
第七章 RAG框架分析之AnythingLLM
7.1 基础知识
7.1.1 产品概述
AnythingLLM 是最易于使用的一体化AI 应用程序,可以执行 RAG、AI 代理等,且无需担心代码或基础设施问题。
7.1.2 AnythingLLM安装
下载地址:https://useanything.com/download
有Windows的版本,功能会比Linux下的差一点点,不过不影响我们使用和体验。
AnythingLLM对于安装机器的硬件要求非常低。


桌面版本和Docker版本具体的功能差异列表
| Feature | Available on Desktop | Available on Docker |
| Multi-user support | ❌ | ✅ |
| Emeddable chat widgets | ❌ | ✅ |
| One-click install | ✅ | ❌ |
| Private documents | ✅ | ✅ |
| Connect to any vector database | ✅ | ✅ |
| Use any LLM | ✅ | ✅ |
| Built-in embedding provider | ✅ | ✅ |
| Built-in LLM provider | ✅ | ❌ |
| White-labeling | ❌ | ✅ |
| Chat logs | ✅ | ✅ |
| Agent support | ✅ | ✅ |
| Agent skills | ✅ | ✅ |
| Third-party data connectors | ✅ | ✅ |
| Password protection | ❌ | ✅ |
| Invite new users to instance | ❌ | ✅ |
| Text splitting configuration | ✅ | ✅ |
