
第八章 RAG的各种增强和衍生发展
8.1 GraphRAG
Graph RAG(图形检索增强生成)是一种先进的方法,它将基于图形的数据结构与检索增强生成技术相结合,以增强语言模型的功能。Graph RAG 旨在针对私有文本语料库进行问答,该语料库的扩展性既可以满足用户问题的普遍性,也可以满足要索引的源文本的数量。Graph RAG 使用 LLM 构建基于图形的文本索引,然后使用它来回答全局查询。该过程分为两个阶段:
- 从源文档中获取实体知识图谱。
- 为所有密切相关的实体群体预先生成社区摘要。
给定一个问题,每个社区摘要用于生成部分响应,然后所有部分响应再次汇总到对用户的最终响应中。

LLM 使用 GPT-4 Turbo 从私有数据集构建的知识图谱。
对于 100 万个标记范围内的数据集上的一类全局意义建构问题, Graph RAG 在生成的答案的全面性和多样性方面都比简单的 RAG 基线有了显著的改进。
什么是 Graph RAG?
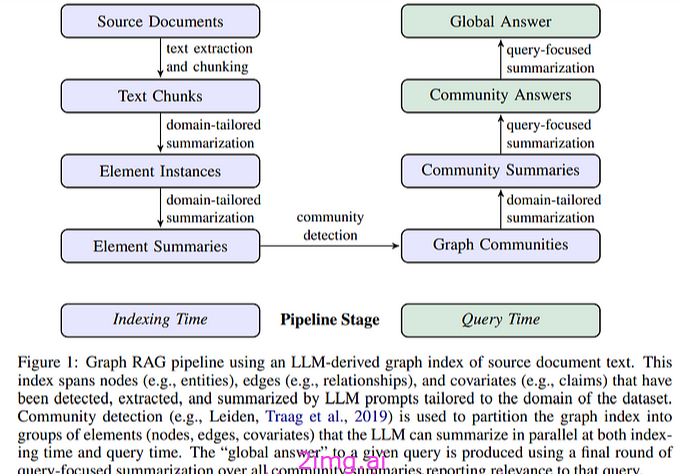
Graph RAG 是一个两步过程,我们通过索引私有数据来构建系统,以创建LLM 派生的知识图谱。这些图谱作为 LLM 内存表示,随后可供后续步骤使用,以进行更好的检索。
系统的第二部分是 LLM 编排,它利用这些预先构建的索引来创建更好的 RAG 管道,可以一次了解整个数据集。
Graph RAG 主要实现了两件事:
- 增强搜索相关性。
- 实现可能需要非常大背景的新场景。例如,查找数据中的趋势、汇总等。
它是怎样做到的?
源文档 → 文本块
- 粒度:来自源文档的输入文本被分成块。
- 权衡:较长的块需要较少的 LLM 调用,但可能会由于较长的上下文窗口而降低召回率。
- 示例:在 HotPotQA 数据集上,600 个标记的块大小提取的实体引用几乎是 2400 个标记的块大小的两倍。
文本块 → 元素实例
- 目标:从文本块中识别并提取图形节点和边。
- 流程:使用 LLM 提示识别实体和关系,输出分隔元组。
- 定制:使用与特定领域相关的少量示例来定制提示。
- 效率:多轮“收集”确保在不影响块大小的情况下检测到更多实体。
元素实例 → 元素摘要
- 总结:LLM 从文本中抽象并总结实体、关系和主张。
- 重复处理:尽管实体引用中可能存在不一致,但由于检测密切相关的实体及其总结,该方法具有弹性。
元素摘要 → 图社区
- 图形建模:创建一个无向加权图,其中节点是实体,边是关系。
- 社区检测:使用莱顿算法将图表划分为分层社区,实现有效的全局汇总。
图表社区 → 社区摘要
- 摘要创建:为每个社区生成类似报告的摘要。
- 实用性:摘要有助于理解数据集的全局结构和语义,有助于回答全局查询。
社区摘要 → 社区答案 → 全局答案
- 查询处理:使用社区摘要来生成答案。
