底模上传至此文件夹内。(如下图所示)
2 准备数据集
在train文件夹下创建文件夹,再创建文件夹,命名:数字_名字。数字代表图片重复次数,一般5-8,例如8_girl;之后将训练的数据集拖进来
数字值的含义代表每张素材图的训练步数。越精细的图,Repeat 值也越高,一般二次元可以 15-30,三次元可以 50-100
train文件夹:此文件夹内需再次新建两个上下级的文件夹,然后将预处理好的数据集(包括素材图和Tag标签文本)上传至最后一个文件夹内。(如下图所示)
注意,这里要特别说明下train文件夹的使用,是需要重点关注的!
- 首先在此train文件夹中新建一个文件夹,可以命名为要训练的模型名称,比如我们命名为dreamgirl文件夹。
- 然后在dreamgirl文件夹中再次新建一个文件夹,注意!注意!注意!
这个新建的文件夹的名称必须是“数字_文件夹名称”的格式!而这个数字特别关键,它就是代表我们每张素材图要训练的次数。
比如示例图中是“30_dreamgirl”,即表示我们每张素材图要训练30次。
“35_dreamgirl”,即表示我们每张素材图要训练35次。
数字值的含义代表每张素材图的训练步数。越精细的图,Repeat 值也越高,一般二次元可以 15-30,三次元可以 50-100。
另外,文件夹名称不允许有空格和特殊字符出现!否则,训练时会出错。
最后将我们原先准备好的数据集中的素材图和Tag标签文本直接全选,复制粘贴进“30_dreamgirl”文件夹中即可
(或者直接全选用鼠标拖进来也可以,线上不支持直接传输文件夹)。
3 基础设置train.sh 进行编辑参数,不知道的话默认就可以

参数说明:
1train_data_dir:训练集输入目录,把之前建立的数据集文件夹路径复制过来,如/content/drive/MyDrive/Lora/input。
底模:填入底模文件夹地址 /content/Lora/sd_model/,刷新加载底模。
2resolution:训练分辨率,支持非正方形,但必须是 64 倍数。一般方图 512×512、768×768,长图 512×768。
3batch_size:一次性送入训练模型的样本数,显存小推荐 1,12G 以上可以 2-6,并行数量越大,训练速度越快。
4max_train_epoches:最大训练的 epoch 数,即模型会在整个训练数据集上循环训练的次数。如最大训练 epoch 为 10,那么训练过程中将会进行 10 次完整的训练集循环,一般可以设为 5-10。
5network_dim:线性 dim,代表模型大小,数值越大模型越精细,常用 4~128,如果设置为 128,则 LoRA 模型大小为 144M。
6network_alpha:线性 alpha,一般设置为比 Network Dim 小或者相同,通常将 network dim 设置为 128,network alpha 设置为 64。7角色lora轮次((max_train_epoches))多一点。建议20;风格lora只要存的图足够多,建议12
总结:
- 针对需要泛化性比较好的模型训练,可以选择SD原始基础底模系列。
- 针对和某个大模型配合使用的模型训练,可以选择需要配合使用的那个大模型作为底模。
- Train_data_dir=“./train/dreamgirl”:训练数据集路径名称。
重点注意一下这里,我们之前将所有的素材图和Tag标签文本放在了“train”文件夹——“dreamgirl”文件夹——“30_dreamgirl”文件夹内,但是这里我们只需要将路径名称写到“dreamgirl”文件夹这一层即可,即标注每张图片训练次数文件夹的上一层文件夹。如果将路径名称直接写到“30_dreamgirl”文件夹这一层,训练时会报错! - Network_dim=128:训练网络维度,常用建议最大设置128,其他还有64、32。但是并不是设置越大越好,如果学习内容比较复杂,可以设置128甚至更高,但还需根据实际情况选择。网络维度越大,学习细节越多,学习速度越慢,学习时间越长,但是容易出现图片过拟合的情况。网络维度越大,模型体积越大,比如设置为32,对应Lora模型最终体积可能出到44M大小,设置为128,可能会出到144M大小。
- net_work_alpha=64:一般设置为训练网络维度的一半或者相同数值即可。比如Network_dim=128,net_work_alpha=64或128。
- batch_size=1:批次处理值,可以理解为每次训练同时选取的素材数,建议不超过3。比如总训练步数有1万步,那么batch_size=1,就还是训练1万步,batch_size=2,总训练步数就变成了5千步。
总结:
(1)batch_size值越小,学习越精细,学习速度越慢,但是收敛越慢也越难。收敛可以简单的理解为,模型训练过程中最终趋于稳定的一个阈值或者状态。
