
最近AI生成视频的能力真是每天都越来越多,心里感觉始终追不上高速发展的AIGC势头。
本文尝试分享尽可能详细的内容,每个都是笔者亲自分析的,如有任何错误之处,请随时联系作者。
本文中的截图或者说配图都是用微信小程序【字形绘梦】制作,谢谢该软件的免费支持。


备注:
本文不负责提供最终测试的生成后的视频。因为很多平台并不提供此种功能。
如有需要,请联系本人。
1 AnimateDiff
这个视频能力是SD体系中的一个插件
插件地址:
基本使用操作
- 打開AnimateDiff 面板,勾選 Enable AnimateDiff
- SaveFormat 我們一般選擇GIF和MP4
- 設置 Number of Frames (總體幀數) , 默認8幀每秒(就是FPS,可以自行修改)
- 點擊【生成】按鈕,按照 Prompt 生成内容和完成。内容輸出在Output目錄下的AnimateDiff目錄下
参数配置界面如下
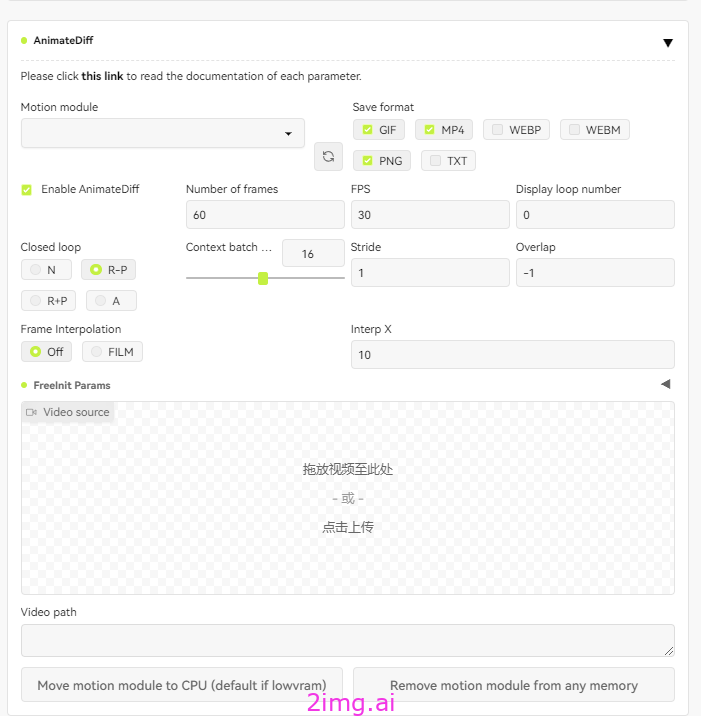
参数说明:
保存格式(Save format):
输出的文件格式。至少选择一个:”GIF”|”MP4″|”WEBP”|”PNG”。如果需要附加信息文本,勾选”TXT”,它将与输出GIF文件保存在相同的目录下。
总帧数(Number of frames):
生成的超短视频的帧数,一般建议20帧以下。
帧率(FPS):
选择30-60为佳。
循环播放次数(Display loop number):
GIF播放的循环次数,值为0表示GIF永远不停止播放。
上下文批处理大小(Context batch size):
每次传入运动模块的帧数。SD1.5运动模块是基于16帧训练的,因此当帧数设置为16时,效果最好。
闭环(Closed loop):
闭环意味着该扩展会尝试使最后一帧与第一帧相同。选择不同的闭环选项(N|R-P|R+P|A)来确定如何实现闭环。
N表示绝对没有闭环。如果帧数小于上下文批处理大小而不是0,则这是唯一可用的选项。
R-P意味着扩展将试图减少闭环上下文的数量。提示行程不会被插值为闭环。
R+P意味着扩展将试图减少闭环上下文的数量。即时行程将被插值为一个闭环。
A意味着扩展将积极尝试使最后一帧与第一帧相同。即时行程将被插值为一个闭环。
步幅(Stride):
最大运动步幅,以2的幂表示(默认值:1)。由于无限上下文生成器的限制,此参数仅在帧数大于上下文批处理大小时有效。当Stride为1时,”Absolutely no closed loop”(绝对不进行闭环)才可能实现。
