
微软又爆 “大瓜”,GPT 参数意外泄露


最近,AI 圈被微软投下的一颗重磅炸弹 “炸开了锅”。在一篇看似普通的论文里,微软竟意外曝光了 GPT 的核心机密 ——4o-mini 只有 8B,o1 也才 300B!此消息一出,瞬间在业界掀起惊涛骇浪,大家纷纷惊愕不已,这就好比是在一场魔术表演中,魔术师突然亮出了底牌,让所有人都猝不及防。
要知道,OpenAI 的 GPT 系列模型一直以来都蒙着一层神秘面纱,特别是关乎模型性能的关键指标 —— 参数量,犹如被藏在保险箱里的宝藏,外界只能凭借各种蛛丝马迹猜测一二。此前,GPT 系列凭借超强的语言处理能力,在问答、文本创作、翻译等诸多领域大显神通,大家都默认其背后必然是有着成百上千亿的参数做支撑。可如今微软论文披露的这组数字,却与人们心中的预设大相径庭,仿佛给 GPT 这个 AI 巨头揭开了一个意想不到的 “小角”。 那么,这些数字究竟意味着什么?为何会引发如此广泛的关注与热议呢?
微软论文究竟说了啥?

研究的初衷与背景
这事儿还得从论文本身的研究说起。微软和华盛顿大学的研究团队把目光聚焦在了医疗领域,为啥是医疗呢?原来,据美国医疗机构调查,有 1/5 的患者在阅读临床笔记时会发现错误,40% 的患者觉得这些错误可能影响治疗,这可不是个小问题。与此同时,大语言模型(LLM)在医学文档任务里用得越来越多,像生成诊疗方法之类的。但这里面有个大麻烦,LLM 容易 “幻觉”,输出些虚构或错误信息,这在医疗里可是要命的,一字之差可能就关乎生死。
为了解决这个难题,微软引入了一个全新的基准 ——MEDEC,这可是首个公开的临床笔记医疗错误检测和纠正基准。它涵盖了诊断、管理、治疗、药物治疗和致病因子这五种错误类型,数据从三家美国医院系统收集了 3848 份临床文本,其中 488 份临床笔记之前没被任何 LLM 见过,还由 8 位医疗人员精心参与错误标注,就是为了确保数据真实可靠,能让 LLM 在医疗领域用得更靠谱。
实验环节 “暗藏玄机”
在实验环节,研究团队为了检测和纠正医疗错误,精挑细选了近期主流的大模型和小模型,像 o1-preview、GPT-4、Claude 3.5 Sonnet、Gemini 2.0 Flash 等等,让它们上场 “比试” 一番。可谁能想到,就在介绍这些模型的时候,“意外” 发生了 —— 模型参数、发布时间等关键信息,就这么明晃晃地被公开了。虽说论文后面也有免责声明,讲确切数据尚未公开,大部分数字是估计的,但这就像在平静湖面投下巨石,大家心里都泛起了嘀咕:这些数据到底准不准?为啥谷歌 Gemini 模型参数就没放出来?难不成微软对这些数据心里有底,就故意的? 而且微软可不是初犯,早在 2023 年 10 月,就曾在论文里 “不小心” 曝出 GPT-3.5-Turbo 模型的 20B 参数,后来又悄悄删掉,这操作实在是让人浮想联翩。
关键数字背后:GPT 模型参数详解
