
提示工程,也称为 上下文提示,是指如何与 LLM 进行沟通, 以在不更新模型权重的情况下引导其行为以实现所需结果的方法。
这是一门经验科学,提示工程方法的效果在不同模型之间可能存在很大差异,因此需要大量的实验和启发式方法。
这篇文章只关注自回归语言模型的快速工程,因此不涉及 Cloze 测试、图像生成或多模态模型。快速工程的核心目标是对齐和模型可控性。
[我个人的辛辣看法] 在我看来,一些快速工程论文不值得长达 8 页,因为这些技巧可以用一两句话来解释,其余的都是关于基准测试的。易于使用和共享的基准测试基础设施应该对社区更有益。设置迭代提示或外部工具使用并不容易。让整个研究社区采用它也不是一件容易的事。
学习最佳资源站点:
基本提示
零样本学习和少样本学习是推动模型的两种最基本方法,由许多 LLM 论文开创,并常用于对 LLM 性能进行基准测试。
零次射击 Zero-Shot
零样本学习 就是简单地将任务文本输入模型并要求得到结果。
(所有情绪分析示例均来自 SST-2)
文字:我敢打赌,视频游戏比电影有趣得多。
情绪:少量样本 Few-shot
少样本学习 针对目标任务提供一组高质量的演示,每个演示都包含输入和期望输出。
由于模型首先看到好的示例,因此它可以更好地理解人类的意图以及想要什么样的答案的标准。因此,少样本学习通常比零样本学习能带来更好的性能。然而,它以更多的 token 消耗为代价,并且当输入和输出文本很长时可能会达到上下文长度限制。
文字:(小明蹦蹦跳跳)在舞台上跳来跳去,奔跑着,汗流浃背,擦着脸,总之,展现着最初让他成名的古怪才华。
情绪:积极
文本:尽管所有证据都表明事实并非如此,但这部烂片还是设法伪装成一部真正的故事片,是那种需要全额入场费、在电视上大肆宣传、声称能逗乐小孩和成年人的电影。
情绪:负面
文本: 多年来,德尼罗第一次在情感上深入挖掘,也许是因为他被他的联合主演的强大作品所感动。
情绪:积极许多研究探讨了如何构建上下文示例以最大化性能,并观察到 提示格式、训练示例和示例顺序的选择会导致显著不同的性能,从接近随机猜测到接近 SoTA。
Tony Z Zhao 等人 (2021) 这篇论文中 研究了少样本分类的情况,并提出 LLM 的几种偏差
(他们在实验中使用了 GPT-3)导致了如此高的方差:
(1)如果样本之间的标签分布不平衡,则存在 多数标签偏差;
(2)新近度偏差 是指模型可能在最后重复标签的趋势;
(3)常见标记偏差 表明 LLM 倾向于比罕见标记更频繁地生成常见标记。
为了克服这种偏差,他们提出了一种方法来校准模型输出的标签概率,使其在输入字符串为 时保持均匀 N/A。
示例选择技巧
- 使用嵌入空间中的 聚类选择与测试示例语义相似的示例(Liu et al.,2021)
- 为了选择一组多样化且具有代表性的示例, Su 等人 (2022) 建议使用基于图的方法:(1)首先,根据样本之间的嵌入(例如通过 SBERT 或 其他 嵌入 模型)余弦相似度构建有向图 �=(�,�),其中每个节点指向其 � 个最近邻居;(2)从一组选定样本 �=∅ 和一组剩余样本 � 开始。每个样本 �∈� 的评分为score(�)=∑�∈{�∣(�,�)∈�,�∈�}�(�),其中 �(�)=�−|{ℓ∈�|(�,ℓ)∈�}|,�>1,如果 � 的许多邻居被选中,则 �(�) 很低,因此评分鼓励选择多样化的样本。
- Rubin 等人 (2022)提出通过针对一个训练数据集的对比学习 来训练嵌入, 以进行上下文学习样本选择。给定每个训练对 (�,�),一个示例 ��(格式化的输入输出对)的质量可以通过 LM 分配的条件概率来衡量:score(��)=�LM(�∣��,�)。我们可以将具有最高� 和最低� 分数的其他示例确定为每个训练对的正负候选集,并将其用于对比学习。
- 一些研究人员尝试使用 Q-Learning 进行样本选择。(Zhang 等人,2022 年)
- 受基于不确定性的 主动学习的启发, Diao 等人(2023) 建议在多次采样试验中识别出具有高分歧或熵的示例。然后注释这些示例以用于小样本提示。
示例订购提示
- 一般建议是保持示例的选择多样化、与测试样本相关且随机排序,以避免多数标签偏差和近因偏差。
- 增加模型大小或包含更多训练示例不会减少上下文示例的不同排列之间的方差。相同的顺序可能对一个模型效果很好,但对另一个模型效果不好。当验证集有限时,请考虑选择顺序,以使模型不会产生极不平衡的预测或对其预测过于自信。(Lu 等人,2022 年)
指令提示Instruction Prompting
在提示中呈现少样本示例的目的是向模型解释我们的意图;换句话说,以演示的形式向模型描述任务指令。然而,少样本在 token 使用方面成本高昂,并且由于上下文长度有限而限制了输入长度。
那么,为什么不直接给出指令呢?
