
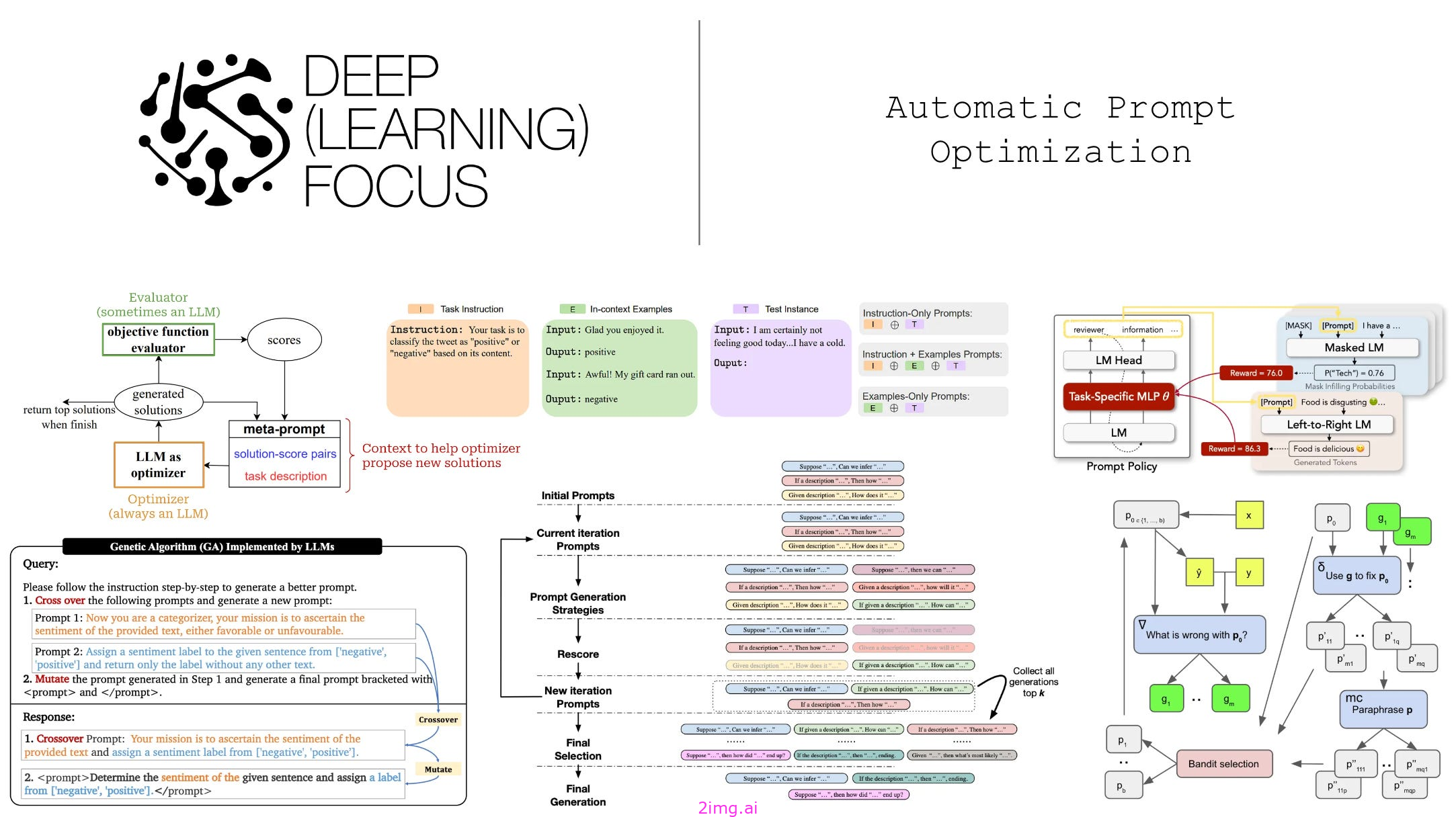
总览
本文分3个部分阐述相对比较理论的各种提示词工程的原理,算法和目前业界现状。
第一部分: 总结 (最后的先放最前,实现本文第二行让你从入门到绝望)
第二部分:自动改进提示(展示各种算法)
第三部分:提示词工程的基础知识 (展示各种方案,工作,内容)
由于技术能力有限及技术时效性,如有错误之处,尽请指教。随时联系我们 2img.ai 或 shxcj.com
先来张图大家先舒展下:

现在回到现实,
突然,
无论是大型语言模型(LLMs),还是其他类型的前沿模型-可以说是现代人工智能最具影响力的进步之一。通过用自然语言编写指令,几乎任何人都可以利用海量神经网络的力量来解决各种实际任务。
前几代深度学习模型在性能方面取得了令人印象深刻的成就,但LLMs不仅仅表现出色,也非常直观的使用.
非专家可以与这些模型互动,并亲自看到它们的潜力,这引起了人们对人工智能研究的空前关注。
“通过对自然语言指令的条件,大型语言模型(LLMs)作为通用计算机展示了令人印象深刻的能力。然而,任务的性能在很大程度上取决于用于指导模型的提示的质量,而最有效的提示是由人类手工制作的。”
尽管提示为 LLMs 提供了直观的接口,但这个接口远非完美。许多模型对提示中的小变化过于敏感。
调整提示的措辞或结构会导致不正确的和意想不到的结果。
因此,撰写有效的提示需要非平凡的领域专业知识,并且已经成为一项备受追捧的技能。
实际上目前针对提示词的一个工作形态,主要是
大多数提示都是通过一个迭代的试错过程创建的,其中有一个人为参与。
我们只是利用我们对提示的知识反复调整和测试提示-以及正在提示的LLM-引导我们的搜索找到一个性能良好的提示。
3 实用技巧和要点 (请允许我把最后的总结提到最上面)
在本概述中,我们看到了各种提示优化技术,包括直接从数据中学习软提示、利用LLMs作为无梯度优化器、使用RL训练更擅长生成提示的模型等方法。我们将所有这些研究的主要结论概述如下。
3.1 为什么即时优化很难
正如我们所看到的,提示优化不是一个正常的优化问题,原因有以下几个:
- 我们试图优化的提示是由离散的令牌组成的。
- 在大多数情况下,我们无法获得梯度信息。
如果我们使用的是LLM API,我们可用来改进提示的信息非常有限。此外,提示是离散的,这使得基于梯度的优化算法的应用变得困难。成功的提示优化算法通过以下方法避免了这些问题:i)采用类似于EA的无梯度优化算法ii)依赖于LLMs从之前尝试过的提示中推断出更好的提示的能力。
3.2 LLM是优秀的即时工程师
从最近的提示优化论文中得出的主要结论之一是,LLMs 擅长写提示。假设我们提供正确的信息作为上下文,我们可以通过反复提示一个 LLM 来批评和改进提示来创建出令人惊讶的强大提示优化算法。更大(更有能力)LLMs 倾向于更擅长这项任务。因此,应用先进的模型,如OpenAI的O1提示优化是一个有趣的机会,但尚未被探索。
3.3 我们应该用什么
由于我们已经见过很多提示优化算法,我们可能不知道这些技术中应该真正使用哪一种。我们看到的很多研究都是有用的。但是,基于LLM的提示优化器(例如OPRO)[3])是迄今为止最简单、最实用的即时优化技术。我们可以使用这些算法自动改进我们编写的任何提示,产生一个更好的提示,仍然可以由人类解释。OPRO是有益且易于应用的,这使得它在LLM从业者中很受欢迎。提供了OPRO的开放式实现在这里.
3.4 人类还有必要吗
虽然即时优化技术可以大大减少手动的即时工程工作,但完全消除人工的即时工程师是不太可能的。到目前为止,我们看到的所有算法都需要一个人工提示工程师提供一个初始提示,作为优化过程的起点。此外,像OPRO这样的技术在实践中需要人为干预/指导,以找到最佳的提示。简单地说,自动提示优化技术本质上是辅助性的. 这些算法自动化了提示工程中一些基本的手动工作,但它们并没有消除对人类提示工程师的需求。然而,应该注意的是,随着时间的推移,LLMs对提示的细微变化自然变得不那么敏感,这使得提示工程在总体上变得不那么必要。
3.5 提示优化的局限性。
到目前为止,我们所看到的提示优化算法对于改进提示的措辞和基本结构是有用的。然而,在构建高性能的LLM系统的过程中,还包含了更多的选择。例如,我们可能需要使用检索扩充生成,在我们的提示中添加额外的数据源,找到可以使用的最佳少拍示例,等等。自动化这些更高级别的选择超出了我们迄今所见的即时优化算法的能力,但研究人员目前正在开发DSPy等工具[31]这可以自动实现 LLM 系统的高级设计和低级实现。
1 自动改进提示
提示需要大量的人力,而且本质上是不完美的。为了缓解这些问题,最近的研究探索了自动提示优化的想法,它利用数据从算法上提高提示的质量。这种方法有几个主要的好处:
- 找到一个好的提示所需要的人工努力更少。
- 提示被系统地搜索和发现,使得性能超过人类书写提示的提示能够被找到。
提示优化技术使我们能够自动提高提示的质量,而无需依赖启发式方法和领域知识。
后续,我们将了解关于这个主题已经发表的大量文献,重点介绍创建更好提示的最实用技术。
- 初步:调度和优化
这里研究优化和快速工程的重叠,但我们不能忘记这两个概念——优化和提示工程-也是不同的研究领域。
通过单独学习这些想法,我们将了解如何将这些想法背后的关键概念结合起来,创建自动提高提示质量的算法。
1.1 什么是优化
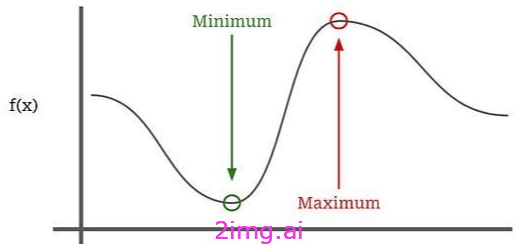
优化函数
最优化是指在一定的函数中寻找最优解或最优点的思想,称为“目标函数”。通常,这意味着找到最小化(或最大化)函数值的点;数学优化等基本概念,我访问了WIKIPEDIA,截图展示部分内容。

通过找到这个最优点,我们正在“优化”函数,或者执行优化.存在过几个世纪以来,优化的领域丰富、广阔,而且极具价值。
优化目标函数的想法可以用来解决大量的重要任务,包括从路由流量到训练神经网络的任何事情。对优化的全面解释超出了本帖的讨论范围,但是许多资源都是可用的。
1.2 优化算法的类型
已经提出了无数的优化算法。即使对于训练神经网络的具体应用,也有一种庞大的优化算法阵列可供选择。尽管有这种多样性,但优化算法可以粗略地分为两类:
- 基于梯度的
- 无梯度
基于梯度的优化
重复地i)计算我们的函数的梯度,第二)使用这个梯度来更新当前的解决方案。
梯度指向(局部)增函数值的方向,因此我们可以使用梯度来寻找函数值较高或较低的区域。我们在下面展示了这个过程的描述,其中我们不断地计算梯度,并沿着梯度的相反方向移动以最小化一个函数(即,梯度下降).
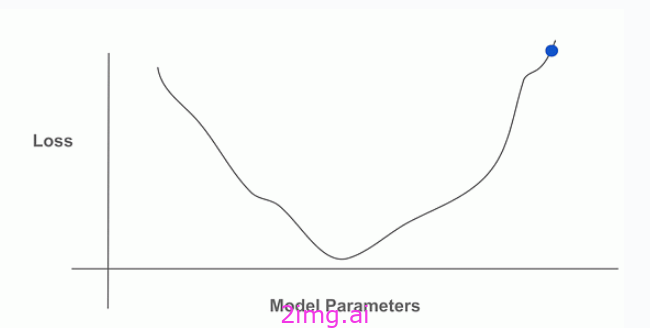
机器学习实践者通常最熟悉基于梯度的优化算法。这些算法的基础思想是反向传播,它几乎被普遍用于训练神经网络和其他机器学习模型。
基于梯度的算法之所以受欢迎,是因为它们既有效又高效!
即使在优化大量变量(例如,一个 LLM 的参数)时,只要沿着梯度的方向寻找解决方案,在计算上也是可行的,这相对便宜。
无梯度算法
是一类不使用任何梯度信息的优化算法;例如,蛮力搜索 和 爬山 是两个基本的例子。
存在许多无梯度优化算法,但其中最流行的一类算法——以及我们将在本次概述中遇到的算法类别-是进化算法(EA);见下文。
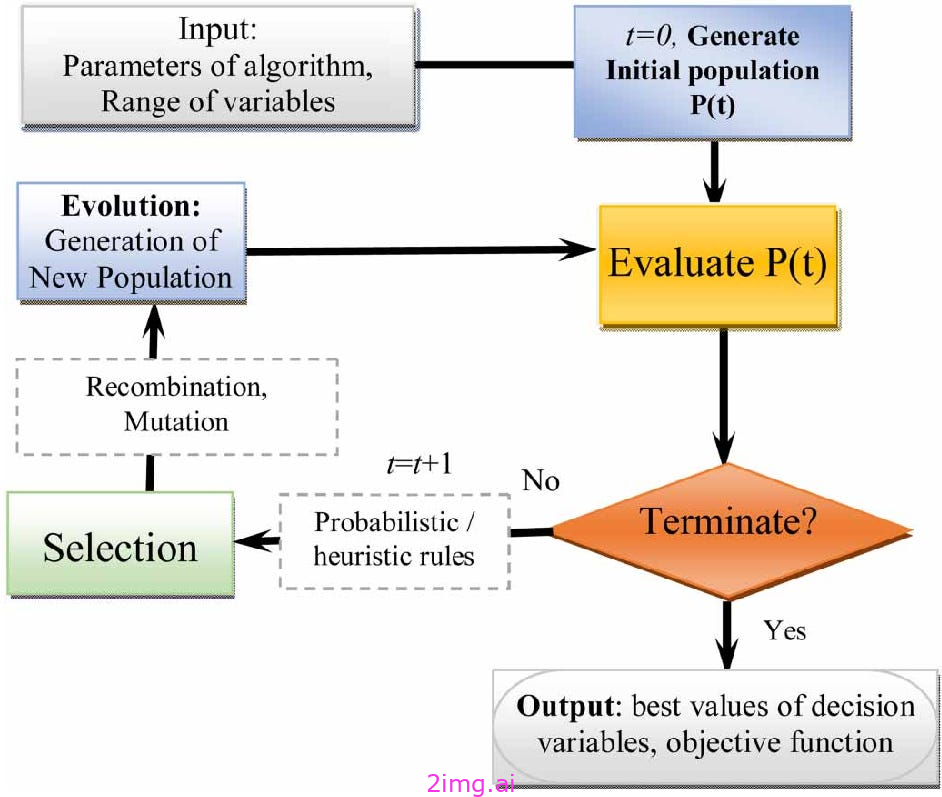
受生物进化思想的启发,EA保持着候选解决方案的“数量”,并反复:
- 更改此人口的成员候选解-通过突变和交叉等进化操作产生新的种群成员,模拟繁殖行为。
- 选择最好的会员-基于某个目标函数-从种群中继续进化(即适者生存)。
存在许多EA变体,但最常见的实例是 遗传算法 和 微分进化.
一般来说,与基于梯度的优化算法相比,EA被认为效率较低。
例如,如果没有梯度信息,训练大型神经网络(例如,LLM)是困难的。
搜索空间非常大,所以调整模式的参数,测量损失,并希望找到一个更好的LLM不会让我们走得很远。
“EA的初始群体通常为
N解决方案,然后使用进化运算符(例如,突变和交叉)迭代生成当前种群的新解决方案,并基于适配函数对其进行更新。“
然而,EA也有许多好处;例如,这些算法很好地平衡了勘探和开发之间的权衡。
基于梯度的算法产生一个单一的解决方案,而EA则维持一个完整的群体!该属性对于某些类别的问题非常有用,这导致EA在许多有趣的领域中被实际采用,例如 进化的神经网络架构 或优化计算机网络拓扑
使用LLM作为优化器
最近,研究人员探索了将LLMs用作无梯度优化器的想法。
为此,我们向LLM提供有关问题当前解决方案的信息——包括解决方案的性能-以及优化轨迹(即以前解决方案的历史)。
然后,我们可以促使一个LLM生成一个新的-希望能更好问题的解决方法。通过测量新解决方案的性能并重复这个过程,我们创建了一种新型的优化算法。我们将看到,此类基于LLM的优化技术经常被用于优化提示。
许多论文涵盖了使用 LLMs 作为优化器的主题。
例如,使用 LLMs 优化简单的回归问题并解决旅行商问题. 研究人员还探索了:
- 将LLM与EAS相结合
- 使用 LLMs 进行超参数优化
- 自动操作神经结构搜索拥有LLM
与其正式定义优化问题并通过编程求解器推导更新步骤,我们用自然语言描述优化问题,然后指示LLM基于问题描述和先前找到的解决方案迭代生成新的解决方案。
2 提示工程的基础知识
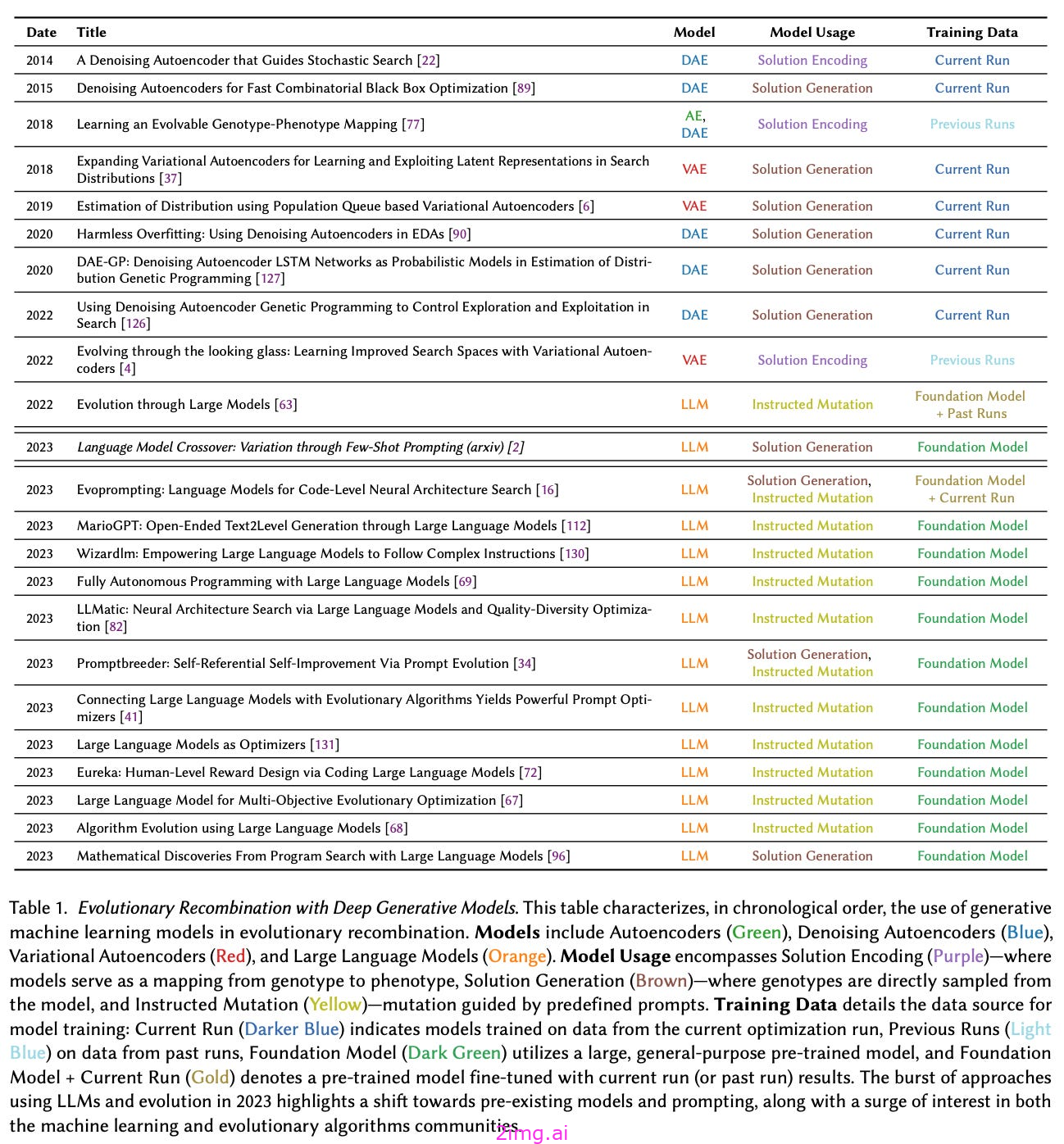
LLM的通用的文本对文本结构既直观又强大。
与其让科学家为每个需要解决的任务训练一个专门的/狭隘的数据模型,我们可以让(几乎)任何人书面解释问题——通过一个提示符-并生成一个合理的解决方案,其中无(或最小)¹)通过将此提示传递给LLM来训练数据;
提示的便捷性释放了显著的潜力,因为非ML领域的专家可以轻松地原型化并演示LLMs的有影响的应用程序
LLMs被证明对提示格式很敏感;特别是,语义相似的提示可能有截然不同的性能,而最佳提示格式可以是模型特定的和任务特定的。
LLMs对提示中的微小更改很敏感 – 我们如何措辞和结构我们的提示的确切细节会产生很大的不同。. 这个问题可能会使非专家很难提示 LLMs .
因此,提示工程(即创建更好提示的艺术)已经成为一种受欢迎和有用的技能。
我们主要集中于自动改进提示的方法,但现在在此介绍一些提示的基础知识。
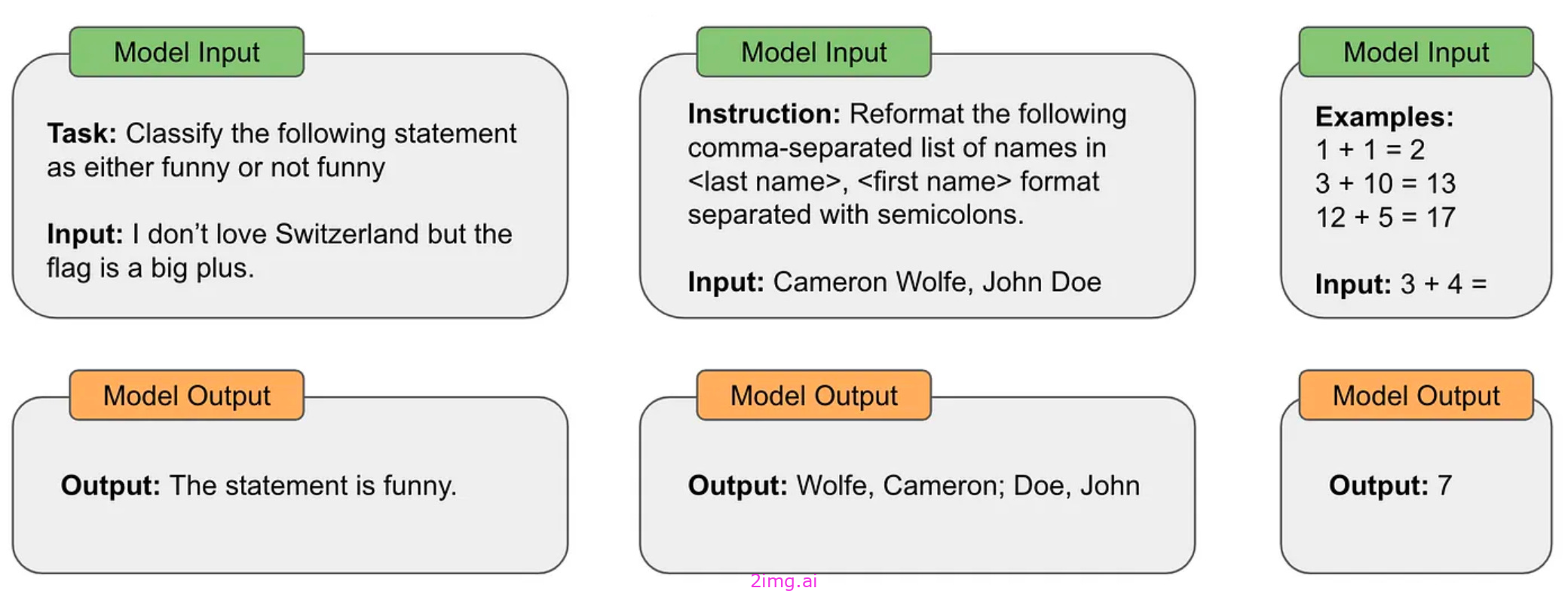
组合所有组件的提示示例
2.1 剖析提示符
虽然我们可以采用许多不同的方法来编写提示符,但通常在任何类型的提示符中都存在一些标准组件:
- 指令:对模型预期输出的文本描述。
- 实例/例子提示中包含的正确输入输出对的具体实例(即演示)。
- 语境:在提示中向LLM提供的任何额外信息。
- 输入数据: LLM 预期处理的实际数据(例如,翻译或分类的句子,摘要的文档等)。
- 结构/指标:我们可以包含不同的标记、标题或组织字符串,以分离或结构化提示的各个部分。
上面显示了一个使用所有这些组件的提示符示例,但提示符不需要包含所有这些组件中的任何一个。我们可以根据我们试图解决的问题的细节或需求,有选择地利用它们。
2.1.1 提示技术
在前面的概述中,我们广泛研究了不同类型的提示技术:
- 实用提示工程:基本概念、零/少拍提示、说明等。
- 高级提示工程:思维链(CoT)提示,CoT提示的变种,上下文检索等。
- 快速工程的现代进展 最近的提示研究(如工具的使用、推理、程序辅助提示、长格式写作等)。
除了上面列出的概述之外,还有无数的在线资源可以学习更多关于快速工程的知识;
2.1.2 编写更好的提示的框架
提示词工程是一门实证科学,它在很大程度上是以试错为基础的。
为了写出更好的提示,我们应该不断地调整一下原来的提示符,测量新提示的性能,并选择更好的提示。
我们还希望确保我们的提示不至于过于复杂。这有几个原因:
- 如果一个复杂的提示程序表现不佳,我们如何知道提示程序的哪一部分是坏的,哪些是需要修复的?
- 复杂提示通常更长,会消耗更多的Token,从而增加货币成本。
基于这些原因,我们应该以一个简单的提示(例如,几步提示或基于指令的提示)开始提示工程过程。
然后,我们(慢慢地)增加提示的复杂性-通过添加少拍例子、使用CoT等高级技术,或者只是调整指令
同时监测一段时间内的性能。
通过遵循这个过程,我们提高了速度,并通过改进的性能证明了复杂性增加的合理性;请参见下文。一旦我们的提示达到了用例的可接受性能水平,该过程就结束了。

