
一、开源喜讯,AI 视觉新时代开启
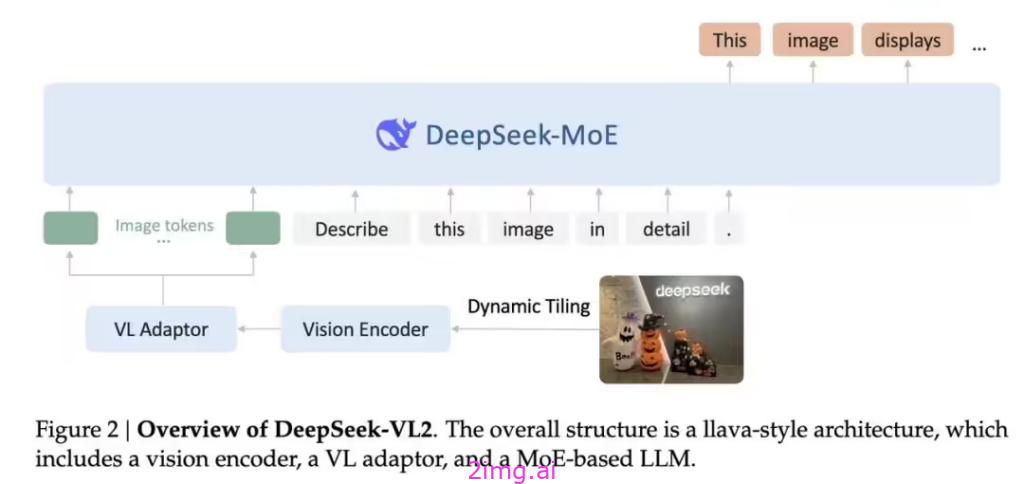

(一)DeepSeek 官方重磅发布
嘿,各位小伙伴们!就在 2024 年 12 月 13 日,DeepSeek 团队在官方公众号发布了一则重磅消息,那就是他们最新研发的 DeepSeek-VL2 模型正式开源啦!这可绝对是 AI 视觉领域的一件大事呀,它标志着 DeepSeek 的视觉模型正式迈入了混合专家模型(Mixture of Experts,简称 MoE)时代呢。从此,我们可以预见到 AI 视觉模型将会在这个新的阶段迎来更多的发展与突破,为我们带来更多的惊喜哦。
(二)亮眼评测指标展现优势
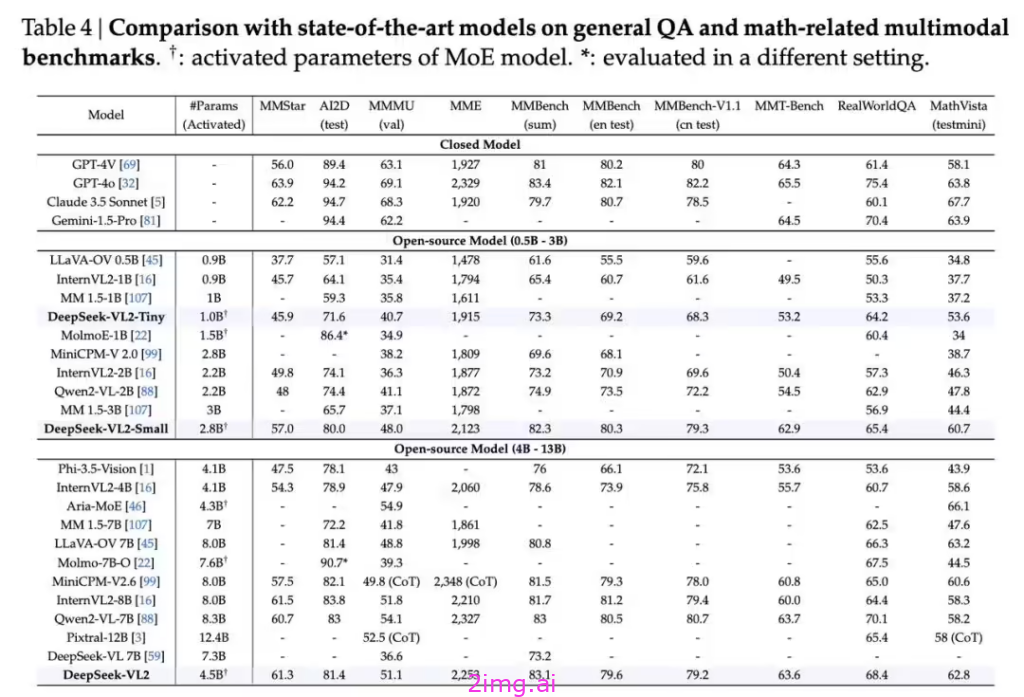
DeepSeek-VL2 模型可不简单,它在各项评测指标上都表现得极为优异呢。和它的前代 DeepSeek-VL 相比,其训练数据量实现了翻倍的增长,这就像是给它注入了强大的能量一般。而且呀,它还引入了梗图理解、视觉定位、视觉故事生成等一系列超实用的新能力,让它在处理复杂视觉任务时更加游刃有余。这些亮眼的评测指标以及新增的能力,无疑展现出了它独特的优势,也让我们越发好奇它在实际应用中究竟能发挥出怎样强大的作用啦,接下来就让我们一起深入探究一番吧。
二、DeepSeek-VL2 亮点全解析


(一)数据量翻倍,功能更丰富
DeepSeek-VL2 相较于第一代的 DeepSeek-VL 模型,可是有着非常显著的提升哦。其优质训练数据量直接增加了一倍呢,这就好比给它的 “知识宝库” 扩充了大量的宝藏,让它能够汲取更多的信息,为更强大的能力奠定基础呀。
而且呀,它还新引入了不少令人眼前一亮的能力,像梗图理解、视觉定位以及视觉故事生成等等。在当下这个网络信息丰富,梗图盛行的时代,它能理解梗图背后的含义,可太实用啦,让我们在处理这类充满趣味又带有独特文化的视觉内容时更加得心应手。视觉定位的能力呢,则有助于精准地确定图像中元素的位置,无论是对于图像分析还是后续的一些应用场景开发都大有益处。还有视觉故事生成,它可以根据图像内容编织出相应的故事,展现出了 DeepSeek-VL2 在多模态内容处理方面的巨大潜力呢,也使得它在应对复杂视觉任务的时候能够更加游刃有余啦。
(二)创新架构,支持动态分辨率
在架构方面,DeepSeek-VL2 也是亮点满满哦。它的视觉部分采用了非常巧妙的切图策略来支持动态分辨率图像呢。具体是怎么操作的呢?就是通过将图像切分成多张子图,再加上一张全局缩略图的方式,从而实现了对动态分辨率图像的支持呀。