- 中级答案:摘要被分成几块,LLM 生成具有有用性分数的答案。
- 最终答案:将得分最高的中间答案组合成最终的全局答案。
通过使用 LLM 生成的知识图谱,GraphRAG 极大地改进了 RAG 的“检索”部分,用更高相关性的内容填充上下文窗口,从而得到更好的答案并捕获证据来源。
能够信任和验证 LLM 生成的结果始终很重要。我们关心的是结果是否正确、连贯,并准确代表源材料中的内容。GraphRAG 在生成每个响应时提供出处或来源基础信息。它表明答案是基于数据集的。随时提供每个断言的引用来源还使人类用户能够快速准确地直接对照原始源材料审核 LLM 的输出。
8.2 RIG
谷歌的研究人员一直在探索将 LLM 与Data Commons集成的方法。Data Commons 是一个庞大的开源公共统计资料库,包含来自联合国、疾病控制和预防中心和全球人口普查局等可信组织的统计数据。Data Commons 充当统一的知识图谱,组织和标准化来自数百个来源的数据,使其可供普遍访问和使用。
通过提供可靠、全面的统计信息来源,Data Commons 使 LLM 能够根据事实数据做出回应,从而降低生成不准确或误导性信息的风险。
RIG 是一种工具启发式(~ 函数调用)方法,旨在通过将 LLM 与 Data Commons(来自可信组织的庞大的开源公共统计数据存储库)集成来提高 LLM 的事实准确性。RIG 背后的核心思想是微调 LLM,以生成自然语言 Data Commons 查询以及生成的统计值。在下图中,您可以看到 LLM 通过“DC(question)”格式进行函数调用。
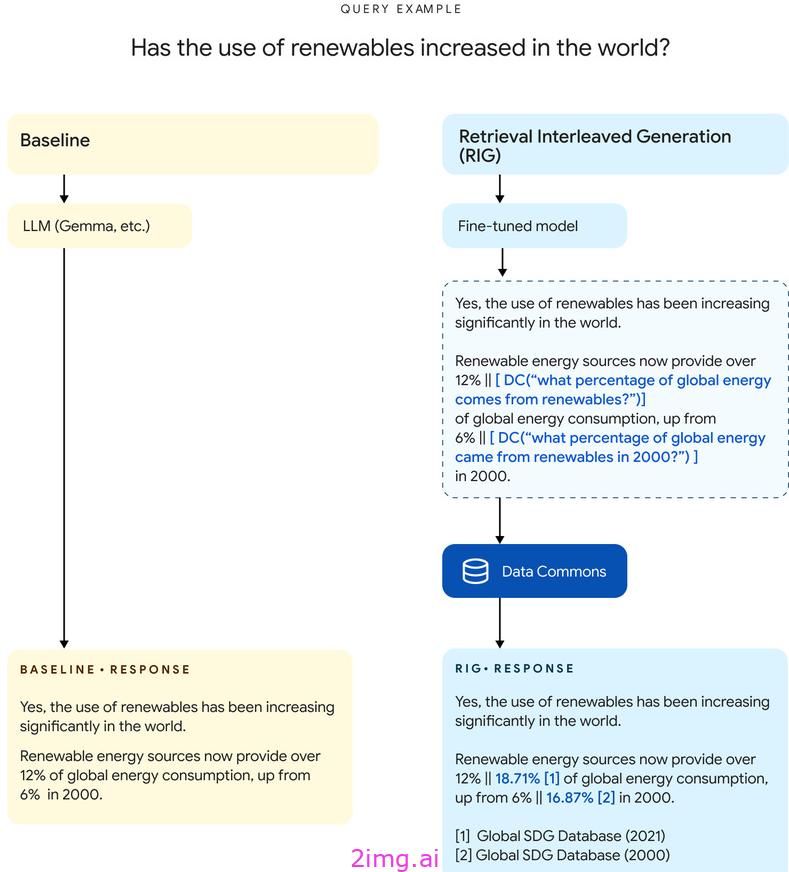
使用统计数据生成响应的基线方法和 RIG 方法的比较。
RIG 管道由三个主要组件组成:
- 模型微调:LLM 在指令响应数据集上进行微调
- 以生成自然语言数据共享查询以及原始 LLM 生成的统计值 (Generated-SV)。
- 自然语言查询描述 Generated-SV,并用于从数据共享 (Ground-Truth-SV) 中检索相应的统计值。
8.3 StructRAG
中国科学院和阿里巴巴集团的研究人员提出了一个名为 StructRAG 的新框架。该框架引入了一种混合信息结构化机制,可根据当前任务的具体要求以最合适的格式构建和利用结构化知识。通过模仿类似人类的思维过程,StructRAG 旨在提高 LLM 在知识密集型推理任务上的表现。
这里深入研究 StructRAG 框架的细节,探索其关键组件以及它们如何协同工作以提高 RAG 性能。讨论 StructRAG 中的关键模块混合结构路由器的训练过程,并展示实验结果以证明该方法的有效性。
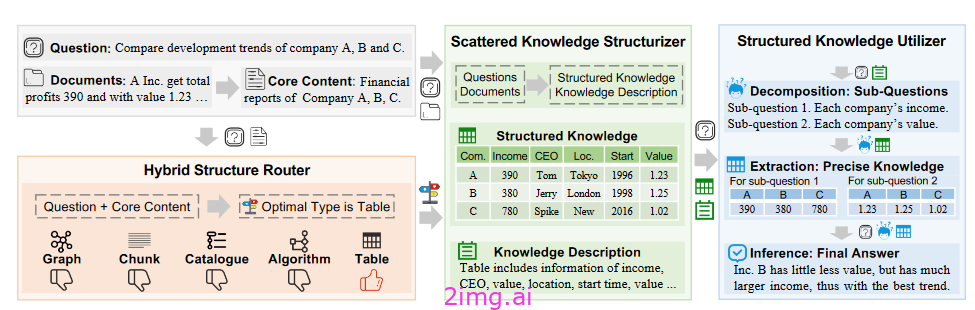
StructRAG 框架概述
8.3.1 框架