指导式 LM (例如 InstructGPT、 自然指令)使用高质量的(任务指令、输入、基本事实输出)三元组对预训练模型进行微调,以使 LM 更好地理解用户意图并遵循指令。
RLHF ( 从人类反馈中进行强化学习)是一种常用的方法。指令遵循风格微调的好处是改进模型,使其更符合人类意图,并大大降低了沟通成本。
在与教学模型交互的时候,要详细描述任务要求,力求 具体 、 精确 ,避免说“不做某事”,而是具体说明要做什么。
定义:确定对话的说话人, “代理人” 或 “客户”。
输入:我已经成功预订了您的机票。
输出:代理人
定义:确定问题要求的类别是“数量” 还是 “位置”。
输入:美国最古老的建筑是
什么?输出:位置
定义:将给定电影评论的情绪分类为“正面” 或 “负面”。
输入:我敢打赌这个视频游戏比这部电影有趣得多。
输出:自一致性抽样Self-Consistency Sampling
自洽抽样 (Wang et al. 2022a)是对温度 > 0 的多个输出进行抽样,然后从这些候选输出中选择最佳输出。选择最佳候选输出的标准因任务而异。一般解决方案是选择 多数票。对于易于验证的任务(例如带有单元测试的编程问题),我们可以简单地运行解释器并使用单元测试验证正确性。
思想链(CoT)Chain-of-Thought
思路链 (CoT) 提示 (Wei 等人,2022 年)会生成一系列简短的句子来逐步描述推理逻辑,称为 推理链 或 理由,最终得出最终答案。在使用 大型模型(例如具有超过 50B 个参数)时, CoT 的优势对于 复杂的推理任务更为明显 。简单任务仅从 CoT 提示中受益不多。
CoT 提示的类型
CoT 提示主要有两种类型:
Few-shot CoT。
它是用一些演示来提示模型,每个演示包含手动编写(或模型生成)的高质量推理链。
(所有数学推理示例均来自 GSM8k)
问题:汤姆和伊丽莎白比赛爬山。伊丽莎白爬山用了30分钟。汤姆爬山用的时间是伊丽莎白的四倍。汤姆爬上这座山需要几个小时?答案
:汤姆爬上这座山需要30 * 4 = << 30 * 4 = 120 >> 120分钟。
汤姆需要120 / 60 = << 120 / 60 = 2 >> 2小时才能爬上这座山。
所以答案是 2。===
问题:杰克是一名足球运动员。他需要购买两双袜子和一双足球鞋。每双袜子的价格为 9.50 美元,鞋子的价格为92 美元。杰克有40美元。杰克还需要多少钱?
答案:两双袜子的总价格为9.50美元x 2 = $ << 9.5 * 2 = 19 >> 19。袜子和鞋子的
总价格为$ 19 + $ 92 = $<< 19 + 92 = 111 >> 111。
杰克还需要 $$ 111 - $$ 40 = $<< 111 - 40 = 71 >> 71。
所以答案是 71。
===
零样本 CoT。Zero-shot CoT
使用自然语言语句 Let’s think step by step 明确鼓励模型首先生成推理链,然后提示以 Therefore, the answer is 产生答案(Kojima 等人,2022 年 )。或类似的语句 Let’s work this out it a step by step to be sure we have the right answer (Zhou 等人,2022 年)。
问题: Marty 有100厘米长的丝带,他必须将其剪成4 等份。每 剪下的部分必须再分成 5等份。每剪下的部分最终会有多长?
