SAM 2、LLaVA或 ChatGPT等模型无需特殊训练即可完成任务。这让人们怀疑训练 AI 的旧方法(即微调)是否已经过时。
在本文中,我们比较了两种模型:YOLOv8(微调)和 YOLO-World(零样本)。通过观察每种模型的效果,我们将尝试回答一个大问题:微调是否会成为过去,还是我们仍然需要这两种训练 AI 的方式?🤔
TL;DR:如下所示,上述问题的答案是:视情况而定!
目录
- 微调 VS 零样本
- YOLOv8 与 YOLO-World
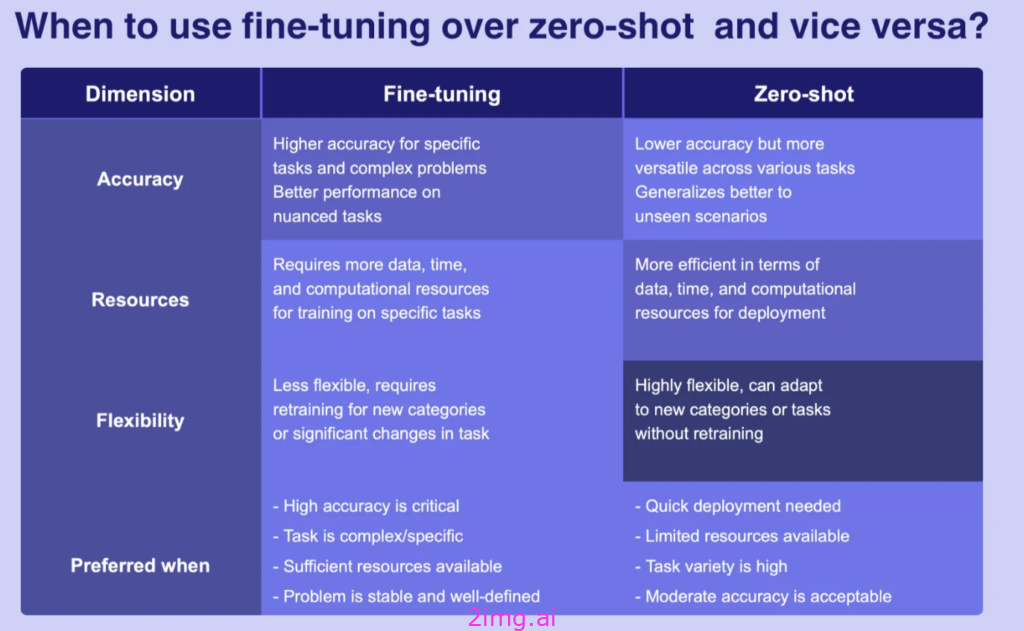
- 那么,何时使用微调而不是零样本,反之亦然?
- 下一步是什么?
1. 微调 VS 零样本
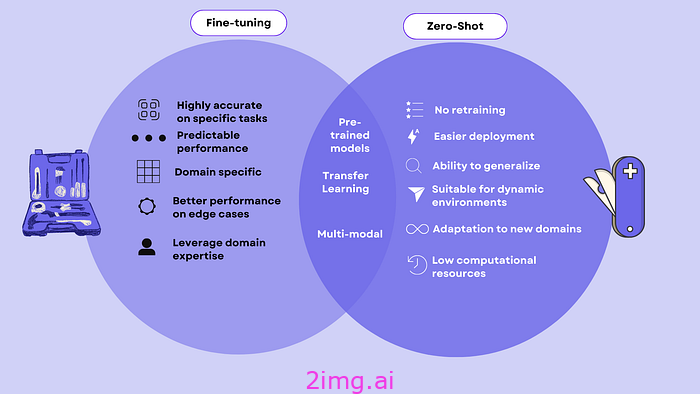
传统上,在物体检测(计算机视觉中的一项关键任务)中,我们严重依赖微调[1]。此过程涉及采用预先训练的模型,并使用较小的特定于任务的数据集调整其参数。
虽然微调有效,但也有其缺点:
- 1.耗时:往往需要数小时甚至数天的训练。
- 2. 数据量巨大:每个新类别都需要大量标记数据。
- 3. 计算成本高昂:需要大量的处理能力和能源。
- 4. 缺乏灵活性:模型需要针对每个新的对象类别进行重新训练。
零样本学习 [2] 是一种突破这些限制的革命性方法。零样本学习并不是新事物,但它使模型能够识别从未明确训练过的对象类别。
从高层次来看,零样本的工作原理如下:
- 1.模型学习将视觉特征与语义概念联系起来(即语义理解)。
- 2. 它利用这种理解来识别新的、看不见的物体(即知识转移)。
- 3.该模型使用上下文线索对不熟悉的物体做出有根据的猜测(即上下文推理)。
这为本文的关键问题奠定了基础:鉴于零样本模型(如为语言任务提供支持的 ChatGPT 模型)越来越受欢迎,物体检测的微调时代是否即将结束?
剩余内容需解锁后查看
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/6386