这样的设计带来的好处可不少哦,它使得 DeepSeek-VL2 最多能够支持 1152×1152 的分辨率,而且对于 1:9 或者 9:1 这样极端的长宽比图像也能轻松应对啦。这意味着无论是那些高分辨率的专业科研图像,还是一些长宽比例比较特殊的创意图像等等,它都可以适配处理哦,极大地拓展了它的应用场景适应性,不管是科研数据的可视化展示,还是创意内容的生成环节,它都能发挥重要的作用呢。
(三)高效训练,成本性能双优
DeepSeek-VL2 在训练效率这块也有着出色的表现哦。它继承了 DeepSeek-VL 的三阶段训练流程,并且在此基础上做了很多优化呢。为了能够适配图像切片数量不定这样的难题呀,它引入了负载均衡策略,就像是一个智能的调度员,合理地分配资源,让训练过程更加顺畅哦。
同时呢,针对图像和文本数据,它还分别采用了不同的流水并行策略,而且对于混合专家模型(MoE)语言模型引入了专家并行的方式,通过这些手段,实现了低成本高性能的训练效果呀。这样一来,既可以保证训练的高效性,又能在一定程度上控制成本,让模型能够更快更好地训练出来,投入到实际的应用当中,为我们提供更优质的服务呢。
三、实际应用中的强大表现
(一)科研图表处理有妙招
DeepSeek-VL2 在科研图表处理方面可是有着独特的 “妙招” 哦。它得益于学习了更多的科研文档数据,所以能够轻松理解各种各样的科研图表呢。
而它的 Plot2Code 功能更是一大亮点呀,科研人员只需要将科研图表输入进去,它就能根据这个图像快速生成 Python 代码哦。这对于科研工作来说,可太实用啦,以往可能需要花费大量时间和精力去手动编写代码来处理分析这些图表数据,现在借助 DeepSeek-VL2 的这个功能,就能高效地完成这部分工作啦,大大地提高了科研人员在数据分析以及自动化脚本生成方面的效率,为科研工作的开展注入了强大的助力呢,也难怪它在学术界和工业界都备受关注啦。
(二)多场景应用显神通
DeepSeek-VL2 的动态分辨率支持让它在多场景应用中 “大显神通” 哦。比如说在图像编辑场景里呀,有时候我们需要处理不同分辨率的图像,可能有的图像分辨率很高,常规的处理方式就会比较吃力,或者有的图像长宽比很特殊,像 1:9 或者 9:1 这样极端的情况。但有了 DeepSeek-VL2 就不一样啦,它可以根据实际需要,灵活地调整图像处理方式,轻松应对各种不同规格的图像,让图像编辑变得更加顺畅高效,帮助图像编辑人员节省时间,还能提升处理效果呢。
再比如在虚拟现实场景中呀,不同的虚拟场景对于图像分辨率等要求也是千差万别,而 DeepSeek-VL2 凭借其支持动态分辨率的优势,可以适配各种场景需求,按需对图像进行处理,极大地提升了用户在虚拟现实体验中的沉浸感,同时也让相关工作人员在构建和优化虚拟场景时更加得心应手呀。可以说,它的应用广泛性真的是给众多领域都带来了极大的便利,提升了大家的工作效率和体验呢。