| Whisper model support | ✅ | ✅ |
| Full developer API | ✅ | ✅ |
| User management | ❌ | ✅ |
| Workspace access management | ❌ | ✅ |
| Website scraping | ✅ | ✅ |
docker安装见
7.2 为什么要使用AnythingLLM?
您需要一个零设置、私有、一体化的 AI 应用程序,用于本地 LLM、RAG 和 AI 代理,并且所有这些都集中在一个地方,而无需开发人员进行痛苦的设置。
7.2.1 AnythingLLM 的一些很酷的功能
- 支持多用户实例和权限
- 新的自定义可嵌入式聊天小部件,可以嵌入到你的网站
- 支持多种文件类型(PDF,TXT,DOCX等)
- 通过简单的用户界面管理你的向量数据库中管理文件
- 提供两种聊天模式:对话和查询。对话保留先前的问题和修订。查询是针对文档的简单QA
- 聊天过程中的引用
- 100%适合云部署。
- “自带LLM”模型
- 处理大文件时极有效的节约成本措施。你永远不必为将大型文件或记录输送到聊天机器人中支付费用,比其他的文件聊天机器人解决方案节省90%的费用。
- 提供全面的开发者API用于自定义集成!
同类开源项目大多基于Python语言开发。AnythingLLM采用了Javascript,前端用React,后端用Node,对于全栈工程师非常友好。
- • 前端: React和ViteJS,实现创建和管理大模型用到的知识库
- • 后端: Node.js Express框架,实现向量数据库的管理和所有与大模型的交互
- • 采集器: Node.js Express框架,实现对文档的处理解析
7.2.2 多用户模式
这一点对于企业级应用特别关键,AnythingLLM支持多用户模式,3种角色的权限管理。