答案:让我们一步一步思考。 提示和扩展
- 自洽抽样 可以通过抽取大量不同的答案然后进行多数表决来提高推理准确性。(Wang 等人,2022a)
- 集成学习的另一种方法是改变示例顺序或使用模型生成的理由来代替人工编写的理由,以在多次样本试验期间引入随机性。然后以多数票汇总模型输出以获得最终答案。(Wang 等人,2022b)
- 如果训练示例仅与真实答案相关(易于验证!)但没有原理,我们可以遵循 STaR ( 自学推理机; Zelikman 等人,2022 年)方法:(1)要求 LLM 生成推理链,只保留那些导致正确答案的推理链;(2)然后用生成的原理微调模型并重复该过程直到收敛。请注意,温度越高,越有可能产生具有正确答案的错误原理。如果训练示例没有基本事实答案,也许可以考虑使用多数票作为“正确”答案。
- 具有更高推理复杂度的提示可以获得更好的性能,其中复杂度通过链中的推理步骤数量来衡量。在分隔推理步骤时,换行符 比句号 或分号 n 效果更好 。(Fu 等人,2023 年)step i.;
- 基于复杂性的一致性 是在所有代中明确偏好复杂链,通过仅在顶部 � 复杂链中进行多数投票。(Fu 等人,2023 年)
- 后来, Shum 等人(2023) 在他们的实验中发现,仅使用复杂示例的 CoT 提示可以提高复杂问题的准确性,但在简单问题上表现不佳;证据显示在 GSM8k 上。
- Q: 发现 改为 Question: 是有帮助的。(Fu等人,2023年)
- Ye & Durrett (2022) 发现,对于涉及文本推理的 NLP 任务(即 QA 和 NLI),在提示中包含解释的好处很小到中等,并且效果因模型而异。他们观察到,解释更有可能是非事实的,而不是不一致的(即解释是否需要预测)。非事实的解释最有可能导致错误的预测。
- Self-Ask (Press 等人,2022 年)是一种反复提示模型 提出后续问题 以迭代构建思维过程的方法。后续问题可以通过搜索引擎结果来回答。类似地, IRCoT (Interleaving Retrieval CoT; Trivedi 等人,2022 年)和 ReAct (Reason + Act; Yao 等人,2023 年)将迭代 CoT 提示与对 Wikipedia API 的查询相结合,以搜索相关实体和内容,然后将其重新添加到上下文中。
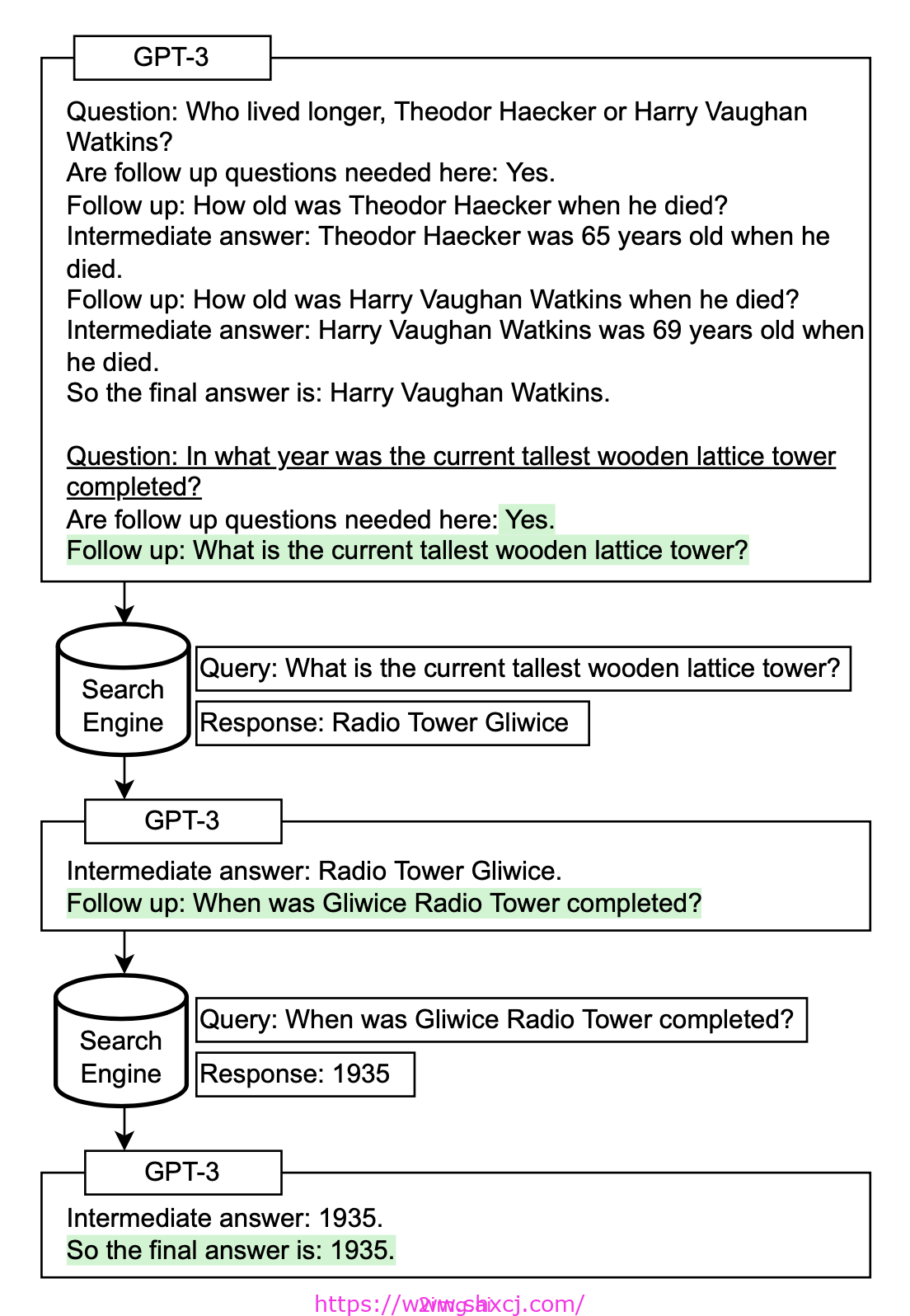

图 1. Self-Ask 如何与外部搜索查询配合使用。(图片来源: Press 等人,2022 年)。