重叠(Overlap):
上下文中重叠的帧数。如果重叠设置为-1(默认值),重叠将为上下文批处理大小的四分之一。由于无限上下文生成器的限制,该参数仅在帧数 > 上下文批处理大小时有效。
帧插值(Frame Interpolation):
使用Deforum的FILM实现在帧之间进行插值。需要Deforum扩展。
插值倍数(Interp X):
将每个输入帧替换为X个插值输出帧。
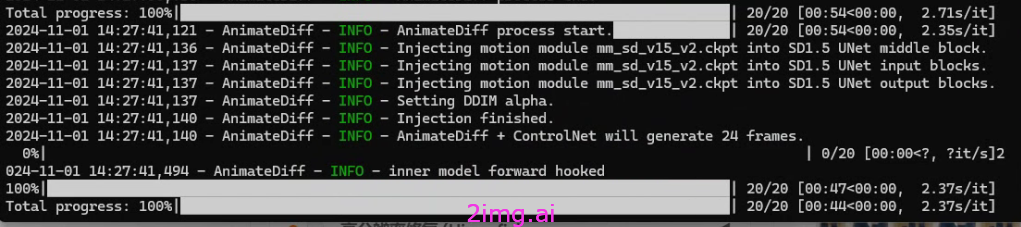
成功運行的截圖
- 運動模塊Injection成功
- 麽有任何錯誤信息,成功輸出GIF,PNG,MP4
注意:
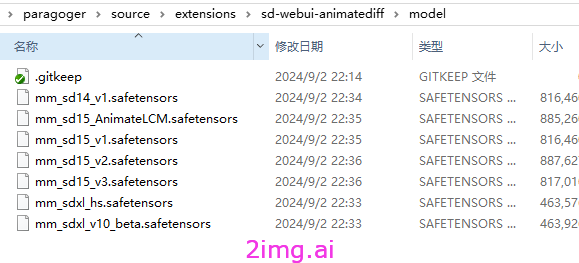
需要用到的模型,在这里下载https://huggingface.co/conrevo/AnimateDiff-A1111/tree/main
然后需要手动下载放到了插件的model目录下。
配置的模型,手动下载放到了插件的model目录下了。如下图
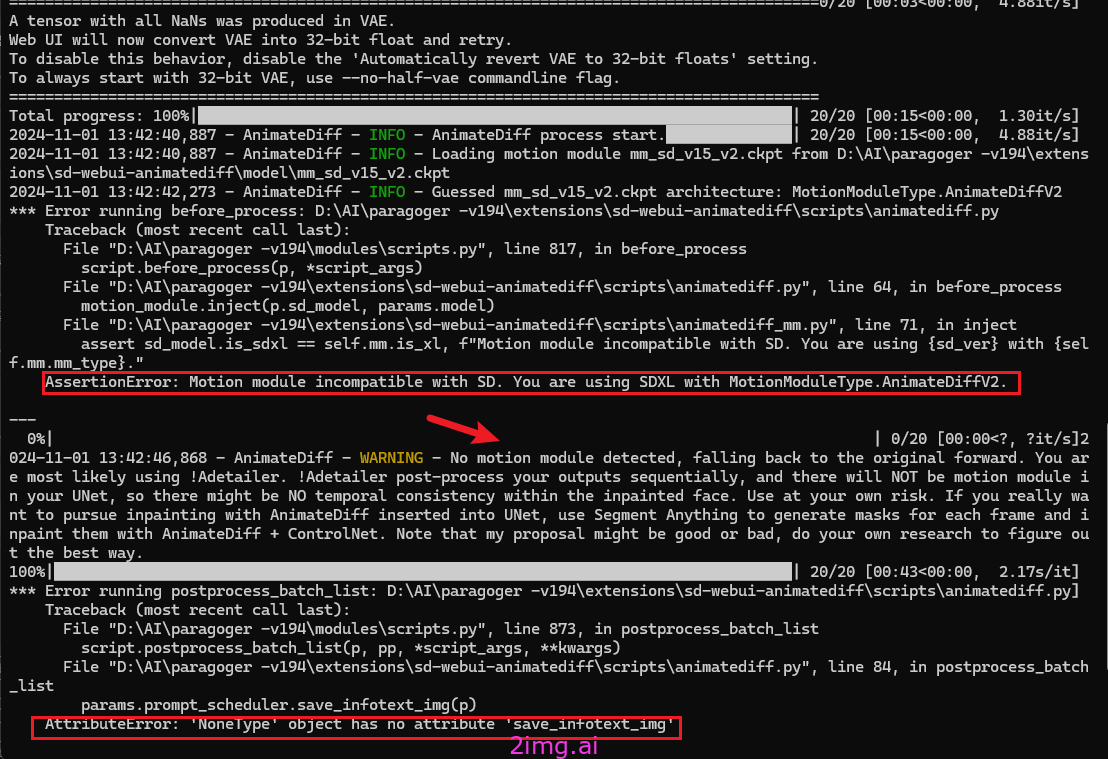
错误集锦
这个连接中指出了一些配置,但是貌似没社么作用https://blog.csdn.net/watson2017/article/details/134421393
如果在txt2img模式下,出现错误(注意导出到mp4和jpg可能错误信息有所不同,但大差不差)
raise EinopsError(message + ‘\n {}’.format(e))
einops.EinopsError: Error while processing rearrange-reduction pattern “(b f) c h w -> b c f h w”.
Input tensor shape: torch.Size([2, 320, 1, 64, 64]). Additional info: {‘b’: 2}.
Expected 4 dimensions, got 5
einops.EinopsError: Shape mismatch, can’t divide axis of length 2 in chunks of 16
还有
如果切换到img2img的模式,错误信息如下。
AttributeError: ‘NoneType’ object has no attribute ‘mode’