四、对 AI 领域及相关行业的影响

(一)丰富 AI 创作生态
DeepSeek-VL2 的开源对于 AI 绘画、写作等创作工具生态来说,无疑是注入了一股强大的新力量。在当下,AI 创作领域发展迅猛,各类工具层出不穷,但 DeepSeek-VL2 凭借其独特的优势,为开发者们提供了更丰富的案例与极具价值的参考。
比如在 AI 绘画方面,现有的一些工具可能在生成图像的创意性或者对特定风格的把控上各有所长,但 DeepSeek-VL2 通过其 MoE 架构以及强大的视觉理解能力,能够更好地理解创作者的意图,应对复杂的创作需求。像在创作一些带有故事性元素的插画时,它对梗图理解以及视觉故事生成的能力就能派上用场,使生成的内容不仅画面精美,还更具内涵和趣味性,提升了生成内容的质量与多样性。
在 AI 写作领域同样如此,它能够处理复杂的文本生成任务,结合图像信息等多模态内容,为创作者提供更全面、更贴合需求的创作思路和文本素材,辅助创作者打破创作瓶颈,产出更优质的文章。对比市场上其他的 AI 创作工具,DeepSeek-VL2 的全面性和对复杂任务的应对能力,使其在众多工具中脱颖而出,进一步丰富了整个 AI 创作生态,让创作者们有了更多的选择和发挥空间。
(二)推动行业变革发展
从行业角度来看,DeepSeek-VL2 的开源带来的影响是深远且具有变革性的。在技术层面,它所采用的创新架构和高效训练策略,如切图策略支持动态分辨率图像、引入负载均衡策略以及流水并行策略等,为其他 AI 视觉模型研发者提供了新的思路和方向。很多技术公司和科研机构会因此面临自我改革的压力,促使他们去深入研究并借鉴这些先进的技术手段,以提升自家产品的性能和竞争力,跟上行业发展的潮流。
在产品研发方向上,其开源可能会引发更多企业关注混合专家模型(MoE)结构的优势,进而在未来的产品规划中考虑融入类似的技术方案,推动整个 AI 视觉模型行业朝着更高效、更智能的方向发展。例如,可能会促使更多模型在处理不同分辨率图像、应对多样化视觉任务方面进行优化升级,拓展应用场景的覆盖范围。
对于消费者而言,DeepSeek-VL2 的出现让他们在选择 AI 视觉产品时有了新的优质选项,能够体验到更高效且精准的视觉处理能力。这也将激发他们对 AI 产品提出更高的期待,倒逼整个行业不断提升产品质量和服务水平,重塑 AI 视觉模型的市场格局,加速 AI 视觉技术在各行业的普及应用,推动各行业的数字化转型,让更多领域受益于 AI 视觉技术带来的便利和创新。
五、AI 发展带来的思考与展望
(一)面临的伦理等问题探讨