- 思维树 (Yao 等人,2023 年)通过在每个步骤探索多种推理可能性来扩展 CoT。它首先将问题分解为多个思维步骤,并在每个步骤中生成多个想法,本质上是创建一个树结构。搜索过程可以是 BFS 或 DFS,而每个状态都由分类器(通过提示)或多数表决进行评估。
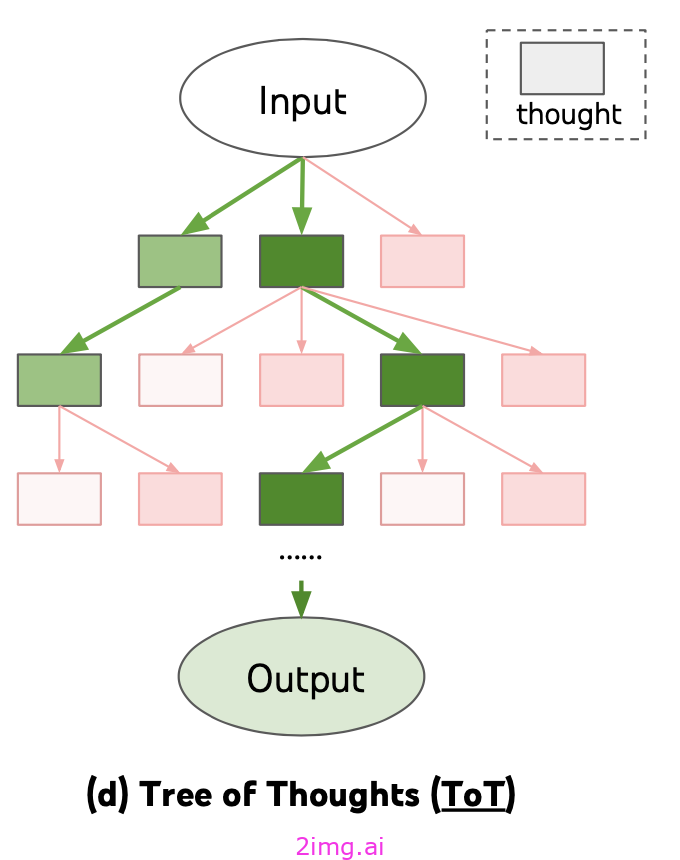
图 2. Self-Ask 如何与外部搜索查询配合使用。(图片来源: Yao 等人,2022 年)。
自动提示设计
Prompt 是一系列前缀标记,可增加给定输入获得所需输出的概率。因此,我们可以将它们视为可训练参数,并 通过梯度下降直接 在嵌入空间上对其进行优化,例如 AutoPrompt (Shin et al.,2020)、 Prefix-Tuning (Li & Liang (2021))、 P-tuning (Liu et al. 2021)和 Prompt-Tuning (Lester et al. 2021)。
APE (自动提示工程师; Zhou 等人,2022 年)是一种在模型生成的指令候选池中进行搜索的方法,然后根据所选的评分函数过滤候选集,最终选择得分最高的最佳候选者。
研究方向1 – augment-prune-select
提示 LLM 根据一小组以输入输出对形式的演示来生成指令候选。
使用迭代蒙特卡罗搜索方法,通过以下提示提出语义相似的变体来改进最佳候选者: Generate a variation of the following instruction while keeping the semantic meaning.nnInput: …nnOutput:…
为了自动构建思路链提示, Shum 等人(2023) 提出了增强-修剪-选择的方法,这是一个三步过程:
- 增强:使用少样本或零样本 CoT 提示,针对给定问题生成多个伪思路链;
- 修剪:根据生成的答案是否与基本事实相符来修剪伪链。
- 选择:应用方差减少的策略梯度策略来学习选定示例的概率分布,同时将示例的概率分布作为策略,将验证集准确度作为奖励。
研究方向2 – adopted clustering techniques
Zhang 等人 (2023) 则采用 聚类 技术来抽样问题,然后生成链。他们观察到 LLM 倾向于犯某些类型的错误。一种类型的错误在嵌入空间中可能相似,因此被归为一类。通过仅从频繁错误簇中抽样一个或几个,我们可以防止一种错误类型的错误演示过多,并收集一组多样化的示例。