2 Infinite Zoom
插件介绍
Infinite Zoom 是个非常有意思的SD中的插件,它允许你自定义每帧的内容,然后串联起来,形成一个无线循环播放的视频。
可以从一个小点,进而进入一个更大的视野点。难度在于,这个切换过程你可能需要好好的控制。
官方地址:
AI视频的质量和元素中间的连贯性有重要关系。 否则视频强扭出来的效果不太好。以下是主要操作界面的使用指南和截图
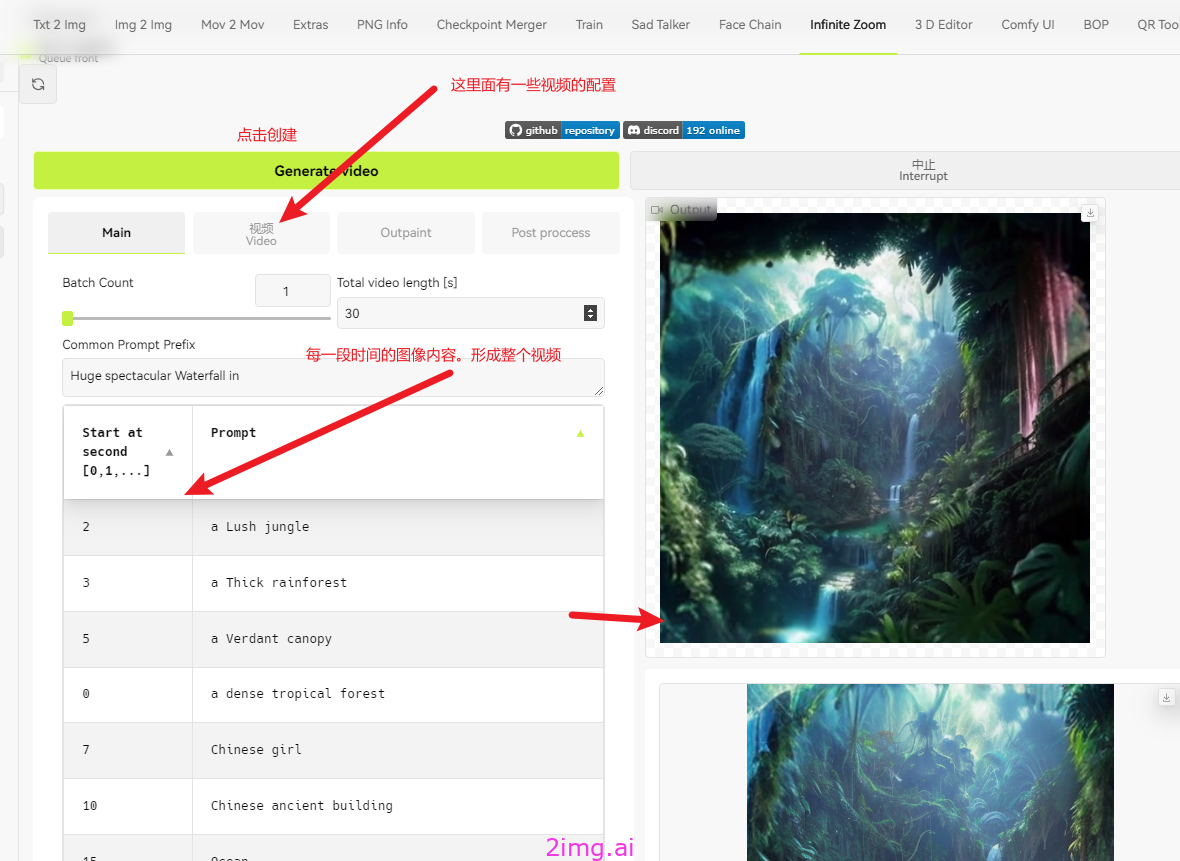
具体使用
第一步,我们使用模型。 https://civitai.com/models/299933/halcyon-sdxl-photorealism
第二步,具体尝试关键字
| 关键字 | |
| A deep underwater scene with a sunken pirate ship illuminated lit from within by a ghostly glow, cannons, surrounded by ghostly sea creatures in the dark waters, (tilt shift lens effect:1.2), light shafts, cinematic color grading, cinematic, epic, depth of field, bokeh, highly detailed, light leak, darkness, haunted, ghostly, dark and moody lighting | |
| A deep underwater scene with a sunken pirate ship illuminated lit from within by a ghostly glow, cannons, surrounded by ghostly sea creatures in the dark waters, (tilt shift lens effect:1.2), light shafts, cinematic color grading, cinematic, epic, depth of field, bokeh, highly detailed, light leak, darkness, haunted, ghostly, dark and moody lighting | |
