什么是矢量数据库?
矢量数据库是一种用于存储、索引和检索多维数据点(通常称为矢量)的数据库。与处理以表格形式组织的数据(如数字和字符串)的数据库不同,矢量数据库专门用于管理以多维矢量空间表示的数据。这使得它们非常适合人工智能和机器学习应用,其中数据通常采用矢量的形式,如图像嵌入、文本嵌入或其他类型的特征矢量。
这些数据库利用索引和搜索算法进行相似性搜索,使它们能够快速识别数据集中最相似的向量。这种能力对于推荐系统、图像和语音识别以及自然语言处理等任务至关重要,因为有效理解和处理高维数据起着至关重要的作用。因此,向量数据库代表了数据库技术的进步,旨在满足严重依赖大量数据的人工智能应用的需求。
向量嵌入
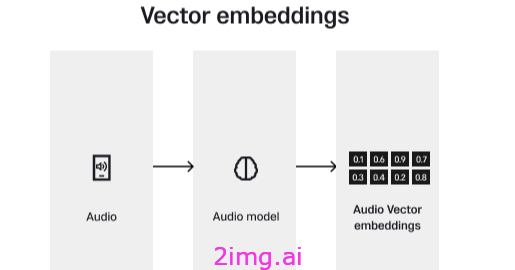
当我们谈论向量数据库时,我们肯定应该知道什么是向量嵌入——数据最终如何存储在向量数据库中。向量嵌入是一种数值代码,它封装了对象的关键特征;例如,音乐流媒体应用中的歌曲。通过分析和提取关键特征(如节奏和流派),每首歌曲都通过嵌入模型转换为向量嵌入。
此过程可确保具有相似属性的歌曲具有相似的向量代码。向量数据库存储这些嵌入,并在查询时比较这些向量以查找和推荐具有最接近匹配特征的歌曲 – 为用户提供高效且相关的搜索体验。
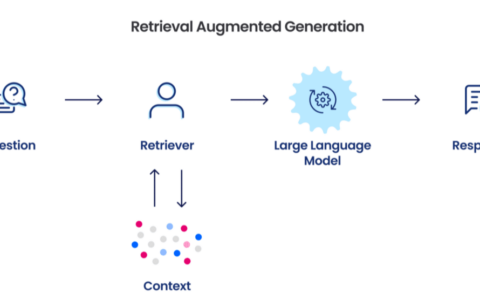
矢量数据库如何工作?
我们知道传统数据库是以行和列的形式存储字符串、数字等标量数据,而向量数据库是针对向量进行操作的,因此优化和查询的方式有很大不同。
在传统数据库中,我们通常会查询数据库中的值与查询完全匹配的行。在向量数据库中,我们应用相似度度量来查找与查询最相似的向量。
矢量数据库使用多种算法的组合,这些算法均参与近似最近邻 (ANN) 搜索。这些算法通过各种索引技术优化搜索。
这些算法被组装成一个管道,可以快速准确地检索查询向量的邻居。由于向量数据库提供近似结果,因此我们考虑的主要权衡是准确性和速度。结果越准确,查询速度就越慢。但是,一个好的系统可以提供超快的搜索和近乎完美的准确性。
以下是矢量数据库的常见流程:

- 索引:向量数据库使用 PQ、LSH 或 HNSW 等算法对向量进行索引(更多信息见下文)。此步骤将向量映射到可实现更快搜索的数据结构。
- 查询:向量数据库将索引查询向量与数据集中的索引向量进行比较,以找到最近的邻居(应用该索引使用的相似度度量)
- 后处理:在某些情况下,矢量数据库从数据集中检索最终的最近邻居,并对其进行后处理以返回最终结果。此步骤可以包括使用不同的相似性度量对最近邻居重新排序。
在以下章节中,我们将更详细地讨论每种算法,并解释它们如何有助于提高矢量数据库的整体性能。
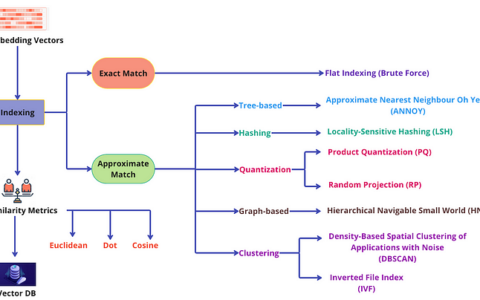
索引技术
基于树的方法对于低维数据非常有效,并且提供精确的最近邻搜索。然而,由于“维数灾难”,它们的性能在高维空间中通常会下降。它们还需要大量内存,并且对于大型数据集效率较低,从而导致更长的构建时间和更高的延迟。
量化方法节省内存,并且通过将向量压缩为紧凑代码来缩短搜索时间。但是,这种压缩可能会导致信息丢失,从而可能降低搜索准确性。此外,这些方法在训练阶段的计算成本可能很高,从而增加构建时间。
哈希方法速度快,内存效率相对较高,可将相似的向量映射到相同的哈希桶。它们在处理高维数据和大规模数据集时表现良好,可提供高吞吐量;但是,由于哈希冲突会导致误报和漏报,搜索结果的质量可能会降低。选择正确数量的哈希函数和哈希表数量至关重要,因为它们会显著影响性能。
聚类方法可以通过将搜索空间缩小到特定聚类来加快搜索操作,但搜索结果的准确性可能会受到聚类质量的影响。聚类通常是一个批处理过程,这意味着它不太适合动态数据,因为动态数据会不断添加新向量,从而导致频繁重新索引。
图方法在准确性和速度之间实现了良好的平衡。它们对于高维数据非常有效,可以提供高质量的搜索结果。然而,它们可能占用大量内存,因为它们需要存储图结构,而且图的构建也需要耗费大量的计算资源。

矢量数据库中算法的选择取决于任务的具体要求,包括数据集的大小和维数、可用的计算资源以及准确度和效率之间可接受的权衡。还值得注意的是,许多现代矢量数据库使用混合方法,结合不同方法的优势来实现高速度和高准确度。对于任何希望从矢量数据库中获得最佳性能的人来说,了解这些算法及其权衡至关重要。现在让我们来看看每个类别中的所有流行算法。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/6828