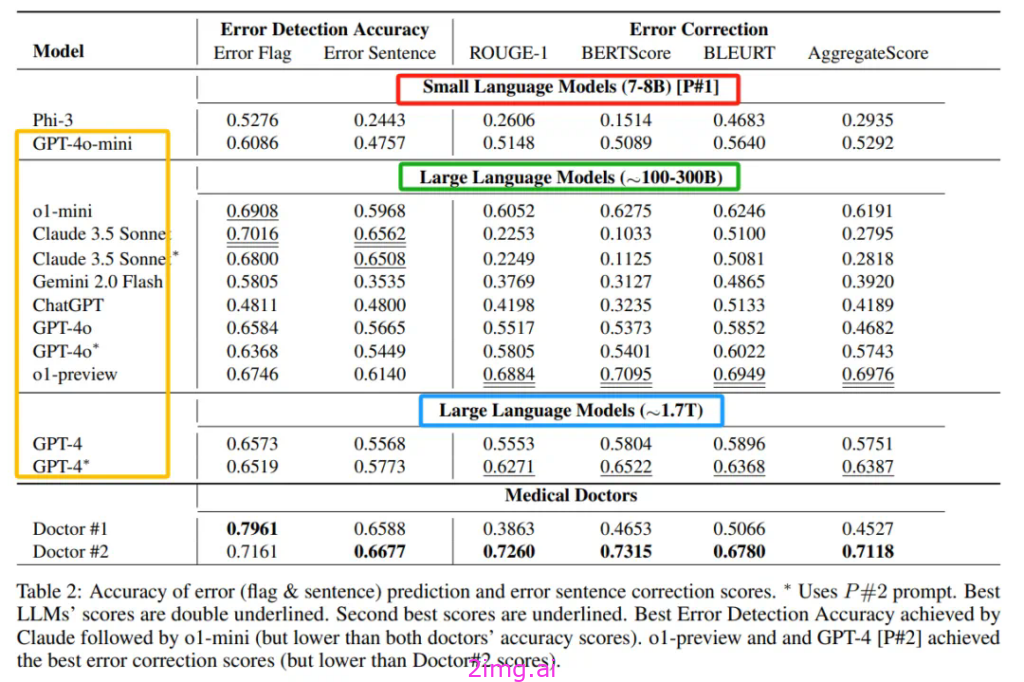
GPT-4o-mini 仅 8B?网友惊掉下巴
当看到 GPT-4o-mini 的参数只有 8B 时,网友们的第一反应是震惊与质疑。毕竟,在大家的认知里,能展现出如此强大语言能力的模型,怎么可能仅靠这点参数就能实现呢?有人甚至调侃道:“这就好比说一辆超跑只用了摩托车的引擎,却跑出了赛车的速度,太不可思议了!”
从模型性能角度来看,此前 GPT-4o-mini 在多项测试中的表现可圈可点。在 MMLU(大规模多任务语言理解)测试里,它斩获了 82.0% 的高分,远超同类小模型;在 MGSM(数学与通用科学模块)测试中,更是以 87.0% 的成绩一骑绝尘。这就引发了一个疑问:如果真的只有 8B 参数,它是如何做到在复杂知识问答、数学推理等诸多领域都表现优异的呢?
有专业人士猜测,GPT-4o-mini 或许采用了 MoE(混合专家模型)架构。这种架构下,模型虽然总体参数看似不多,但在运行时能够根据任务需求,灵活调用不同的 “专家模块”,就像一个拥有多个专业智囊团的指挥官,面对不同难题能迅速派出最合适的专家解决,从而在有限参数下实现高效能。而且,从推理成本的角度推算,有网友发现 4o-mini 的价格是 GPT-3.5-Turbo 的 40%,倘若之前 GPT-3.5-Turbo 的 20B 参数属实,那么按照比例,4o-mini 刚好在 8B 左右,这似乎又为其参数的真实性增添了几分可信度。 但即便如此,仍有不少人持观望态度,毕竟没有得到 OpenAI 的官方确认,大家都不敢轻易下定论。
o1 系列:o1-preview 约 300B 的影响力
再看 o1-preview 约 300B 的参数,这一数字同样引发了诸多讨论。在大模型的世界里,300B 参数虽然比不上 GPT-4 那令人咋舌的 1.76T,但也绝不容小觑。o1 系列模型自推出以来,就凭借独特的强化学习训练方式备受关注,特别是在推理能力上,仿佛被赋予了 “深度思考” 的技能,面对复杂问题时,能够层层剖析,给出逻辑缜密的回答。
在实际应用场景中,300B 参数的 o1-preview 展现出了很强的适应性。以科研领域为例,科研人员在探索前沿课题时,需要查阅海量文献、整合复杂知识,o1-preview 能够快速理解专业文献中的术语、理论,帮助科研人员梳理研究脉络,提供创新性思路;在软件开发领域,面对代码调试、算法优化等难题,它可以像经验丰富的程序员一样,给出精准的代码建议,助力开发者提高效率。而且,相比一些超大规模模型,o1-preview 在资源占用和推理速度上找到了较好的平衡,对于一些算力并非顶级充裕的企业和研究机构来说,它提供了一个高性价比的选择,让更多人能够享受到先进 AI 模型带来的便利,推动 AI 技术在更多领域落地生根。 所以,这看似 “仅仅” 300B 的参数,实则蕴含着巨大的能量,正在悄然改变着多个行业的创新模式。
行业震荡:各方反应不一