| 4K photograph, Cinematic scene of a strong human (Buzz Lightyear:1.2) astronaut wearing massive heavy (warhammer 40k:1.2) chaos marine grey gold armor, (glowing green magic:1.5), glass bubble helmet, cinematic lighting, (cinematic color grading:1.2), rocky alien planet, dark moody lighting, casting a spell, extremely detailed armor, adeptus mechanicus, walking through a sandstorm, small (helmet:1.4), sword, detailed textures, fuji cinestill, sunset <lora:Dystopia:0.3> <lora:add-detail-xl:1> | |
| 1girl, photograph of a young gypsy woman looking over shoulder at viewer, tiny transparent shawl, ((partially braided sunkissed hair blowing in the wind)), ((backlighting)), (cinematic color grading:1.2), turquoise and silver jewelry, large statement amulet, epic, perfect female face, realism, Beautiful desert dusk, light leak, lens flare, aesthetic, realism, masterpiece, studio quality, warm Cinematic lighting, HDR, HQ, 8k, 4k, Amazing, Photorealistic, Hyper realistic, light rays, f2.0, dust particles, sharp focus, light particles <lora:add-detail-xl:1>, backlit, dark moody lighting | |
| a cyan scifi futuristic concept motorcycle, (TRON rider:1), curvy and aerodynamic, Kowloon walled city narrow winding alleyway, light speed, flash, (heavy rain:1.2), motion trail, darkness, (speed lines:1.1), (motion blur:1.1), high contrast, deep focus, TRON, style by Ridley Scott, Cyberpunk 2077, Bladerunner, fog, mist, epic visual effects, arc lightning, underglow, interstellar, flow, detailed, scifi, extremely detailed textures, star blast, dark vibrant colors, cosmic art, stars in background, headlights, cinematic scene, lens flare, cinematic color grading, film still, god rays, glow, art of Doug Chiang and John Park glowneon, fuji cinestill, light leak, glowing, sparks, lightning, ultra detailed <lora:add-detail-xl:2>, dramatic lighting <lora:blacklight_makeup_v2:1> ultraviolet blacklight reactive paint, powerlines, catwalks, alleyway <lora:SDS_Contrast tool_XL:0.8> |
此时,生成5s的内容,和视频的输出结果。
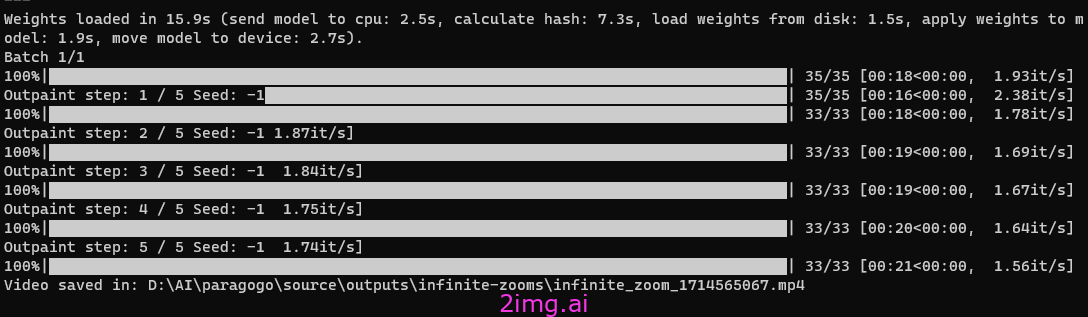
如果碰到MPEG的问题,可能是处理FFMPEG4 的组件没有。 放到任意位置,加到 PATH中即可。
如下图中的3个可执行最终文件,如你这边没有可自行下载FFMPEG编译后获得,或者直接联系我发你。
3 Mov2Mov