系统会默认创建一个管理员(Admin)账号,拥有全部的管理权限。
第二种角色是Manager账号,可管理所有工作区和文档,但是不能管理大模型、嵌入模型和向量数据库。
普通用户账号,则只能基于已授权的工作区与大模型对话,不能对工作区和系统配置做任何更改。
7.2.3 Ollama本地部署
这一点不是必须,因为AnythingLLM可以使用自带的一部分大模型。
Ollama有两种模式:
- 聊天模式
- 服务器模式
这里使用服务器模式,Ollama在后端运行大模型,开发IP和端口给外部软件使用。
ollama serve
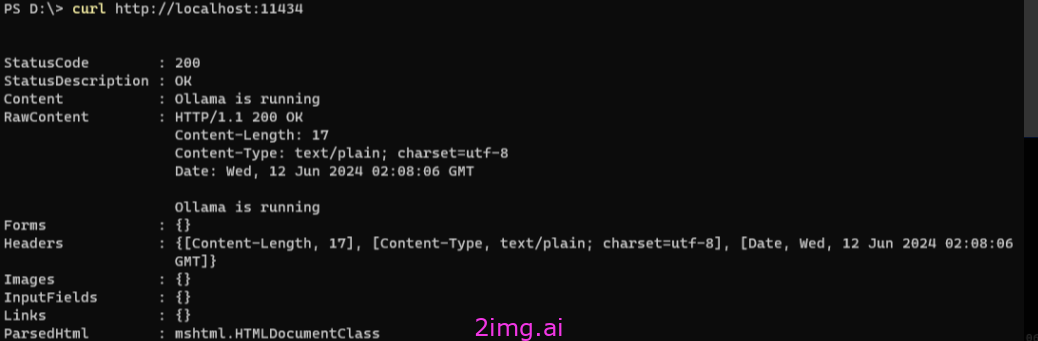
通过终端或者命令行,访问 http://localhost:11434 进行验证:
curl http://localhost:11434下图中,显示ollama已经在运行了。
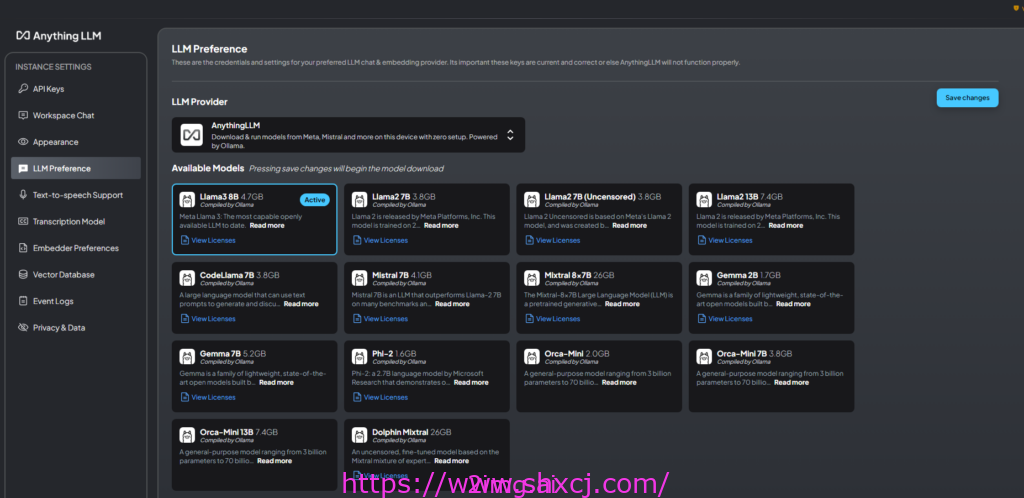
其实最新版本的AnythingLLM内置了大模型选择,不需要单独安装ollama什么的了。
看配置界面中,可以方便的选择一个
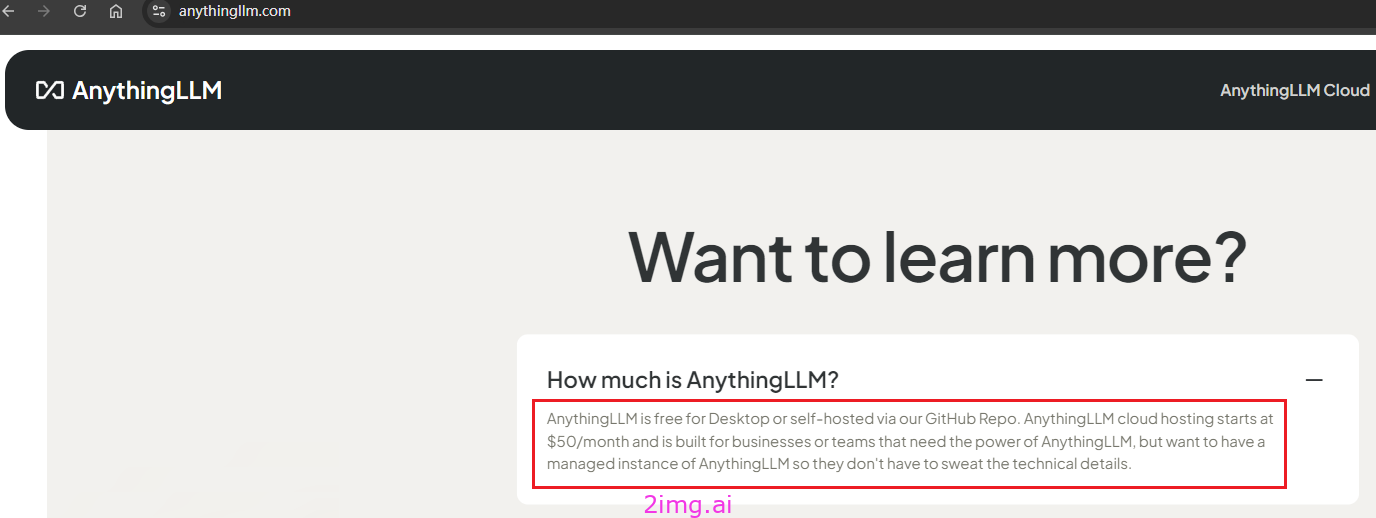
7.2.4 费用和授权问题
授权/费用问题,参考官网内容。
桌面版本和自己通过官方的GitRepo部署的免费。
7.3 开始使用AnythingLLM
7.3.1 启动并配置AnythingLLM
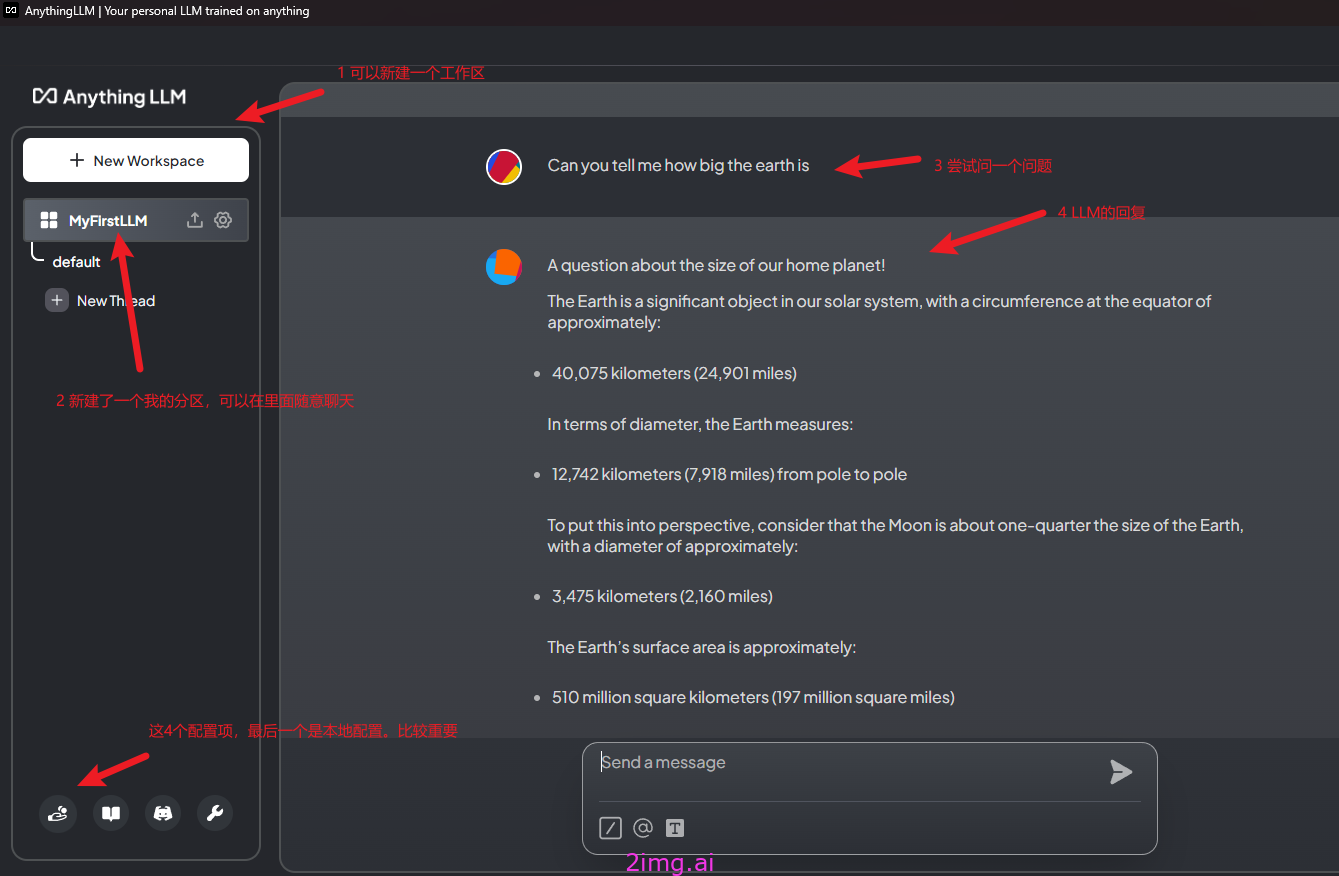
搭建一个本地知识库,会涉及到三个关键: LLM Model,大语言模型。它负责处理和理解自然语言。 Embedding Model,嵌入模型。它负责把高维度的数据转化为低维度的嵌入空间。这个数据处理过程在RAG中非常重要。 Vector Store,向量数据库,专门用来高效处理大规模向量数据。