2.1.3 快速的工程只是优化而已
如果我们研究上面概述的快速工程过程的步骤,我们会意识到这是一个优化问题!
我们反复调整解决方案我们的提示-并分析新的解决方案是否更好。
在这种设置中,“优化者”是一个人类提示工程师,他会利用自己的判断力和提示知识来确定下一个可以试用的最佳提示。
然而,鉴于提示词工程需要如此多的试错,我们可能会想,我们是否可以替换²人类在这一优化过程中使用自动化的方法或算法。那当然是可以的。
2.1.4 为什么优化提示很难
正如我们刚才所学到的,我们可以考虑两类优化算法来自动化快速工程过程。遗憾的是,使用基于梯度的算法进行快速优化是困难的,原因如下:
- 对于许多LLMs,我们只能访问API,这使我们无法收集/使用任何梯度信息。
- 提示由离散符号组成,使用基于梯度的算法优化离散解很复杂。
正如我们将在本概述中看到的,我们可以通过一些方法来避免这些问题,并使用基于梯度的优化来找到更好的提示。然而,由于上述原因,我们将主要依靠无梯度算法进行快速优化。事实上,EA实际上是离散优化问题中最成功和最广泛使用的算法之一。
2.2 提示优化的早期工作
优化提示的思想并不新鲜。提示的概念一经提出,研究人员就开始研究这个问题。早期的一些关于即时优化的工作,这些工作被应用于这两个领域仅编码器语言模型的变种以及 了解BERT LLM系列产品。这项工作启发了后来常用的快速优化技术。
2.2.1 生成合成提示
如上所述,由于提示符内部的令牌的离散性质,直接优化提示符是困难的。
我们可以解决这个问题的一种方法是训练一个LLM来生成提示作为输出。通过这样做,我们可以训练生成提示符的LLM的权重,而不是试图直接优化提示符。
这是一种实用且常用的技术。然而,正如我们将看到的,这个空间中的大多数工作使用预训练的LLMs来写提示符,而不是显式优化LLMs来编写更好的提示符。
2.2.2 指令诱导
是最早探索用预训练的LLM生成提示的作品之一。该技术旨在给出一些具体的(上下文)作为输入的任务的例子。我们编写了一个提示,其中包含几个输入输出示例,最后要求LLM通过完成“指令是…”的序列来推断正在解决的任务;见上文。
“我们发现,在很大程度上,当使用一个既足够大又对齐以跟随指令的模型时,生成指令的能力确实会显现出来。”
LLMs 不会脱离常规来解决这个任务;
例如,一个预训练的GPT-3模型只达到10%的准确率。
然而,较大的模型在按照指令进行对齐后,就开始在执行此任务时表现良好。
这指令GPT模型—一个早期的、基于GPT-3-的LLM变体,它是通过RLHF调整以遵循人类指示-在教学归纳任务上实现了近70%的准确性。
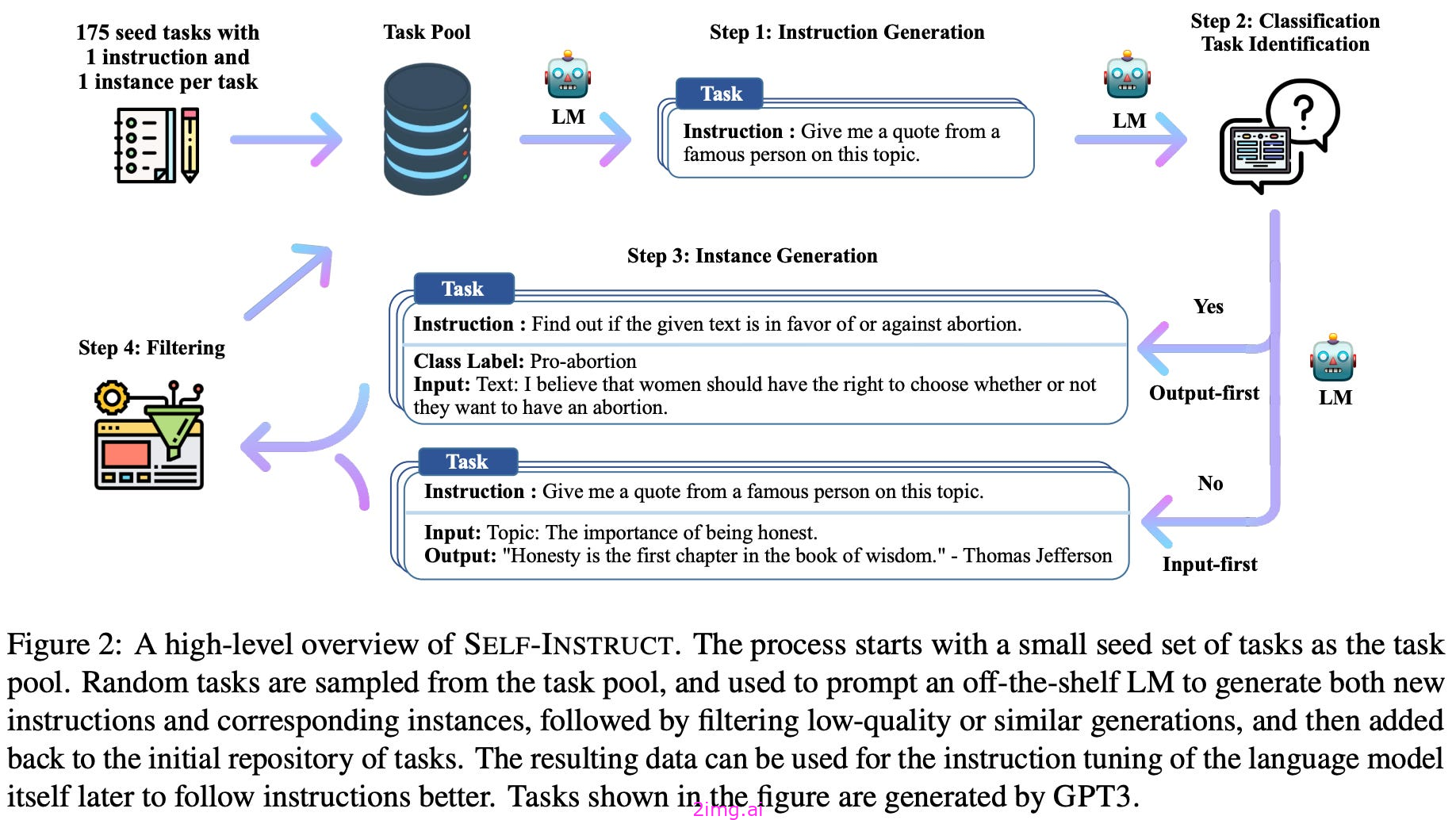
2.2.3 自我教育
自我教育最早被提议用于使用 LLMs 生成合成的框架之一指令调优数据集。
从一小组种子任务开始,这个框架会提示一个 LLM-使用种子任务作为输入-生成可以解决的新任务。之后,我们可以使用相同的LLM为每个任务创建具体的演示,这些演示基于质量进行筛选。这个管道的结果是一个由LLM生成的指令调优数据集,包含大量用于各种任务的输入输出示例。
许多论文使用类似的框架来生成合成指令。例如,作者在[使用预训练的 LLM 来多样化种子提示集,并发现更好的提示来分析 LLM 的知识库。还提出了自我指导的变体,如第二个版本的技术,该技术可降低生成成本,同时提高数据质量。

WizardLM [9]设计一个自指示风格的框架,该框架是为创建高度复杂的指令调优数据集量身定制的。这个方法的核心是一种名为 EvolInstruct 的技术,它使用一个LLM来迭代地重写-或进化-指令,以增加其复杂性。我们可以用两种基本方法来演化任何给定的指令:
- 深度:通过添加约束、要求更多的推理步骤、使输入复杂化等方式使当前指令更加复杂(即保持相同的指令并使其更加复杂)。
- 因布罗德增强指令调优数据集的主题覆盖面、技能覆盖面和总体多样性(即为数据中尚未覆盖的主题生成指令)。
每种进化类型都有许多变种。对深度和广度演变的示例提示[9]如下所示,尽管在 EvolInstruct的实现过程中使用了许多额外的提示。

进化提示的例子
鉴于演化提示的这些策略,我们可以采用以下三步法:
i) 不断进化的指令,
ii) 生成指令响应
iii) 删除或消除不可行或无法变得更复杂的提示。
通过执行这些步骤,我们可以引导Self-Instruct框架生成具有高度复杂指令的合成数据集;请参见下文。
2.2.4 软提示:前缀和提示校准
如果我们想要改进提示,我们可以从简单地调整提示中的措辞或指令开始。这种方法被称为“硬”提示调优,因为我们正在以离散的方式明确地更改提示中存在的单词. 然而,硬提示调优并不是唯一可用的工具-我们可以探索软性,不断更新提示。.
2.2.4.1 前缀调优
是第一批探索持续更新 LLM 提示的论文之一。传统的模型微调是在下游数据集中训练模型的所有参数,而前缀调优则几乎使模型的所有参数保持不变。
相反,我们附加了一个“前缀”—或模型输入开始处的一组额外的令牌向量-到模型的提示,并直接训练此前缀的内容。
然而,前缀调优不仅仅是更新输入提示符,还为底层模型中每个Transformer 块的输入添加了一个可学习的前缀;请参见下文的示例。
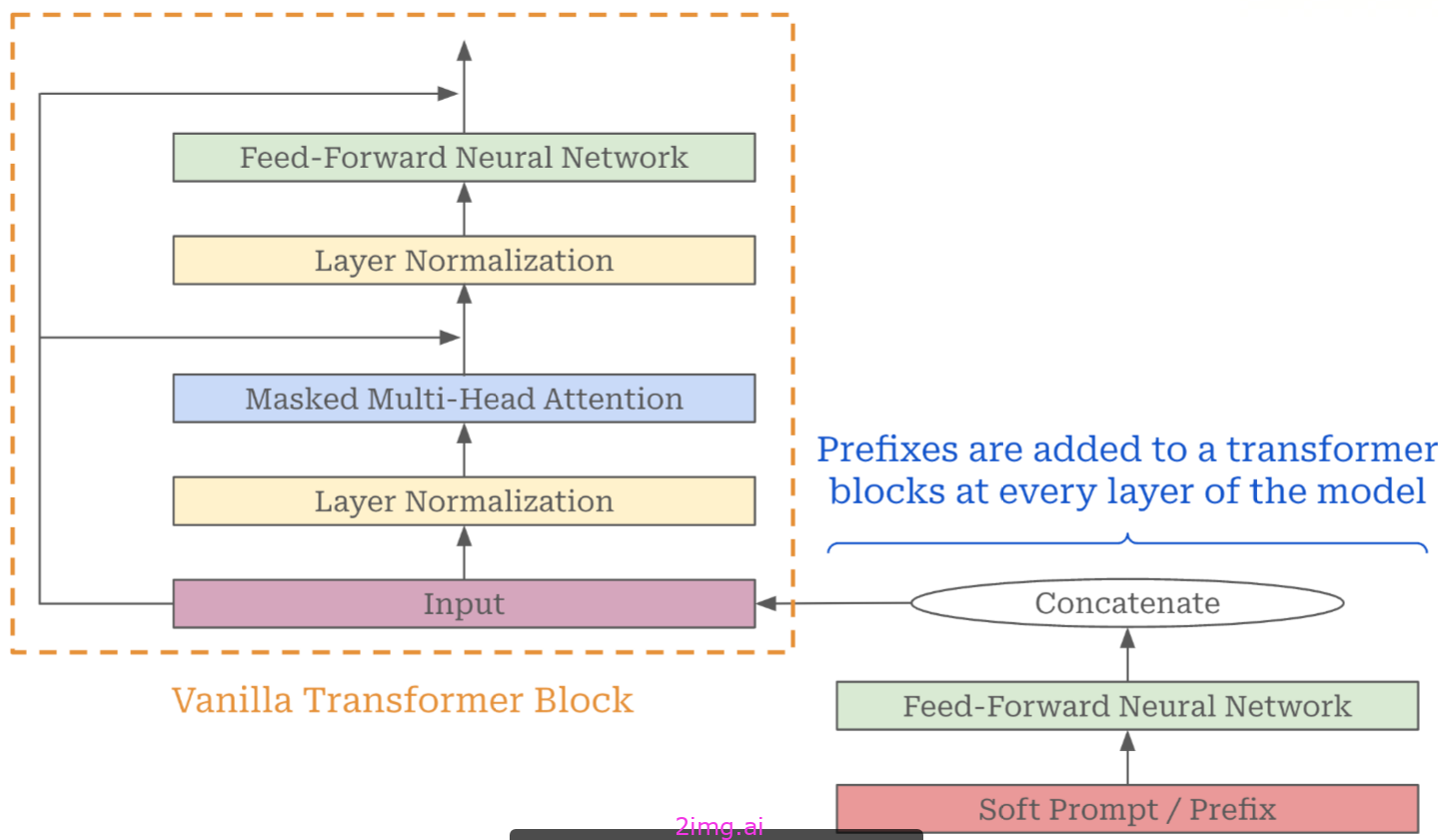
带有可学习前缀的Transformer块
在前缀调优中,我们只训练模型中添加的前缀。与其直接训练前缀的内容,在与每个层的输入连接之前,通过前馈转换将可学习的前缀传递,使训练更加稳定。这种技术将更多的可学习参数添加到模型中,被称为“重新参数化”。
(自[5])
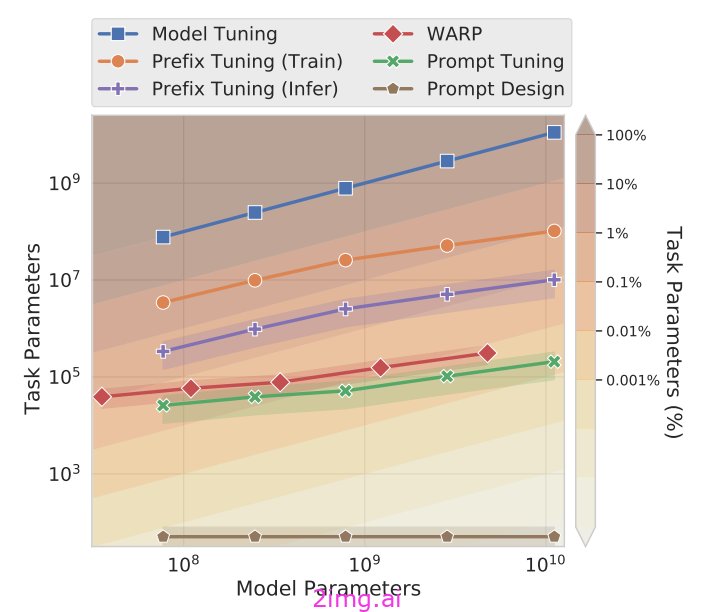
在训练过程中,除前缀以外的所有参数都保持冻结状态,这大大减少了-乘以100倍或更多,如上图所示-微调过程中学习的参数总数。尽管如此,我们可以通过前缀调优来极大地提高下游任务的性能;请参见下文。
虽然前缀调优在上述实验中表现良好,但在微调实验中考虑的唯一基础模型是GPT-2,这意味着这些结果还有待用更现代的模型和数据集来证明。
2.2.4.2 提示调优
是前缀调优的简化这是同时提出的。
同样,我们从一个预训练语言模型开始,并冻结模型的参数。与训练模型不同,我们创建一个“软”提示符,或一系列与 LLM 输入开始相关的令牌序列。然后,我们通过训练来学习软提示-与任何其他模型参数相似-通过梯度下降查看我们的数据集;见下文。
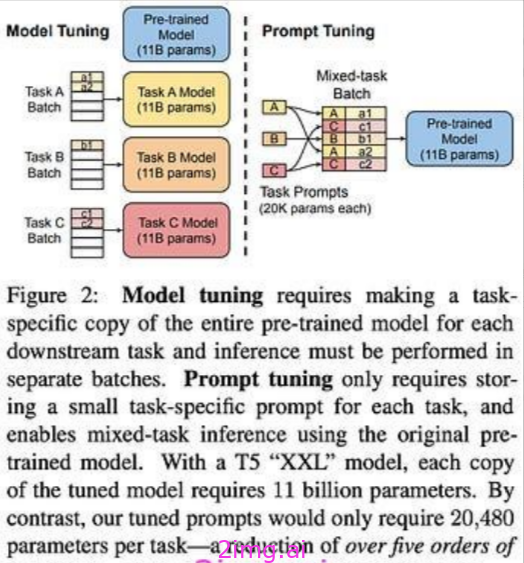
与前缀调优相比,提示调优只将前缀令牌预先设置到输入层-而不是每一层-且不需要重新参数化⁴为了训练稳定。因此,与前缀优化相比,提示优化过程中学习到的参数总数要低得多。
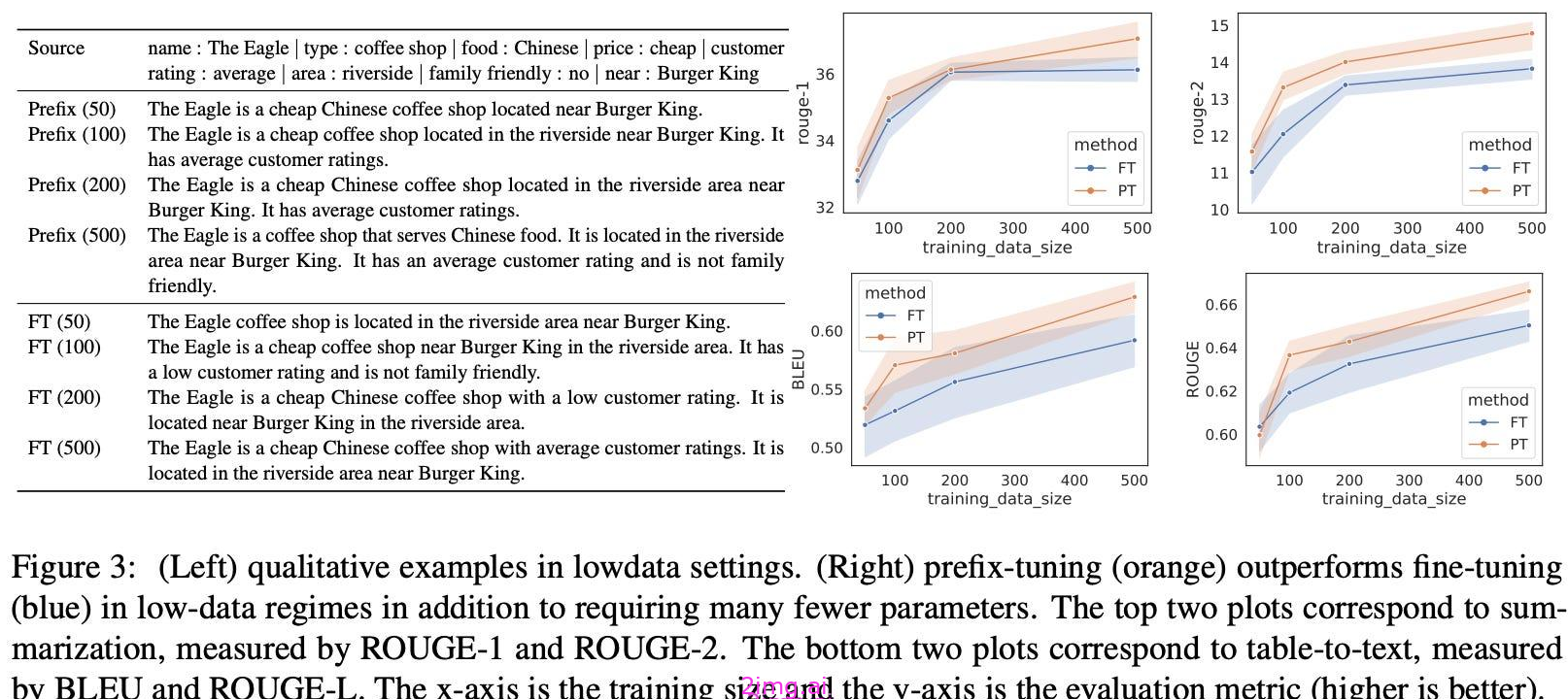
尽管可学习参数的数量很少,但即时调优效果惊人,甚至在底层 LLM 变得更大时赶上了端到端模型训练的性能;见下文。此外,提示调优的性能通常超过人工设计的提示-尽管我们应该注意,人类的表现取决于人类的书写提示。.
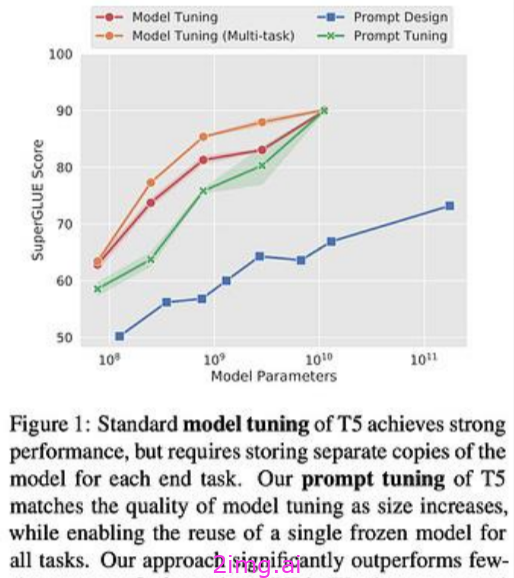
2.2.4.3. 软提示
软提示就其性能而言是有效的,但有人可能会认为这些技术实际上对改进提示工程过程没有任何作用。
提示工程的目标是发现一个基于文本的提示,在考虑应用领域和LLM的情况下工作良好。
提示符和前缀调优不是解决这个问题,而是消除了提示符是离散的/基于文本的约束。
这些技术发现的“提示”只是一个通过基于梯度的优化学习的连续向量。与任何其他模型参数类似,这个向量是不可理解的,并且不能转移到另一个 LLM 中使用。