这个插件也是SD中的。主要的作用从名字上可以直观的看出来。通过Movie 生成 Movie。
我看到过一个NBA的真人视频被卡通形象替换了,自己尝试,但是效果不是很好。具体是否缺失了什么重要的内容,可能还需要读者自己研究深挖下。我只能浅尝辄止了。
插件介绍
下载地址:https://github.com/Scholar01/sd-webui-mov2mov
下载后直接放到SD的插件目录即可。
主要使用步骤:
见下图
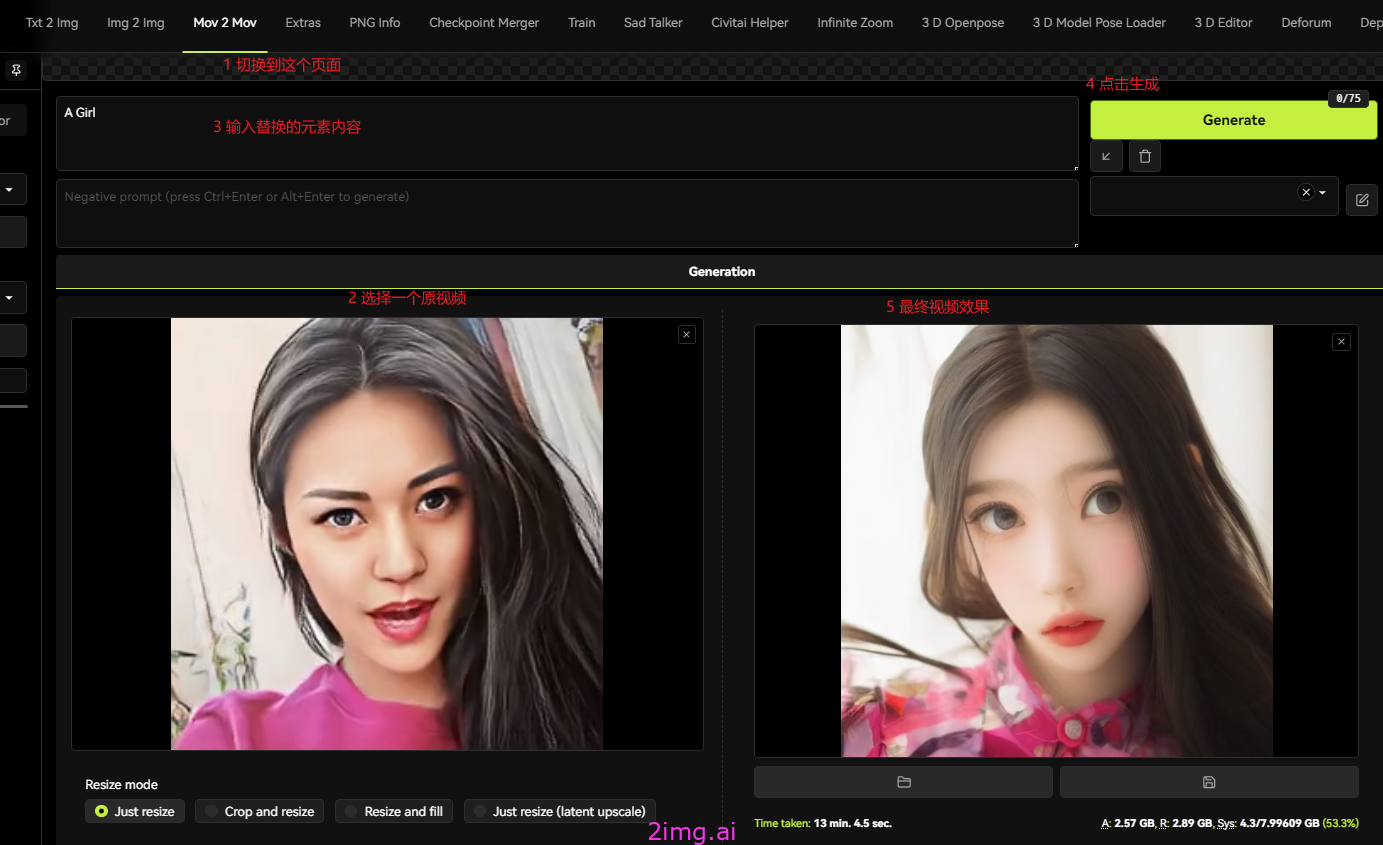
将AI视频转化为动漫风格
具体操作步骤如下:
- 在Stable Diffusion的WebUI界面中选择“mov2mov”选项卡。
- 点击“选择视频”按钮,选择要进行转换的AI视频文件。
- 在“模型选择”中,我们可以选择一款适合动漫风格的模型,例如“AWPainting”模型。该模型可以在国内知名的AI模型分享社区“哩布哩布AI”上下载,并放入Stable Diffusion对应文件夹中。
- 调整其他参数,如“迭代次数”、“步长”等,以达到满意的效果。
- 点击“开始转换”按钮,等待转换完成。
转换完成后,我们就可以在“输出文件夹”中看到转换后的动漫风格视频了。此时,我们可以使用视频编辑软件对其进行进一步的编辑和处理,如添加音效、字幕等,以制作出更加精美的AI动画。
注意:
Mov2Mov的本质是一帧一帧的处理,将原来每帧中的内容,替换成AI生成的。再形成视频。因此耗时也比较久。
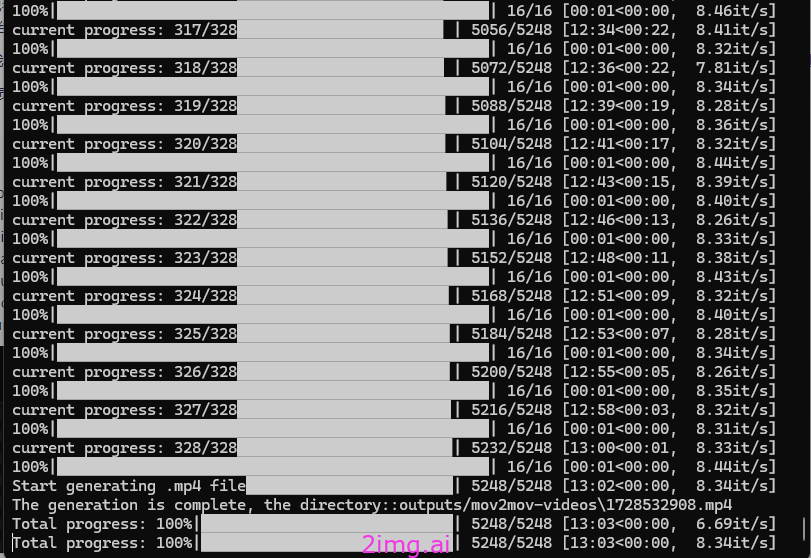
下面这个使用原始NBA视频,用卡通人物代替了。但是真实人物的动作都被大致保留了。形成了卡通画视频的效果。
Text2Video
Text2Video 一键生成视频. 也是SD中的一个插件,主要提供用户输入文字,然后自动帮你一键生成视频内容。
听上去不错,但是实际的效果可能会偏差比较大。 但无论如何,简单易用对吧。
插件介绍
官方地址:
模型和显存占用情况
6 GB 的 vram 应该足以在 256×256 分辨率下在低 vram vae 的 GPU 上运行
24 帧长的 256×256 视频绝对可以装入 12GB 的 NVIDIA GeForce RTX 2080 Ti,或者如果你有一个支持 Torch2 注意力优化的显卡,你可以将长达 125 帧(8 秒)的视频放入相同的 12 GB 的 VRAM 中!
在相同条件下,250 帧(16 秒)需要 20 GB。
具体使用