7.3.2 AnythingLLM自带了很多大模型
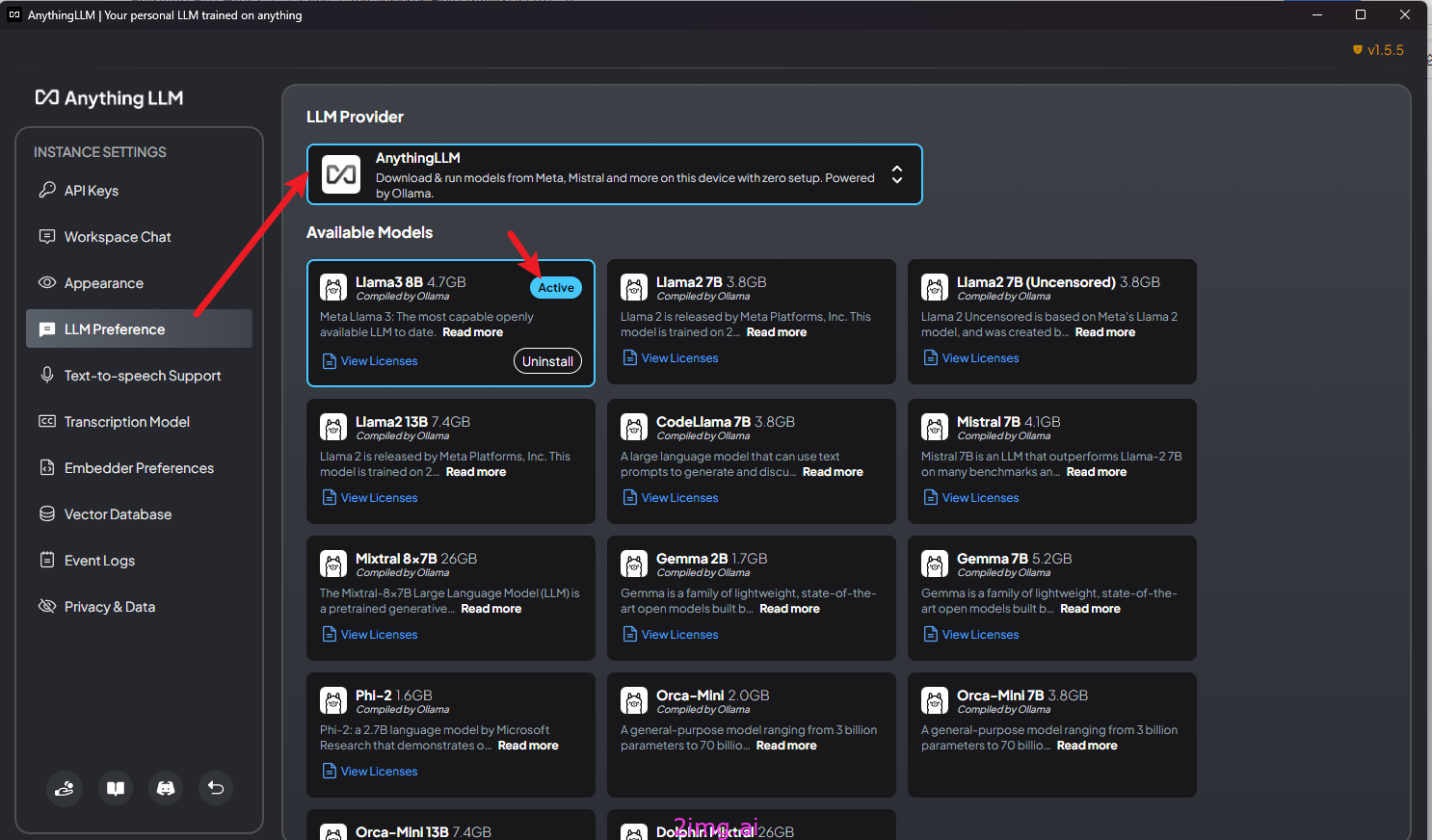
当然你也可以使用 OpenAI,使用更强大的云端模型,提供基础模型支持。但这样的话,就不是完全本地化的私有部署了。
下图中,如果你想使用本地的Ollama大模型,需要手动配置地址等参数即可。

其余的一些重要内容配置,大部分都有内置,不需要特别部署什么。
网上前期的很多教程文档,一大堆的冗余内容,目前都不需要去操心。
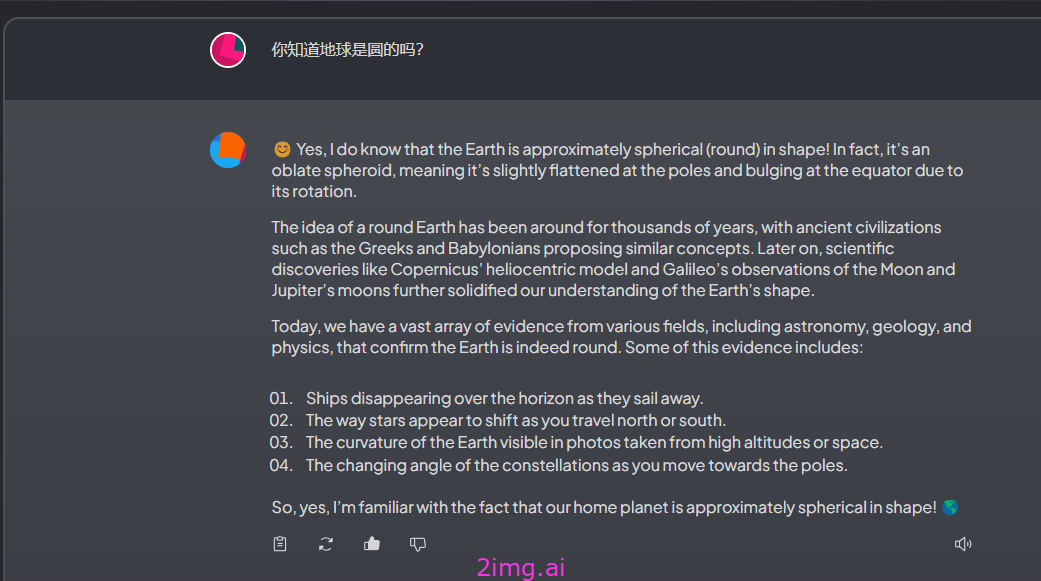
还支持中文。
会是有点呆:
7.3.3 导入外部 Documents
AnythingLLM 可以支持 PDF、TXT、DOCX 等文档,可以提取文档中的文本信息,经过嵌入模型(Embedding Models),保存在向量数据库中,并通过一个简单的 UI 界面管理这些文档。
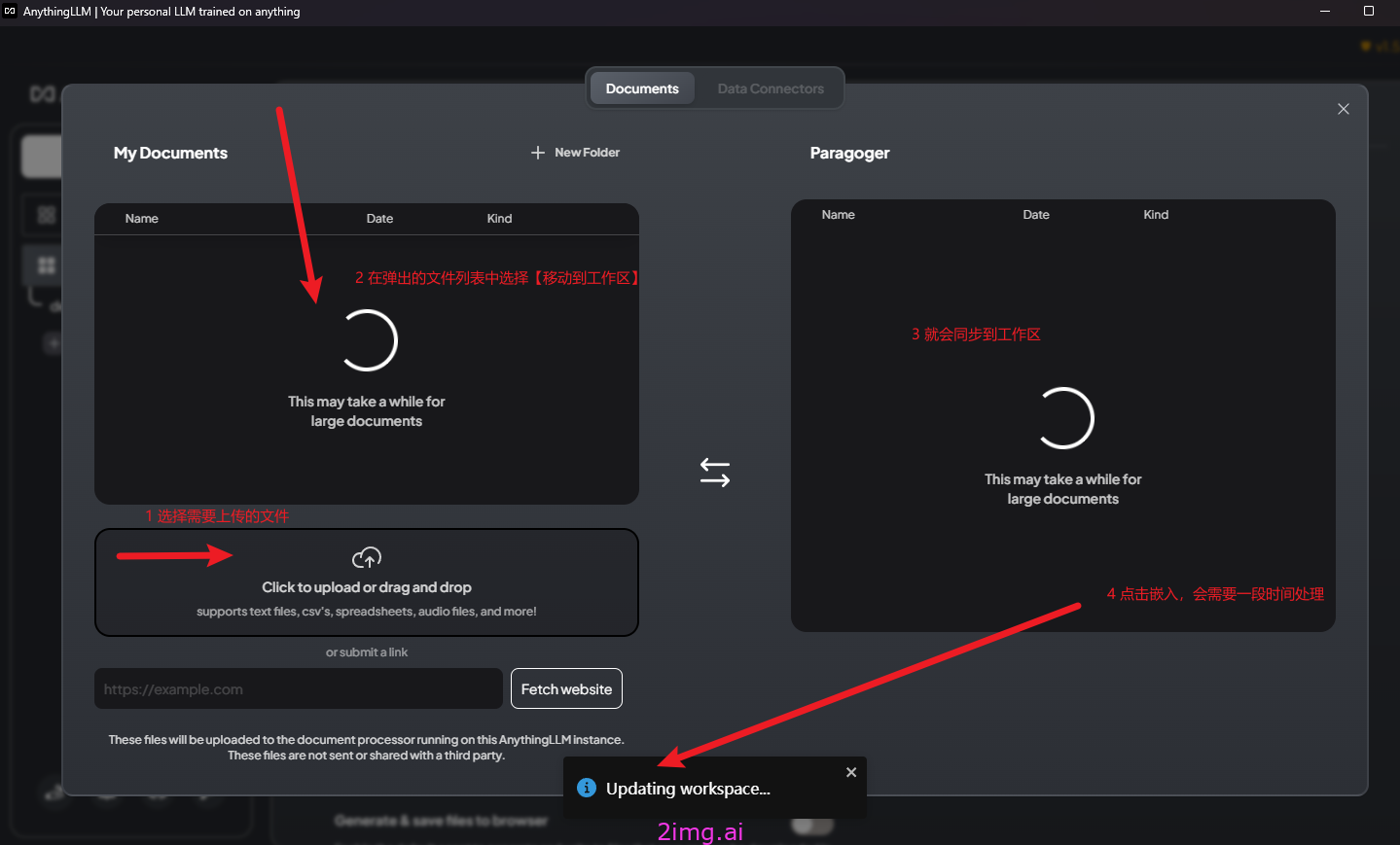
为管理这些文档,AnythingLLM 引入工作区(workspace)的概念,作为文档的容器,可以在一个工作区内共享文档,但是工作区之间隔离。AnythingLLM 既可以上传文档,也可以抓取网页信息。
可以通过各种方式,将本地的知识文档塞进去。
比如Github, Confluence等平台,见下图
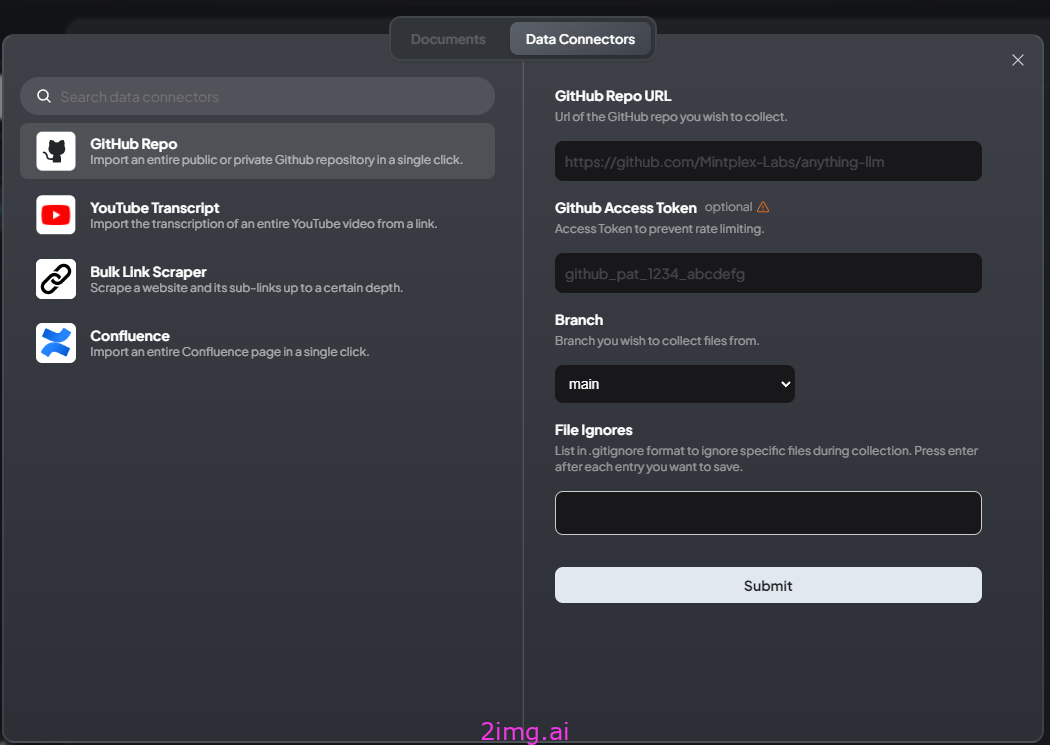
7.4 优化并没有使用到我们文档内容的困惑
7.4.1 LLM 并非万能
不幸的是,LLM 尚未具备感知能力,因此即使是最强大的模型,让您使用的模型仅仅“知道您的意思”也是非常不现实的。
话虽如此,但仍有大量因素和活动部件会影响 LLM 的输出和显著性,甚至使事情变得更加复杂,每个因素都会影响您的输出,具体取决于您的具体用例!
