
本文直接从代码级别开始,引导每个人学习掌握LangChain下的编程能力。
本文中的截图或者说配图都是用微信小程序【字形绘梦】制作,谢谢该软件的免费支持。


1 基础知识
Python下的开发基础知识我就不多说了。这里要勾勒下Python下的虚拟环境的配置。
1.1 创建Python虚拟环境
python -m venv 你的文件夹名字
这句话创建了一个Python的虚拟环境,这样你可以在不同的环境中安装不同版本的依赖,解决了冲突问题。
然后执行
.你的文件夹名字/script/activate.bat
激活这个虚拟空间,然后开始用各种顺手的编辑器在这个位置下安装或者卸载依赖,然后开始编程吧。
1.2 开始编程
推荐使用VSCode,这个最高效率的一体化IDE开发工具。以前我们常说Visual Studio是地表最强IDE, 现在说VS Code是地表最强IDE也不为过。
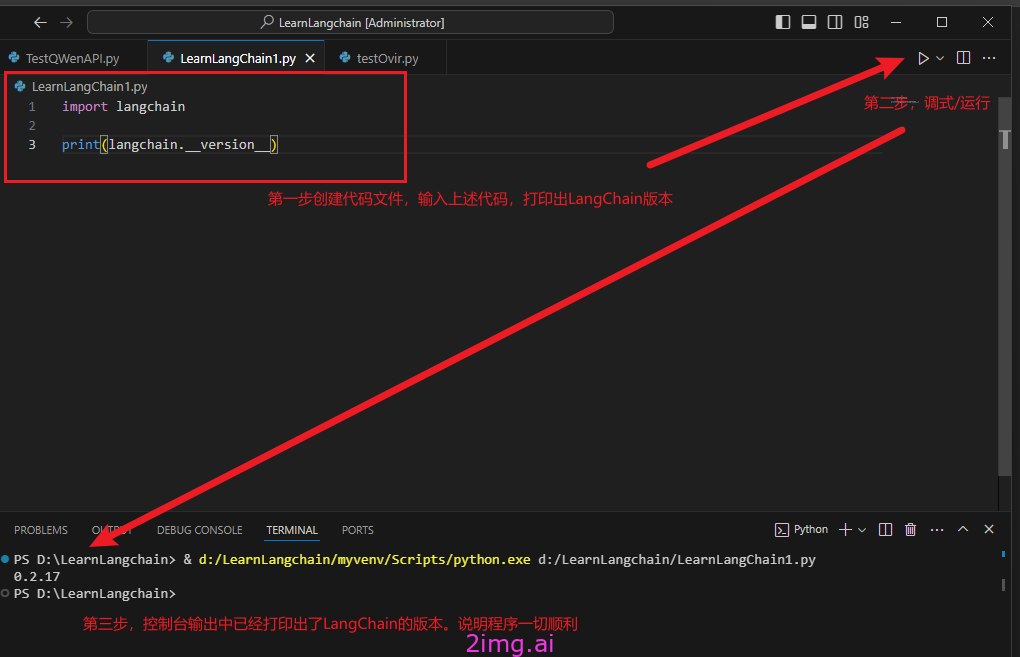
最简单的例子。
下图中,
第一行,我们引用langchain的开发包
第二行,我们用print指令打印langchain的版本。
下图中三步展示了如何编写代码,调试运行,查看输出结果等内容。这个例子可以正常运行,已经说明:
- 你已经入门了
- 整体开发环境OK了,你可以做任何开发的事情了
如果出现Langchain包找不到等错误。是你没有激活当前的Python虚拟环境。
可以到venv的目录下调用 venv/scripts/activate.bat 激活下即可。(这个venv不是固定的名字,是你创建的时候自己取的名字)
如果发现更多的依赖有问题,请查看是否有一个requirments.txt文件,如果有,执行
pip install -r requirements.txt
安装依赖,应该能解决很多问题
1.3 更进一步
以下的代码,我们做2件事情。
- 准备好对应的API key等信息,调用 通义千问 的大模型,得到一个聊天回答
- 我们要求对方作为一个C++ 工程师,给我们一段编程
在这个例子中api_key 你可以去 通义千问 注册后得到你自己的Key,替换代码中的即可。
在目前的代码中,我们没有采用流式的回复获取,一次性得到答案。所以处理的时间可能会需要一些,大家在查看结果的时候稍微耐心等待下。
import os
from openai import OpenAI
myClient = OpenAI(
# 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx",
api_key="sk-5b3bdd33fe584683a83b3a032366cf9a",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
#开始创建一个聊天
completion = myClient.chat.completions.create(
model="qwen-plus", # 模型列表:https://help.aliyun.com/zh/model-studio/getting-started/models
messages=[
{'role': 'system', 'content': 'You are a helpful assistant.'},
{'role': 'user', 'content': '你是谁?'}],
)
print(completion.model_dump_json())
#让计算机给我们自己编程
completion = myClient.chat.completions.create(
model="qwen-plus", # 模型列表:https://help.aliyun.com/zh/model-studio/getting-started/models
messages=[
{'role': 'system', 'content': '作为一个C++工程师'},
{'role': 'user', 'content': '请帮我编写一段代码将2个整数相加,返回int类型'}],
)
print(completion.model_dump_json())1.4 更多的聊天
下面的代码增加了一个Prompt回答时候用到的模板
另外,使用DashScope大模型。
可以 pip install DashScope 安装
from langchain_community.llms import Tongyi
from langchain_core.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
import os
# API——key自行去Qwen或者Azure申请即可
os.environ["DASHSCOPE_API_KEY"] = "sk-5b3bdd33fe584683a83b3a032366cf9a"
DASHSCOPE_API_KEY="sk-5b3bdd33fe584683a83b3a032366cf9a"
# 以下2行代码是最简单的LLM调用形式
# res=Tongyi().invoke("上海多大")
# print(res)#打印结果
# 以下代码套用了一个回答模板
llm=Tongyi(temperature=1)