StructRAG 框架由三个主要模块组成,它们依次工作,以确定最佳结构类型、构建结构化知识并利用该知识进行准确推理。让我们仔细看看每个模块。
- 混合结构路由器:混合结构路由器是 StructRAG 的核心组件,负责确定给定任务最合适的结构类型。它将问题和文档的核心内容作为输入,并输出最佳结构类型。路由器考虑五种候选结构类型:表格、图形、算法、目录和块,每种类型都适用于不同类型的知识密集型任务。
选择最佳结构类型至关重要,因为它直接影响后续模块的有效性。为了训练路由器,作者提出了一种基于决策变压器和偏好优化 (DPO) 算法的新方法,该方法遵循强化学习原则,无需额外的奖励模型。路由器的训练数据是通过合成-模拟-判断管道生成的,该管道为各种任务和结构类型创建高质量的合成偏好对。
- 分散知识结构化器:一旦确定了最佳结构类型,分散知识结构化器就会发挥作用。该模块负责提取分散在原始文档中的相关信息,并将其重构为所选格式的结构化知识。结构化器利用 LLM 强大的理解和生成功能来执行这一复杂任务。
结构化器将问题、选定的结构类型和每个原始文档作为输入。然后,它从文档中提取结构化知识并生成结构化知识的描述。输出的结构化知识被收集并组合起来,形成给定任务的整体结构化知识。
- 结构化知识利用器:StructRAG 框架中的最后一个模块是结构化知识利用器,它根据构建的结构化知识进行推理以回答问题。该模块旨在处理可能妨碍直接识别和利用相关信息的复杂组合问题。
利用器采用基于LLM的方法进行问题分解、精确知识提取和最终答案推理。它首先根据结构化知识的整体描述将原始问题分解为若干个更简单的子问题。然后从结构化知识中为每个子问题提取精确知识。最后,利用器整合所有子问题及其对应的精确知识以生成最终答案。
8.3.2 训练混合结构路由器
混合结构路由器的性能对于 StructRAG 框架的整体有效性至关重要。为了训练路由器,作者提出了一种新方法,该方法结合了用于生成训练数据的综合-模拟-判断流水线和用于偏好训练的 DPO 算法。

训练数据构建示意图。
综合-模拟-判断流程包括三个步骤:
- 任务合成:给定一组手动收集的涵盖可能结构类型的种子任务,LLM 用于通过上下文学习合成新任务。每个合成任务包括一个问题和文档的核心内容。
- 解决方案模拟:对于每个合成任务,LLM 使用不同类型的结构化知识模拟解决任务的过程。此步骤为每个任务生成不同的模拟解决方案。
- 偏好判断:基于 LLM 的判断器会比较每个任务的模拟解决方案,并生成有关结构类型的偏好对。此管道的输出是一组可用于训练路由器的合成偏好对。
然后,生成的偏好对会通过 DPO 算法训练路由器。训练的输入包括问题和文档的核心内容,输出则是最优的结构类型。DPO 算法使路由器能够学习不同任务之间结构类型的偏好,从而增强其选择最合适结构类型的能力。
8.3.3 实验结果
