
前言:
上一章,我们介绍了关键字的权重控制和一些小技巧
本章,我们介绍更多的提示词高级功法。同时也指出像六脉神剑一样,好的坏的作品有时候是个谜。
我们之前的内容,对于一些基本控制有了长足的了解,当我们面对更加商业化的正式需求,会要求更多更细的内容时,我们会要求更为接地气的行为控制能力。
段落化,报告化,结构化的内容结果输出和中间流转过程控制是后续高质量AIGC内容的几个重要要求方向,本文在这方面加强了更多的资料内容。更多资料进: 2img.ai
知识点:
- Prompt关键字的神秘
- 如何控制最终结果长度
- 如何控制不想要的品质或者内容
关键字的痛
大家都知道六脉神剑是超级强大的武功存在,然而在段誉的手中,是好是坏。关键字在RA/SD体系中也是如此。有时候你可以制作出特别好的作品,有时候却不起作用。为什么呢?
我们还需要多多学习和理解。
Prompt 开发也采用类似循环迭代的方式,逐步逼近最优。
具体来说,有了任务想法后,可以先编写初版 Prompt,注意清晰明确并给模型充足思考时间。运行后检查结果,如果不理想,则分析 Prompt 不够清楚或思考时间不够等原因,做出改进,再次运行。如此循环多次,终将找到适合应用的 Prompt。
总之,很难有适用于世间万物的所谓“最佳 Prompt ”,开发高效 Prompt 的关键在于找到一个好的迭代优化过程,而非一开始就要求完美。通过快速试错迭代,可有效确定符合特定应用的最佳 Prompt 形式。


提示优化1 控制长度
在看到语言模型根据产品说明生成的第一个版本营销文案后,我们注意到文本长度过长,不太适合用作简明的电商广告语。所以这时候就需要对 Prompt 进行优化改进。具体来说,第一版结果满足了从技术说明转换为营销文案的要求,描写了中世纪风格办公椅的细节。但是过于冗长的文本不太适合电商场景。这时我们就可以在 Prompt 中添加长度限制,要求生成更简洁的文案。
提取回答并根据空格拆分,中文答案为97个字,较好地完成了设计要求。
# 优化后的 Prompt,要求生成描述不多于 50 词
prompt = f"""
您的任务是帮助营销团队基于技术说明书创建一个产品的零售网站描述。
根据```标记的技术说明书中提供的信息,编写一个产品描述。
使用最多50个词。
技术规格:```{fact_sheet_chair}```
"""
response = get_completion(prompt)
print(response)
中世纪风格办公家具系列,包括文件柜、办公桌、书柜、会议桌等。多种颜色和涂层可选,可带或不带扶手。底座涂层选项为不锈钢、哑光黑色、光泽白色或铬。适用于家庭或商业场所,符合合同使用资格。意大利制造。我们可以计算一下输出的长度。
# 由于中文需要分词,此处直接计算整体长度
len(response)9当在 Prompt 中设置长度限制要求时,语言模型生成的输出长度不总能精确符合要求,但基本能控制在可接受的误差范围内。比如要求生成50词的文本,语言模型有时会生成60词左右的输出,但总体接近预定长度。
这是因为语言模型在计算和判断文本长度时依赖于分词器,而分词器在字符统计方面不具备完美精度。目前存在多种方法可以尝试控制语言模型生成输出的长度,比如指定语句数、词数、汉字数等。