template='''
你的名字是小联,当人问问题的时候,你都会在开头加上'你好,我是智能机器人',然后再回答{question}
'''
prompt=PromptTemplate(
template=template,
input_variables=["question"]#这个question就是用户输入的内容,这行代码不可缺少
)
## 创建了一个chain
chain = LLMChain(#将llm与prompt联系起来
llm=llm,
prompt=prompt
)
question='微软这个公司怎么样'
res=chain.invoke(question)#运行
print(res['text'])#打印结果上述的代码中 LLMChain可能会提示已废弃。建议使用新的方法。
下面的代码,我们针对对应的代码行内容进行了修改。
## 创建了一个chain ,绑定我的大模型和我的提示词模板
chain = llm | prompt;
question='微软这个公司怎么样'
res=chain.invoke(question)#运行
print(res)2 增强RAG解析
2.1 接入RAG
from langchain_community.llms import Tongyi
from langchain_core.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain.chains import RetrievalQA
#from langchain.document_loaders import TextLoader
from langchain_community.document_loaders import TextLoader
#from langchain.embeddings import OpenAIEmbeddings
from langchain_community.embeddings import OpenAIEmbeddings
from langchain.indexes import VectorstoreIndexCreator
from langchain.text_splitter import CharacterTextSplitter
#from langchain.vectorstores import Chroma
from langchain_community.vectorstores import Chroma
from langchain.embeddings import HuggingFaceBgeEmbeddings
import os
# 这些Key请在实际使用中替换成你自己的
os.environ["DASHSCOPE_API_KEY"] = "sk-5b3bdd33fe584683a83b3a032366cf9a"
DASHSCOPE_API_KEY="sk-5b3bdd33fe584683a83b3a032366cf9a"
#os.environ["OPENAI_API_KEY"] = "sk-5b3bdd33fe584683a83b3a032366cf9a"
myLLM=Tongyi(temperature=1)
template='''
当人问问题的时候,你都会在开头加上'你好,我是智能机器人',然后再回答{question}
'''
#这个question就是用户输入的内容,这行代码不可缺少
prompt=PromptTemplate(
template=template,
input_variables=["question"]
)
#将llm与prompt联系起来
chain = LLMChain(
llm=myLLM,
prompt=prompt
)
# 创建文本加载器
## 这里需要确保该文本Utf8编码
loader = TextLoader('D:\\1.txt', encoding='utf8')
# 加载文档
documents = loader.load()
# 文本分块
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# 计算嵌入向量
embeddings = HuggingFaceBgeEmbeddings()
# 创建向量库
db = Chroma.from_documents(texts, embeddings)
# 将向量库转换为检索器
retriever = db.as_retriever()
# 创建检索问答系统
qa = RetrievalQA.from_chain_type(llm=myLLM, chain_type="stuff", retriever=retriever)
question='字形绘梦这个产品是哪个公司出的'
res=chain.invoke(question)#运行
print(res['text'])#打印结果我们在D盘放了一个1.txt,输入了 字形绘梦 相关产品的信息,然而RAG之后,没有输出正确的内容。
大家可以字形试一下,错误的答案应该是回复阿里的产品。
2.2 高级模态RAG操作
from langchain_community.llms import Tongyi