在各种知识密集型推理任务上评估了 StructRAG,并将其性能与几个强大的 RAG 基线进行了比较。实验在 Loong 基准上进行的,其中包括四个任务(Spotlight 定位、比较、聚类和推理链)和四种文档长度设置。
结果表明,StructRAG 在大多数任务和文档长度设置中都优于基线,在整体指标中实现了最先进的性能。
值得注意的是,随着任务复杂度的增加,StructRAG 的性能提升变得更加明显。随着文档长度的增加,解决任务所需的有用信息变得更加分散,使得推理过程更具挑战性。在这些复杂场景中,StructRAG 显示出比基线显著的改进,证实了其在以最合适的格式构建和利用结构化知识方面的有效性。
还进行了消融研究,以验证 StructRAG 框架中每个模块的贡献。结果表明,所有三个模块(混合结构路由器、分散知识结构化器和结构化知识利用器)在整体性能中都发挥着至关重要的作用。删除其中任何一个模块都会导致性能明显下降,其中混合结构路由器的影响最为显著。
此外将 StructRAG 的性能与固定结构类型(例如,仅使用表、图、块、目录或算法)进行了比较,以证明混合信息结构化的重要性。结果证实,使用单一固定结构类型不足以满足多样化任务的需求,而根据任务要求选择最佳结构类型的能力对于实现强大的性能至关重要。
8.4.4 结论
StructRAG 通过引入混合信息结构化机制,为提高 LLM 在知识密集型推理任务上的表现提供了一种有前途的方法。通过模仿类似人类的思维过程,StructRAG 根据手头任务的具体要求,以最合适的格式构建和利用结构化知识。
回顾一下:
- 该框架由三个关键模块组成:确定最佳结构类型的混合结构路由器、将原始文档转换为结构化知识的分散知识结构化器以及执行问题分解和精确知识提取以进行准确答案推理的结构化知识利用器。
- 混合结构路由器的训练是 StructRAG 的一个关键方面。作者提出了一种合成-模拟-判断流程来生成高质量的合成偏好对,并采用 DPO 算法进行偏好训练。这种方法使路由器能够学习不同结构类型对各种任务的偏好,从而增强其选择最合适结构类型的能力。
- 在各种知识密集型推理任务上的实验结果证明了 StructRAG 的有效性,该框架实现了最先进的性能,并且比强大的 RAG 基线有显著的改进。消融研究证实了框架中每个模块的重要性,突出了混合结构路由器在整体性能中的关键作用。
- 此外,StructRAG 与固定结构类型的比较强调了混合信息结构化的重要性。根据任务要求选择最佳结构类型的能力对于在不同任务中实现出色的性能至关重要。
总之,StructRAG 为利用混合结构化知识开发更强大的 RAG 系统提供了一个有希望的方向。通过模仿类似人类的思维过程,该框架根据手头任务的具体要求以最合适的格式构建和利用结构化知识。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/6952