虽然语言模型对长度约束的遵循不是百分之百精确,但通过迭代测试可以找到最佳的长度提示表达式,使生成文本基本符合长度要求。这需要开发者对语言模型的长度判断机制有一定理解,并且愿意进行多次试验来确定最靠谱的长度设置方法。
提示优化2: 处理抓错文本细节
在迭代优化 Prompt 的过程中,我们还需要注意语言模型生成文本的细节是否符合预期。
比如在这个案例中,进一步分析会发现,该椅子面向的其实是家具零售商,而不是终端消费者。所以生成的文案中过多强调风格、氛围等方面,而较少涉及产品技术细节,与目标受众的关注点不太吻合。
这时候我们就可以继续调整 Prompt,明确要求语言模型生成面向家具零售商的描述,更多关注材质、工艺、结构等技术方面的表述。
通过迭代地分析结果,检查是否捕捉到正确的细节,我们可以逐步优化 Prompt,使语言模型生成的文本更加符合预期的样式和内容要求。
细节的精准控制是语言生成任务中非常重要的一点。我们需要训练语言模型根据不同目标受众关注不同的方面,输出风格和内容上都适合的文本。
# 优化后的 Prompt,说明面向对象,应具有什么性质且侧重于什么方面
prompt = f"""
您的任务是帮助营销团队基于技术说明书创建一个产品的零售网站描述。
根据```标记的技术说明书中提供的信息,编写一个产品描述。
该描述面向家具零售商,因此应具有技术性质,并侧重于产品的材料构造。
使用最多50个单词。
技术规格: ```{fact_sheet_chair}```
"""
response = get_completion(prompt)
print(response)这款中世纪风格办公家具系列包括文件柜、办公桌、书柜和会议桌等,适用于家庭或商业场所。可选多种外壳颜色和底座涂层,底座涂层选项为不锈钢、哑光黑色、光泽白色或铬。
椅子可带或不带扶手,可选软地板或硬地板滚轮,两种座椅泡沫密度可选。外壳底座滑动件采用改性尼龙PA6/PA66涂层的铸铝,座椅采用HD36泡沫。原产国为意大利。
可见,通过修改 Prompt ,模型的关注点倾向了具体特征与技术细节。
我可能进一步想要在描述的结尾展示出产品 ID。因此,我可以进一步改进这个 Prompt ,要求在描述的结尾,展示出说明书中的7位产品 ID。
# 更进一步
prompt = f"""
您的任务是帮助营销团队基于技术说明书创建一个产品的零售网站描述。
根据```标记的技术说明书中提供的信息,编写一个产品描述。
该描述面向家具零售商,因此应具有技术性质,并侧重于产品的材料构造。
在描述末尾,包括技术规格中每个7个字符的产品ID。
使用最多50个单词。
技术规格: ```{fact_sheet_chair}```
"""
response = get_completion(prompt)
print(response)这款中世纪风格的办公家具系列包括文件柜、办公桌、书柜和会议桌等,适用于家庭或商业场所。可选多种外壳颜色和底座涂层,底座涂层选项为不锈钢、哑光黑色、光泽白色或铬。椅子可带或不带扶手,可选塑料前后靠背装饰或10种面料和6种皮革的全面装饰。座椅采用HD36泡沫,可选中等或高密度,座椅高度44厘米,深度41厘米。外壳底座滑动件采用改性尼龙PA6/PA66涂层的铸铝,外壳厚度为10毫米。原产国为意大利。产品ID:SWC-100/SWC-110。通过上面的示例,我们可以看到 Prompt 迭代优化的一般过程。与训练机器学习模型类似,设计高效 Prompt 也需要多个版本的试错调整。