from langchain_core.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain.chains import RetrievalQA
#from langchain.document_loaders import TextLoader
from langchain_community.document_loaders import TextLoader
#from langchain.embeddings import OpenAIEmbeddings
from langchain_community.embeddings import OpenAIEmbeddings
from langchain.indexes import VectorstoreIndexCreator
from langchain.text_splitter import CharacterTextSplitter
#from langchain.vectorstores import Chroma
from langchain_community.vectorstores import Chroma
import os
from langchain_community.document_loaders import PyPDFLoader
from langchain.embeddings import HuggingFaceBgeEmbeddings
##
#from langchain.document_loaders import OnlinePDFLoader
#from langchain.document_loaders import UnstructuredPDFLoader
# 这些Key请在实际使用中替换成你自己的
os.environ["DASHSCOPE_API_KEY"] = "sk-5b3bdd33fe584683a83b3a032366cf9a"
DASHSCOPE_API_KEY="sk-5b3bdd33fe584683a83b3a032366cf9a"
myLLM=Tongyi(temperature=1)
template='''
'你好,我是智能机器人',然后再回答{question}
'''
#这个question就是用户输入的内容,这行代码不可缺少
prompt=PromptTemplate(
template=template,
input_variables=["question"]
)
#将llm与prompt联系起来
chain = myLLM | prompt;
# 创建文本加载器
## 这里需要确保该文本Utf8编码
#loader = OnlinePDFLoader("D:\\1_HelpDoc.pdf");
#loader = UnstructuredPDFLoader("D:\\1_HelpDoc.pdf");
loader = PyPDFLoader("D:\\1_HelpDoc.pdf")
pages = loader.load_and_split()
# 加载文档
documents = loader.load()
# 文本分块
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# 计算嵌入向量
# 不知道为什么,目前提示Resource not found.
# embeddings = OpenAIEmbeddings()
model_id = "hkunlp/instructor-large"
embeddings = HuggingFaceBgeEmbeddings(model_name=model_id)
# 创建向量库
db = Chroma.from_documents(texts, embeddings)
# 将向量库转换为检索器
retriever = db.as_retriever()
# 创建检索问答系统
qa = RetrievalQA.from_chain_type(llm=myLLM, chain_type="stuff", retriever=retriever)
#question='腹主动脉瘤模板中默认参数含义'
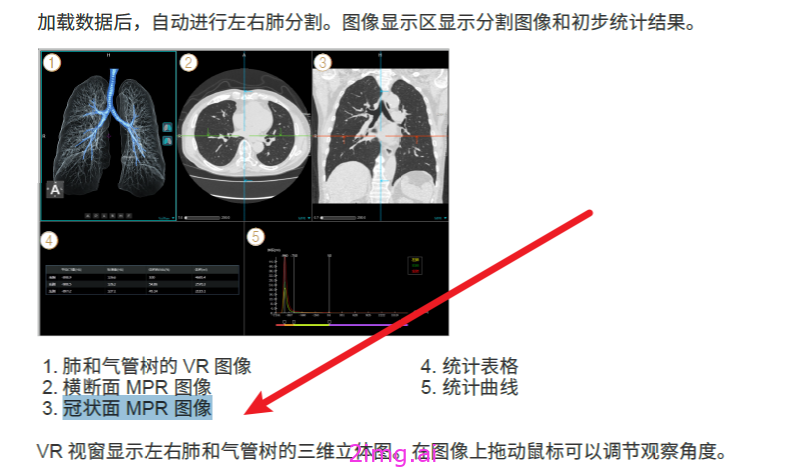
question="加载数据后,自动进行左右肺分割。图像显示区显示分割图像和初步统计结果,其中冠状面 MPR 图像是图中哪部分?"
res=chain.invoke(question)#运行
print(type(res))
print(res.to_string())#打印结果这里我们遇到一些问题,原本我们可以解析txt文件,但此时我们想要解析包含图片数据的PDF文件。
我们想要针对下图中的内容,让LLM能够解析出我们想要的确切答案
如果碰到以下问题,删除旧的。升级即可。
pip install –upgrade langchain.core


RAG目前验证下来,命中还不够,敬请期待我的下一篇更高级研究文档
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/8113