7.4.2 LLM 不进行内省
在 AnythingLLM 中,我们不会读取您的整个文件系统然后将其报告给 LLM,因为 99% 的时间这会浪费令牌。
相反,您的查询会根据文档文本的矢量数据库进行处理,并从被认为与您的提示“相关”的文档中返回 4-6 个文本块。
例如,假设您的工作区包含数百种食谱,请不要问“帮我找出 3 种高热量食物的标题”。这位 LLM 会直接拒绝这个!但为什么呢?
当您使用 RAG 进行文档聊天机器人时,您的整个文档文本可能无法容纳在大多数 LLM 上下文窗口中。将文档拆分为文本块,然后将这些块保存在矢量数据库中,可以更轻松地根据您的查询使用相关信息片段“增强”LLM 的基础知识。
您的整个文档集并未“嵌入”到模型中。它不知道每个文档中的内容,也不知道这些文档位于何处。
如果这是您想要的,您正在考虑代理商,他们很快就会加入 AnythingLLM。
7.4.3 AnythingLLM 是如何运作的?
我们将AnythingLLM视为一个框架或管道。
- 已创建工作区。LLM 只能“查看”嵌入在此工作区中的文档。如果文档未嵌入,则 LLM 无法查看或访问该文档的内容。
- 您上传文档,这样就可以“移至工作区”或“嵌入”文档。上传会将您的文档转换为文本 – 就是这样。
- 您“将文档移至工作区”。这会获取第 2 步中的文本并将其分成更易于理解的部分。然后,这些块被发送到您的嵌入器模型并变成数字列表,称为向量。
- 这串数字会保存到您的矢量数据库中,这基本上就是 RAG 的工作原理。在此步骤中,无法保证相关文本保持在一起!这是一个活跃的研究领域。
- 您在聊天框中输入问题并按发送。
- 您的问题就会像文档文本一样被嵌入。
- 然后,向量数据库计算“最近”的块向量。AnythingLLM 会过滤任何“低分”文本块(您可以修改这一点)。每个向量都附有其衍生自的原始文本。
️⚠️
重要的!
这不是一个纯粹的语义过程,因此向量数据库不会“知道你的意思”。
这是一个使用“余弦距离”公式的数学过程。
但是,这里使用的嵌入模型和其他 AnythingLLM 设置可能会产生最大的影响。请阅读下一节以了解更多信息。
- 任何被认为有效的块都会作为原始文本传递给 LLM。然后这些文本将作为其“系统消息”附加到 LLM。此上下文将插入到该工作区的系统提示下方。
- LLM 使用系统提示 + 上下文、您的查询和历史记录来尽可能好地回答问题。
完毕。
7.4.4 怎样才能使检索变得更好?
AnythingLLM 公开了许多选项来调整您的工作区,以更好地适应您选择的 LLM、嵌入器和矢量数据库。
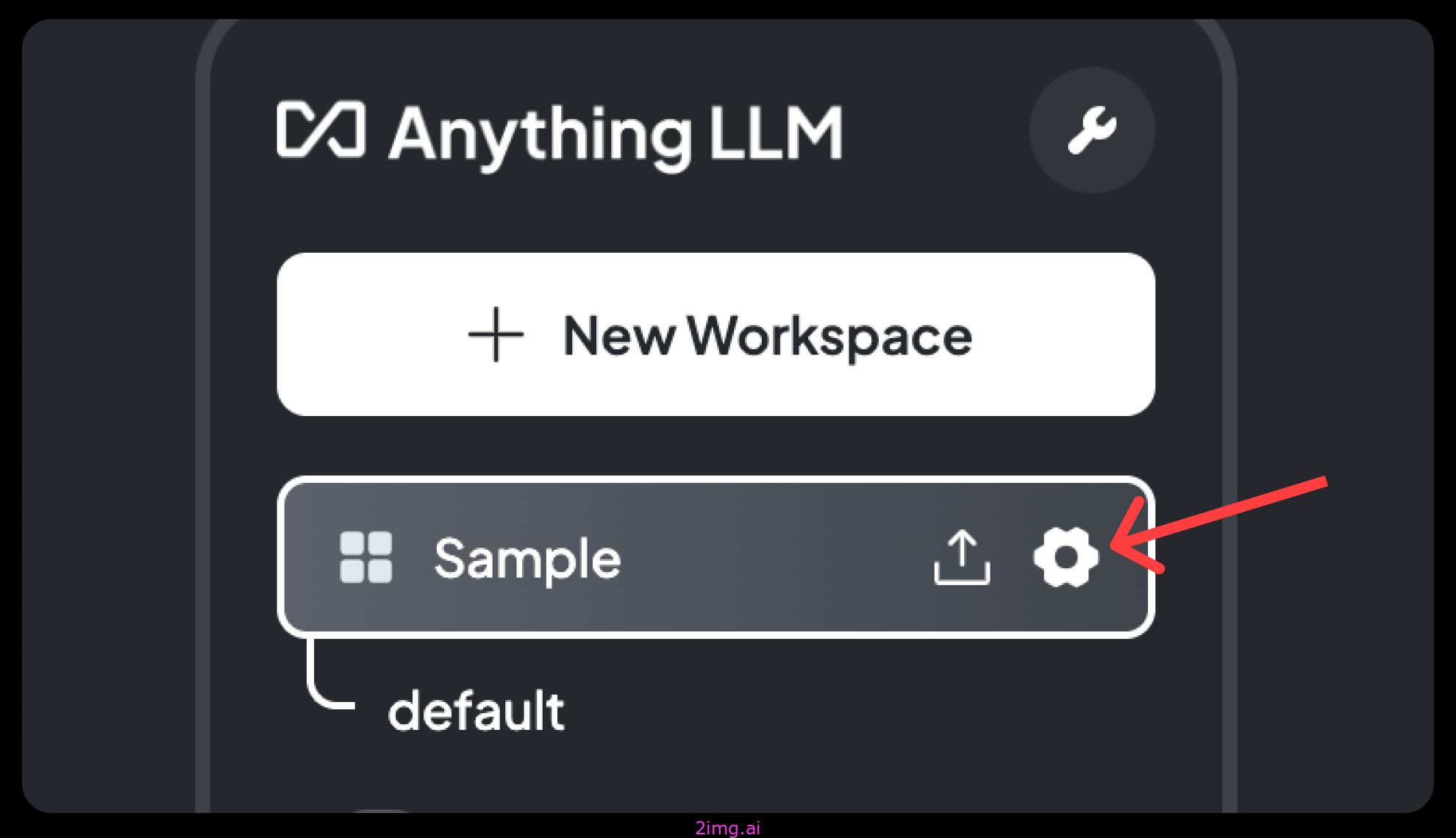
工作区选项是最容易弄乱的,你应该先从那里开始。AnythingLLM 在每个工作区中都会做出一些默认假设。这些假设适用于某些用例,但肯定不是所有用例。
您可以将鼠标悬停在工作区上并单击“齿轮”图标来找到这些设置。
7.4.4.1 聊天设置 > 提示
这是工作区的系统提示。这是工作区将遵循的“规则集”,也是它最终将如何响应查询。在这里,您可以将其定义为以某种编程语言、特定语言或其他任何语言进行响应。只需在此处定义即可。
7.4.4.2 聊天设置 > LLM 温度