具体来说,第一版 Prompt 应该满足明确和给模型思考时间两个原则。在此基础上,一般的迭代流程是:首先尝试一个初版,分析结果,然后继续改进 Prompt,逐步逼近最优。许多成功的Prompt 都是通过这种多轮调整得出的。
都是废话,总来来说,就是不断的尝试,调优。
提示优化3: 添加表格描述
继续添加指引,要求提取产品尺寸信息并组织成表格,并指定表格的列、表名和格式;再将所有内容格式化为可以在网页使用的 HTML。
# 要求它抽取信息并组织成表格,并指定表格的列、表名和格式
prompt = f"""
您的任务是帮助营销团队基于技术说明书创建一个产品的零售网站描述。
根据```标记的技术说明书中提供的信息,编写一个产品描述。
该描述面向家具零售商,因此应具有技术性质,并侧重于产品的材料构造。
在描述末尾,包括技术规格中每个7个字符的产品ID。
在描述之后,包括一个表格,提供产品的尺寸。表格应该有两列。第一列包括尺寸的名称。第二列只包括英寸的测量值。
给表格命名为“产品尺寸”。
将所有内容格式化为可用于网站的HTML格式。将描述放在<div>元素中。
技术规格:```{fact_sheet_chair}```
"""
response = get_completion(prompt)
print(response)<div>
<h2>中世纪风格办公家具系列椅子</h2>
<p>这款椅子是中世纪风格办公家具系列的一部分,适用于家庭或商业场所。它有多种外壳颜色和底座涂层可选,包括不锈钢、哑光黑色、光泽白色或铬。您可以选择带或不带扶手的椅子,以及软地板或硬地板滚轮选项。此外,您可以选择两种座椅泡沫密度:中等(1.8磅/立方英尺)或高(2.8磅/立方英尺)。</p>
<p>椅子的外壳底座滑动件是改性尼龙PA6/PA66涂层的铸铝,外壳厚度为10毫米。座椅采用HD36泡沫,底座是五个轮子的塑料涂层铝底座,可以进行气动椅子调节,方便升降。此外,椅子符合合同使用资格,是您理想的选择。</p>
<p>产品ID:SWC-100</p>
</div>
<table>
<caption>产品尺寸</caption>
<tr>
<th>宽度</th>
<td>20.87英寸</td>
</tr>
<tr>
<th>深度</th>
<td>20.08英寸</td>
</tr>
<tr>
<th>高度</th>
<td>31.50英寸</td>
</tr>
<tr>
<th>座椅高度</th>
<td>17.32英寸</td>
</tr>
<tr>
<th>座椅深度</th>
<td>16.14英寸</td>
</tr>
</table>上述输出为 HTML 代码,我们可以使用 Python 的 IPython 库将 HTML 代码加载出来。
# 表格是以 HTML 格式呈现的,加载出来
from IPython.display import display, HTML
display(HTML(response))中世纪风格办公家具系列椅子
这款椅子是中世纪风格办公家具系列的一部分,适用于家庭或商业场所。它有多种外壳颜色和底座涂层可选,包括不锈钢、哑光黑色、光泽白色或铬。您可以选择带或不带扶手的椅子,以及软地板或硬地板滚轮选项。此外,您可以选择两种座椅泡沫密度:中等(1.8磅/立方英尺)或高(2.8磅/立方英尺)。