因此,前缀和提示调优更接近于参数高效微调(PEFT)技术比它们更能自动提示优化策略。
与其寻找更好的提示,我们向模型添加少量的附加参数,并直接训练这些参数—同时保持预训练模型的固定性-通过一个较小的、特定领域的数据集。
这些附加参数只是碰巧连接到我们的提示符,而不是注入到模型的内部权重矩阵中。
2.2.4.4. 基于API的访问
提示符和前缀调优的另一个问题是,当我们只能通过API访问一个 LLM 时,这些技术无法使用。
我们需要对模型的权重进行任何形式的梯度训练的完全访问,但LLM API仅提供对模型输出的访问。这些LLM是真正的黑匣子!因此,提示和前缀调整仅兼容于开源LLM,但研究人员已经试图为这个问题创造变通办法。
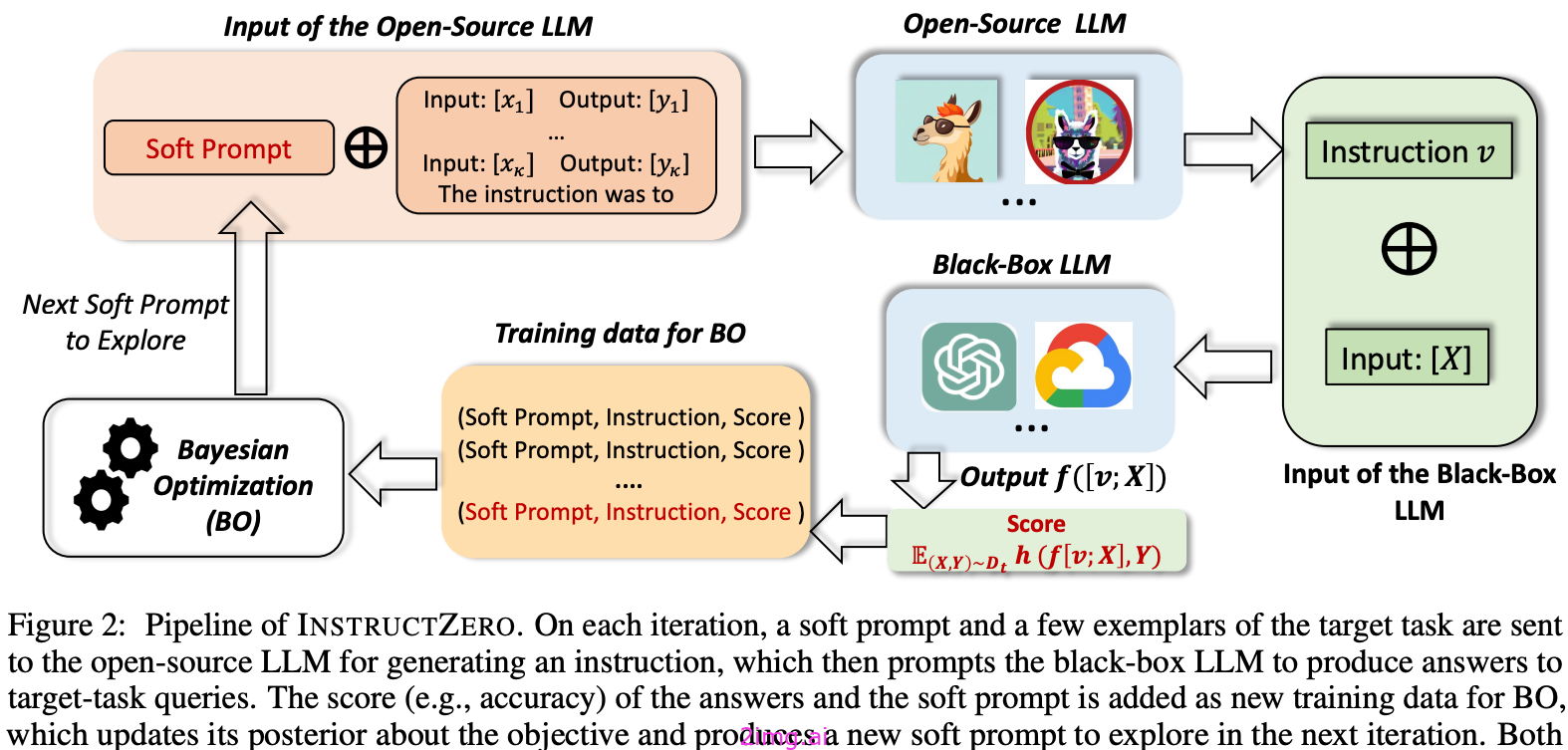
指令零在软提示符和LLM API之间插入另一个LLM。
这个(开源的)LLM可以训练生成基于文本的指令,并提供软提示和额外的任务信息作为输入;见上文。
然后,生成的指令可以正常地传递到LLM API。
简单地说,我们使用额外的LLM将软提示“解码”为基于文本的提示,然后再将其传递给API。
为了提高生成的指令的质量,我们可以使用贝叶斯优化,它产生的指令与通过其他自动提示方法发现的提示的性能相匹配或超过。
在软提示上多下功夫。前缀和提示调谐是最广为人知的软提示技术,但也有许多其他论文考虑过这个想法。以下是这个领域其他著名论文的例子:
- 混合软提示 通过微调提供给语言模型的整个提示来形成——要么来自现有提示,要么来自随机初始化-形成一个软提示,然后可以与其他软提示混合或组合,以实现更好的任务性能。
- 弯曲 解决了通过学习任务特定的词嵌入来适应多个下游任务的问题,这些词嵌入可以与模型的输入关联以解决不同的任务。
- P调谐 通过将一系列可训练嵌入与模型的提示连接来解决提示工程的不稳定性,其中模型可以随添加的嵌入进行微调或保持冻结。
- PADA 通过训练语言模型来预测解决问题的领域特定提示,然后使用生成的提示来实际解决问题,从而提高LLMs适应新领域的能力。
2.2.5 离散提示优化
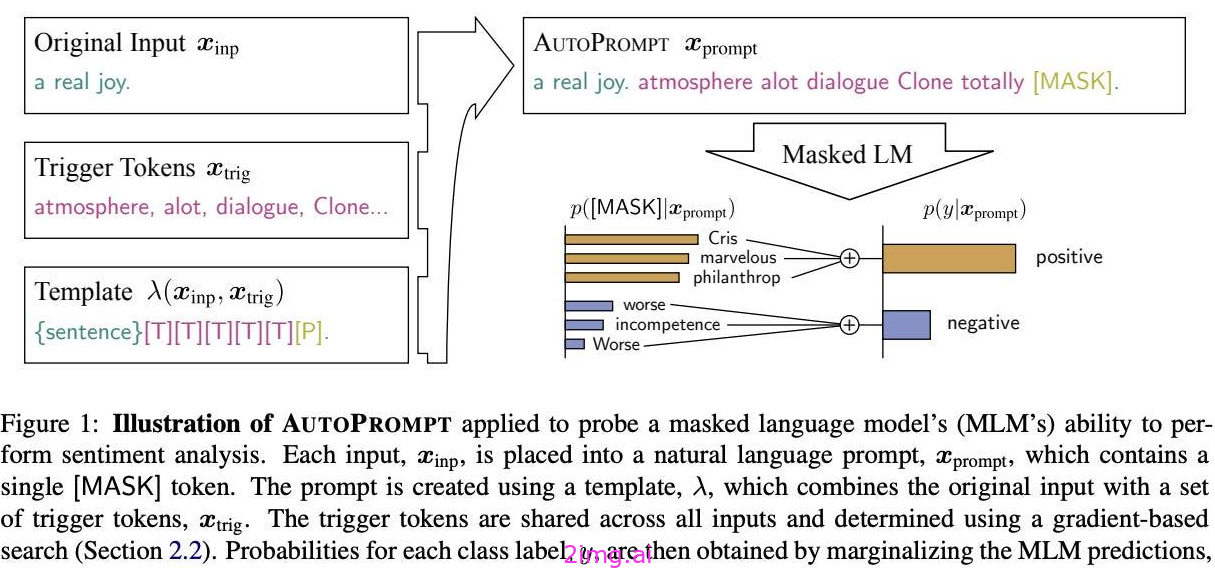
正如我们已经看到的,软提示在可解释性、跨模型的可重用性以及对基于API的LLMs的适用性方面都有限制。
不幸的是,这些局限性破坏了提示的几个关键好处。
考虑到这一点,我们可能会想知道,我们是否可以在维护这些属性的同时自动优化提示。
在提示的早期,发表了关于寻找离散“触发”标记的想法的论文,这些标记可以包含在模型的提示中,以帮助解决某些问题。
2.2.5.1 自动投影[11]
对离散的令牌集执行梯度引导搜索,以发现一组最佳的附加令牌集,并将其包含在 LLM 的提示中。
这种方法应用于探测 LLMs 内知识的任务,我们看到这些附加的标记会带来更可靠和稳定的性能。
通过使用触发符号,我们可以通过严格的(基于梯度的)搜索过程优化 LLM 的性能,而不是通过手动试错来搜索最佳提示。
由于使用了梯度信息,我们在AutoPrompt 用于编辑提示符号的训练过程可能不稳定。作为一种替代方法,后来的研究探索了通过以下方式优化提示强化学习.
使用RL优化提示背后的想法非常简单。
首先,我们定义了一个策略网络,它只是一个生成候选提示作为输出的LLM。
然后,我们可以将这个策略网络的奖励定义为它生成的提示的性能!见下文对该框架的描述。
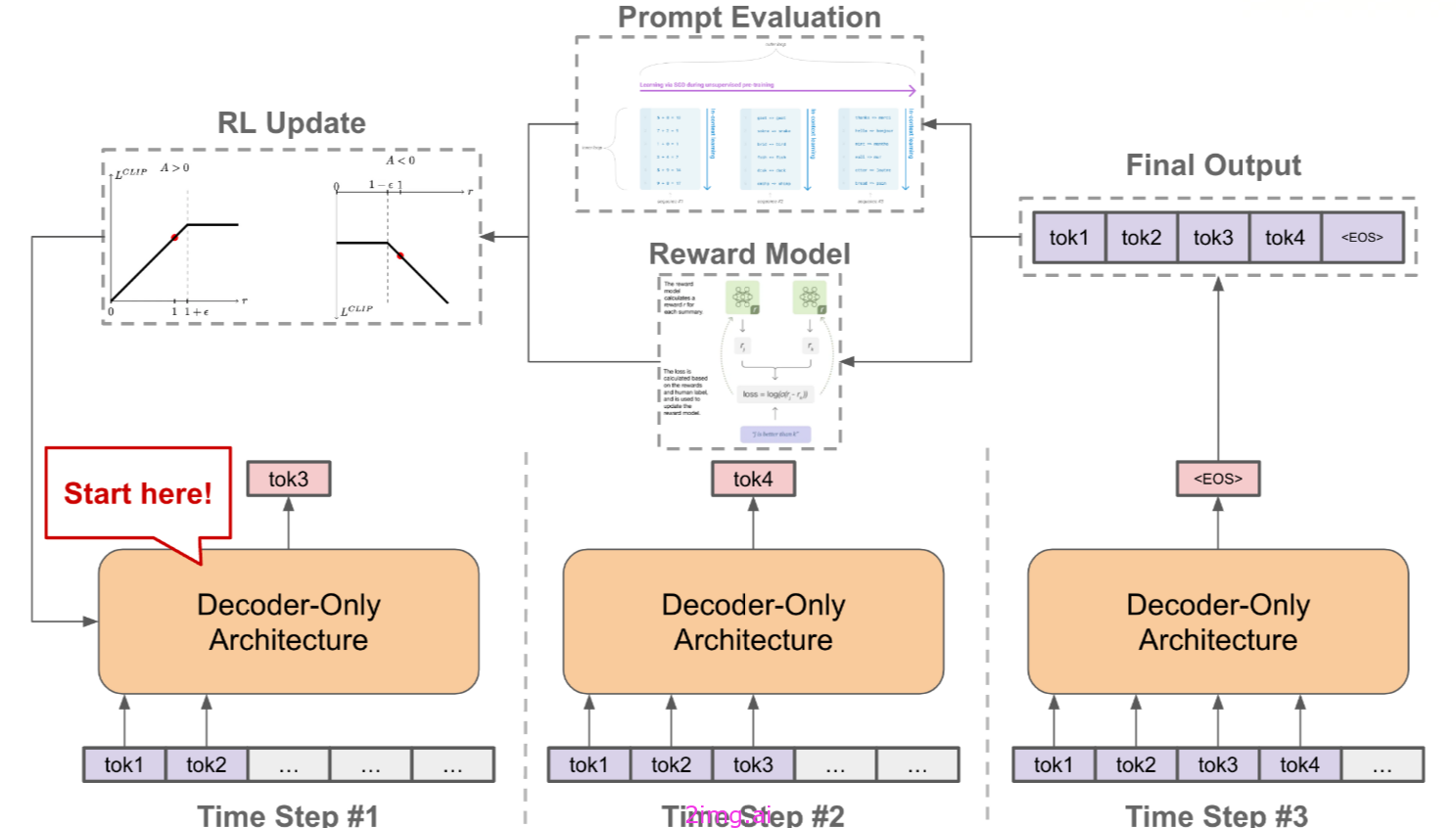
使用RL优化LLM
这个设置非常类似于通过以下方式培训一名LLM从人类反馈中强化学习(RLHF).
在这两种情况下,我们的策略都是一个LLM,并且该策略通过生成令牌来执行操作。一旦一个完整的序列被生成,我们就计算这个序列的奖励。在 RLHF中,这种奖励是奖励模型的输出,它是人类偏好的代名词。对于提示优化,此奖励由提示的性能决定;见上文。
2.2.5.2 RLPrompt
是使用RL优化离散提示的最著名的论文之一。生成提示的策略网络作为预训练的LLM实现。该模型的参数保持不变,但我们向该模型添加一个额外的前馈层,该前馈层通过RL进行训练;见下文。
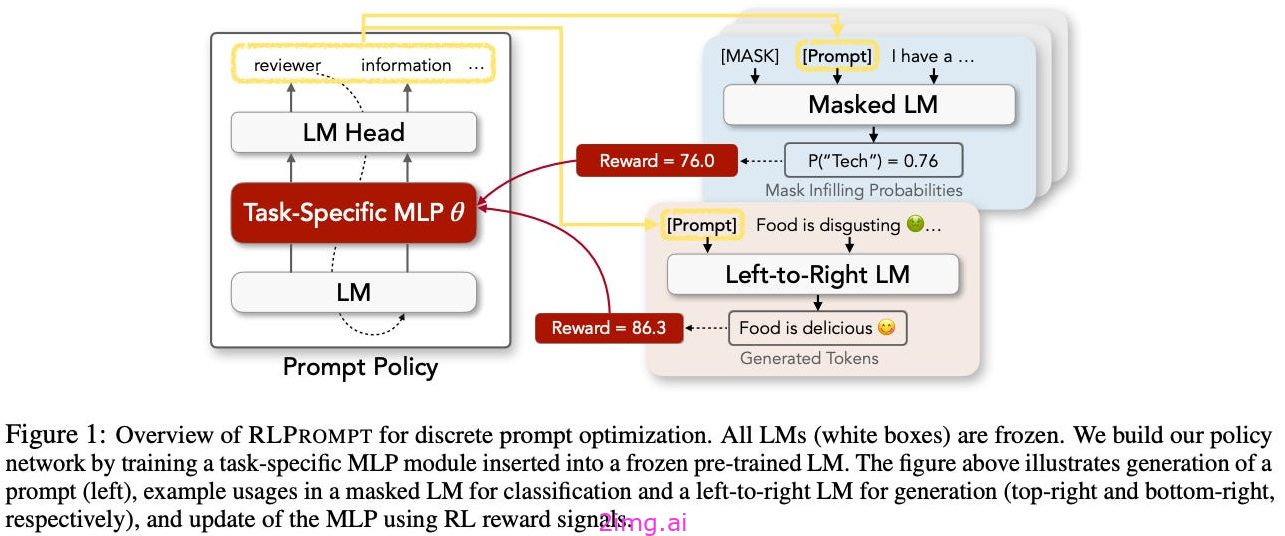
此策略网络用于生成候选提示,由另一个LLM接收以解决任务-引入提示的策略网络和LLM不需要相同。. 奖励是通过衡量在给定提示下所取得的绩效(例如,分类准确性或输出对给定风格的坚持程度)来获得的。在这里,奖励函数依赖于由LLM生成的输出。因此,RLP prompt框架内的奖励信号是不可预测、复杂且难以优化的。尽管有这个问题,可以使用各种奖励稳定技术来使优化过程更加可靠。