随着 DeepSeek-VL2 这样强大的 AI 视觉模型的出现以及 AI 技术的迅猛发展,我们也不得不去深入思考一些随之而来的问题,尤其是伦理和版权方面的问题。
大家都知道,AI 生成内容的能力越来越强,像 DeepSeek-VL2 既能处理科研图表,又能理解梗图,还能生成相应的文本内容等。但这就引发了一个疑问,这些由 AI 生成的内容,其版权归属到底该如何界定呢?是归属于研发模型的团队,还是使用模型去创作的使用者,亦或是其他相关方呢?这目前还缺乏非常明确清晰的规定,很容易在后续应用过程中产生版权纠纷。
从伦理角度来看,DeepSeek-VL2 这类强大的模型可以快速高效地生成各种视觉及文本内容,那会不会对一些创意工作者的就业产生冲击呢?毕竟很多原本需要人工去构思、创作的内容,现在借助模型就能快速产出了。而且对于创意工作者而言,长期依赖这样的工具,会不会导致他们自身创造性思维的减弱呢?此外,模型学习的数据来源广泛,如何确保其中涉及的个人隐私信息不被泄露,数据的安全性又该如何保障,这些都是亟待解决的重要伦理问题。
所以说,尽管 DeepSeek-VL2 的开源为我们带来了诸多便利和新的发展机遇,但在其后续的发展过程中,我们必须要重视并积极应对这些伦理、版权以及数据安全等方面的挑战,让 AI 技术可以在合理合规、符合伦理道德的轨道上不断前行,真正为人类所用,为社会创造价值。
(二)对未来应用的美好期许
虽然 AI 发展面临着诸多需要思考和解决的问题,但我们依旧可以对以 DeepSeek-VL2 为代表的 AI 技术未来在各行各业的应用满怀美好的期许。
在医疗领域,借助 DeepSeek-VL2 强大的图像理解能力以及对动态分辨率的支持,医生们可以更精准地分析 X 光片、CT 影像等医疗图像,辅助快速准确地诊断病情,甚至在一些复杂的手术规划方面,模型也可以通过处理相关的图像数据给出有价值的参考建议,提升手术的成功率,为患者带来更多康复的希望。
教育行业同样可以受益良多,老师能够利用 DeepSeek-VL2 的图像生成和理解功能,制作出更加生动有趣、互动性强的教学课件,比如对于一些抽象的科学知识、历史场景等,通过生成合适的图像或者解析相关的图表资料,让学生可以更好地理解和掌握,极大地提高教学质量和效果。
在娱乐产业方面,像影视制作、游戏开发等领域,DeepSeek-VL2 及其相关技术可以帮助创作者们更高效地打造出绚丽逼真的虚拟场景、角色形象等视觉内容,并且可以根据不同用户的需求快速生成定制化的娱乐体验,让大家能更好地沉浸在丰富多彩的娱乐世界当中。
关注我们的公众号,掌握最新资讯!

RA/SD 衍生者AI训练营。发布者:風之旋律,转载请注明出处:https://www.shxcj.com/archives/7879