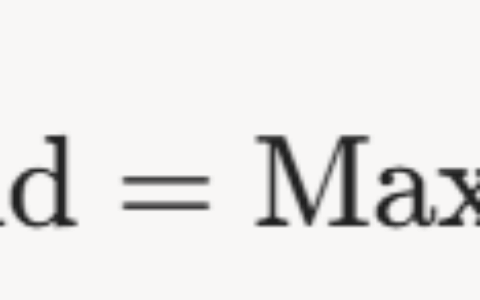A/B测试是最常用的用户体验研究方法。通过比较控制(A)版本和变体(B)版本,它根据您的关键指标来衡量哪一个版本最成功。
对于机器学习,A/B测试弥合了理论模型性能指标(如准确性、精度、召回或F1得分)与现实世界影响之间的差距。通过这种方式,数据科学家可以做出数据驱动的决策,并降低部署表现不佳模型的风险。
虽然流量分割经常用于A/B测试,但它并不是实时ML模型测试的正确方法。为了进行有效的比较,相同的数据点(例如,相同的客户用于个性化优惠,相同的类别用于需求预测)应该始终得到相同的模型预测。这一要求使得随机流量分割不适用于实时ML模型的测试。
为什么
例如,如果你在电子商务网站上实现交叉销售算法,以衡量你的模型有多大的销售额,那么你必须始终如一地向每个客户展示来自同一个模型的建议。这确保您可以根据特定型号版本公平地评估每个客户的销售额是否增加,而不是引入多个型号版本的可变性。
另一个例子是,如果要实现需求预测模型来预测库存需求,则相同的产品类别(例如日记、水果)必须始终从相同的模型版本中接收预测。这种一致性对于准确评估模型对预测精度的影响非常重要。通过确保每个类别只从一个模型版本中看到预测,可以消除库存调整中的随机变化。这样,预测精度和运行效率的任何变化都可以直接与被测试的具体模型版本相关联。
插曲:A/B测试 vs Canary部署
在软件部署领域,金丝雀部署和A/B测试用于不同的目的。Canary部署通过向一小部分用户推出新更改来解决质量保证问题,从而能够在不影响更广泛用户基础的情况下及早发现问题。而A/B测试是关于版本比较的。在这里,对不同版本进行跨用户组的测试,以评估哪一个版本的性能或参与度更好。虽然金丝雀部署强调通过增量发布进行质量控制,A/B测试通过比较多个版本来关注功能的有效性。两种策略都是有价值的,但每种策略都是根据测试和部署的具体目标来应用的。在本文中,我们将重点关注A/B测试。
如何使用Databricks无服务器端点做到这一点

下面介绍使用Databricks无服务器端点进行A/B测试的示例。此服务已具有流量分割选项但我们不会使用它。我们将使用 MLflow pyfunc创建一个包装模型类,以完全控制A/B测试配置设置。
- 我们首先加载和准备训练和测试数据集。在本例中,我们将用不同的参数设置训练同一个模型。配置设置包括模型参数和从Databricks表中加载的数据集。
# Load the NYC taxi trips dataset
nyc_taxi_df = spark.table("samples.nyctaxi.trips")
nyc_taxi_pd = nyc_taxi_df.toPandas()
# Define feature columns and target column
feature_columns = ["trip_distance", "pickup_zip", "dropoff_zip"]
target_column = "fare_amount"
nyc_taxi_pd = nyc_taxi_pd.dropna(subset=feature_columns + [target_column])
train_df = nyc_taxi_pd.sample(frac=0.8, random_state=123)
test_df = nyc_taxi_pd.drop(train_df.index)
X_train = train_df[feature_columns]
y_train = train_df[target_column]
X_test = test_df[feature_columns]
y_test = test_df[target_column]
catalog_name = "mlops_dev"
schema_name = "nyc_taxi_fare"
model_name = f"{catalog_name}.{schema_name}.nyc_taxi_fare_model"2. 两者模式A和模式B使用各自的参数分别进行训练。每个模型的性能指标(如MSE和R2分数)都记录在 MLflow中。我们在ML flow Model Registry中注册这两个模型,为它们分配别名model_A和model_B,以简化A/B测试包装中的引用。
# Model A parameters
params_a = {"n_estimators": 100, "max_depth": 10, "random_state": 42}
preprocessor = ColumnTransformer(
transformers=[("cat", OneHotEncoder(handle_unknown="ignore"), ["pickup_zip", "dropoff_zip"])],
remainder="passthrough"
)
# Create a pipeline with preprocessing and model
pipeline_a = Pipeline(steps=[("preprocessor", preprocessor), ("regressor", RandomForestRegressor(**params_a))])
# Log Model A to MLflow
with mlflow.start_run(run_name="Model_A") as run_a:
# Train Model A
pipeline_a.fit(X_train, y_train)
# Evaluate Model A
y_pred_a = pipeline_a.predict(X_test)
mse_a = mean_squared_error(y_test, y_pred_a)
mlflow.log_params(params_a)
mlflow.log_metric("mse", mse_a)
signature = infer_signature(model_input=X_train, model_output=y_pred_a)
mlflow.sklearn.log_model(sk_model=pipeline_a, artifact_path=model_name, signature=signature)
model_a_uri = f"runs:/{run_a.info.run_id}/sklearn-pipeline-model"
model_version = mlflow.register_model(
model_uri=model_a_uri, name=model_name
)
# Assign alias for Model A
model_version_alias = "model_A"
client.set_registered_model_alias(model_name, model_version_alias, f"{model_version.version}")
model_uri = f"models:/{model_name}@{model_version_alias}"