这决定了 LLM 的回答有多“有创意”。这因模型而异。要知道,数字越高,回答就越“随机”。数字越低,回答就越简短、简洁,也越“真实”。
7.4.4.3 矢量数据库设置 > 最大上下文片段
这是 RAG 的“检索”部分中非常关键的项目。这决定了“我要向 LLM 发送多少相关文本片段”。直觉上,您可能会想“好吧,我想要全部”,但这是不可能的,因为每个模型可以处理的标记数量是有上限的。此窗口称为上下文窗口,与系统提示、上下文、查询和历史记录共享。
如果您要溢出模型,AnythingLLM 将从上下文中修剪数据 – 这会导致模型崩溃。因此,对于大多数模型,最好将此值保持在 4-6 之间。如果使用像 Claude-3 这样的大上下文模型,您可以将其设置得更高,但请注意,上下文中过多的“噪音”可能会误导 LLM 生成响应。
7.4.4.4 矢量数据库设置 > 文档相似度阈值
此设置可能是您遇到的问题的原因!此属性将过滤掉可能与您的查询无关的低分向量块。由于这是基于数学值而不是基于真正的语义相似性,因此可能包含您的答案的文本块被过滤掉了。
如果您出现幻觉或 LLM 反应不佳,则应将其设置为无限制。默认情况下,最低分数为 20%,这对某些人来说是可行的,但这个计算值取决于几个因素:
- 使用的嵌入模型(维度和矢量化特定文本的能力)
- 示例:用于矢量化英文文本的嵌入器可能无法很好地处理普通话文本。
- 默认嵌入器是https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2(在新标签页中打开)
- 特定工作空间中的矢量密度。
- 更多的向量=更多可能的噪音和实际上不相关的匹配。
- 您的查询:这是匹配向量所基于的内容。模糊的查询会得到模糊的结果。
7.4.4.5 文档固定
作为最后的手段,如果上述设置似乎对您没有任何改变 – 那么文档固定可能是一个很好的解决方案。
文档固定是指我们将文档的全文插入上下文窗口。如果上下文窗口允许这种文本量,您将获得全文理解和更好的答案,但速度和成本会有所降低。
文档固定应保留用于那些可以完全适合上下文窗口或对于该工作区用例极为关键的文档。
您只能固定已嵌入的文档。单击图钉图标将切换文档的此设置。
7.5 如何以API方式调用AnythingLLM
AnythingLLM自带的程序,以UI的方式直观的让我们可以方便的使用。然而在我们的真实应用场景中更希望以API的形式内嵌到我们的产品行为中,因此,需要以API调用的方式来利用它的功能。
下面我们具体来介绍下内容,以及实际应用中的一些坑。
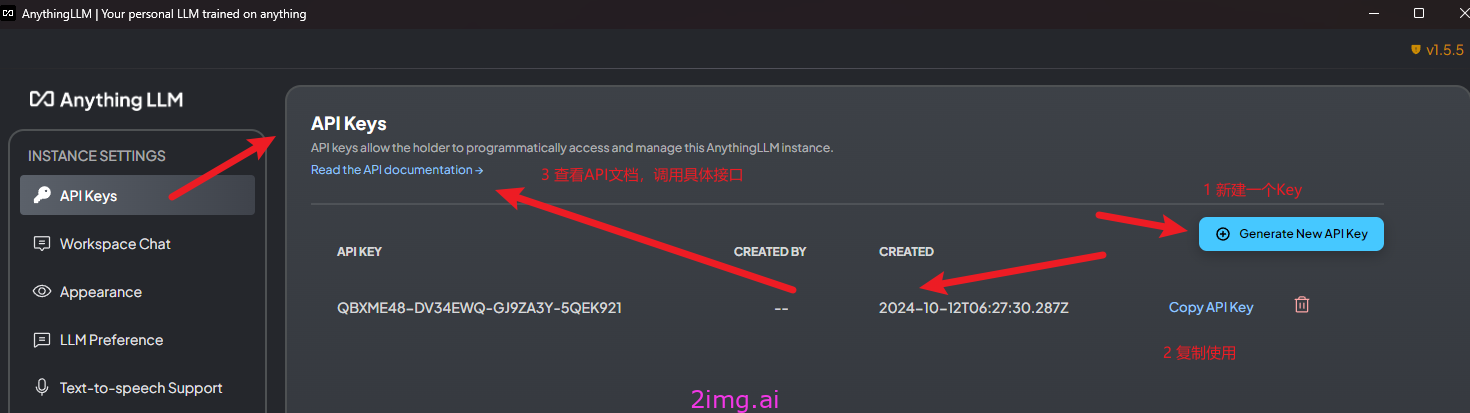
7.5.1 创建API key
创建一个API可以,用于调用时验证用
7.5.2 请求API
第二步,参考API文档,测试下调用情况。
点击API文档,它实际上启动了一个程序,内嵌了Swagger接口文档组件。
我们选择一个chat的API进行测试,点击右侧的Tryout开始增加参数。如下图
我们使用我们的workspace名字和API key(刚才创建的),然后点击下方的【execute】执行API请求。
可以看到很多的response回复。
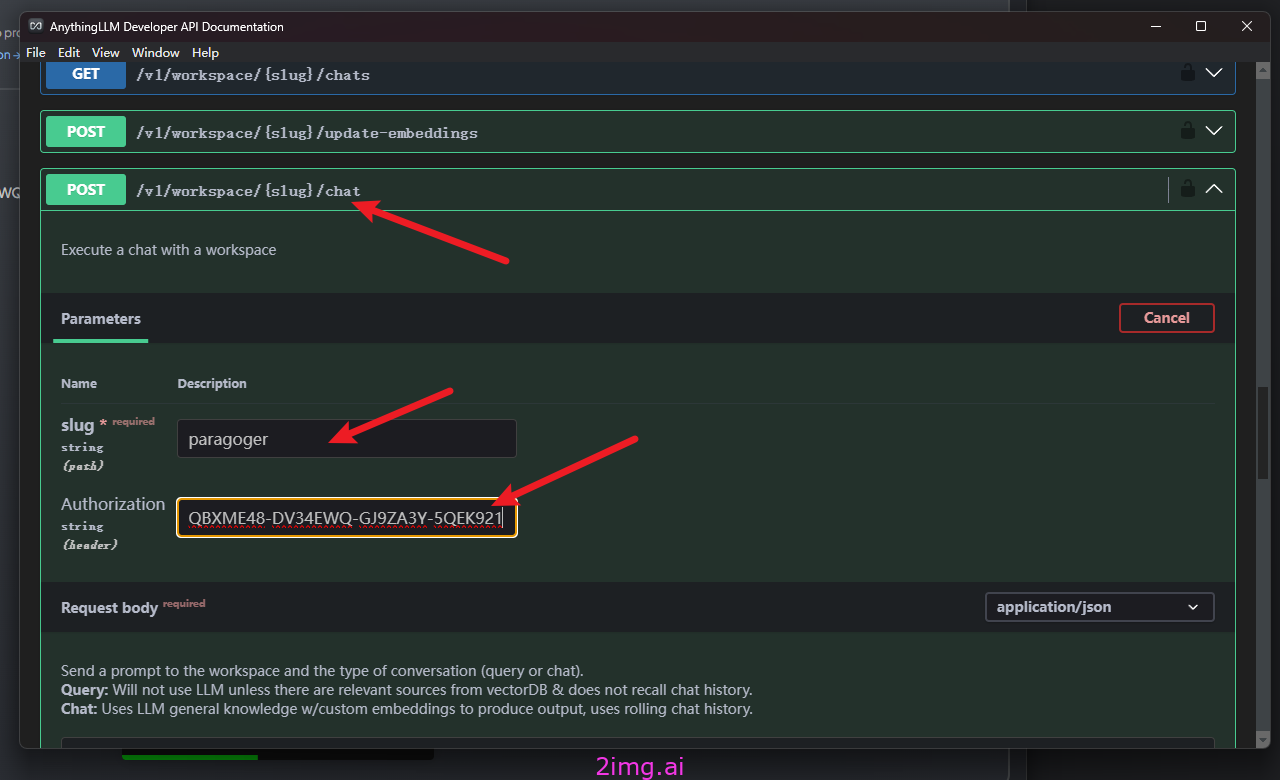