- 问题聚类:嵌入问题并运行�-均值进行聚类。
- 演示选择:从每个簇中选择一组代表性问题;即从一个簇中选择一次演示。每个簇中的样本按与簇质心的距离排序,优先选择距离质心较近的样本。
- 推理生成:使用零样本 CoT 为选定的问题生成推理链,并构建少样本提示来运行推理。
增强语言模型
Mialon 等人 (2023)对增强语言模型进行了调查, 涵盖了增强了推理能力和使用外部工具能力的多种语言模型类别。推荐它。
RAG
我们经常需要在模型预训练时间截止或内部/私有知识库之后完成需要最新知识的任务。在这种情况下,如果我们没有在提示中明确提供上下文,模型将无法知道上下文。许多 开放域问答方法都 依赖于首先在知识库中进行检索,然后将检索到的内容作为提示的一部分。这种过程的准确性取决于检索和生成步骤的质量。
Lazaridou 等人 (2022) 研究了如何使用 Google 搜索进行文档检索以增强 LLM。给定一个问题 �,从 Google 返回的 20 个 URL 中提取干净的文本,从而生成一组文档。由于这些文档很长,因此每个文档被分成 6 个句子的段落,{�}。段落根据证据段落和查询之间的基于 TF-IDF 的余弦相似度进行排序。提示中仅使用最相关的段落来生成答案 �。
编程语言
PAL (程序辅助语言模型); Gao 等人,2022 年)和 PoT (思维提示程序; Chen 等人,2022 年)都 要求 LLM 生成编程语言语句来解决自然语言推理问题,从而将解决步骤转移到 Python 解释器等运行时。这种设置将复杂的计算和推理解耦。它依赖于具有足够好编码技能的 LM。

比较 CoT 和 PoT。(图片来源: Chen et al. 2022)。
外部 API
TALM (Tool Augmented Language Models; Parisi et al. 2022)是一个通过文本到文本 API 调用进行增强的语言模型。LM 被引导以生成 任务输入文本|tool-call 并 tool input text 以此为条件来构造 API 调用请求。 |result 出现时,将调用指定的工具 API,并将返回的结果附加到文本序列中。最终输出在 |output token 之后生成。

图 4. TALM 中的 API 调用格式。(图片来源: Parisi 等人,2022 年)。