当应用于分类和样式转换任务时,发现RLPrompt生成的提示效果优于微调和提示调优策略;请参见上文。
但是,我们想要自动优化可以被人类轻松理解的提示,却做不到这一点。
RLPrompt发现的提示符,尽管在与其他 LLMs 一起使用时传输良好,但往往是不合语法的,甚至是“胡说八道”。
根据我们的观点,这一发现可能会让我们思考提示在某些方面是否是一种独特的语言。
“优化后的提示通常是不合语法的胡言乱语文本;令人惊讶的是,这些胡言乱说的提示可以在不同的LM之间转移以保持显著的性能,这表明LM提示可能不遵循人类的语言模式。
为什么这个能用通过使用RL,我们最终可以实现优化离散提示的训练过程。与我们目前看到的其他方法相比,像RLPrompt这样的技术做出了两个关键的改变来使这成为可能:
- 我们用LLM生成提示符。
- 我们根据它生成的提示的质量来优化这个LLM。
通过使用一个 LLM 生成提示符,我们可以专注于优化 LLM 的 (连续) 权重,而不是离散提示符。这种方法也被诸如指令诱导等技术所使用。或自我教育,但我们超越这些技术,使用RL来教模型创建更好的提示。我们需要RL来执行这种优化,因为用于生成奖励的系统基于一个 LLM,因此,不可差别!
换句话说,我们不能轻易地计算出梯度来用于优化目的。
2.3 自动优化 LLMs 的提示
既然我们已经了解了优化提示的早期工作,我们将了解关于自动提示优化的最新和流行的论文。
几乎所有这些论文都依赖于LLMs优化提示的能力。使用 LLM 作为无梯度优化器(可以说)比传统和已建立的优化算法更不严格。
然而,这些方法在概念上简单,易于实现/应用于实践,并且非常有效,这使得基于 LLM 的即时优化算法变得相当流行。
写一个有效的提示需要大量的尝试和错误。提示词工程是一个黑盒优化问题
2.3.1 APE
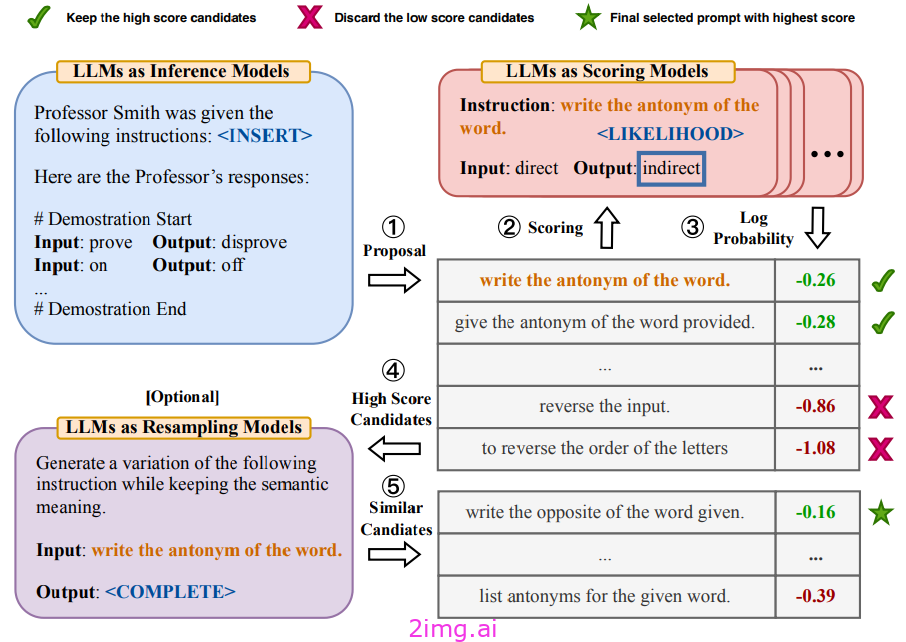
所提出的方法,称为自动提示工程师(APE),搜索由一个LLM提出的提示池,以找到表现最好的提示。
此设置使用单独的LLMs来提出和评估提示。为了进行评估,我们通过以下方式生成输出Zero-Shot推断并根据所选的评分函数评估输出。
尽管APE很简单,但它显示在以找到与人类在相同任务上编写的提示匹配或超越其性能的提示,揭示LLMs 实际上擅长于编写提示的任务.
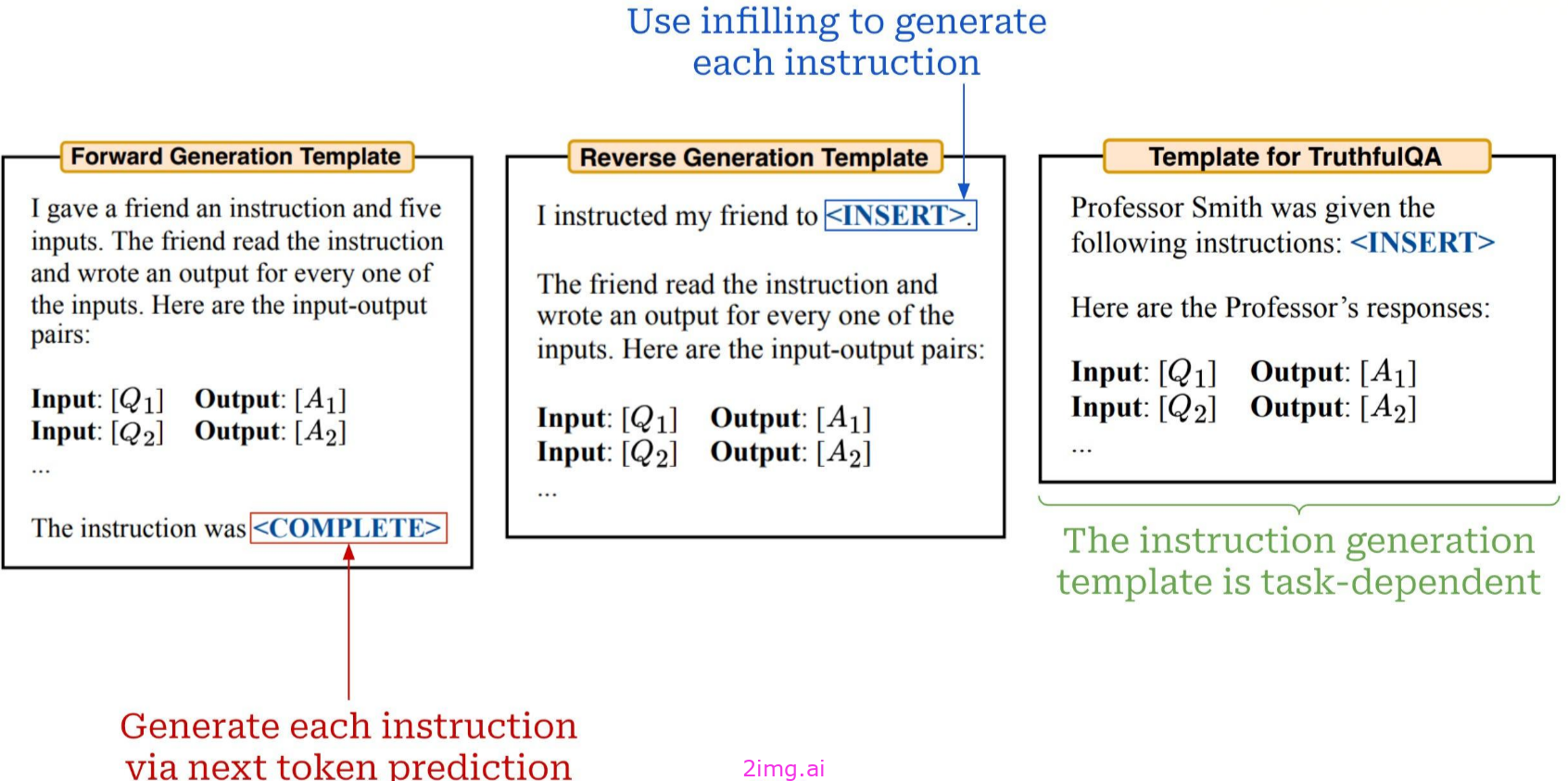
APE指令生成模板
2.3.1.1 这个是怎么用的
APE有两个主要业务:建议和得分.
对于建议,我们要求LLM为任务生成新的候选提示;有关一组示例提示,请参见上文。如上所示,新指令的生成可以以正向或反向方式完成。在前向模式下,我们只需通过以下方式生成新的指令:下一个标记预测,这与用LLM生成任何其他类型的文本相同。另一方面,逆向发电的基础是填充(即,将缺少的文本/令牌插入序列的中间),这在a中是不可能的仅编码的LLM. 根据任务的不同,我们可能会调整指令生成模板的措辞。
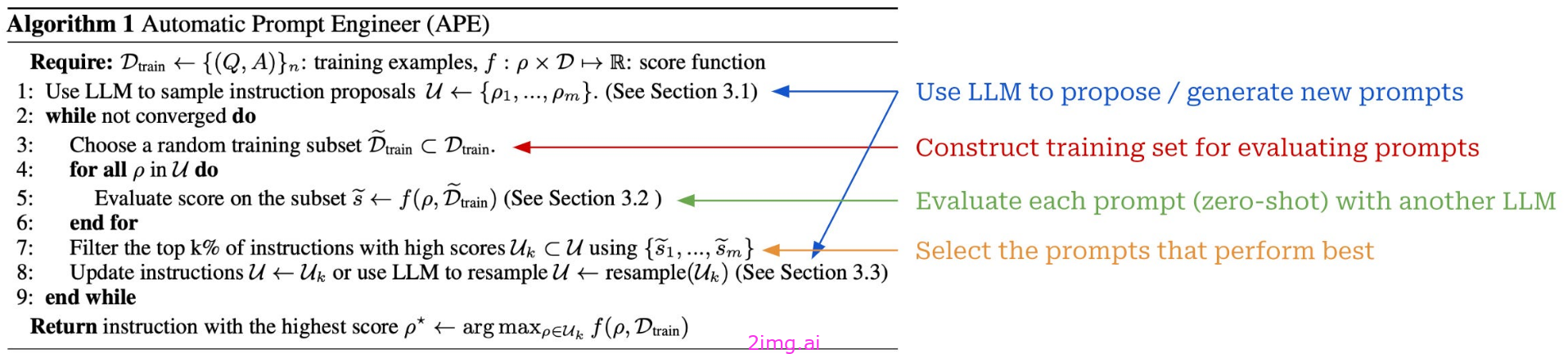
APE的步骤
我们看到在LLMs 可以从先前的指令推断出更好的指令。为了确定生成指令的质量,我们可以简单地用另一个 LLM 以 Zero-Shot 的方式评估它们,或者使用输出精度或更软的度量(例如,对数概率正确输出的)。
每个生成的提示的评估都发生在一个固定的训练集上,该训练集在整个提示优化过程中使用。
与微调相比,通过APE进行快速优化所需的培训示例要少得多。在优化完成后,我们通常会通过一个持久性测试集来评估最终提示。
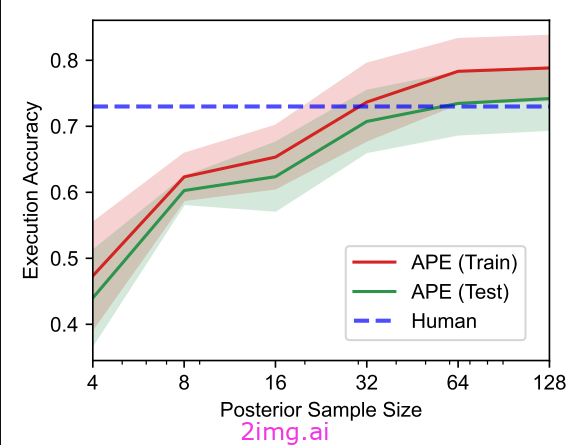
为了实现尽可能好的性能,我们应该要求LLM生成 ~64 提示以供选择。如果我们生成更多的提示,就开始看到性能方面的回报在下降-所发现的最佳提示在准确性方面没有显著提高。
2.3.1.2 迭代生成
我们还可以使用APE以迭代方式优化提示。在这个设置中,我们仍然要求一个 LLM 提出新的指令,为每个指令计算一个分数,并选择得分最高的指令。然而,再进一步,我们可以通过将这些生成的指令作为输入,使用它们作为上下文来以类似方式提出更多指令变体,并选择执行最佳的提示来重复这个过程;请参见下文。

迭代APE
使用这个策略,我们可以探索LLM提出的提示的不同变体。然而,我们看到在迭代APE仅提高了正在探索的提示套件的整体质量。
APE发现的最佳提示的性能在多次迭代后保持不变;请参见下文。
由于这个原因,迭代APE的额外成本可能是不必要的。.
2.3.1.3 APE是否发现更好的提示
APE的评估基于其在多个设置中写入有效提示的能力,包括零签名提示、少签名提示,CoT提示,以及指导LLM行为的提示(例如,更真实)。
通过各种实验,我们发现APE能够找到比人类写的提示更好的提示。
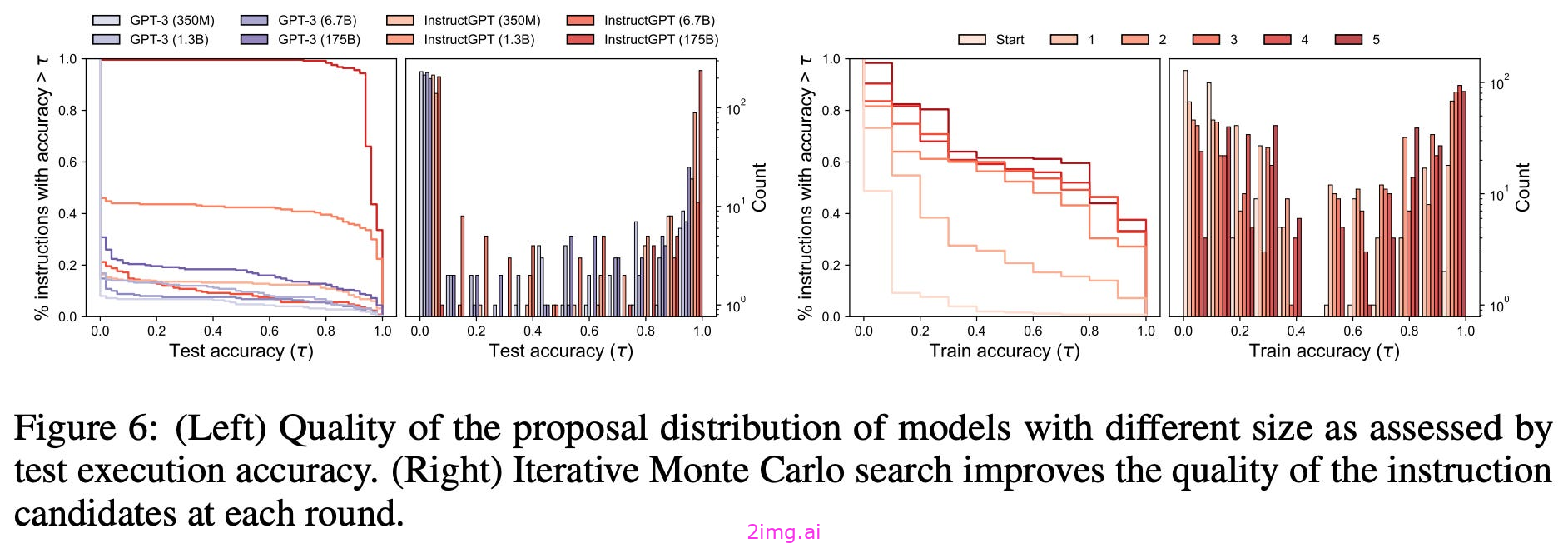
特别是,APE在24个指令引导任务中的24个和21个BIG-Bench任务中的17个中生成的提示比人工编写的提示要好;详情请参见下文。
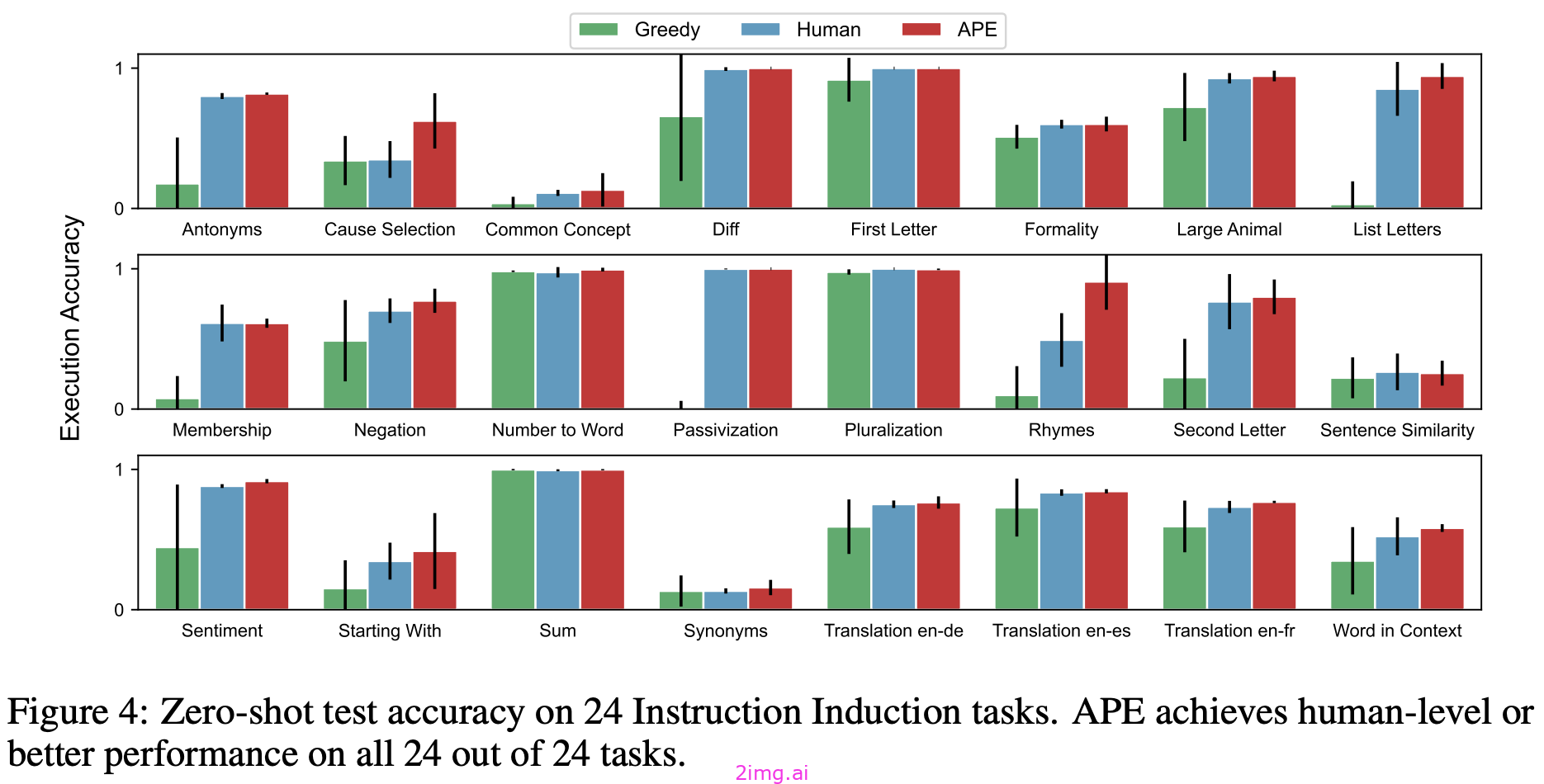
通过研究APE提出的提示,我们甚至可以推导出编写有效提示的有用技巧。在许多情况下,这些技巧可以很好地推广到各种任务中,并教会我们如何正确地提示某些模型。
2.3.2 自动提示优化
虽然APE工作得很好,但它用于优化提示的过程是随机的和无方向的。我们简单地使用一个 LLM 来提出一堆新的提示变体,并选择生成的执行最佳的提示。
该算法中不存在迭代优化过程。相反,我们完全依赖优化器 LLM 提出各种有前途的提示变体的能力,这些变体可以在一次评估中找到更好的提示。
一种快速优化技术,称为自动快速优化(APO),那是受这个类比的启发。APO是一种通用技术,只需要一个(小)训练数据集、一个初始提示符和对一个LLM API的访问即可工作。
这个算法使用批量的训练数据来推导“梯度”——只是基于文本的批评,概述当前提示的局限性-指导对提示的编辑和改进,模仿梯度更新;
见下文。

2.3.2.1 优化框架
APO旨在以自然语言梯度为指导,对提示进行离散改进。这些梯度由以下公式导出:
- 使用LLM在训练数据集上执行当前提示。
- 根据某个目标函数衡量提示的表现。
- 使用一个LLM来批判这个提示在训练数据集上的表现中的关键局限性。
推导出的梯度仅仅捕捉了当前提示中存在的各种问题的文本摘要。使用这个摘要,我们然后可以提示一个 LLM-使用梯度和当前提示作为输入-以减少这些问题的方式编辑现有提示。APO反复应用这些步骤以找到最佳提示。
见下文对该框架的描述。
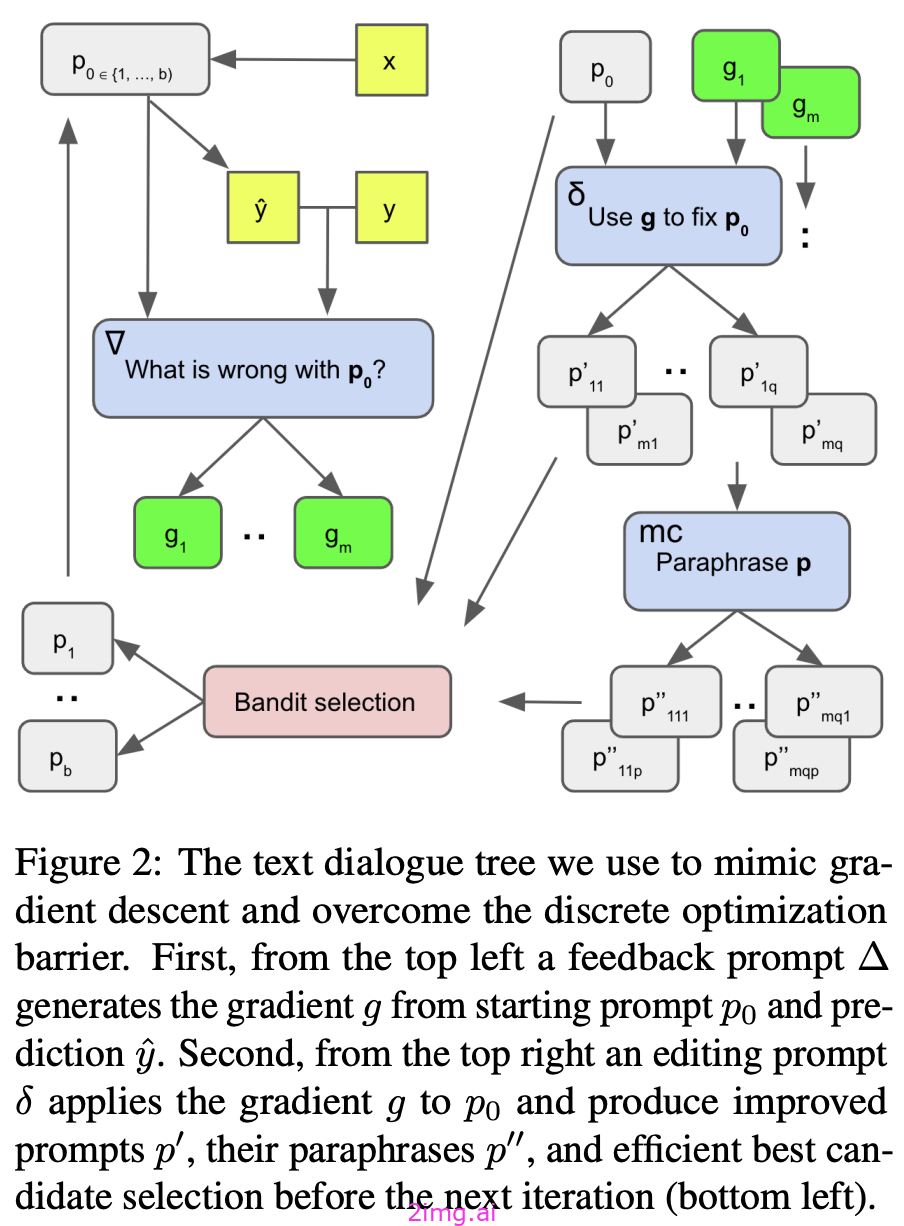
2.3.2.2 梯度和编辑
APO创建一个递归反馈循环,通过以下方式优化提示:
i)收集当前提示对训练数据所造成的错误,
ii)通过自然语言梯度总结这些错误,
iii)使用梯度生成多个修改后的提示版本,
四选择编辑过的最佳提示
并五)重复这个过程几次。
为了生成“梯度”, 展示了训练数据集中当前提示所导致的错误的LLM示例,并要求模型提出这些错误的原因。然后,使用这些原因作为编辑提示的上下文;见下文。

使用自然语言梯度编辑提示
在每次迭代中,我们会对当前的提示生成几次编辑-编辑数量是优化过程的一个超参数。. 此外,我们可以通过显式地为每个提示生成多个措辞来扩展搜索空间,这是一种被称为蒙特卡洛抽样;
见下文。

在APO中的蒙特卡罗抽样
2.3.2.3 搜索和选择
通过生成每个提示的多个变体,我们可以通过以下方式搜索最佳提示:波束搜索.
换句话说,我们在每次迭代时都会为最佳提示保留几个候选人,建议N编辑每个提示,然后选择最佳选项B根据提示进行编辑通过测量培训集的绩效-保留在下一次迭代中;见下文。