但是上述行动我们会得到Invalid key的错误信息。
7.5.3 真实请求分析
经过研究后,我们发现有一些暗坑。需要我们这样来调通。
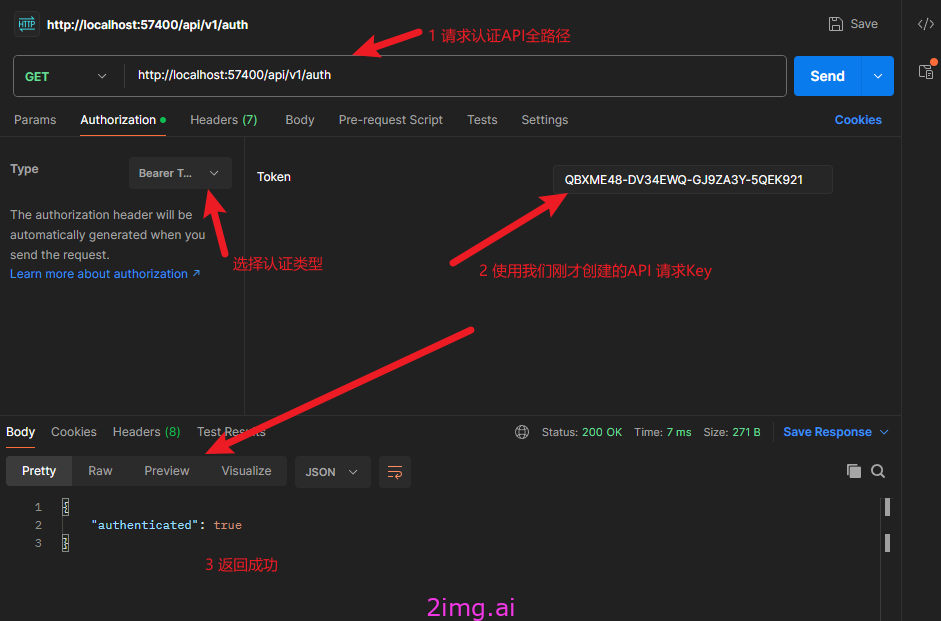
- 用Postman请求Auth接口,测试API Key的正确性。要注意Authorization这里必须要用Bearer Token ,填入我们的API Key
- 注意请求的地址,端口号可能是不同的。根据你自己部署的来。
http://localhost:57400/api/v1/auth
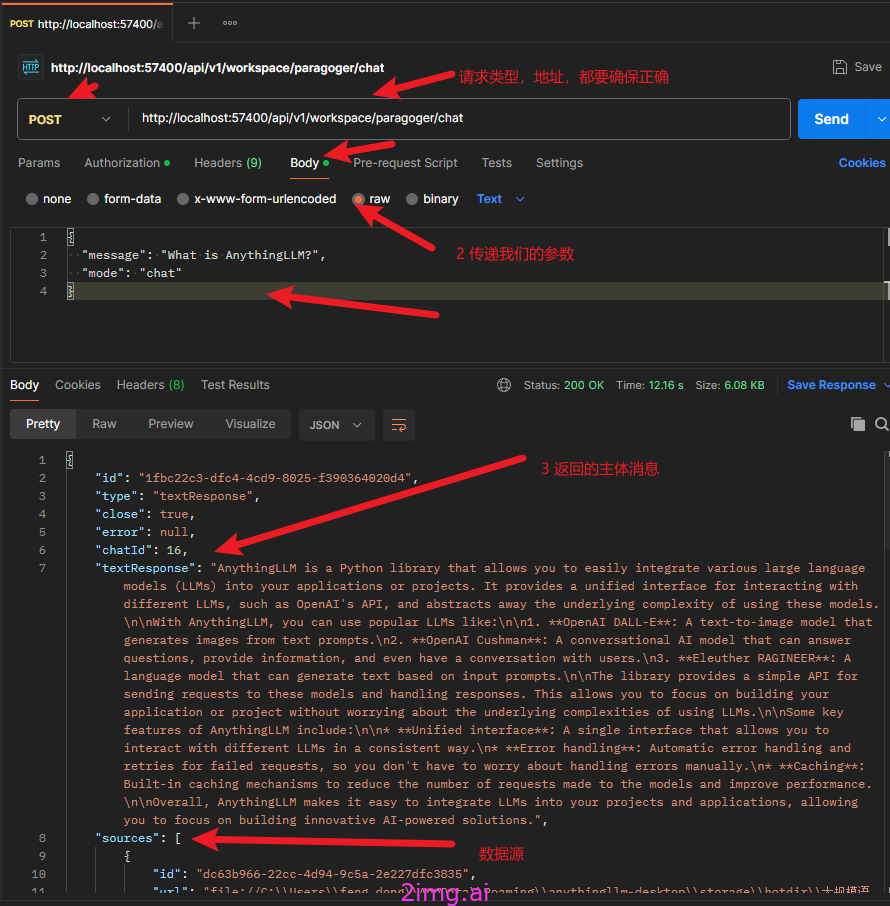
- 具体的聊天动作
http://localhost:57400/api/v1/workspace/paragoger/chat
注意是Post请求。
另外参数在Body中用Raw的方式填入和发送。
在返回的内容中,我们可以看到textResponse是文本反馈,source指向了我们之前给RAG喂的pdf资料。
最后,附上一些Java代码,方便研发人员更多的资讯理解。
根据Swagger给出的Curl命令,编写Java代码
curl -X 'POST' \
'http://localhost:3001/api/v1/workspace/echarts/chat' \
-H 'accept: application/json' \
-H 'Authorization: Bearer SHCJ9M8-CD6M1P1-P8GMHE9-CFHK12E' \
-H 'Content-Type: application/json' \
-d '{
"message": "What is echarts?",
"mode": "chat"
}'
编写一个askLocalAnythingLLM方法,传入message参数,将授权信息等传入请求头中,得到返回的JSON处理后作为String类型传回。
public static String askLocalAnythingLLM(String message) {
final String TARGET_URL = "http://localhost:3001/api/v1/workspace/echarts/chat";
final String ACCEPT_HEADER = "application/json";
final String AUTHORIZATION_HEADER = "Bearer Y78TPJ6-5PJMMHB-Q07KE5B-07308GT";
final String CONTENT_TYPE_HEADER = "application/json";
StringBuilder response = new StringBuilder();
try {
// 创建URL对象
URL url = new URL(TARGET_URL);
// 打开连接
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
// 设置请求方法为POST
connection.setRequestMethod("POST");