TALM 采用自演方法,以迭代方式引导工具使用示例数据集,并利用该数据集微调 LM。这种自演方法定义为与工具 API 交互的模型,它根据新添加的工具 API 是否可以改进模型输出来迭代扩展数据集。Toolformer 也采用了相同的想法,下面将更详细地介绍。该流程大致模拟了 RL 过程,其中 LM 是策略网络,并通过二元奖励信号通过策略梯度进行训练。
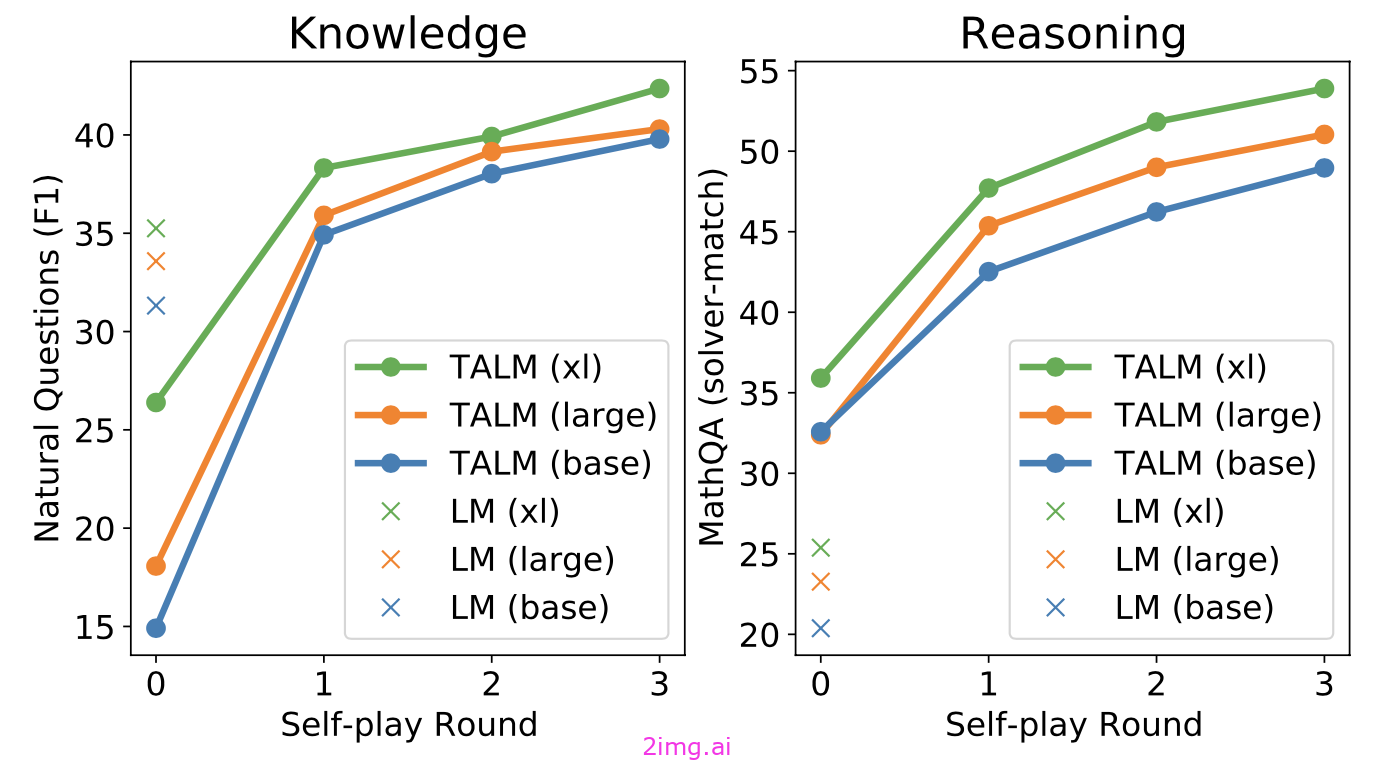
图 5. 自我游戏迭代有助于提升模型性能。(图片来源: Parisi 等人,2022 年)。
Toolformer
(Schick 等人,2023 年)是一个可以通过简单的 API 使用外部工具的 LM,它以自监督的方式构建,每个 API 只需要少量的演示。Toolformer 的工具箱包括:
- 计算器 可以帮助 LM 弥补缺乏精确数学技能的缺陷;
- 问答系统, 帮助解决不真实的内容和幻觉
- 搜索引擎 在预训练截止时间后提供最新信息;
- 提高低资源语言性能的翻译系统
- 日历 让 LM 了解时间的进展。
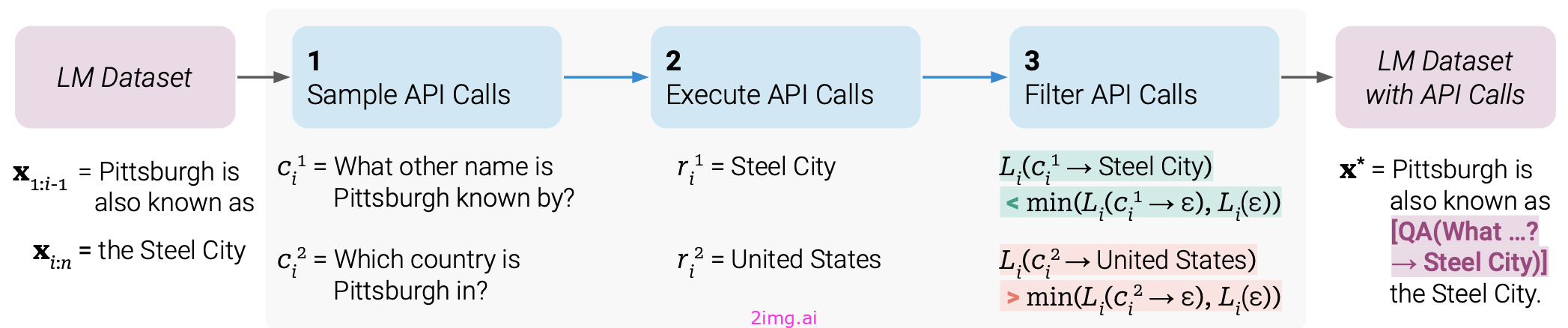
图 6. 如何构建 Toolformer 的说明。(图片来源: Schick 等人,2023 年)。
Toolformer 的训练如下:
提示注释潜在的 API 调用。要求预先训练过的 LM 通过少量学习和 API 调用使用示例注释数据集。格式示例:2-6 深入提示词工程 【SVIP】图 7. 如何注释数据集以进行 API 调用。
(图片来源: Schick 等人,2023 年)。
每个 API 调用表示为 (API 名称, 对应输入) 的元组,�=(��,��),其对应结果表示为 �。有结果和无结果的 API 调用序列分别标记为:
�(�)=⟨API⟩��(��)⟨/API⟩�(�,�)=⟨API⟩��(��)→�⟨/API⟩
根据概率 �LM(⟨API⟩∣prompt(�),�1:�) 对 API 调用进行抽样,如果概率大于阈值,则选择前 � 个候选位置在位置 � 处进行 API 调用。
然后,我们从 LM 中抽取潜在的 API 调用,给定序列 [prompt(�),�1,…,��−1,⟨API⟩] 作为前缀,⟨/API⟩ 作为后缀。
根据 API 调用是否有助于模型预测未来标记来过滤注释。 使用自监督损失来决定哪些 API 调用真正有用。
执行每个API调用��以获得相应的结果��。
当模型以提示为前缀时,计算 LM 对标记 ��,…,�� 的加权交叉熵损失。计算两个版本,一个使用 API 结果,另一个使用空序列 �。��
+=��(�(��,��))��−=min(��(�),��(�(��,�)))仅保留 ��−−��+ 大于阈值的 API 调用,这意味着添加此 API 调用及其结果有助于模型预测未来的标记。
在这个带注释的数据集上对 LM 进行微调。 新的训练序列构造为 �∗=�1:�−1,�(��,��),��:� 。训练数据是原始数据集(例如论文中的 CCNet 子集)及其增强版本的组合。
在推理时,解码一直运行直到模型产生“→”标记,表明它接下来正在等待 API 调用的响应。
Toolformer 目前不支持以链式方式使用工具(即使用一个工具的输出作为另一个工具的输入)或以交互方式使用工具(即在人工选择后采用 API 响应)。两者都是未来扩展模型的有趣方向。
有用的资源
OpenAI Cookbook 有许多关于如何有效利用 LLM 的深入示例。
LangChain,一个将语言模型与其他组件相结合以构建应用程序的库。
微软的语义核心
参考
[1] Zhao 等人, “使用前校准:提高语言模型的少样本性能。” ICML 2021
[2] 刘等人, “什么是 GPT-3 的良好上下文示例?” arXiv 预印本 arXiv:2101.06804 (2021 年)。
[3] Lu 等人, “奇妙有序的提示及其查找位置:克服小样本提示顺序敏感性。” ACL 2022
[4] Ye 等人, “情境教学学习”。arXiv 预印本 arXiv:2302.14691 (2023)。
[5] Su 等人, “选择性注释使语言模型成为更好的小样本学习者。” arXiv 预印本 arXiv:2209.01975 (2022 年)。
[6] Rubin 等人, “学习检索情境学习的提示。” NAACL-HLT 2022
[7] Wei 等人, “思维链提示在大型语言模型中引发推理。” NeurIPS 2022
[8] 王等人, “自一致性改善语言模型中的思路链推理。” ICLR 2023。
[9] Diao 等人, “针对大型语言模型的思维链式主动提示”。arXiv 预印本 arXiv:2302.12246 (2023)。
[10] Zelikman 等人, “STaR:通过推理进行引导推理。” arXiv 预印本 arXiv:2203.14465 (2022)。
[11] Ye & Durrett。 “小样本情境学习中解释的不可靠性。” arXiv 预印本 arXiv:2205.03401 (2022 年)。