- 在使用前,我们需要下载针对Model Type2种分类下的模型文件,大于20G左右还是比较大的。
- ModelScope的下载地址: https://huggingface.co/ali-vilab/modelscope-damo-text-to-video-synthesis/tree/main 。下载完成后请放在目录stable-diffusion-webui/models/ModelScope/t2v
- VideoCrafter的下载地址:https://drive.google.com/file/d/13ZZTXyAKM3x0tObRQOQWdtnrI2ARWYf_/view 。下载完成后请放在目录models/VideoCrafter/model.ckpt
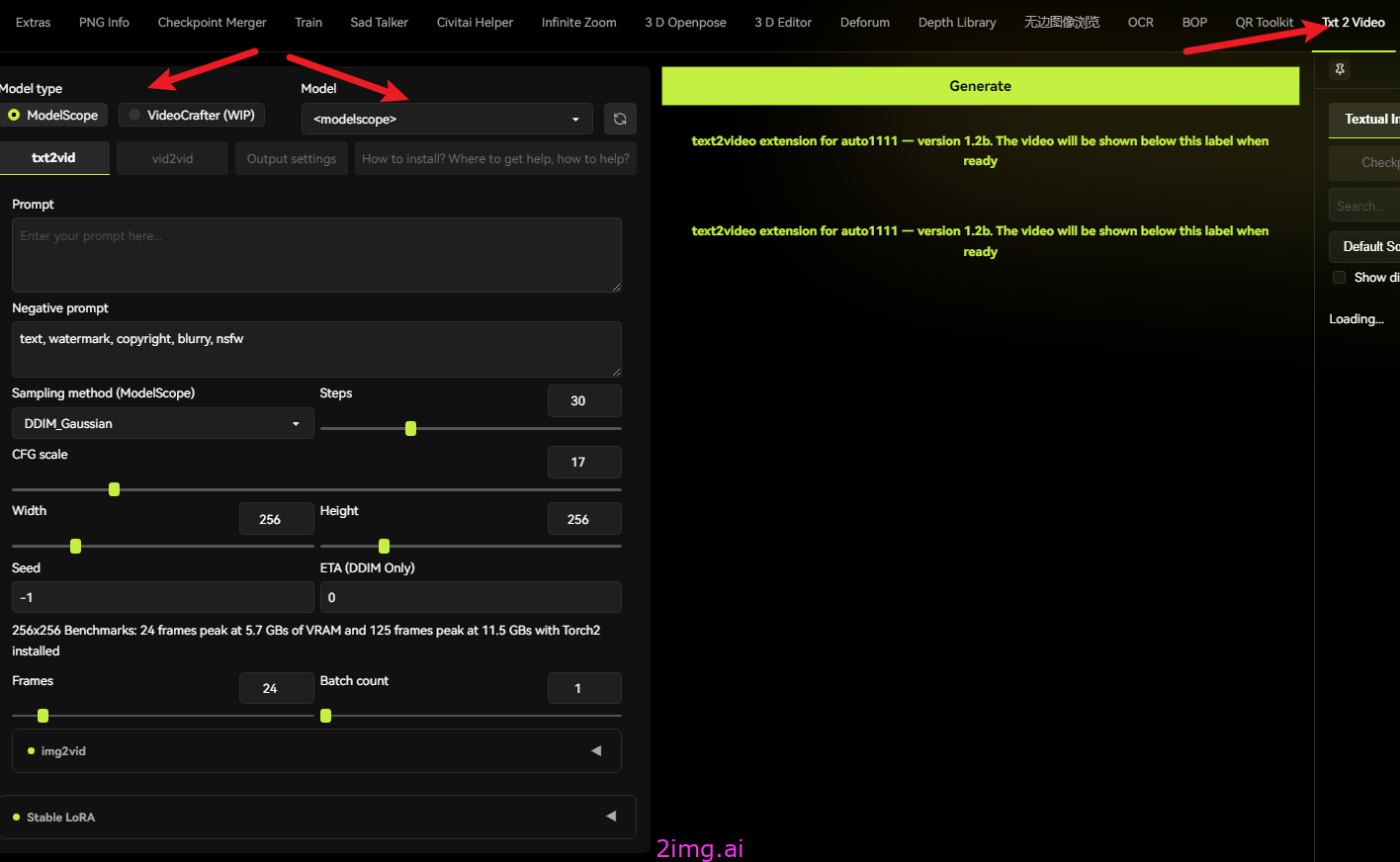
我们在该插件的Prompt区域输入关键字,描述我们的视频的主要内容。点击生成。
可以看到Console中开始进行各种处理了
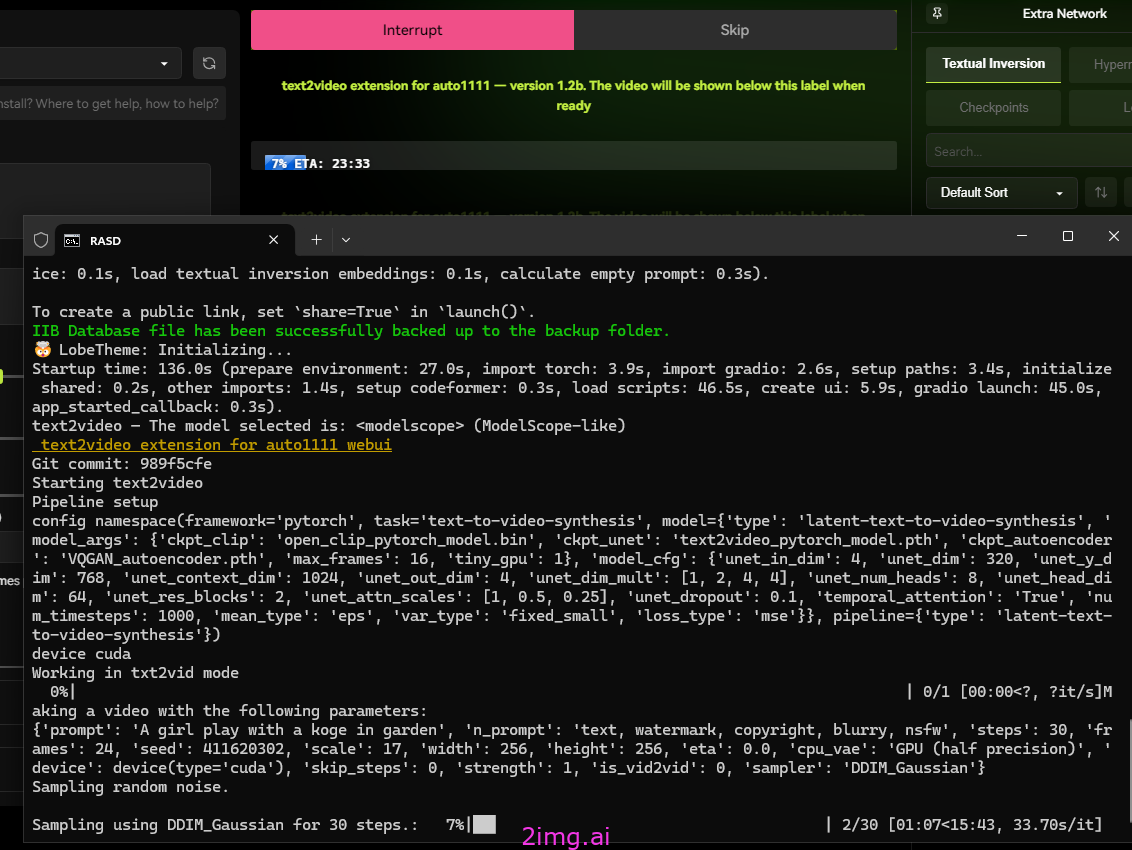
让一个女孩子笑。
生成很快,效果还可以。
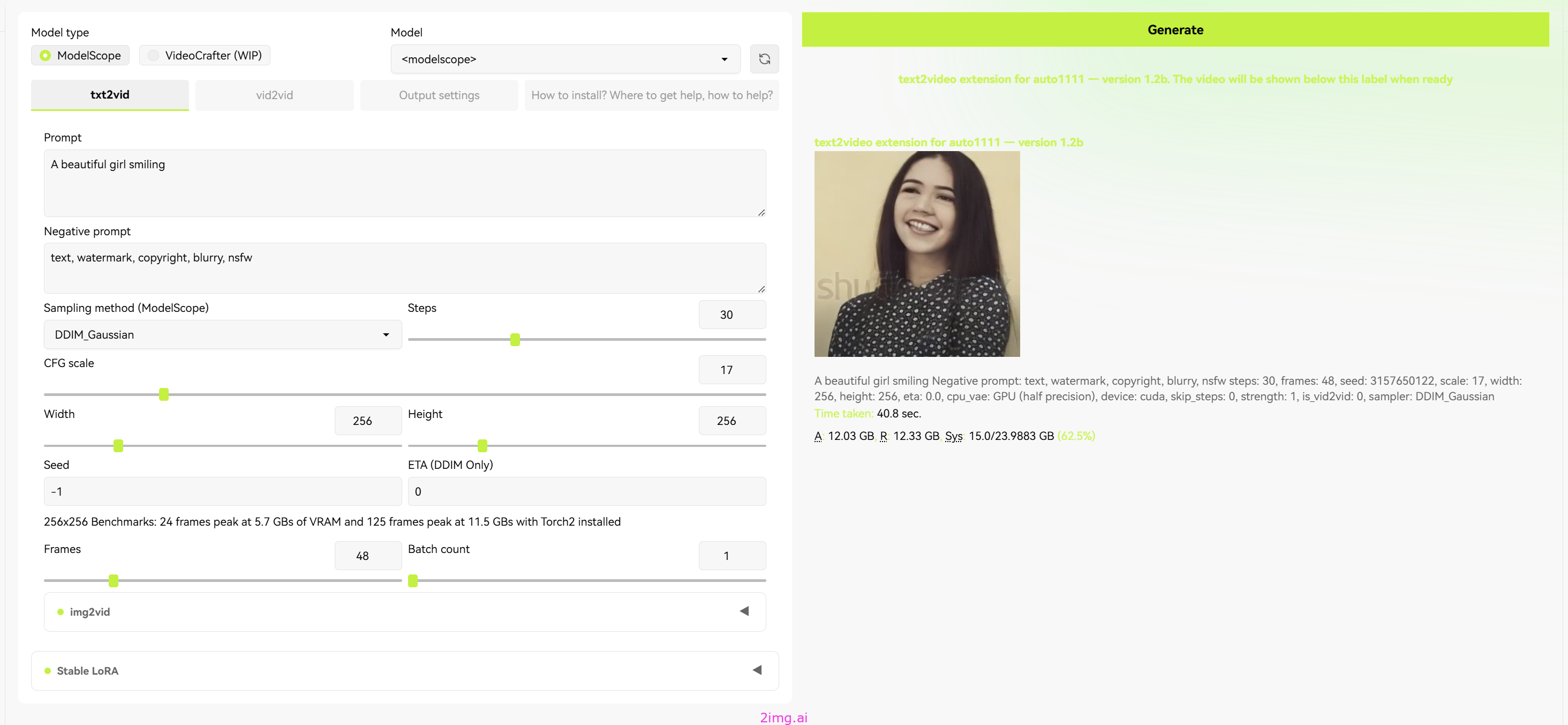
总体来看,还是可以的。
至少比较有趣。
MoneyPrintTurbo
我翻译过来是钞票打印机. 国人自己开发的开源框架。使用起来很方便,不过就是时不时问题出现。
官方地址: https://github.com/harry0703/MoneyPrinterTurbo
版本:MoneyPrinterTurbo v1.1.2
主界面:
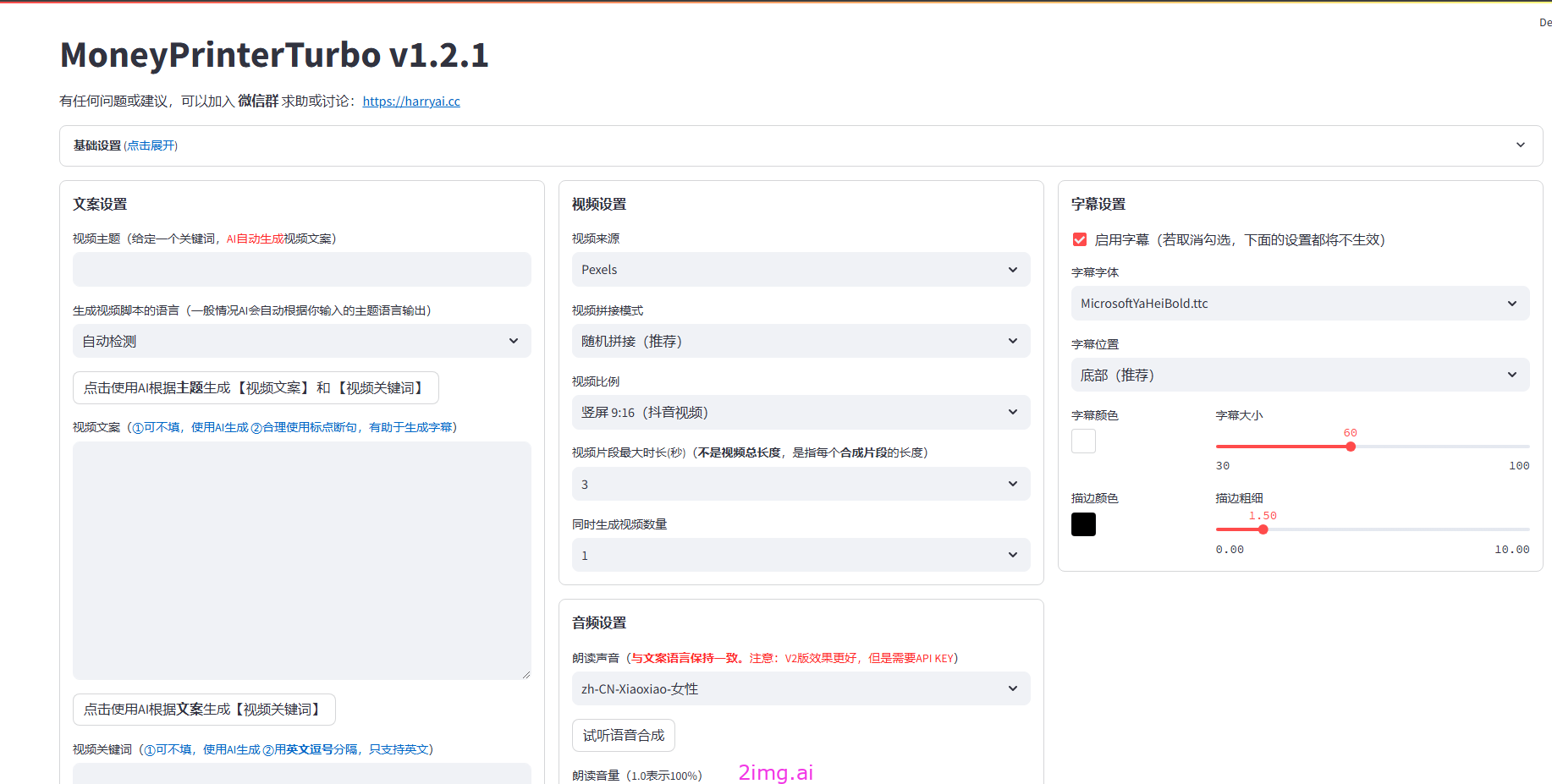
真实的使用过程需要配置具体内容:
- 需要去网站 申请 API Key。 https://www.pexels.com/
pexels_api_key
pexels_api_keys = [ “r6116DzQWaT8nhUIjM8Nnkn0pKXccRjOIXw7EWzTlqaT3xsUBXuHoYDB”,]
配置文件中内容是这样的
- 配置大模型 OpenAI的内容
openai_api_key = “你的Key” openai_base_url = “https://api.openai.com/v1” openai_model_name = “gpt-3.5-turbo”
- 可能需要配置Console翻墙能力
CMD中执行,需要