椅子的外壳底座滑动件是改性尼龙PA6/PA66涂层的铸铝,外壳厚度为10毫米。座椅采用HD36泡沫,底座是五个轮子的塑料涂层铝底座,可以进行气动椅子调节,方便升降。此外,椅子符合合同使用资格,是您理想的选择。
产品ID:SWC-100
产品尺寸
| 宽度 | 20.87英寸 |
|---|---|
| 深度 | 20.08英寸 |
| 高度 | 31.50英寸 |
| 座椅高度 | 17.32英寸 |
| 座椅深度 | 16.14英寸 |
其余控制
大语言模型中的 “温度”(temperature) 参数可以控制生成文本的随机性和多样性。temperature 的值越大,语言模型输出的多样性越大;temperature 的值越小,输出越倾向高概率的文本。
举个例子,在某一上下文中,语言模型可能认为“比萨”是接下来最可能的词,其次是“寿司”和“塔可”。若 temperature 为0,则每次都会生成“比萨”;而当 temperature 越接近 1 时,生成结果是“寿司”或“塔可”的可能性越大,使文本更加多样。
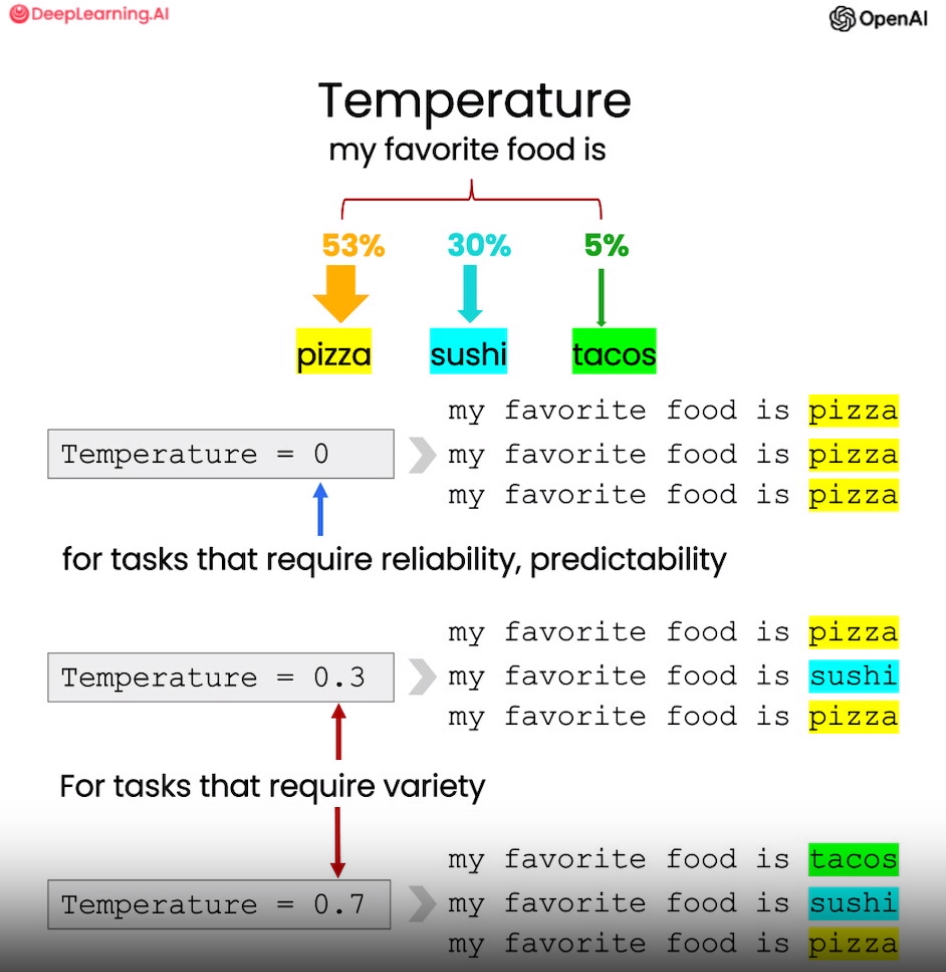
图 1.7 温度系数
一般来说,如果需要可预测、可靠的输出,则将 temperature 设置为0,在所有课程中,我们一直设置温度为零;如果需要更具创造性的多样文本,那么适当提高 temperature 则很有帮助。调整这个参数可以灵活地控制语言模型的输出特性。
在下面例子中,针对同一段来信,我们提醒语言模型使用用户来信中的详细信息,并设置一个较高的 temperature ,运行两次,比较他们的结果有何差异。
# 第一次运行
prompt = f"""
你是一名客户服务的AI助手。
你的任务是给一位重要的客户发送邮件回复。
根据通过“```”分隔的客户电子邮件生成回复,以感谢客户的评价。
如果情感是积极的或中性的,感谢他们的评价。
如果情感是消极的,道歉并建议他们联系客户服务。
请确保使用评论中的具体细节。
以简明和专业的语气写信。
以“AI客户代理”的名义签署电子邮件。
客户评价:```{review}```
评论情感:{sentiment}
"""
response = get_completion(prompt, temperature=0.7)
print(response)尊敬的客户,
感谢您对我们产品的评价。我们非常重视您的意见,并对您在使用过程中遇到的问题表示诚挚的道歉。
我们对价格的变动深感抱歉。根据您的描述,我们了解到在12月第二周,套装的价格出现了不同程度的上涨。我们会进一步调查此事,并确保我们的定价策略更加透明和一致。
您提到了产品部分的质量下降,特别是锁定刀片的部分。我们对此感到非常遗憾,并将反馈给我们的研发团队,以便改进产品的设计和质量控制。我们始终致力于提供优质的产品,以满足客户的需求和期望。
此外,我们将非常感谢您分享了您对产品的使用方式和相关提示。您的经验和建议对我们来说非常宝贵,我们将考虑将其纳入我们的产品改进计划中。
如果您需要进一步帮助或有其他问题,请随时联系我们的客户服务团队。我们将竭诚为您提供支持和解决方案。
再次感谢您的反馈和对我们的支持。我们将继续努力提供更好的产品和服务。
祝您一切顺利!