(2)batch_size值越大,学习跨度越大,学习速度越快,但是学习也越不仔细,而且由于同时处理的任务数变大,所以对电脑计算配置要求变高,可能会导致始终找不到最优值,最终模型泛化性越差。
(batch_size变大会将训练步数减少,可能会提前到达一个拟合点,如果继续用较小的学习率,可能始终找不到最佳收敛点,导致过拟合。因此学习率也需要对应增大,以适应提前结束学习。)
- max_train_epochs=10:总训练轮次数值,10即表示总共训练10轮。设置过大,容易过拟合,导致最终模型失去泛化性,一般建议5-20轮即可。
- lr=“1e-4”:学习率值,可以理解为学习的速度,速度太快可能会不仔细,速度太慢又可能耗费时间,建议初次训练保持默认即可。当设置了以下unet_lr和text_encoder_lr两个参数时,此值失效。
- unet_lr=“1e-4”:UNet学习率,同上。1e-4=0.0001,即1*10的-4次方。建议初次训练保持默认即可。
batch_size和学习率的关系需要注意一下:
当你需要调节batch_size的值时,对应的学习率也应该调节,一般是batch_size的值乘以N倍时,对应的学习率也应该乘以N倍。但是并不是绝对,还是要根据素材数量、质量等实际情况修改调节学习率参数值。比如原来是batch_size=1,unet_lr=“1e-4”,现在要调节为batch_size=2,unet_lr=“2e-4”去做训练时,出现了“Loss=NAN”,那就不合适,需要调节学习率或调整数据集。
- text_encoder_lr=“1e-5”:文本编码器学习率。1e-5=0.00001,即1*10的-5次方。一般设置为unet学习率的1/2或者1/10,建议初次训练保持默认即可。
- optimizer_type=“Lion”:优化器选择,还可以使用默认的AdamW8bit。
- output_name=“dreamgirl”:模型保存名称。训练完成后,在SD软件中调用Lora模型时会以<lora:dreamgirl:1>的形式出现。
- save_models_as=“safetensors”:模型后缀名称。其他还有ckpt、pt。建议使用safetensors作为后缀。如:“xxx.safetensors”模型。
4 启动训练脚本
输入bash train.sh。之后等待。。
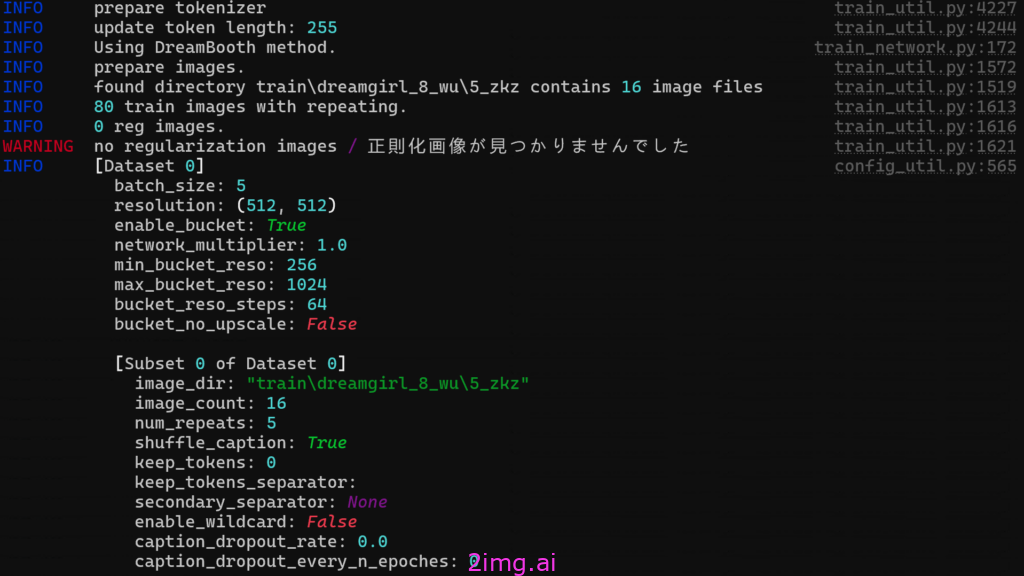
结束后
模型训练过程中的注意事项
1、训练底模可能会报错
我们训练Lora模型前,会提前上传训练用的大模型底模至sd-models文件夹中备用,可以上传一个,也可以选择需要的一次性全部上传。建议选择两三个常用的底模大模型上传即可,比如一个SD1.5系列底模、一个真人大模型、一个二次元大模型。上传过多的话,可能有些很长时间都用不到,还一直占用数据盘内存。
如果训练过程中提示大模型底模出错,可以查看train.sh配置文件中的底模路径(其他路径设置也要检查)是否填写正确。如果检查后路径填写正确但是依然报错,可以选择本地的此底模重新再上传一次,一般都能解决。
总结:
A、检查train.sh配置文件底模路径是否正确。
B、重新上传大模型底模。
2、文件名可能会报错
文件夹和文件夹内的文件,一般以英文字母或英文字母加下划线的形式命名。不允许有空格以及特殊字符出现(比如*、#等),否则会报错。
注意以上两点,然后按照教程操作,就可以直接训练Lora模型了。
3、训练核心数据
但是,就目前为止,不建议直接开始训练,还是要学习完后面的课程之后,再进行训练操作,因为后续的课程中有一期是直接带领大家去训练出一个人物和一个画风的模型,包括了训练数据的参考标准总结和经验,这也是帮你省钱省时间省精力的精髓。
在课程前言我们也提到过,如果你直接开始训练,可能会不停的调整训练参数,比如素材图质量、数量、训练轮次等,一轮又一轮,一次又一次的不停调试,观察每一次的Loss损失函数值和其他数据,那么这就是一个耗费时间和精力以及金钱的过程。就像现在,这段文字我告诉你,只需三五秒钟的时间,但是实际过程中,你可能要花费三五天的时间甚至一个星期才能调整到自己满意的一个数据状态。因此,如果有了后续的一期数据总结教程作为参考标准,那么参考这个数据总结标准,你就可以直接调整参数进行训练,尽可能一次性的完成达标训练了。这也是为什么很多人在网上看了很多lora模型训练教程,到了自己实操时依然训练不好的原因。实际上你只是跟着其他人学会了如何去训练lora模型的整体大概流程,而训练数据总结的一个核心参考标准并没有给到你。但是参考标准也只是参考标准,每个人训练的模型都是千差万别的,要学会在参考标准的基础上,举一反三,总结自己的训练经验,才能更加深入的了解、训练和运用模型。
RA/SD 衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/8390