网友热议:炸开了锅
此消息一经传出,网友们瞬间 “炸开了锅”,社交平台上相关话题热度飙升。有的网友开启 “脑洞模式”,调侃道:“难道 GPT 是掌握了什么‘模型压缩神功’,用这么少参数就‘称霸武林’?” 还有人化身 “技术侦探”,根据微软过往 “前科”,大胆揣测:“微软这是又手滑了,还是故意为之,想给 OpenAI 来个下马威?” 质疑声也此起彼伏,不少人坚称:“以 GPT 展现出的实力,绝不可能仅靠这点参数,肯定还有未曝光的‘黑科技’。” 甚至有人担忧:“这参数一泄露,OpenAI 的技术壁垒是不是要被打破了,未来 GPT 还能保住‘王座’吗?” 大家你一言我一语,让这场讨论愈发白热化,仿佛一场没有硝烟的 “参数大战” 正在网络世界激烈上演。
OpenAI 沉默,竞争对手暗窥
处在舆论漩涡中心的 OpenAI 却出奇地保持沉默,未对微软论文披露的参数信息做任何回应。这一态度更是让外界猜测纷纷,有人说 OpenAI 是在暗中评估此次泄密的影响,筹备 “反击策略”;也有人认为他们可能是默认了数据的真实性,只是需要时间调整宣传口径。
与此同时,OpenAI 的竞争对手们可没闲着。Anthropic 团队看到 Claude 3.5 Sonnet 在论文实验里表现不俗,似乎看到了赶超的曙光,开始加大研发投入,计划在后续版本里进一步优化模型性能,抢占市场份额;谷歌的研究人员则抓紧时间重新审视 Gemini 模型的参数设置与架构设计,试图从这场参数泄密风波中汲取灵感,找到突破点,让 Gemini 在未来的竞争中脱颖而出。整个 AI 行业犹如平静湖面下暗流涌动,一场围绕模型参数与技术创新的激烈角逐,已然悄然拉开帷幕。
科研界反思:数据保密之重
科研界也因微软这次 “意外” 陷入了深深反思。一方面,大家意识到在追求学术成果与技术突破的道路上,数据保密如同 “生命线”。顶尖科技公司耗费大量心血研发的模型参数,一旦过早泄露,不仅可能使前期研发投入打折扣,更可能打乱技术迭代的节奏,让竞争对手有机可乘。像微软这样的行业巨头,接连出现参数泄露事件,无疑为所有科研团队敲响了警钟。
另一方面,伦理规范的问题也被再次摆上台面。大语言模型在医疗、金融、教育等诸多关键领域的应用日益广泛,其输出结果关乎民生、经济乃至社会稳定。倘若模型的构建、训练数据以及参数设置等关键信息缺乏透明度与规范性,一旦出现偏差、错误甚至恶意利用,后果不堪设想。科研人员纷纷呼吁,未来在 AI 研究领域,亟需建立更严格、更完善的数据保护机制与伦理审查体系,确保每一项创新成果既能推动科技进步,又能保障公众利益与社会福祉,让 AI 真正成为造福人类的 “利器”,而非引发混乱的 “潘多拉魔盒”。
未来展望:参数揭秘后的 AI 路在何方?

此次微软论文意外曝光 GPT 核心机密,无疑给 AI 行业的未来发展带来了诸多变数。一方面,从技术走向来看,模型参数的 “神秘面纱” 被揭开一角后,或许会引发更多科研团队对大模型架构的深度探索。MoE 架构因 GPT-4o-mini 的出色表现备受瞩目,未来可能会有更多变体或优化版本涌现,促使 AI 模型在有限算力下实现更高性能,加速 AI 技术普惠大众的进程。另一方面,在产业格局上,OpenAI 面临着前所未有的挑战与机遇,如何应对参数泄露后的舆论风波、巩固技术优势,成为其亟待解决的问题;而竞争对手们则虎视眈眈,企图借此东风弯道超车,未来 AI 巨头之间的竞争必将愈发白热化。
在应用拓展层面,随着人们对模型性能与参数关系有了新认知,医疗、教育、金融等行业在引入 AI 技术时,将不再单纯迷信参数规模,而是更注重模型与实际场景的适配性,推动定制化、专业化 AI 应用落地生根。但与此同时,监管的难题也随之而来,如何确保模型开发、数据使用遵循伦理规范,保障公众权益,需要政府、科研机构与企业携手共进,构建完善的监管体系。
总之,这场由微软论文引发的 “参数风暴”,既是 AI 行业发展长河中的一次剧烈震荡,也是促使各方重新审视、砥砺前行的契机。未来 AI 之路充满挑战,但相信在全球科研人员与从业者的共同努力下,AI 必将朝着更加稳健、有益的方向蓬勃发展,为人类社会开启更加绚丽多彩的智能篇章。让我们拭目以待,持续关注这场 AI 变革中的每一个精彩瞬间。

RA/SD 衍生者AI训练营。发布者:風之旋律,转载请注明出处:https://www.shxcj.com/archives/8329