set http_proxy=http://127.0.0.1:7890 & set https_proxy=http://127.0.0.1:7890 cmd下运行
确保科学上网成功。
功能特性
- 完整的 MVC架构,代码 结构清晰,易于维护,支持
API和Web界面 - 支持视频文案 AI自动生成,也可以自定义文案
- 支持多种 高清视频 尺寸
- 竖屏 9:16,
1080x1920 - 横屏 16:9,
1920x1080
- 竖屏 9:16,
- 支持 批量视频生成,可以一次生成多个视频,然后选择一个最满意的
- 支持 视频片段时长设置,方便调节素材切换频率
- 支持 中文 和 英文 视频文案
- 支持 多种语音 合成
- 支持 字幕生成,可以调整
字体、位置、颜色、大小,同时支持字幕描边设置 - 支持 背景音乐,随机或者指定音乐文件,可设置
背景音乐音量 - 视频素材来源 高清,而且 无版权,也可以使用自己的本地素材
- 支持 OpenAI、moonshot、Azure、gpt4free、one-api、通义千问、Google Gemini、Ollama 等多种模型接入
后期计划
- GPT-SoVITS 配音支持
- 优化语音合成,利用大模型,使其合成的声音,更加自然,情绪更加丰富
- 增加视频转场效果,使其看起来更加的流畅
- 增加更多视频素材来源,优化视频素材和文案的匹配度
- 增加视频长度选项:短、中、长
- 增加免费网络代理,让访问OpenAI和素材下载不再受限
- 朗读声音和背景音乐,提供实时试听
- 支持更多的语音合成服务商,比如 OpenAI TTS
- 自动上传到YouTube平台
同时它提供一键安装和Docker的不同方式。不过获取视频源的地方不是很针对中国市场,B站视频等目前的版本还没有支持到。所以视频内容不是很对的上文本内容。
但无论如何,生成垃圾视频的能力是完全足够了。
注意:
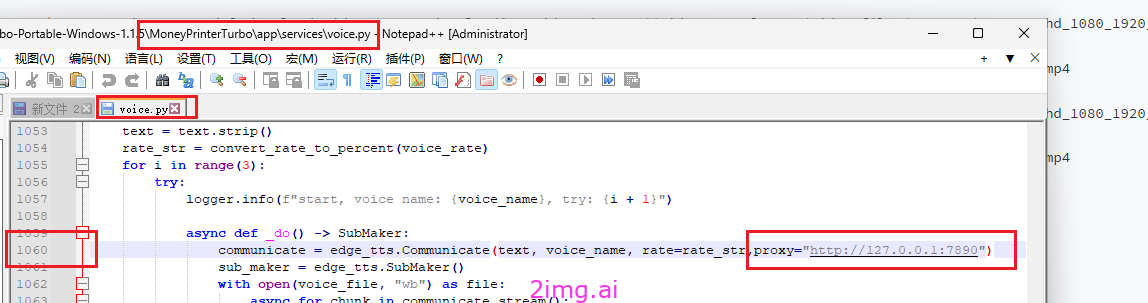
最近TTS语音模块貌似有访问不了的情况,结合论坛的修复方案,可以参考下图。
增加一段Proxy的设置代码即可。
好了,今天就介绍到这里。这些视频制作的能力我评估给出4星价值。
后续我会介绍能力更强的5星视频能力。
当然这些都是免费的方案,请不要和付费的商业方案做对比。你懂的。

2024年底了,祝大家2025 更好。
RA/SD 衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/8091