
DeepSeek-V3 横空出世,开源界的 “超级核弹”

最近,科技圈被一颗 “重磅炸弹” 炸翻了天,国产大模型 DeepSeek-V3 重磅开源,瞬间在海外社交媒体上掀起惊涛骇浪,X(原推特)上相关话题热度飙升,讨论帖如雪花般纷飞,从技术大拿、科研精英到普通 AI 爱好者,无一不被其吸引,纷纷加入这场热议狂欢。这股热潮也如旋风般迅速刮回国内,各大科技社区、论坛瞬间被 DeepSeek-V3 的帖子 “霸屏”,所有人都在问:这个 DeepSeek-V3 到底什么来头?
性能卓越,比肩 GPT-4o 的 “国货之光”
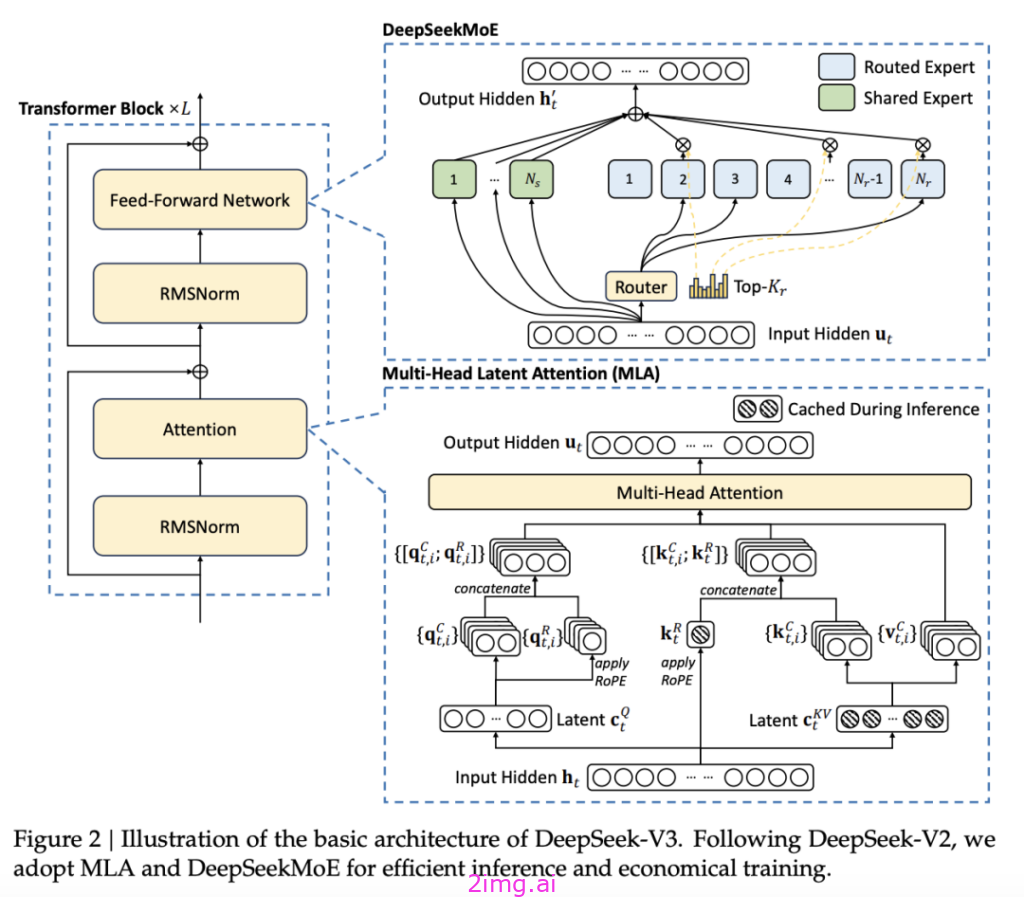
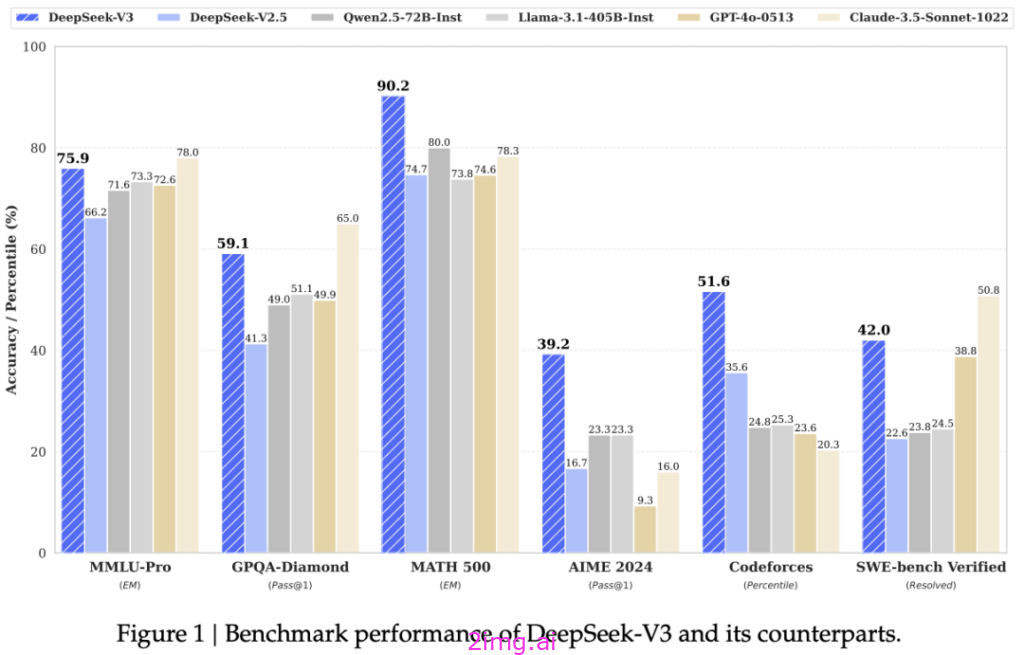
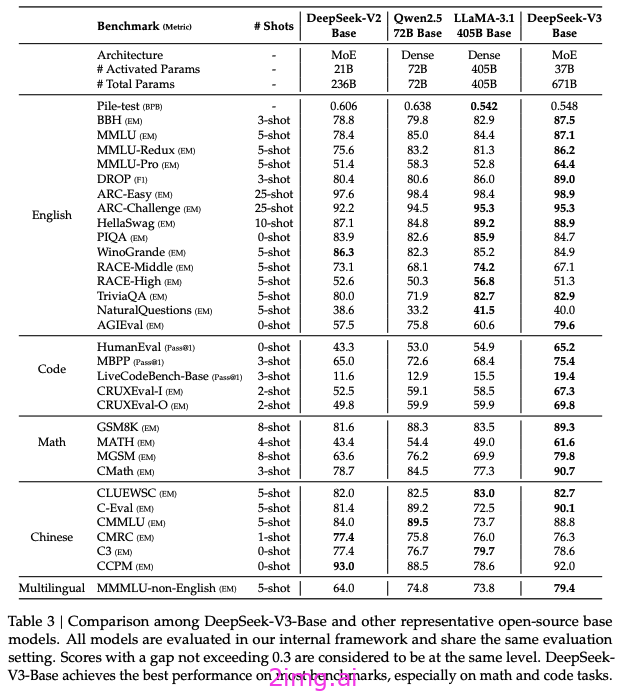
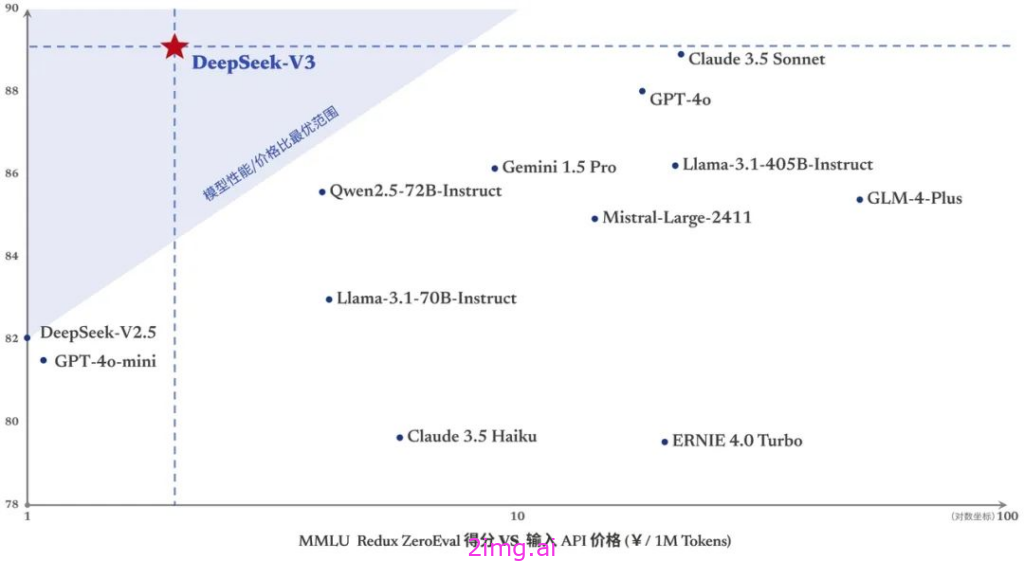