使用光束搜索来迭代选择最佳提示
正如我们可能预料的那样,如果我们在整个培训数据集中不断评估所有提示候选人,波束搜索可能会变得昂贵。
但高级的想法是我们可以使用统计数据来选择哪些提示值得全面评估,而不是仅仅天真地评估整个培训数据集中的每一个提示。
2.3.2.4 这个效果好吗
对APO在四种不同的基于文本的分类任务上提示GPT-3.5的能力进行了评估,这些任务包括越狱检测、仇恨言论检测、假新闻检测和讽刺检测。
为什么只考虑分类问题?评估APO的分类任务的明确选择可能是由于为这些问题定义目标函数的简单性-我们可以根据分类准确性来评估每个提示。. 对于复杂或开放式任务,定义目标函数并不简单,这使得APO等技术的应用不那么直接。
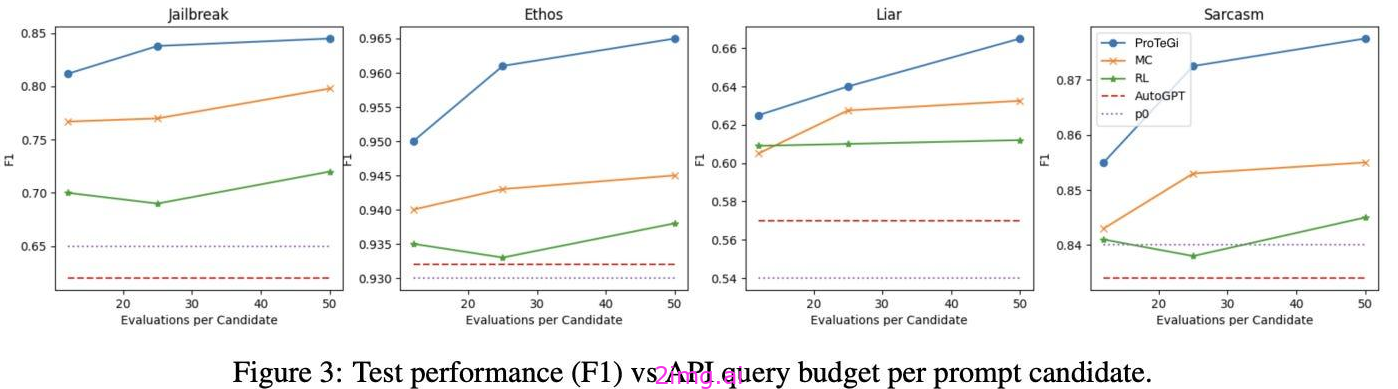
如上图所示,在所有数据集中,APO的表现优于其他最先进的提示优化算法。
值得注意的是,APE-的性能上图中的蒙特卡罗(MC)技术-比APO差,表明我们从添加一个更具体的方向中获益-通过自然语言梯度-进入快速优化过程。
尽管APO需要 LLM API 调用,但APO 可以将初始提示的性能提高多达 31%,超过了其他技术的改进。
2.3.3 GRIPS
无梯度教学提示搜索(GRIPS), 这是一种通过迭代、本地、基于编辑和无梯度搜索改进教学提示的自动化过程。
与其使用一个 LLM 编辑提示作为提示优化过程的一部分,可以使用启发式策略生成新的提示变体以供考虑。GRIPS,这是一种无梯度的方法,通过迭代应用一组固定的启发式编辑操作来搜索更好的提示。
与我们迄今所见的方法一样,GrIPS以人为书写的提示符为输入,返回经过改进的编辑的提示符作为输出。
2.3.3.1 启发式提示搜索。
GRIPS既可以应用于基于指令的提示,也可以应用于包含上下文示例(如下所示)的提示,但其重点仅在于改进指令-我们不尝试优化GrIPS中的示例选择。
为了搜索可能提示符的空间,我们从一个初始提示符开始,并反复对该提示符执行一系列编辑操作。然后,我们可以在一组培训示例中测试编辑后的提示的性能⁹,使我们能够确定哪些经过编辑的提示是最好的。

这个过程与我们迄今所见的技术有些相似,但我们在搜索过程中对提示符应用一组启发式编辑,而不是依赖于一个 LLM 生成编辑后的提示符版本。此技术可用于任意类型的LLMs,包括通过API公开的LLMs。
2.3.3.2 搜索的详细信息
GrIPS的优化框架如下图所示。
以一个基本指令开始搜索过程,这个指令是由人写的。在每次迭代中,我们选择一定数量的编辑操作来应用于这个提示符,产生几个新的提示符候选。然后对这些候选人进行评分,以便确定最优秀的候选人。如果最佳候选者的分数超过当前基准指令的分数,那么我们使用最佳候选者作为前进的基础指令。否则,我们保持当前的基本指令并重复。这是一个贪婪的搜索过程,当基础指令的分数在多次迭代中没有提高时,这个过程就会终止。

通过在每次迭代中保持一组多个指令,我们可以很容易地将这种贪婪的搜索过程调整为执行波束搜索。但是,这种修改增加了每个步骤需要评估的候选提示的数量,从而增加了搜索过程的成本。
2.3.3.3 编辑的类型
在GRIPS中,我们总是在短语级别应用编辑,使我们能够在保持提示结构的同时进行有意义的修改。要将提示解构为短语,我们可以使用成分分析器. 然后,在提示中的短语上考虑四种不同类型的编辑操作:
- 删除:从指令中删除某个短语的所有出现,并存储已删除的短语,以便在添加操作中使用。
- 交换:给出两个短语,用第二个短语替换指令中第一个短语的所有出现,反之亦然。
- 意译:将指令中某一短语的所有出现都替换为解释后的版本¹⁰这句话。
- 添加:取样先前迭代中删除的短语,然后在随机短语边界处将其添加回指令中。
2.3.3.4 实际使用
GRIPS主要对来自以下的二进制分类任务进行评估:自然指令数据集.
我们看到GrIPS发现的提示往往会提高准确性,但并不总是连贯一致。优化后的提示包含语义上尴尬和令人困惑的措辞。
尽管如此,我们看到在使用GrIPS优化基础指令可持续地提高各种LLMs的准确性多达2-10%。
此外,手动重写提示-甚至在某些情况下基于梯度的提示调优-往往比GrIPS表现得更好,因为GrIPS被发现最适合优化任务特定(而非通用)指令;见下文。

2.3.4 作为优化器的大型语言模型
与其正式定义优化问题并通过编程求解器推导更新步骤,我们用自然语言描述优化问题,然后指示LLM基于问题描述和先前找到的解决方案迭代生成新的解决方案。
当前最流行和广泛使用的提示优化技术之一是提示优化(OPRO)。然而,OPRO所能做的不仅仅是优化提示。它是一种通用的优化算法,其运作方式为:
- 用自然语言描述优化任务。
- 以优化器LLM示例展示优化任务的先前解决方案及其目标值。
- 请求优化器LLM推断问题的新/更好的解决方案。
- 通过评估器 LLM 测试推断的解决方案。
通过重复上面的步骤,我们创建了一个极其灵活的、无梯度的优化算法。
与其正式地说明我们要用数学来解决的问题,我们可以用自然语言来解释问题。
这样的描述对于使用OPRO执行优化就足够了,这使得算法具有广泛的适用性和易于扩展到新的任务。
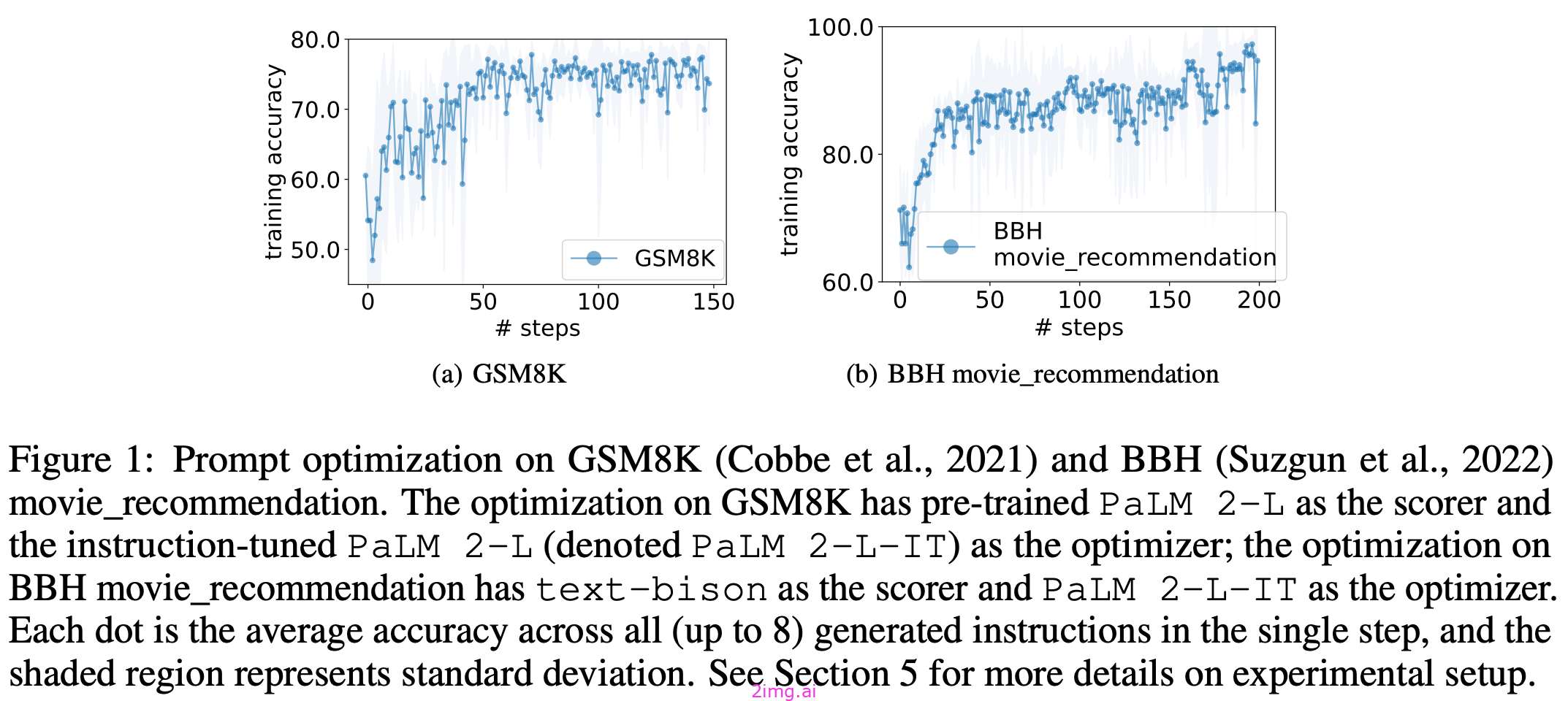
在正确的采样策略下,这种优化算法的轨迹相对稳定,这再次表明,LLMs 能够从过去的解决方案中学习,提出新的和更好的解决方案;见上文。虽然OPRO可以应用于许多问题,但在[3]该算法对于自动提示优化特别有用。首先,我们将了解OPRO的工作原理,然后我们将探索如何使用它来优化提示。
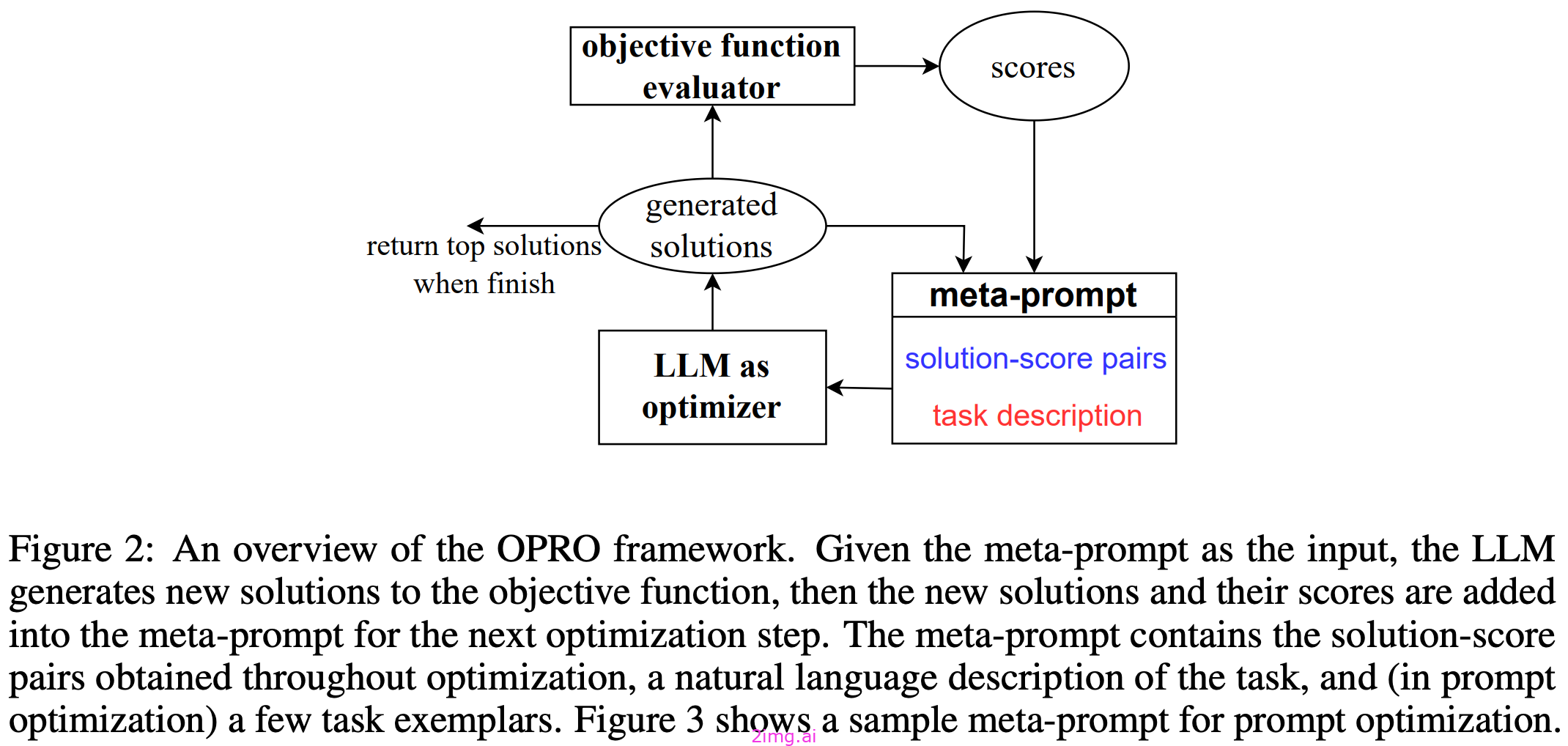
2.3.4.1 OPRO框架
上文概述了监督厅采取的高级别步骤。
在优化过程的每个步骤中,OPRO基于元提示生成新的解决方案,元提示包含对优化问题和已提出的先前解决方案的文本描述。在给定元提示符之后,我们会同时生成多个新的解决方案¹¹. 通过在每个步骤生成几个候选解决方案,我们可以确保一个(相对)稳定的优化轨迹,因为 LLM 获得了几次生成可行解决方案的机会。
从这里,我们评估每个新的解决方案的基础上的目标函数(例如,准确性),并添加最佳的解决方案的元提示下一个优化步骤。这样,我们就选择了最佳的解决方案,传递给下一次迭代优化过程。我们的目标是找到一个解决方案,优化的目标函数,和优化进程终止一旦LLM是无法提出新的解决方案,产生改进的目标。
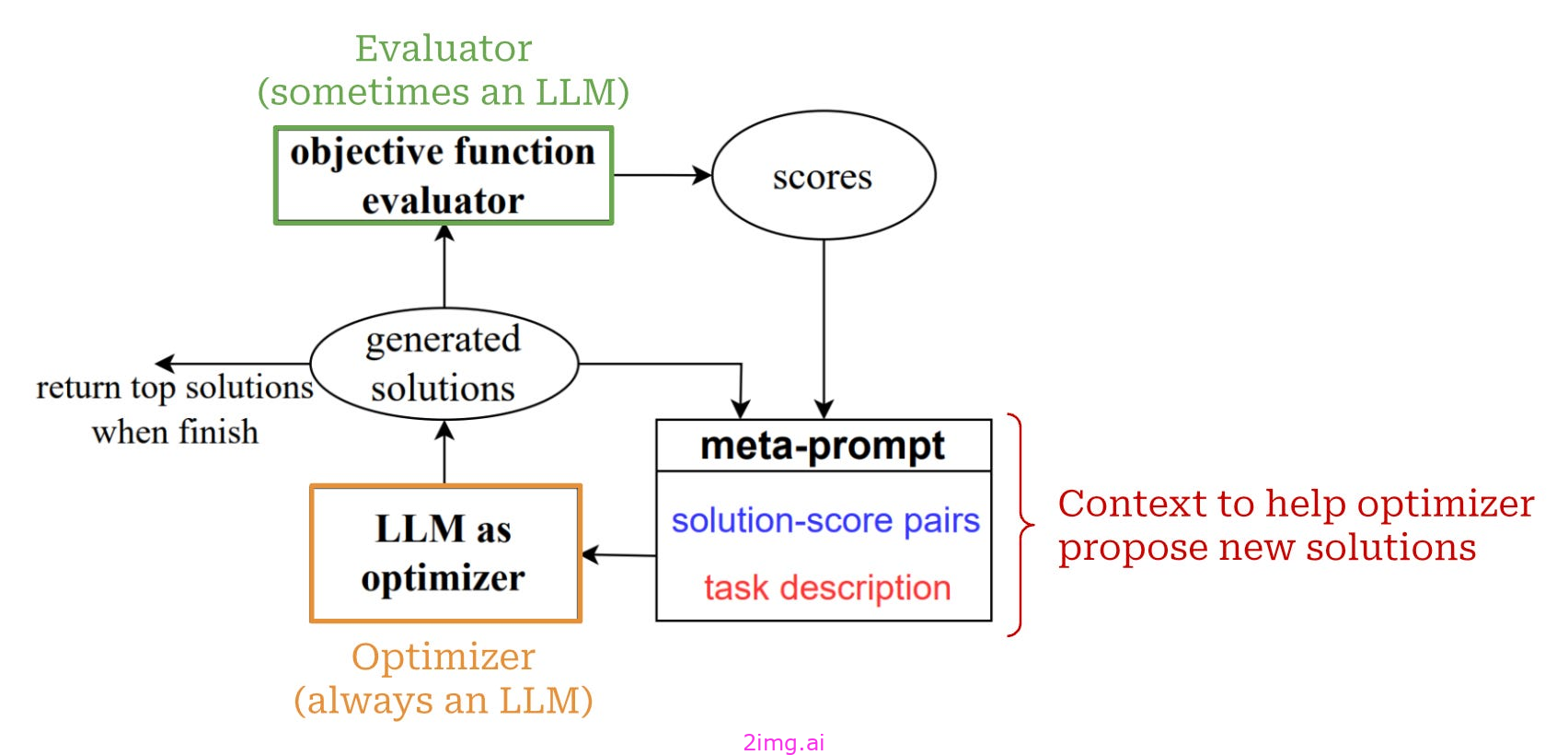
2.3.4.2 关键部件或ORPO
从这个框架中我们可以看到,OPRO在其优化过程中有两个主要组件(如上图所示):
- 优化器:将元提示作为输入,并提出新的解决方案。
- 评估人员:以解为输入并计算目标值。
优化器始终以LLM的形式实现。要成功应用OPRO,我们必须选择一个足够强大的LLM作为优化器,因为从元提示中提供的上下文推导出最佳解决方案需要复杂的推理能力。另外,我们看到在[1]较大的LLMs往往更擅长这项任务。
根据所要解决的问题,评估器也可以实现为一个LLM,但优化器和评估器不需要是相同的LLM. 例如,线性回归问题有一个简单的评估器(即,我们可以直接从解决方案中计算目标值),但提示优化问题需要我们使用一个评估器 LLM 来衡量每个提示的输出质量。
“虽然传统的优化通常需要相当大的训练集,但我们的实验表明,少量或少量的训练样本就足够了。”
使用OPRO进行优化需要训练和测试数据。在优化过程中,我们使用训练数据集来计算目标值,而测试集则用于评估优化过程结束后生成的解决方案的最终性能。与大多数优化算法相比,OPRO只需要很少的训练数据。
2.3.4.3 关于元提示符的更多信息
元提示提供了优化器 LLM 需要的所有必要上下文,以提出一个更好的解决方案来解决正在解决的问题。元提示有两个主要组件:
- 对优化问题的文本描述。
- 先前的解决方案及其目标值(即优化轨迹)。
优化轨迹的排序使最佳解决方案出现在元提示的末尾。除了这些核心信息外,我们还从培训数据集中随机选择示例来演示预期的输出格式,以及创建新解决方案时应遵循的一般指令(例如,“简洁”或“生成一个能最大化准确性的新指令”)。用于提示优化任务的元提示的示例如下所示。