[12] Trivedi 等人, “针对知识密集型多步骤问题,使用思路链推理进行交错检索。” arXiv 预印本 arXiv:2212.10509 (2022)。
[13] Press 等人, “测量和缩小语言模型中的组合性差距。” arXiv 预印本 arXiv:2210.03350 (2022 年)。
[14] Yao 等人, “ReAct:语言模型中的协同推理和行动。” ICLR 2023。
[15] Fu 等人, “基于复杂性的多步推理提示。” arXiv 预印本 arXiv:2210.00720 (2022 年)。
[16] Wang 等人, “语言模型中的理论增强集成”。arXiv 预印本 arXiv:2207.00747 (2022 年)。
[17] 张等人, “大型语言模型中的自动思维链提示。” arXiv 预印本 arXiv:2210.03493 (2022 年)。
[18] Shum 等人, “通过思维链从标记数据中实现自动提示增强和选择。” arXiv 预印本 arXiv:2302.12822 (2023 年)。
[19] 周等人, “大型语言模型是人类级别的快速工程师。” ICLR 2023。
[20] Lazaridou 等人, “通过少量提示实现开放域问答的互联网增强语言模型。” arXiv 预印本 arXiv:2203.05115 (2022)。
[21] Chen 等人, “思维提示程序:将计算与数值推理任务的推理区分开来。” arXiv 预印本 arXiv:2211.12588 (2022)。
[22] Gao 等人, “PAL:程序辅助语言模型”。arXiv 预印本 arXiv:2211.10435 (2022 年)。
[23] Parisi 等人。 “TALM:工具增强语言模型” arXiv 预印本 arXiv:2205.12255 (2022 年)。
[24] Schick 等人, “Toolformer:语言模型可以自学使用工具。” arXiv 预印本 arXiv:2302.04761 (2023 年)。
[25] Mialon 等人。 “增强语言模型:一项调查” arXiv 预印本 arXiv:2302.07842 (2023 年)。
[26] 姚等人, “思维树:利用大型语言模型进行深思熟虑的问题解决”。arXiv 预印本 arXiv:2305.10601 (2023 年)
RA/SD 衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/81