DeepSeek-V3 可不是徒有其表,多项评测成绩彰显出其 “硬实力”。在知识领域,基于教育类基准测试如 MMLU、MMLU-Pro 和 GPQA,它分别取得了 88.5、75.9 和 59.1 的高分,将一众开源模型远远甩在身后,与 GPT-4o、Claude-Sonnet-3.5 等闭源大模型的差距也微乎其微,这意味着在知识储备与理解运用上,DeepSeek-V3 已站在了行业前沿,能为用户提供精准、深入的知识解答,无论是学术探讨、专业学习还是日常知识拓展,都能轻松应对。
事实性知识测试中,在 SimpleQA 和中文 SimpleQA 两个基准上,DeepSeek-V3 领先开源同行。英文事实知识测试里虽稍逊 GPT-4o 和 Claude-Sonnet-3.5 ,但中文事实知识板块却表现强劲,对中文语境知识的精准把握,让它在服务中文用户时更具优势,像回答中国历史文化、时事热点相关问题时,答案准确又详实。
再看代码、数学与推理领域,DeepSeek-V3 更是 “大杀四方”。数学相关基准测试里,在所有非长链式思维的开源和封闭模型中,它一骑绝尘,特定基准如 MATH-500 中,成绩甚至超过 OpenAI o1-preview,面对复杂数学难题,能快速给出逻辑清晰的解题步骤。编程相关任务中,编程竞赛基准 LiveCodeBench 上它表现最佳,工程相关任务虽略逊 Claude-Sonnet-3.5 ,但远超其他模型,生成的代码不仅功能性强,注释、算法解释、开发流程指引还十分全面,对程序员来说,就像身边随时有个资深导师,助力代码编写事半功倍。整体对比下来,DeepSeek-V3 明显超越 Llama-3.1-405B 和 Qwen 2.5-72B 等主流开源模型,多数测试里,连 GPT-4o 都甘拜下风,唯有在专注英语的 SimpleQA 和 FRAMES 测试中,GPT-4o 以微弱优势领先,不过在中文和数学类测试里,DeepSeek-V3 依旧是毫无争议的王者,用实力重新定义了国产大模型的高度。
557 万美元创奇迹,低成本的 “逆袭密码”

DeepSeek-V3 令人惊叹的可不止是性能,还有它那低到超乎想象的训练成本。仅 557 万美元的总训练成本,相较于动辄数亿美元投入的业界巨头,简直就是 “白菜价”。它是怎么做到的呢?