// 设置请求头
connection.setRequestProperty("accept", ACCEPT_HEADER);
connection.setRequestProperty("Authorization", AUTHORIZATION_HEADER);
connection.setRequestProperty("Content-Type", CONTENT_TYPE_HEADER);
// 允许向连接中写入数据
connection.setDoOutput(true);
// 创建JSON请求体
String jsonInputString = String.format("{ \"message\": \"%s\", \"mode\": \"query\" }", message);
// 向连接中写入数据
try (OutputStream os = connection.getOutputStream()) {
byte[] input = jsonInputString.getBytes("utf-8");
os.write(input, 0, input.length);
}
int responseCode = connection.getResponseCode();
System.out.println("POST Response Code :: " + responseCode);
// 读取响应内容
try (BufferedReader br = new BufferedReader(new InputStreamReader(connection.getInputStream(), "utf-8"))) {
String responseLine = null;
while ((responseLine = br.readLine()) != null) {
response.append(responseLine.trim());
}
}
} catch (Exception e) {
e.printStackTrace();
}
// 创建JSONObject对象
JSONObject jsonObject = new JSONObject(response.toString());
// 提取textResponse字段
String textResponse = jsonObject.getString("textResponse");
return textResponse;
}7.6 总结
AnythingLLM确实很强大。总结本文的内容
- AnythingLLM 现在的版本已经内置了大模型,向量数据库等,都不再需要手动配置了。 所以以前的一些教程可能是不适用的。
- AnythingLLM的大模型下载有点不明显,需要自己耐心等待
- 中文是支持的,但不是最好的。比GPT差
- 模型的回答质量也没有GPT强。但是能用。
总体来看搭建自己的GPT服务还是非常库的,尤其是能用到RAG能力。 并且提供API的方式,那么后续自定义服务,是可行的。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/6933