model_A = mlflow.sklearn.load_model(model_uri)# Model B parameters (different from Model A for testing purposes)
params_b = {"n_estimators": 200, "max_depth": 15, "random_state": 42}
# Create a pipeline for Model B
pipeline_b = Pipeline(steps=[("preprocessor", preprocessor), ("regressor", RandomForestRegressor(**params_b))])
# Log Model B to MLflow
with mlflow.start_run(run_name="Model_B") as run_b:
# Train Model B
pipeline_b.fit(X_train, y_train)
# Evaluate Model B
y_pred_b = pipeline_b.predict(X_test)
mse_b = mean_squared_error(y_test, y_pred_b)
mlflow.log_params(params_b)
mlflow.log_metric("mse", mse_b)
signature = infer_signature(model_input=X_train, model_output=y_pred_b)
mlflow.sklearn.log_model(sk_model=pipeline_b, artifact_path=model_name, signature=signature)
model_b_uri = f"runs:/{run_b.info.run_id}/sklearn-pipeline-model"
model_version = mlflow.register_model(
model_uri=model_b_uri, name=model_name
)
# Assign alias for Model B
model_version_alias = "model_B"
client.set_registered_model_alias(model_name, model_version_alias, f"{model_version.version}")
model_uri = f"models:/{model_name}@{model_version_alias}"
model_B = mlflow.sklearn.load_model(model_uri)3. 创建了一个自定义 PythonModel 包装类(命名为 ModelWrapper),它将model_A和model_B作为输入。在这个包装盒中,我们定义了A/B测试逻辑:a散列函数用于决定每个数据点接收哪个模型版本。例如,如果客户ID的哈希值是偶数,则model_A处理预测;如果是奇数,则模型_B处理。这确保每个客户或类别都能一致地看到来自同一模型版本的预测,从而避免随机流量分裂。
model_a = mlflow.sklearn.load_model(model_a_uri)
model_b = mlflow.sklearn.load_model(model_b_uri)
class ABTestModelWrapper(mlflow.pyfunc.PythonModel):
def __init__(self, model_a, model_b):
# Load the models A and B from MLflow
self.model_a = model_a
self.model_b = model_b
def predict(self, context, model_input):
# Use hash function on 'pickup_location_id' to consistently assign models
hashed_id = int(hashlib.md5(str(model_input["pickup_location_id"].values[0]).encode()).hexdigest(), 16)
if hashed_id % 2 == 0:
return {"Prediction": self.model_a.predict(model_input), "model": "Model A"}
else:
return {"Prediction": self.model_b.predict(model_input), "model": "Model B"}
model_name = f"{catalog_name}.{schema_name}.nyc_taxi_fare_model_ab_test"
# Log the wrapper model in MLflow
with mlflow.start_run(run_name="AB_Test_Model") as run:
mlflow.pyfunc.log_model(
artifact_path="ab_test_model",
python_model=ABTestModelWrapper(model_a, model_b),
)
ab_test_model_uri = f"runs:/{run.info.run_id}/ab_test_model"
model_version_ab = mlflow.register_model(
model_uri=ab_test_model_uri,
name=model_name
)Pyfunc包装器模型被记录为 MLflow 模型,它支持版本跟踪和服务端点部署。
4.部署服务端点:注册 MLflow 包装机模型后,我们建立了一个服务端点在Databricks上进行实时A/B测试。此端点被配置为将传入请求引导到Pyfunc包装器模型,该模型应用A/B测试逻辑。
workspace = WorkspaceClient()
workspace.serving_endpoints.create(
name="nyc-taxi-fare-serving-ab-test",
config=EndpointCoreConfigInput(
served_entities=[
ServedEntityInput(
entity_name=f"{catalog_name}.{schema_name}.nyc_taxi_fare_model",
scale_to_zero_enabled=True,
workload_size="Small",
entity_version=model_version_ab,
)
]
),
)在这个示例中,我们展示了如何使用Databricks无服务器端点为机器学习模型设置A/B测试。通过使用 MLflow Pyfunc创建自定义包装模型,我们可以根据特定属性来分配模型版本,而不是依赖随机流量划分。
通过这种方式,我们可以精确控制模型比较,确保每个用户或数据段从相同的模型版本接收一致的预测。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/6998