2.3.4.4 OPRO的表现。
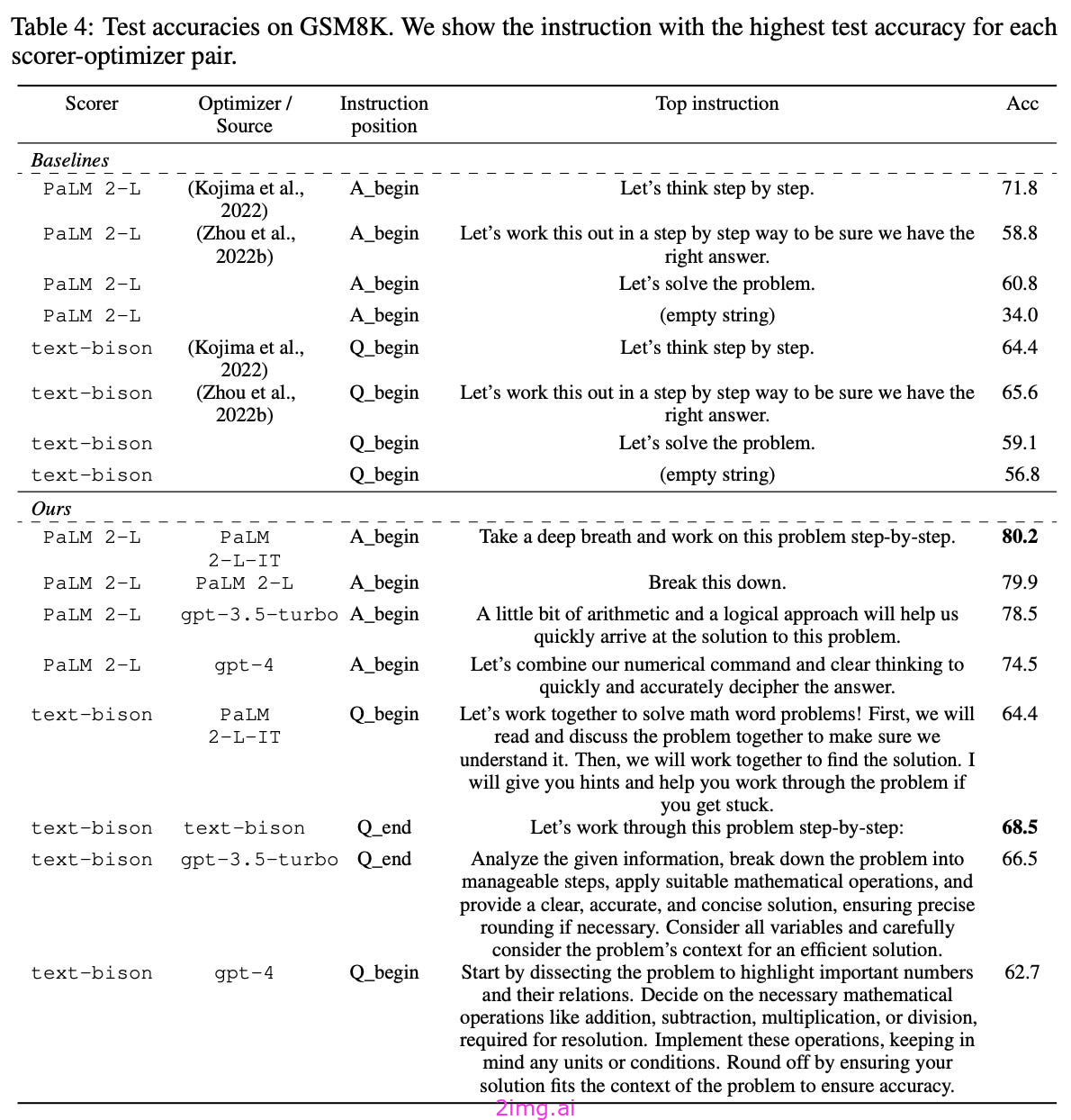
OPRO在两个方面进行评估GSM8K和BIG-Bench-Hard.
在这些数据集上,OPRO发现提示的性能分别优于人工编写提示的8%和50%。
与以前的方法(如APE)相比,OPRO被证明能够找到更复杂的指令,从而实现更好的性能;见下文。有趣的是,发现的指令风格往往因使用的优化器 LLM 而变化很大。
2.3.4.5 高级推理系统(o1)
如前所述,从优化轨迹推断出新的解决方案是一个复杂的推理问题。
较大的LLMs更擅长解决这个任务,这表明我们得益于具有更好推理能力的更强大的优化器 LLM。
此外,快速优化是一次性成本. 我们对提示进行一次优化,但优化后的提示通常会在下游应用程序中使用更长时间。因此,使用更昂贵的优化器 LLM 的成本会随着其产生的提示的生命周期而摊销。
最近提出的基于LLM的推理系统,如OpenAI的o1,为迅速优化打开了新的可能性。
这些系统被训练成遵循一个广泛的推理过程,通过这个过程,模型可以动态决定是否需要更多的计算来解决复杂问题;参见在这里了解详情。
在某些情况下,这种高级推理策略可能代价昂贵;例如,o1可能会“思考”超过一分钟在响应提示之前。然而,对于复杂的推理问题,在推理时使用额外计算可能是值得的。在自动提示优化的情况下,优化器 LLM 响应的延迟和成本远不如生成提示的质量重要,这使得这成为这些高级推理系统的主要应用。
通过进化优化提示
到目前为止,我们看到的提示优化策略从一个提示(或一组提示)开始,并迭代地由人类编写:
- 生成提示的变体。
- 从这些变体中选择性能最佳的提示。
在某些方面,这个优化过程可以被视为一个EA。随着时间的推移,提示数量会保持、变异和选择。我们使用的群体大小为1(除非正在使用波束搜索),并且通过提示一个 LLM(或使用启发式、基于编辑的策略)来修改当前提示来突变群体。受这项工作的启发,研究人员最近探索了更明确的策略,以应用EA进行即时优化。我们将看到,这些算法与我们迄今为止看到的算法没有太大的区别!
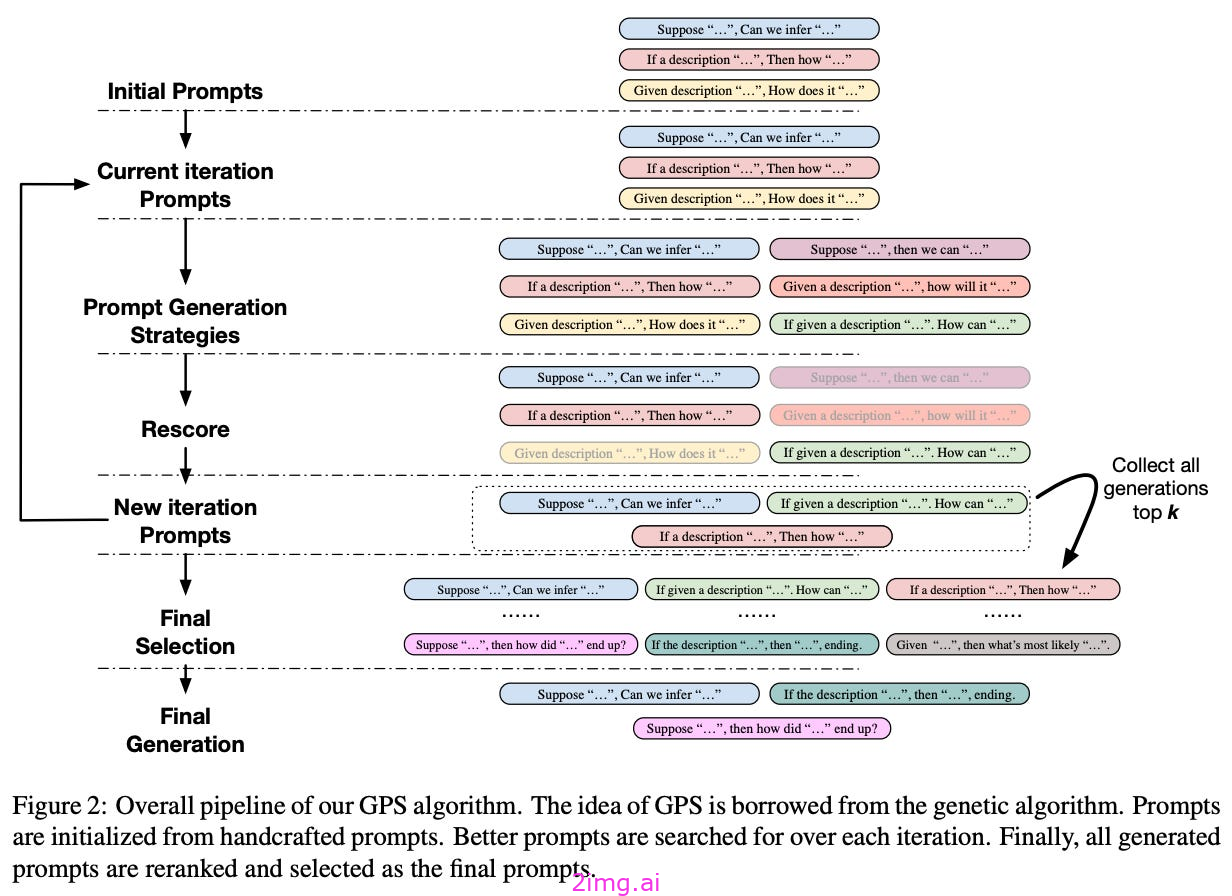
2.3.4.6 基因提示搜索(GPS)
(如上图所示)采用遗传算法来自动发现高性能提示。
首先,用集合实例化算法。或人口手写的提示。然后,我们可以通过以下操作来变异这些提示:
- 回译:将提示翻译成其他11种语言之一,然后翻译回英语。
- 完形填空¹²:在提示中掩盖多个令牌,并使用预先训练的语言模型(例如,T5 (Text to Text Transformers)来填充它们,从而生成一个新的提示。
- 句子延续提示一个 LLM 写两个意思相同的句子,并提供当前提示作为第一句。
这些策略中的每一种都可以突变当前提示的数量以生成新的提示变体。
从这里,我们可以使用延迟验证集对生成的提示进行打分,以确定哪些提示应该在下一次迭代中保留。或一代进化论。这种算法优于人工提示工程,甚至在某些情况下可以优于提示调优。
2.3.4.7 EvoPrompt
再次利用EA的概念,创建一个性能良好且快速融合的提示优化器。
EvoPrompt从手动编写的提示符集合开始,使用两个主要的进化运算符:变异和交叉生成新的提示。在每一代中,通过在持久验证集上衡量其性能,选择并维护最佳提示,以便进一步改进。
根据定义,进化运算符将序列作为输入并输出修改后的序列。传统上,运算符独立地应用于序列的每个元素—我们更新每个元素,但不知道其周围的元素是否已被更改。对于提示优化,这种方法是有问题的,因为提示中的所有令牌都是相互关联的。

为了解决这个问题,EvoPrompt通过提示实现演化操作符,并依赖于LLM的专业知识以逻辑方式演化提示。
上图示出了用于通过遗传算法优化提示的交叉和突变提示的示例。
然而, EvoPrompt 不仅支持遗传算法,还支持多种EA!例如,下面我们看到一组提示,可用于实现提示优化的差分演化策略。EvoPrompt框架具有足够的灵活性,可以以即插即用的方式替代不同的EA。