技术架构上,DeepSeek-V3 采用混合专家(MoE)架构,这种架构就像是一个 “智能资源分配器”,面对不同任务,能精准激活特定参数模块,避免资源浪费,让每一分算力都花在刀刃上。如处理文本生成任务时,激活擅长语言组织的参数子集,处理数学问题就切换到精于运算的参数部分,大大提高效率。在此基础上,创新的无辅助损失负载均衡策略登场,实时监控专家模块负载,动态调整任务分配,确保各模块协同高效,不出现 “忙闲不均”,保障整体性能不受损。多令牌预测(MTP)技术更是神来之笔,允许模型一次预测多个未来令牌,训练效率直接提升三倍,原本耗时的训练流程大幅缩短。
硬件与算法协同优化也是关键。DeepSeek 选用英伟达 H800 GPU,为模型训练打造坚实算力基础。算法层面,FP8 混合精度训练框架大显身手,在不损失模型精度前提下,降低数据存储与运算需求,减少一半内存占用,加速计算过程。流水线并行的 DualPipe 算法则让 GPU 各组件紧密协作,前向、后向计算与通信高效重叠,减少空闲等待,让训练一气呵成。靠着这些 “组合拳”,DeepSeek-V3 在短短两个月内,用 2048 个 GPU 就完成训练,成本效益做到极致,给行业树立全新标杆,让大家看到 AI 大模型发展的新路径:高性能与低成本,完全可以兼得。
产学研资多方热议,行业变革的 “星星之火”
DeepSeek-V3 的惊艳亮相,在产学研资各界激起千层浪。科研领域,顶尖 AI 科学家们纷纷点赞,斯坦福大学 AI 实验室主任李飞飞称赞:“DeepSeek-V3 打破常规,从架构创新到训练优化,开辟出大模型发展新航道,让我们看到 AI 性能提升与成本控制的完美平衡,为全球科研人员提供全新思路。” 清华大学计算机系教授张钹也表示:“其在中文语境知识处理和数学推理上的优势,贴合国内科研与教育刚需,有望成为学术研究、人才培养的得力助手。”
投资圈更是 “春江水暖鸭先知”,将 DeepSeek-V3 视为潜力无限的 “宝藏”。红杉资本中国合伙人沈南鹏直言:“这一开源模型大幅降低行业准入门槛,后续围绕其开发应用、优化服务的创业项目将如雨后春笋,投资机会满满。” 真格基金徐小平也在社交媒体发声:“DeepSeek-V3 证明中国 AI 创新力量,投资此类有核心技术、能改写行业规则的项目,就是拥抱未来。”
产业端,互联网大厂、传统企业都闻风而动。百度 CTO 王海峰指出:“它给行业带来‘鲶鱼效应’,促使大家重新审视模型研发投入产出比,加速技术迭代。” 阿里达摩院相关负责人认为:“从电商智能客服到物流优化调度,DeepSeek-V3 多领域赋能潜力巨大,将重塑产业流程,提升效率。” 传统制造业巨头富士康科技集团也透露正探索引入该模型优化生产排期、设备维护等环节,降本增效。各方热议背后,是 DeepSeek-V3 作为变革火种,点燃 AI 全面赋能各行各业、重塑产业生态的燎原之势。
从价格战到普惠路,AI 普及的 “领航灯塔”
回顾 DeepSeek 过往,那可是价格战中的 “狠角色”。今年五月,就率先打响大模型降价第一枪,API 输入费用一降再降,引得行业巨震,各大厂纷纷跟进,大模型价格从 “云端” 跌入 “凡尘”,让众多中小企业、开发者有了入场机会,为 AI 应用的广泛试水铺平道路。如今,DeepSeek-V3 带着超强性能与超低训练成本登场,更是将普惠 AI 的进程按下 “加速键”。
在教育领域,它能化身智能辅导老师,为学生提供个性化学习计划、答疑解惑,无论是复杂数学题还是晦涩知识点,都能轻松拿捏,偏远山区孩子也能借此畅享优质教育资源;医疗保健方面,辅助医生快速诊断病情、筛选治疗方案,基层医疗人员面对疑难病症有了智能参谋,提升诊断准确率与效率;智能办公里,自动生成报告、优化工作流程,职场人从繁琐事务解脱,专注创意创新,开启办公新篇;日常生活中,变身贴心生活助手,安排日程、推荐美食、规划出行,让生活井井有条又充满惊喜。DeepSeek-V3 就像一束光,穿透技术与成本的壁垒,照亮 AI 全民普及之路,假以时日,从城市到乡村,AI 将深度嵌入生活每个角落,开启智能生活新篇章。

RA/SD 衍生者AI训练营。发布者:風之旋律,转载请注明出处:https://www.shxcj.com/archives/8277