AI客户代理第二次运行输出结果会发生变化:
# 第二次运行
prompt = f"""
你是一名客户服务的AI助手。
你的任务是给一位重要的客户发送邮件回复。
根据通过“```”分隔的客户电子邮件生成回复,以感谢客户的评价。
如果情感是积极的或中性的,感谢他们的评价。
如果情感是消极的,道歉并建议他们联系客户服务。
请确保使用评论中的具体细节。
以简明和专业的语气写信。
以“AI客户代理”的名义签署电子邮件。
客户评价:```{review}```
评论情感:{sentiment}
"""
response = get_completion(prompt, temperature=0.7)
print(response)亲爱的客户,
非常感谢您对我们产品的评价和反馈。我们非常重视您的意见,并感谢您对我们产品的支持。
首先,我们对价格的变动感到非常抱歉给您带来了困扰。我们会认真考虑您提到的情况,并采取适当的措施来改进我们的价格策略,以避免类似情况再次发生。
关于产品质量的问题,我们深感抱歉。我们一直致力于提供高质量的产品,并且我们会将您提到的问题反馈给我们的研发团队,以便改进产品的设计和制造过程。
如果您需要更多关于产品保修的信息,或者对我们的其他产品有任何疑问或需求,请随时联系我们的客户服务团队。我们将竭诚为您提供帮助和支持。
再次感谢您对我们产品的评价和支持。我们将继续努力提供优质的产品和出色的客户服务,以满足您的需求。
祝您度过愉快的一天!
AI客户代理温度(temperature)参数可以控制语言模型生成文本的随机性。温度为0时,每次使用同样的 Prompt,得到的结果总是一致的。而在上面的样例中,当温度设为0.7时,则每次执行都会生成不同的文本。
所以,这次的结果与之前得到的邮件就不太一样了。再次执行同样的 Prompt,邮件内容还会有变化。因此。我建议读者朋友们可以自己尝试不同的 temperature ,来观察输出的变化。总体来说,temperature 越高,语言模型的文本生成就越具有随机性。可以想象,高温度下,语言模型就像心绪更加活跃,但也可能更有创造力。
适当调节这个超参数,可以让语言模型的生成更富有多样性,也更能意外惊喜。希望这些经验可以帮助你在不同场景中找到最合适的温度设置。
总结
作为 Prompt 工程师,关键不是一开始就要求完美的 Prompt,而是掌握有效的 Prompt 开发流程。
具体来说,首先编写初版 Prompt,然后通过多轮调整逐步改进,直到生成了满意的结果。
对于更复杂的应用,可以在多个样本上进行迭代训练,评估 Prompt 的平均表现。
在应用较为成熟后,才需要采用在多个样本集上评估 Prompt 性能的方式来进行细致优化。因为这需要较高的计算资源。
总之,Prompt 工程师的核心是掌握 Prompt 的迭代开发和优化技巧,而非一开始就要求100%完美。通过不断调整试错,最终找到可靠适用的 Prompt 形式才是设计 Prompt 的正确方法。
个人心得:
- 可以用 【侧重于xxx】,要求AI输出 侧重于某些内容的关键点
- 可以用 【提取xxxx】,要求AI输出的内容从总结性,或者范式文本中提取重要的内容。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/79