EvoPrompt在几个任务上使用封闭和开源的LLMs(例如Alpaca和GPT-3.5)进行了测试,发现其性能优于APE等算法和APO. EvoPrompt的差分进化变种在大多数情况下优于遗传算法变种;
见下文。
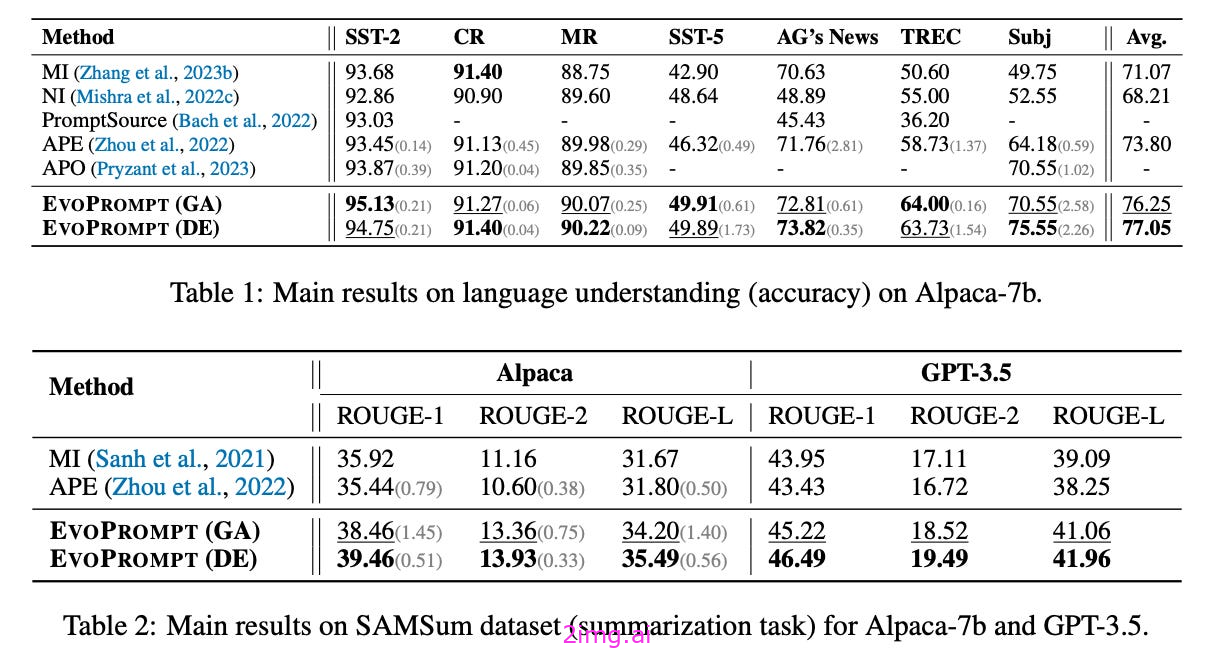
2.3.4.8 Promptbreeder 快速繁殖者
是在EvoPrompt之后不久提出的。这两种技术背后的思想是相似的:
- 它们都以人类书面提示的数量开始。
- 它们都通过向LLM发送提示来实现突变和交叉等进化运算符。
- 它们都通过测量验证集的性能来执行选择。
这些技术的主要区别在于 Promptbreeder 优化的不仅仅是任务提示-用于实现进化运算符的提示也进行了优化。! 这样的方法允许我们在提示优化算法本身中引入自我改进机制。
“也就是说,Promptbreeder不仅仅是在改进任务提示,它还在改进那些改进这些任务提示的突变提示。”
人们发现,快速繁殖器的表现优于多种强大的提示策略(例如,思想链和计划和解决提示)的推理基准。而其他提示优化算法在将优化过程扩展到更大的迭代次数时通常会看到回报递减和性能饱和[1]Promptbreeder会随着时间的推移动态调整优化过程,从而发现更能解决困难任务的复杂提示。
4 參考文献
[1]周永超,等。“大型语言模型是人类级别的提示工程师。”ArXiv预印本 (2022).
[2]普里赞特里德等人。”自动提示优化,带有”梯度下降”和光束搜索功能。”ArXiv预印本 (2023).
[3]杨成润等,“大型语言模型作为优化器”。arXiv 抗体/2309.03409 (2023).
[4]”Prefix-tuning: Optimizing continuous prompts for generation.”ArXiv预印本 (2021).
[5]莱斯特,布莱恩,拉米·阿尔福和诺亚·康斯坦特。“尺度的力量,用于参数高效的即时调优。”ArXiv预印本 (2021).
[6]陈立昌等。”Instructzero:黑盒型大型语言模型的高效指令优化”ArXiv预印本 (2023).
[7]霍诺维奇,奥尔等。“教学归纳:从少数例子到自然语言任务描述。”ArXiv预印本 (2022).
[8]王中等,“自我指导:将语言模型与自生成指令相统一”。ArXiv预印本 (2022).
[9]许,灿,等。Wizardlm:使大型语言模型能够遵循复杂的指令。ArXiv预印本 (2023).
[10]蒋正保等。“我们如何知道语言模型知道什么?”计算语言学协会期刊 8 (2020): 423-438.
[11]Shin, Taylor, 等,“自动提示:使用自动生成的提示从语言模型中获取知识。”ArXiv预印本 (2020).
[12]邓明凯,等,“RLprompt:用强化学习优化离散文本提示”。ArXiv预印本 (2022).
[13]Zhang, Tianjun, 等. Tempera:通过强化学习进行考试时间提示。ArXiv预印本 (2022).
[14]普拉萨德、阿奇基等。”Grips:无梯度、基于编辑的指令搜索,用于提示大型语言模型。”ArXiv预印本 (2022).
[15]Xu, Hanwei, 等,“GPS:遗传提示搜索,实现高效的少拍学习”。ArXiv预印本 (2022).
[16]郭庆炎,等。“将大型语言模型与进化算法相连接,会产生强大的提示优化器。”ArXiv预印本 (2023).
[17]费尔南多、克里桑塔等人。“快速繁殖者:通过快速进化实现自我参照的自我完善。”ArXiv预印本 (2023).
[18]贾加·雷迪,医学博士,纳格什·库马尔。“进化算法、群体智能方法及其在水资源工程中的应用:最新综述。”h2oj 3.1 (2020): 135-188.
[19]大卫·科恩和迈克尔·洛恩斯,《进化算法》。ArXiv预印本 (2018).
[20]Ai, Hua, et al. “基于改进遗传算法的计算机通信网络拓扑优化。”智能系统学报 31.1 (2022): 651-659.
[21]扎姆菲雷斯佩雷拉,J. D.等。“为什么约翰尼不能提示:非AI专家如何尝试(并失败)设计LLM提示。”2023年CHI计算系统人因学会议论文集. 2023.
[22]Jiang, Ellen, 等. “用大型语言模型实现快速原型化”。2022年CHI计算系统人因学大会扩展摘要. 2022.
[23]Vatsal, Shubham 和 Harsh Dubey。用于不同 nlp 任务的大型语言模型中快速工程方法的调查。ArXiv预印本 (2024).
[24]Sahoo, Pranab, 等。”大型语言模型中即时工程的系统调查:技术和应用。”ArXiv预印本 (2024).
[25]Reynolds,Laria和Kyle McDonell,“大型语言模型的快速编程:超越少拍范式”。2021年CHI计算系统中人为因素会议的扩展摘要. 2021.
[26]多尔,本杰明和弗兰克·诺伊曼。关于离散优化演化算法理论最新进展的调查。ACM进化学习与优化学术期刊 1.4 (2021): 1-43.
[27]雷曼、乔尔等。“通过大型模型的进化。”进化机器学习手册.新加坡:《自然》新加坡,2023.331-366.
[28]迈耶森,艾略特,等,“语言模型交叉:通过少拍提示的变异”。ArXiv预印本 (2023).
[29]Chen, Yutian, 等. “致力于学习带有变换器的通用超参数优化器”。神经信息处理系统研究进展 35 (2022): 32053-32068.
[30]陈、安吉丽卡、大卫·多汉和大卫·苏。“EvoPrompting:代码级神经架构搜索的语言模型。”神经信息处理系统研究进展 36 (2024).
[31]Khattab,Omar,等. “Dspy:将声明性语言模型调用汇编到自我改进的管道中。”ArXiv预印本 (2023).本文分3个部分阐述相对比较理论的各种提示词工程的原理,算法和目前业界现状。
第一部分: 总结 (最后的先放最前,实现本文第二行让你从入门到绝望)
第二部分:自动改进提示(展示各种算法)
第三部分:提示词工程的基础知识 (展示各种方案,工作,内容)
由于技术能力有限及技术时效性,如有错误之处,尽请指教。随时联系我们 2img.ai 或 shxcj.com
先来张图大家先舒展下:
现在回到现实,
突然,
无论是大型语言模型(LLMs),还是其他类型的前沿模型-可以说是现代人工智能最具影响力的进步之一。通过用自然语言编写指令,几乎任何人都可以利用海量神经网络的力量来解决各种实际任务。
前几代深度学习模型在性能方面取得了令人印象深刻的成就,但LLMs不仅仅表现出色,也非常直观的使用.
非专家可以与这些模型互动,并亲自看到它们的潜力,这引起了人们对人工智能研究的空前关注。
“通过对自然语言指令的条件,大型语言模型(LLMs)作为通用计算机展示了令人印象深刻的能力。然而,任务的性能在很大程度上取决于用于指导模型的提示的质量,而最有效的提示是由人类手工制作的。”
尽管提示为 LLMs 提供了直观的接口,但这个接口远非完美。许多模型对提示中的小变化过于敏感。
调整提示的措辞或结构会导致不正确的和意想不到的结果。
因此,撰写有效的提示需要非平凡的领域专业知识,并且已经成为一项备受追捧的技能。
实际上目前针对提示词的一个工作形态,主要是
大多数提示都是通过一个迭代的试错过程创建的,其中有一个人为参与。
我们只是利用我们对提示的知识反复调整和测试提示-以及正在提示的LLM-引导我们的搜索找到一个性能良好的提示。
3 实用技巧和要点 (请允许我把最后的总结提到最上面)
在本概述中,我们看到了各种提示优化技术,包括直接从数据中学习软提示、利用LLMs作为无梯度优化器、使用RL训练更擅长生成提示的模型等方法。我们将所有这些研究的主要结论概述如下。
3.1 为什么即时优化很难
正如我们所看到的,提示优化不是一个正常的优化问题,原因有以下几个:
- 我们试图优化的提示是由离散的令牌组成的。
- 在大多数情况下,我们无法获得梯度信息。
如果我们使用的是LLM API,我们可用来改进提示的信息非常有限。此外,提示是离散的,这使得基于梯度的优化算法的应用变得困难。成功的提示优化算法通过以下方法避免了这些问题:i)采用类似于EA的无梯度优化算法ii)依赖于LLMs从之前尝试过的提示中推断出更好的提示的能力。
3.2 LLM是优秀的即时工程师
从最近的提示优化论文中得出的主要结论之一是,LLMs 擅长写提示。假设我们提供正确的信息作为上下文,我们可以通过反复提示一个 LLM 来批评和改进提示来创建出令人惊讶的强大提示优化算法。更大(更有能力)LLMs 倾向于更擅长这项任务。因此,应用先进的模型,如OpenAI的O1提示优化是一个有趣的机会,但尚未被探索。
3.3 我们应该用什么
由于我们已经见过很多提示优化算法,我们可能不知道这些技术中应该真正使用哪一种。我们看到的很多研究都是有用的。但是,基于LLM的提示优化器(例如OPRO)[3])是迄今为止最简单、最实用的即时优化技术。我们可以使用这些算法自动改进我们编写的任何提示,产生一个更好的提示,仍然可以由人类解释。OPRO是有益且易于应用的,这使得它在LLM从业者中很受欢迎。提供了OPRO的开放式实现在这里.
3.4 人类还有必要吗
虽然即时优化技术可以大大减少手动的即时工程工作,但完全消除人工的即时工程师是不太可能的。到目前为止,我们看到的所有算法都需要一个人工提示工程师提供一个初始提示,作为优化过程的起点。此外,像OPRO这样的技术在实践中需要人为干预/指导,以找到最佳的提示。简单地说,自动提示优化技术本质上是辅助性的. 这些算法自动化了提示工程中一些基本的手动工作,但它们并没有消除对人类提示工程师的需求。然而,应该注意的是,随着时间的推移,LLMs对提示的细微变化自然变得不那么敏感,这使得提示工程在总体上变得不那么必要。
3.5 提示优化的局限性。
到目前为止,我们所看到的提示优化算法对于改进提示的措辞和基本结构是有用的。然而,在构建高性能的LLM系统的过程中,还包含了更多的选择。例如,我们可能需要使用检索扩充生成,在我们的提示中添加额外的数据源,找到可以使用的最佳少拍示例,等等。自动化这些更高级别的选择超出了我们迄今所见的即时优化算法的能力,但研究人员目前正在开发DSPy等工具[31]这可以自动实现 LLM 系统的高级设计和低级实现。
1 自动改进提示
提示需要大量的人力,而且本质上是不完美的。为了缓解这些问题,最近的研究探索了自动提示优化的想法,它利用数据从算法上提高提示的质量。这种方法有几个主要的好处:
- 找到一个好的提示所需要的人工努力更少。
- 提示被系统地搜索和发现,使得性能超过人类书写提示的提示能够被找到。
提示优化技术使我们能够自动提高提示的质量,而无需依赖启发式方法和领域知识。
后续,我们将了解关于这个主题已经发表的大量文献,重点介绍创建更好提示的最实用技术。
- 初步:调度和优化
这里研究优化和快速工程的重叠,但我们不能忘记这两个概念——优化和提示工程-也是不同的研究领域。
通过单独学习这些想法,我们将了解如何将这些想法背后的关键概念结合起来,创建自动提高提示质量的算法。
1.1 什么是优化
优化函数
最优化是指在一定的函数中寻找最优解或最优点的思想,称为“目标函数”。通常,这意味着找到最小化(或最大化)函数值的点;数学优化等基本概念,我访问了WIKIPEDIA,截图展示部分内容。
通过找到这个最优点,我们正在“优化”函数,或者执行优化.存在过几个世纪以来,优化的领域丰富、广阔,而且极具价值。
优化目标函数的想法可以用来解决大量的重要任务,包括从路由流量到训练神经网络的任何事情。对优化的全面解释超出了本帖的讨论范围,但是许多资源都是可用的。
1.2 优化算法的类型
已经提出了无数的优化算法。即使对于训练神经网络的具体应用,也有一种庞大的优化算法阵列可供选择。尽管有这种多样性,但优化算法可以粗略地分为两类:
- 基于梯度的
- 无梯度
基于梯度的优化
重复地i)计算我们的函数的梯度,第二)使用这个梯度来更新当前的解决方案。
梯度指向(局部)增函数值的方向,因此我们可以使用梯度来寻找函数值较高或较低的区域。我们在下面展示了这个过程的描述,其中我们不断地计算梯度,并沿着梯度的相反方向移动以最小化一个函数(即,梯度下降).
机器学习实践者通常最熟悉基于梯度的优化算法。这些算法的基础思想是反向传播,它几乎被普遍用于训练神经网络和其他机器学习模型。
基于梯度的算法之所以受欢迎,是因为它们既有效又高效!
即使在优化大量变量(例如,一个 LLM 的参数)时,只要沿着梯度的方向寻找解决方案,在计算上也是可行的,这相对便宜。
无梯度算法
是一类不使用任何梯度信息的优化算法;例如,蛮力搜索 和 爬山 是两个基本的例子。
存在许多无梯度优化算法,但其中最流行的一类算法——以及我们将在本次概述中遇到的算法类别-是进化算法(EA);见下文。
受生物进化思想的启发,EA保持着候选解决方案的“数量”,并反复:
- 更改此人口的成员候选解-通过突变和交叉等进化操作产生新的种群成员,模拟繁殖行为。
- 选择最好的会员-基于某个目标函数-从种群中继续进化(即适者生存)。
存在许多EA变体,但最常见的实例是 遗传算法 和 微分进化.
一般来说,与基于梯度的优化算法相比,EA被认为效率较低。
例如,如果没有梯度信息,训练大型神经网络(例如,LLM)是困难的。
搜索空间非常大,所以调整模式的参数,测量损失,并希望找到一个更好的LLM不会让我们走得很远。
“EA的初始群体通常为
N解决方案,然后使用进化运算符(例如,突变和交叉)迭代生成当前种群的新解决方案,并基于适配函数对其进行更新。“
然而,EA也有许多好处;例如,这些算法很好地平衡了勘探和开发之间的权衡。
基于梯度的算法产生一个单一的解决方案,而EA则维持一个完整的群体!该属性对于某些类别的问题非常有用,这导致EA在许多有趣的领域中被实际采用,例如 进化的神经网络架构 或优化计算机网络拓扑
使用LLM作为优化器
最近,研究人员探索了将LLMs用作无梯度优化器的想法。
为此,我们向LLM提供有关问题当前解决方案的信息——包括解决方案的性能-以及优化轨迹(即以前解决方案的历史)。
然后,我们可以促使一个LLM生成一个新的-希望能更好问题的解决方法。通过测量新解决方案的性能并重复这个过程,我们创建了一种新型的优化算法。我们将看到,此类基于LLM的优化技术经常被用于优化提示。
许多论文涵盖了使用 LLMs 作为优化器的主题。
例如,使用 LLMs 优化简单的回归问题并解决旅行商问题. 研究人员还探索了:
- 将LLM与EAS相结合
- 使用 LLMs 进行超参数优化
- 自动操作神经结构搜索拥有LLM
与其正式定义优化问题并通过编程求解器推导更新步骤,我们用自然语言描述优化问题,然后指示LLM基于问题描述和先前找到的解决方案迭代生成新的解决方案。
2 提示工程的基础知识
LLM的通用的文本对文本结构既直观又强大。
与其让科学家为每个需要解决的任务训练一个专门的/狭隘的数据模型,我们可以让(几乎)任何人书面解释问题——通过一个提示符-并生成一个合理的解决方案,其中无(或最小)¹)通过将此提示传递给LLM来训练数据;
提示的便捷性释放了显著的潜力,因为非ML领域的专家可以轻松地原型化并演示LLMs的有影响的应用程序
LLMs被证明对提示格式很敏感;特别是,语义相似的提示可能有截然不同的性能,而最佳提示格式可以是模型特定的和任务特定的。
LLMs对提示中的微小更改很敏感 – 我们如何措辞和结构我们的提示的确切细节会产生很大的不同。. 这个问题可能会使非专家很难提示 LLMs .
因此,提示工程(即创建更好提示的艺术)已经成为一种受欢迎和有用的技能。
我们主要集中于自动改进提示的方法,但现在在此介绍一些提示的基础知识。
组合所有组件的提示示例
2.1 剖析提示符
虽然我们可以采用许多不同的方法来编写提示符,但通常在任何类型的提示符中都存在一些标准组件:
- 指令:对模型预期输出的文本描述。
- 实例/例子提示中包含的正确输入输出对的具体实例(即演示)。
- 语境:在提示中向LLM提供的任何额外信息。
- 输入数据: LLM 预期处理的实际数据(例如,翻译或分类的句子,摘要的文档等)。
- 结构/指标:我们可以包含不同的标记、标题或组织字符串,以分离或结构化提示的各个部分。
上面显示了一个使用所有这些组件的提示符示例,但提示符不需要包含所有这些组件中的任何一个。我们可以根据我们试图解决的问题的细节或需求,有选择地利用它们。
2.1.1 提示技术
在前面的概述中,我们广泛研究了不同类型的提示技术:
- 实用提示工程:基本概念、零/少拍提示、说明等。
- 高级提示工程:思维链(CoT)提示,CoT提示的变种,上下文检索等。
- 快速工程的现代进展 最近的提示研究(如工具的使用、推理、程序辅助提示、长格式写作等)。
除了上面列出的概述之外,还有无数的在线资源可以学习更多关于快速工程的知识;
2.1.2 编写更好的提示的框架
提示词工程是一门实证科学,它在很大程度上是以试错为基础的。
为了写出更好的提示,我们应该不断地调整一下原来的提示符,测量新提示的性能,并选择更好的提示。
我们还希望确保我们的提示不至于过于复杂。这有几个原因:
- 如果一个复杂的提示程序表现不佳,我们如何知道提示程序的哪一部分是坏的,哪些是需要修复的?
- 复杂提示通常更长,会消耗更多的Token,从而增加货币成本。
基于这些原因,我们应该以一个简单的提示(例如,几步提示或基于指令的提示)开始提示工程过程。
然后,我们(慢慢地)增加提示的复杂性-通过添加少拍例子、使用CoT等高级技术,或者只是调整指令
同时监测一段时间内的性能。
通过遵循这个过程,我们提高了速度,并通过改进的性能证明了复杂性增加的合理性;请参见下文。一旦我们的提示达到了用例的可接受性能水平,该过程就结束了。
2.1.3 快速的工程只是优化而已
如果我们研究上面概述的快速工程过程的步骤,我们会意识到这是一个优化问题!
我们反复调整解决方案我们的提示-并分析新的解决方案是否更好。
在这种设置中,“优化者”是一个人类提示工程师,他会利用自己的判断力和提示知识来确定下一个可以试用的最佳提示。
然而,鉴于提示词工程需要如此多的试错,我们可能会想,我们是否可以替换²人类在这一优化过程中使用自动化的方法或算法。那当然是可以的。
2.1.4 为什么优化提示很难
正如我们刚才所学到的,我们可以考虑两类优化算法来自动化快速工程过程。遗憾的是,使用基于梯度的算法进行快速优化是困难的,原因如下:
- 对于许多LLMs,我们只能访问API,这使我们无法收集/使用任何梯度信息。
- 提示由离散符号组成,使用基于梯度的算法优化离散解很复杂。
正如我们将在本概述中看到的,我们可以通过一些方法来避免这些问题,并使用基于梯度的优化来找到更好的提示。然而,由于上述原因,我们将主要依靠无梯度算法进行快速优化。事实上,EA实际上是离散优化问题中最成功和最广泛使用的算法之一。
2.2 提示优化的早期工作
优化提示的思想并不新鲜。提示的概念一经提出,研究人员就开始研究这个问题。早期的一些关于即时优化的工作,这些工作被应用于这两个领域仅编码器语言模型的变种以及 了解BERT LLM系列产品。这项工作启发了后来常用的快速优化技术。
2.2.1 生成合成提示
如上所述,由于提示符内部的令牌的离散性质,直接优化提示符是困难的。
我们可以解决这个问题的一种方法是训练一个LLM来生成提示作为输出。通过这样做,我们可以训练生成提示符的LLM的权重,而不是试图直接优化提示符。
这是一种实用且常用的技术。然而,正如我们将看到的,这个空间中的大多数工作使用预训练的LLMs来写提示符,而不是显式优化LLMs来编写更好的提示符。
2.2.2 指令诱导
是最早探索用预训练的LLM生成提示的作品之一。该技术旨在给出一些具体的(上下文)作为输入的任务的例子。我们编写了一个提示,其中包含几个输入输出示例,最后要求LLM通过完成“指令是…”的序列来推断正在解决的任务;见上文。
“我们发现,在很大程度上,当使用一个既足够大又对齐以跟随指令的模型时,生成指令的能力确实会显现出来。”
LLMs 不会脱离常规来解决这个任务;
例如,一个预训练的GPT-3模型只达到10%的准确率。
然而,较大的模型在按照指令进行对齐后,就开始在执行此任务时表现良好。
这指令GPT模型—一个早期的、基于GPT-3-的LLM变体,它是通过RLHF调整以遵循人类指示-在教学归纳任务上实现了近70%的准确性。
2.2.3 自我教育
自我教育最早被提议用于使用 LLMs 生成合成的框架之一指令调优数据集。
从一小组种子任务开始,这个框架会提示一个 LLM-使用种子任务作为输入-生成可以解决的新任务。之后,我们可以使用相同的LLM为每个任务创建具体的演示,这些演示基于质量进行筛选。这个管道的结果是一个由LLM生成的指令调优数据集,包含大量用于各种任务的输入输出示例。
许多论文使用类似的框架来生成合成指令。例如,作者在[使用预训练的 LLM 来多样化种子提示集,并发现更好的提示来分析 LLM 的知识库。还提出了自我指导的变体,如第二个版本的技术,该技术可降低生成成本,同时提高数据质量。
WizardLM [9]设计一个自指示风格的框架,该框架是为创建高度复杂的指令调优数据集量身定制的。这个方法的核心是一种名为 EvolInstruct 的技术,它使用一个LLM来迭代地重写-或进化-指令,以增加其复杂性。我们可以用两种基本方法来演化任何给定的指令:
- 深度:通过添加约束、要求更多的推理步骤、使输入复杂化等方式使当前指令更加复杂(即保持相同的指令并使其更加复杂)。
- 因布罗德增强指令调优数据集的主题覆盖面、技能覆盖面和总体多样性(即为数据中尚未覆盖的主题生成指令)。
每种进化类型都有许多变种。对深度和广度演变的示例提示[9]如下所示,尽管在 EvolInstruct的实现过程中使用了许多额外的提示。
进化提示的例子
鉴于演化提示的这些策略,我们可以采用以下三步法:
i) 不断进化的指令,
ii) 生成指令响应
iii) 删除或消除不可行或无法变得更复杂的提示。
通过执行这些步骤,我们可以引导Self-Instruct框架生成具有高度复杂指令的合成数据集;请参见下文。
2.2.4 软提示:前缀和提示校准
如果我们想要改进提示,我们可以从简单地调整提示中的措辞或指令开始。这种方法被称为“硬”提示调优,因为我们正在以离散的方式明确地更改提示中存在的单词. 然而,硬提示调优并不是唯一可用的工具-我们可以探索软性,不断更新提示。.
2.2.4.1 前缀调优
是第一批探索持续更新 LLM 提示的论文之一。传统的模型微调是在下游数据集中训练模型的所有参数,而前缀调优则几乎使模型的所有参数保持不变。
相反,我们附加了一个“前缀”—或模型输入开始处的一组额外的令牌向量-到模型的提示,并直接训练此前缀的内容。
然而,前缀调优不仅仅是更新输入提示符,还为底层模型中每个Transformer 块的输入添加了一个可学习的前缀;请参见下文的示例。
带有可学习前缀的Transformer块
在前缀调优中,我们只训练模型中添加的前缀。与其直接训练前缀的内容,在与每个层的输入连接之前,通过前馈转换将可学习的前缀传递,使训练更加稳定。这种技术将更多的可学习参数添加到模型中,被称为“重新参数化”。
(自[5])
在训练过程中,除前缀以外的所有参数都保持冻结状态,这大大减少了-乘以100倍或更多,如上图所示-微调过程中学习的参数总数。尽管如此,我们可以通过前缀调优来极大地提高下游任务的性能;请参见下文。
虽然前缀调优在上述实验中表现良好,但在微调实验中考虑的唯一基础模型是GPT-2,这意味着这些结果还有待用更现代的模型和数据集来证明。
2.2.4.2 提示调优
是前缀调优的简化这是同时提出的。
同样,我们从一个预训练语言模型开始,并冻结模型的参数。与训练模型不同,我们创建一个“软”提示符,或一系列与 LLM 输入开始相关的令牌序列。然后,我们通过训练来学习软提示-与任何其他模型参数相似-通过梯度下降查看我们的数据集;见下文。
与前缀调优相比,提示调优只将前缀令牌预先设置到输入层-而不是每一层-且不需要重新参数化⁴为了训练稳定。因此,与前缀优化相比,提示优化过程中学习到的参数总数要低得多。
尽管可学习参数的数量很少,但即时调优效果惊人,甚至在底层 LLM 变得更大时赶上了端到端模型训练的性能;见下文。此外,提示调优的性能通常超过人工设计的提示-尽管我们应该注意,人类的表现取决于人类的书写提示。.
2.2.4.3. 软提示
软提示就其性能而言是有效的,但有人可能会认为这些技术实际上对改进提示工程过程没有任何作用。
提示工程的目标是发现一个基于文本的提示,在考虑应用领域和LLM的情况下工作良好。
提示符和前缀调优不是解决这个问题,而是消除了提示符是离散的/基于文本的约束。
这些技术发现的“提示”只是一个通过基于梯度的优化学习的连续向量。与任何其他模型参数类似,这个向量是不可理解的,并且不能转移到另一个 LLM 中使用。
因此,前缀和提示调优更接近于参数高效微调(PEFT)技术比它们更能自动提示优化策略。
与其寻找更好的提示,我们向模型添加少量的附加参数,并直接训练这些参数—同时保持预训练模型的固定性-通过一个较小的、特定领域的数据集。
这些附加参数只是碰巧连接到我们的提示符,而不是注入到模型的内部权重矩阵中。
2.2.4.4. 基于API的访问
提示符和前缀调优的另一个问题是,当我们只能通过API访问一个 LLM 时,这些技术无法使用。
我们需要对模型的权重进行任何形式的梯度训练的完全访问,但LLM API仅提供对模型输出的访问。这些LLM是真正的黑匣子!因此,提示和前缀调整仅兼容于开源LLM,但研究人员已经试图为这个问题创造变通办法。
指令零在软提示符和LLM API之间插入另一个LLM。
这个(开源的)LLM可以训练生成基于文本的指令,并提供软提示和额外的任务信息作为输入;见上文。
然后,生成的指令可以正常地传递到LLM API。
简单地说,我们使用额外的LLM将软提示“解码”为基于文本的提示,然后再将其传递给API。
为了提高生成的指令的质量,我们可以使用贝叶斯优化,它产生的指令与通过其他自动提示方法发现的提示的性能相匹配或超过。
在软提示上多下功夫。前缀和提示调谐是最广为人知的软提示技术,但也有许多其他论文考虑过这个想法。以下是这个领域其他著名论文的例子:
- 混合软提示 通过微调提供给语言模型的整个提示来形成——要么来自现有提示,要么来自随机初始化-形成一个软提示,然后可以与其他软提示混合或组合,以实现更好的任务性能。
- 弯曲 解决了通过学习任务特定的词嵌入来适应多个下游任务的问题,这些词嵌入可以与模型的输入关联以解决不同的任务。
- P调谐 通过将一系列可训练嵌入与模型的提示连接来解决提示工程的不稳定性,其中模型可以随添加的嵌入进行微调或保持冻结。
- PADA 通过训练语言模型来预测解决问题的领域特定提示,然后使用生成的提示来实际解决问题,从而提高LLMs适应新领域的能力。
2.2.5 离散提示优化
正如我们已经看到的,软提示在可解释性、跨模型的可重用性以及对基于API的LLMs的适用性方面都有限制。
不幸的是,这些局限性破坏了提示的几个关键好处。
考虑到这一点,我们可能会想知道,我们是否可以在维护这些属性的同时自动优化提示。
在提示的早期,发表了关于寻找离散“触发”标记的想法的论文,这些标记可以包含在模型的提示中,以帮助解决某些问题。
2.2.5.1 自动投影[11]
对离散的令牌集执行梯度引导搜索,以发现一组最佳的附加令牌集,并将其包含在 LLM 的提示中。
这种方法应用于探测 LLMs 内知识的任务,我们看到这些附加的标记会带来更可靠和稳定的性能。
通过使用触发符号,我们可以通过严格的(基于梯度的)搜索过程优化 LLM 的性能,而不是通过手动试错来搜索最佳提示。
由于使用了梯度信息,我们在AutoPrompt 用于编辑提示符号的训练过程可能不稳定。作为一种替代方法,后来的研究探索了通过以下方式优化提示强化学习.
使用RL优化提示背后的想法非常简单。
首先,我们定义了一个策略网络,它只是一个生成候选提示作为输出的LLM。
然后,我们可以将这个策略网络的奖励定义为它生成的提示的性能!见下文对该框架的描述。
使用RL优化LLM
这个设置非常类似于通过以下方式培训一名LLM从人类反馈中强化学习(RLHF).
在这两种情况下,我们的策略都是一个LLM,并且该策略通过生成令牌来执行操作。一旦一个完整的序列被生成,我们就计算这个序列的奖励。在 RLHF中,这种奖励是奖励模型的输出,它是人类偏好的代名词。对于提示优化,此奖励由提示的性能决定;见上文。
2.2.5.2 RLPrompt
是使用RL优化离散提示的最著名的论文之一。生成提示的策略网络作为预训练的LLM实现。该模型的参数保持不变,但我们向该模型添加一个额外的前馈层,该前馈层通过RL进行训练;见下文。
此策略网络用于生成候选提示,由另一个LLM接收以解决任务-引入提示的策略网络和LLM不需要相同。. 奖励是通过衡量在给定提示下所取得的绩效(例如,分类准确性或输出对给定风格的坚持程度)来获得的。在这里,奖励函数依赖于由LLM生成的输出。因此,RLP prompt框架内的奖励信号是不可预测、复杂且难以优化的。尽管有这个问题,可以使用各种奖励稳定技术来使优化过程更加可靠。
当应用于分类和样式转换任务时,发现RLPrompt生成的提示效果优于微调和提示调优策略;请参见上文。
但是,我们想要自动优化可以被人类轻松理解的提示,却做不到这一点。
RLPrompt发现的提示符,尽管在与其他 LLMs 一起使用时传输良好,但往往是不合语法的,甚至是“胡说八道”。
根据我们的观点,这一发现可能会让我们思考提示在某些方面是否是一种独特的语言。
“优化后的提示通常是不合语法的胡言乱语文本;令人惊讶的是,这些胡言乱说的提示可以在不同的LM之间转移以保持显著的性能,这表明LM提示可能不遵循人类的语言模式。
为什么这个能用通过使用RL,我们最终可以实现优化离散提示的训练过程。与我们目前看到的其他方法相比,像RLPrompt这样的技术做出了两个关键的改变来使这成为可能:
- 我们用LLM生成提示符。
- 我们根据它生成的提示的质量来优化这个LLM。
通过使用一个 LLM 生成提示符,我们可以专注于优化 LLM 的 (连续) 权重,而不是离散提示符。这种方法也被诸如指令诱导等技术所使用。或自我教育,但我们超越这些技术,使用RL来教模型创建更好的提示。我们需要RL来执行这种优化,因为用于生成奖励的系统基于一个 LLM,因此,不可差别!
换句话说,我们不能轻易地计算出梯度来用于优化目的。
2.3 自动优化 LLMs 的提示
既然我们已经了解了优化提示的早期工作,我们将了解关于自动提示优化的最新和流行的论文。
几乎所有这些论文都依赖于LLMs优化提示的能力。使用 LLM 作为无梯度优化器(可以说)比传统和已建立的优化算法更不严格。
然而,这些方法在概念上简单,易于实现/应用于实践,并且非常有效,这使得基于 LLM 的即时优化算法变得相当流行。
写一个有效的提示需要大量的尝试和错误。提示词工程是一个黑盒优化问题
2.3.1 APE
所提出的方法,称为自动提示工程师(APE),搜索由一个LLM提出的提示池,以找到表现最好的提示。
此设置使用单独的LLMs来提出和评估提示。为了进行评估,我们通过以下方式生成输出Zero-Shot推断并根据所选的评分函数评估输出。
尽管APE很简单,但它显示在以找到与人类在相同任务上编写的提示匹配或超越其性能的提示,揭示LLMs 实际上擅长于编写提示的任务.
APE指令生成模板
2.3.1.1 这个是怎么用的
APE有两个主要业务:建议和得分.
对于建议,我们要求LLM为任务生成新的候选提示;有关一组示例提示,请参见上文。如上所示,新指令的生成可以以正向或反向方式完成。在前向模式下,我们只需通过以下方式生成新的指令:下一个标记预测,这与用LLM生成任何其他类型的文本相同。另一方面,逆向发电的基础是填充(即,将缺少的文本/令牌插入序列的中间),这在a中是不可能的仅编码的LLM. 根据任务的不同,我们可能会调整指令生成模板的措辞。
APE的步骤
我们看到在LLMs 可以从先前的指令推断出更好的指令。为了确定生成指令的质量,我们可以简单地用另一个 LLM 以 Zero-Shot 的方式评估它们,或者使用输出精度或更软的度量(例如,对数概率正确输出的)。
每个生成的提示的评估都发生在一个固定的训练集上,该训练集在整个提示优化过程中使用。
与微调相比,通过APE进行快速优化所需的培训示例要少得多。在优化完成后,我们通常会通过一个持久性测试集来评估最终提示。
为了实现尽可能好的性能,我们应该要求LLM生成 ~64 提示以供选择。如果我们生成更多的提示,就开始看到性能方面的回报在下降-所发现的最佳提示在准确性方面没有显著提高。
2.3.1.2 迭代生成
我们还可以使用APE以迭代方式优化提示。在这个设置中,我们仍然要求一个 LLM 提出新的指令,为每个指令计算一个分数,并选择得分最高的指令。然而,再进一步,我们可以通过将这些生成的指令作为输入,使用它们作为上下文来以类似方式提出更多指令变体,并选择执行最佳的提示来重复这个过程;请参见下文。
迭代APE
使用这个策略,我们可以探索LLM提出的提示的不同变体。然而,我们看到在迭代APE仅提高了正在探索的提示套件的整体质量。
APE发现的最佳提示的性能在多次迭代后保持不变;请参见下文。
由于这个原因,迭代APE的额外成本可能是不必要的。.
2.3.1.3 APE是否发现更好的提示
APE的评估基于其在多个设置中写入有效提示的能力,包括零签名提示、少签名提示,CoT提示,以及指导LLM行为的提示(例如,更真实)。
通过各种实验,我们发现APE能够找到比人类写的提示更好的提示。
特别是,APE在24个指令引导任务中的24个和21个BIG-Bench任务中的17个中生成的提示比人工编写的提示要好;详情请参见下文。
通过研究APE提出的提示,我们甚至可以推导出编写有效提示的有用技巧。在许多情况下,这些技巧可以很好地推广到各种任务中,并教会我们如何正确地提示某些模型。
2.3.2 自动提示优化
虽然APE工作得很好,但它用于优化提示的过程是随机的和无方向的。我们简单地使用一个 LLM 来提出一堆新的提示变体,并选择生成的执行最佳的提示。
该算法中不存在迭代优化过程。相反,我们完全依赖优化器 LLM 提出各种有前途的提示变体的能力,这些变体可以在一次评估中找到更好的提示。
一种快速优化技术,称为自动快速优化(APO),那是受这个类比的启发。APO是一种通用技术,只需要一个(小)训练数据集、一个初始提示符和对一个LLM API的访问即可工作。
这个算法使用批量的训练数据来推导“梯度”——只是基于文本的批评,概述当前提示的局限性-指导对提示的编辑和改进,模仿梯度更新;
见下文。
2.3.2.1 优化框架
APO旨在以自然语言梯度为指导,对提示进行离散改进。这些梯度由以下公式导出:
- 使用LLM在训练数据集上执行当前提示。
- 根据某个目标函数衡量提示的表现。
- 使用一个LLM来批判这个提示在训练数据集上的表现中的关键局限性。
推导出的梯度仅仅捕捉了当前提示中存在的各种问题的文本摘要。使用这个摘要,我们然后可以提示一个 LLM-使用梯度和当前提示作为输入-以减少这些问题的方式编辑现有提示。APO反复应用这些步骤以找到最佳提示。
见下文对该框架的描述。
2.3.2.2 梯度和编辑
APO创建一个递归反馈循环,通过以下方式优化提示:
i)收集当前提示对训练数据所造成的错误,
ii)通过自然语言梯度总结这些错误,
iii)使用梯度生成多个修改后的提示版本,
四选择编辑过的最佳提示
并五)重复这个过程几次。
为了生成“梯度”, 展示了训练数据集中当前提示所导致的错误的LLM示例,并要求模型提出这些错误的原因。然后,使用这些原因作为编辑提示的上下文;见下文。
使用自然语言梯度编辑提示
在每次迭代中,我们会对当前的提示生成几次编辑-编辑数量是优化过程的一个超参数。. 此外,我们可以通过显式地为每个提示生成多个措辞来扩展搜索空间,这是一种被称为蒙特卡洛抽样;
见下文。
在APO中的蒙特卡罗抽样
2.3.2.3 搜索和选择
通过生成每个提示的多个变体,我们可以通过以下方式搜索最佳提示:波束搜索.
换句话说,我们在每次迭代时都会为最佳提示保留几个候选人,建议N编辑每个提示,然后选择最佳选项B根据提示进行编辑通过测量培训集的绩效-保留在下一次迭代中;见下文。
使用光束搜索来迭代选择最佳提示
正如我们可能预料的那样,如果我们在整个培训数据集中不断评估所有提示候选人,波束搜索可能会变得昂贵。
但高级的想法是我们可以使用统计数据来选择哪些提示值得全面评估,而不是仅仅天真地评估整个培训数据集中的每一个提示。
2.3.2.4 这个效果好吗
对APO在四种不同的基于文本的分类任务上提示GPT-3.5的能力进行了评估,这些任务包括越狱检测、仇恨言论检测、假新闻检测和讽刺检测。
为什么只考虑分类问题?评估APO的分类任务的明确选择可能是由于为这些问题定义目标函数的简单性-我们可以根据分类准确性来评估每个提示。. 对于复杂或开放式任务,定义目标函数并不简单,这使得APO等技术的应用不那么直接。
如上图所示,在所有数据集中,APO的表现优于其他最先进的提示优化算法。
值得注意的是,APE-的性能上图中的蒙特卡罗(MC)技术-比APO差,表明我们从添加一个更具体的方向中获益-通过自然语言梯度-进入快速优化过程。
尽管APO需要 LLM API 调用,但APO 可以将初始提示的性能提高多达 31%,超过了其他技术的改进。
2.3.3 GRIPS
无梯度教学提示搜索(GRIPS), 这是一种通过迭代、本地、基于编辑和无梯度搜索改进教学提示的自动化过程。
与其使用一个 LLM 编辑提示作为提示优化过程的一部分,可以使用启发式策略生成新的提示变体以供考虑。GRIPS,这是一种无梯度的方法,通过迭代应用一组固定的启发式编辑操作来搜索更好的提示。
与我们迄今所见的方法一样,GrIPS以人为书写的提示符为输入,返回经过改进的编辑的提示符作为输出。
2.3.3.1 启发式提示搜索。
GRIPS既可以应用于基于指令的提示,也可以应用于包含上下文示例(如下所示)的提示,但其重点仅在于改进指令-我们不尝试优化GrIPS中的示例选择。
为了搜索可能提示符的空间,我们从一个初始提示符开始,并反复对该提示符执行一系列编辑操作。然后,我们可以在一组培训示例中测试编辑后的提示的性能⁹,使我们能够确定哪些经过编辑的提示是最好的。
这个过程与我们迄今所见的技术有些相似,但我们在搜索过程中对提示符应用一组启发式编辑,而不是依赖于一个 LLM 生成编辑后的提示符版本。此技术可用于任意类型的LLMs,包括通过API公开的LLMs。
2.3.3.2 搜索的详细信息
GrIPS的优化框架如下图所示。
以一个基本指令开始搜索过程,这个指令是由人写的。在每次迭代中,我们选择一定数量的编辑操作来应用于这个提示符,产生几个新的提示符候选。然后对这些候选人进行评分,以便确定最优秀的候选人。如果最佳候选者的分数超过当前基准指令的分数,那么我们使用最佳候选者作为前进的基础指令。否则,我们保持当前的基本指令并重复。这是一个贪婪的搜索过程,当基础指令的分数在多次迭代中没有提高时,这个过程就会终止。
通过在每次迭代中保持一组多个指令,我们可以很容易地将这种贪婪的搜索过程调整为执行波束搜索。但是,这种修改增加了每个步骤需要评估的候选提示的数量,从而增加了搜索过程的成本。
2.3.3.3 编辑的类型
在GRIPS中,我们总是在短语级别应用编辑,使我们能够在保持提示结构的同时进行有意义的修改。要将提示解构为短语,我们可以使用成分分析器. 然后,在提示中的短语上考虑四种不同类型的编辑操作:
- 删除:从指令中删除某个短语的所有出现,并存储已删除的短语,以便在添加操作中使用。
- 交换:给出两个短语,用第二个短语替换指令中第一个短语的所有出现,反之亦然。
- 意译:将指令中某一短语的所有出现都替换为解释后的版本¹⁰这句话。
- 添加:取样先前迭代中删除的短语,然后在随机短语边界处将其添加回指令中。
2.3.3.4 实际使用
GRIPS主要对来自以下的二进制分类任务进行评估:自然指令数据集.
我们看到GrIPS发现的提示往往会提高准确性,但并不总是连贯一致。优化后的提示包含语义上尴尬和令人困惑的措辞。
尽管如此,我们看到在使用GrIPS优化基础指令可持续地提高各种LLMs的准确性多达2-10%。
此外,手动重写提示-甚至在某些情况下基于梯度的提示调优-往往比GrIPS表现得更好,因为GrIPS被发现最适合优化任务特定(而非通用)指令;见下文。
2.3.4 作为优化器的大型语言模型
与其正式定义优化问题并通过编程求解器推导更新步骤,我们用自然语言描述优化问题,然后指示LLM基于问题描述和先前找到的解决方案迭代生成新的解决方案。
当前最流行和广泛使用的提示优化技术之一是提示优化(OPRO)。然而,OPRO所能做的不仅仅是优化提示。它是一种通用的优化算法,其运作方式为:
- 用自然语言描述优化任务。
- 以优化器LLM示例展示优化任务的先前解决方案及其目标值。
- 请求优化器LLM推断问题的新/更好的解决方案。
- 通过评估器 LLM 测试推断的解决方案。
通过重复上面的步骤,我们创建了一个极其灵活的、无梯度的优化算法。
与其正式地说明我们要用数学来解决的问题,我们可以用自然语言来解释问题。
这样的描述对于使用OPRO执行优化就足够了,这使得算法具有广泛的适用性和易于扩展到新的任务。
在正确的采样策略下,这种优化算法的轨迹相对稳定,这再次表明,LLMs 能够从过去的解决方案中学习,提出新的和更好的解决方案;见上文。虽然OPRO可以应用于许多问题,但在[3]该算法对于自动提示优化特别有用。首先,我们将了解OPRO的工作原理,然后我们将探索如何使用它来优化提示。
2.3.4.1 OPRO框架
上文概述了监督厅采取的高级别步骤。
在优化过程的每个步骤中,OPRO基于元提示生成新的解决方案,元提示包含对优化问题和已提出的先前解决方案的文本描述。在给定元提示符之后,我们会同时生成多个新的解决方案¹¹. 通过在每个步骤生成几个候选解决方案,我们可以确保一个(相对)稳定的优化轨迹,因为 LLM 获得了几次生成可行解决方案的机会。
从这里,我们评估每个新的解决方案的基础上的目标函数(例如,准确性),并添加最佳的解决方案的元提示下一个优化步骤。这样,我们就选择了最佳的解决方案,传递给下一次迭代优化过程。我们的目标是找到一个解决方案,优化的目标函数,和优化进程终止一旦LLM是无法提出新的解决方案,产生改进的目标。
2.3.4.2 关键部件或ORPO
从这个框架中我们可以看到,OPRO在其优化过程中有两个主要组件(如上图所示):
- 优化器:将元提示作为输入,并提出新的解决方案。
- 评估人员:以解为输入并计算目标值。
优化器始终以LLM的形式实现。要成功应用OPRO,我们必须选择一个足够强大的LLM作为优化器,因为从元提示中提供的上下文推导出最佳解决方案需要复杂的推理能力。另外,我们看到在[1]较大的LLMs往往更擅长这项任务。
根据所要解决的问题,评估器也可以实现为一个LLM,但优化器和评估器不需要是相同的LLM. 例如,线性回归问题有一个简单的评估器(即,我们可以直接从解决方案中计算目标值),但提示优化问题需要我们使用一个评估器 LLM 来衡量每个提示的输出质量。
“虽然传统的优化通常需要相当大的训练集,但我们的实验表明,少量或少量的训练样本就足够了。”
使用OPRO进行优化需要训练和测试数据。在优化过程中,我们使用训练数据集来计算目标值,而测试集则用于评估优化过程结束后生成的解决方案的最终性能。与大多数优化算法相比,OPRO只需要很少的训练数据。
2.3.4.3 关于元提示符的更多信息
元提示提供了优化器 LLM 需要的所有必要上下文,以提出一个更好的解决方案来解决正在解决的问题。元提示有两个主要组件:
- 对优化问题的文本描述。
- 先前的解决方案及其目标值(即优化轨迹)。
优化轨迹的排序使最佳解决方案出现在元提示的末尾。除了这些核心信息外,我们还从培训数据集中随机选择示例来演示预期的输出格式,以及创建新解决方案时应遵循的一般指令(例如,“简洁”或“生成一个能最大化准确性的新指令”)。用于提示优化任务的元提示的示例如下所示。
2.3.4.4 OPRO的表现。
OPRO在两个方面进行评估GSM8K和BIG-Bench-Hard.
在这些数据集上,OPRO发现提示的性能分别优于人工编写提示的8%和50%。
与以前的方法(如APE)相比,OPRO被证明能够找到更复杂的指令,从而实现更好的性能;见下文。有趣的是,发现的指令风格往往因使用的优化器 LLM 而变化很大。
2.3.4.5 高级推理系统(o1)
如前所述,从优化轨迹推断出新的解决方案是一个复杂的推理问题。
较大的LLMs更擅长解决这个任务,这表明我们得益于具有更好推理能力的更强大的优化器 LLM。
此外,快速优化是一次性成本. 我们对提示进行一次优化,但优化后的提示通常会在下游应用程序中使用更长时间。因此,使用更昂贵的优化器 LLM 的成本会随着其产生的提示的生命周期而摊销。
最近提出的基于LLM的推理系统,如OpenAI的o1,为迅速优化打开了新的可能性。
这些系统被训练成遵循一个广泛的推理过程,通过这个过程,模型可以动态决定是否需要更多的计算来解决复杂问题;参见在这里了解详情。
在某些情况下,这种高级推理策略可能代价昂贵;例如,o1可能会“思考”超过一分钟在响应提示之前。然而,对于复杂的推理问题,在推理时使用额外计算可能是值得的。在自动提示优化的情况下,优化器 LLM 响应的延迟和成本远不如生成提示的质量重要,这使得这成为这些高级推理系统的主要应用。
通过进化优化提示
到目前为止,我们看到的提示优化策略从一个提示(或一组提示)开始,并迭代地由人类编写:
- 生成提示的变体。
- 从这些变体中选择性能最佳的提示。
在某些方面,这个优化过程可以被视为一个EA。随着时间的推移,提示数量会保持、变异和选择。我们使用的群体大小为1(除非正在使用波束搜索),并且通过提示一个 LLM(或使用启发式、基于编辑的策略)来修改当前提示来突变群体。受这项工作的启发,研究人员最近探索了更明确的策略,以应用EA进行即时优化。我们将看到,这些算法与我们迄今为止看到的算法没有太大的区别!
2.3.4.6 基因提示搜索(GPS)
(如上图所示)采用遗传算法来自动发现高性能提示。
首先,用集合实例化算法。或人口手写的提示。然后,我们可以通过以下操作来变异这些提示:
- 回译:将提示翻译成其他11种语言之一,然后翻译回英语。
- 完形填空¹²:在提示中掩盖多个令牌,并使用预先训练的语言模型(例如,T5 (Text to Text Transformers)来填充它们,从而生成一个新的提示。
- 句子延续提示一个 LLM 写两个意思相同的句子,并提供当前提示作为第一句。
这些策略中的每一种都可以突变当前提示的数量以生成新的提示变体。
从这里,我们可以使用延迟验证集对生成的提示进行打分,以确定哪些提示应该在下一次迭代中保留。或一代进化论。这种算法优于人工提示工程,甚至在某些情况下可以优于提示调优。
2.3.4.7 EvoPrompt
再次利用EA的概念,创建一个性能良好且快速融合的提示优化器。
EvoPrompt从手动编写的提示符集合开始,使用两个主要的进化运算符:变异和交叉生成新的提示。在每一代中,通过在持久验证集上衡量其性能,选择并维护最佳提示,以便进一步改进。
根据定义,进化运算符将序列作为输入并输出修改后的序列。传统上,运算符独立地应用于序列的每个元素—我们更新每个元素,但不知道其周围的元素是否已被更改。对于提示优化,这种方法是有问题的,因为提示中的所有令牌都是相互关联的。
为了解决这个问题,EvoPrompt通过提示实现演化操作符,并依赖于LLM的专业知识以逻辑方式演化提示。
上图示出了用于通过遗传算法优化提示的交叉和突变提示的示例。
然而, EvoPrompt 不仅支持遗传算法,还支持多种EA!例如,下面我们看到一组提示,可用于实现提示优化的差分演化策略。EvoPrompt框架具有足够的灵活性,可以以即插即用的方式替代不同的EA。
EvoPrompt在几个任务上使用封闭和开源的LLMs(例如Alpaca和GPT-3.5)进行了测试,发现其性能优于APE等算法和APO. EvoPrompt的差分进化变种在大多数情况下优于遗传算法变种;
见下文。
2.3.4.8 Promptbreeder 快速繁殖者
是在EvoPrompt之后不久提出的。这两种技术背后的思想是相似的:
- 它们都以人类书面提示的数量开始。
- 它们都通过向LLM发送提示来实现突变和交叉等进化运算符。
- 它们都通过测量验证集的性能来执行选择。
这些技术的主要区别在于 Promptbreeder 优化的不仅仅是任务提示-用于实现进化运算符的提示也进行了优化。! 这样的方法允许我们在提示优化算法本身中引入自我改进机制。
“也就是说,Promptbreeder不仅仅是在改进任务提示,它还在改进那些改进这些任务提示的突变提示。”
人们发现,快速繁殖器的表现优于多种强大的提示策略(例如,思想链和计划和解决提示)的推理基准。而其他提示优化算法在将优化过程扩展到更大的迭代次数时通常会看到回报递减和性能饱和[1]Promptbreeder会随着时间的推移动态调整优化过程,从而发现更能解决困难任务的复杂提示。
4 參考文献
[1]周永超,等。“大型语言模型是人类级别的提示工程师。”ArXiv预印本 (2022).
[2]普里赞特里德等人。”自动提示优化,带有”梯度下降”和光束搜索功能。”ArXiv预印本 (2023).
[3]杨成润等,“大型语言模型作为优化器”。arXiv 抗体/2309.03409 (2023).
[4]”Prefix-tuning: Optimizing continuous prompts for generation.”ArXiv预印本 (2021).
[5]莱斯特,布莱恩,拉米·阿尔福和诺亚·康斯坦特。“尺度的力量,用于参数高效的即时调优。”ArXiv预印本 (2021).
[6]陈立昌等。”Instructzero:黑盒型大型语言模型的高效指令优化”ArXiv预印本 (2023).
[7]霍诺维奇,奥尔等。“教学归纳:从少数例子到自然语言任务描述。”ArXiv预印本 (2022).
[8]王中等,“自我指导:将语言模型与自生成指令相统一”。ArXiv预印本 (2022).
[9]许,灿,等。Wizardlm:使大型语言模型能够遵循复杂的指令。ArXiv预印本 (2023).
[10]蒋正保等。“我们如何知道语言模型知道什么?”计算语言学协会期刊 8 (2020): 423-438.
[11]Shin, Taylor, 等,“自动提示:使用自动生成的提示从语言模型中获取知识。”ArXiv预印本 (2020).
[12]邓明凯,等,“RLprompt:用强化学习优化离散文本提示”。ArXiv预印本 (2022).
[13]Zhang, Tianjun, 等. Tempera:通过强化学习进行考试时间提示。ArXiv预印本 (2022).
[14]普拉萨德、阿奇基等。”Grips:无梯度、基于编辑的指令搜索,用于提示大型语言模型。”ArXiv预印本 (2022).
[15]Xu, Hanwei, 等,“GPS:遗传提示搜索,实现高效的少拍学习”。ArXiv预印本 (2022).
[16]郭庆炎,等。“将大型语言模型与进化算法相连接,会产生强大的提示优化器。”ArXiv预印本 (2023).
[17]费尔南多、克里桑塔等人。“快速繁殖者:通过快速进化实现自我参照的自我完善。”ArXiv预印本 (2023).
[18]贾加·雷迪,医学博士,纳格什·库马尔。“进化算法、群体智能方法及其在水资源工程中的应用:最新综述。”h2oj 3.1 (2020): 135-188.
[19]大卫·科恩和迈克尔·洛恩斯,《进化算法》。ArXiv预印本 (2018).
[20]Ai, Hua, et al. “基于改进遗传算法的计算机通信网络拓扑优化。”智能系统学报 31.1 (2022): 651-659.
[21]扎姆菲雷斯佩雷拉,J. D.等。“为什么约翰尼不能提示:非AI专家如何尝试(并失败)设计LLM提示。”2023年CHI计算系统人因学会议论文集. 2023.
[22]Jiang, Ellen, 等. “用大型语言模型实现快速原型化”。2022年CHI计算系统人因学大会扩展摘要. 2022.
[23]Vatsal, Shubham 和 Harsh Dubey。用于不同 nlp 任务的大型语言模型中快速工程方法的调查。ArXiv预印本 (2024).
[24]Sahoo, Pranab, 等。”大型语言模型中即时工程的系统调查:技术和应用。”ArXiv预印本 (2024).
[25]Reynolds,Laria和Kyle McDonell,“大型语言模型的快速编程:超越少拍范式”。2021年CHI计算系统中人为因素会议的扩展摘要. 2021.
[26]多尔,本杰明和弗兰克·诺伊曼。关于离散优化演化算法理论最新进展的调查。ACM进化学习与优化学术期刊 1.4 (2021): 1-43.
[27]雷曼、乔尔等。“通过大型模型的进化。”进化机器学习手册.新加坡:《自然》新加坡,2023.331-366.
[28]迈耶森,艾略特,等,“语言模型交叉:通过少拍提示的变异”。ArXiv预印本 (2023).
[29]Chen, Yutian, 等. “致力于学习带有变换器的通用超参数优化器”。神经信息处理系统研究进展 35 (2022): 32053-32068.
[30]陈、安吉丽卡、大卫·多汉和大卫·苏。“EvoPrompting:代码级神经架构搜索的语言模型。”神经信息处理系统研究进展 36 (2024).
[31]Khattab,Omar,等. “Dspy:将声明性语言模型调用汇编到自我改进的管道中。”ArXiv预印本 (2023).
RA/SD 衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/7353