
介绍
ChatGPT 或当今底层的大型语言模型 (LLM) 能够在给出提示的情况下生成情境化的响应。
作为 LLM 发展的下一步,我们希望响应能够根据最终用户的角色、对话历史、当前对话环境和情绪变得越来越个性化。
LLM 个性化的主要优势包括:
- 个性化响应:Gen AI 解决方案根据与之交互的用户调整其语言、语调和复杂性。这确保对话更符合用户的期望和沟通风格。
- 对话上下文:Gen AI 解决方案了解用户的典型用例、偏好和历史记录,从而能够提供更具上下文相关性和个性化的响应。
- 内容定制:Gen AI解决方案可以根据用户的需求,优先考虑或突出显示不同的功能或内容类型,从而使交互更加高效和人性化。
- 主动协助:Gen AI 解决方案可以预测不同用户的需求,并根据他们的特定个人资料或任务提供主动建议、资源或提醒。
在之前的文章 [1] 中,我们撰写了关于设计基于用例的 LLM 评估策略的文章。在某种程度上,当我们谈论应用生成式人工智能 (Gen AI) 来解决当今的特定用例时,我们基本上是在个性化预训练的(基础)LLM,以便它提供针对该用例的特定响应。当今的用例情境化 [2] 主要涉及使用用例特定的企业数据对预训练的 LLM 应用微调/RAG。


在本文中,我们讨论了如何将相同的技术应用于用户数据(用户个人资料和对话数据)以个性化 LLM 响应。
因此,我们基本上需要了解如何最好地应用:
- 微调,
- 检索增强生成 (RAG),
- 带人工反馈的强化学习(RLHF)
关于用户数据:
- 用户资料、人物角色
- 对话历史记录
- 当前对话背景和情绪。
基于用户角色的 LLM 微调
如今,用户希望获得无缝且个性化的体验,并希望获得定制答案来满足他们的特定查询。然而,由于规模、性能和隐私方面的挑战,用户特定的个性化仍然具有挑战性。
基于角色的个性化 [3] 旨在通过将服务的最终用户划分为一组可管理的用户类别来克服这些挑战,这些类别代表了大多数用户的人口统计和偏好。例如,在支持 Gen AI 的 IT 服务台(当今 Gen AI 采用率最高的领域之一)场景中,典型的角色包括:
- 领导层:高级个人(例如副总裁、董事),他们需要优先获得对敏感数据的安全访问支持,以及对高层演示和视频会议的协助。
- 知识型员工:严重依赖技术来完成日常任务的员工(例如,分析师、工程师、设计师)。
- 现场工作人员:主要在办公室外工作的员工(例如销售代表、服务技术人员)。因此,他们的要求主要集中在远程访问公司系统、可靠的 VPN 以及离线工作功能的支持。
- 行政/人力资源:负责各种行政任务(例如人力资源、财务)的支持人员,主要要求协助使用微软 Office 软件、访问特定的业务应用程序以及快速解决常规 IT 问题。
- 新员工/实习生:新加入组织且可能不完全熟悉公司 IT 系统的个人。因此,他们的问题主要集中在入职相关的问题上。
鉴于此,执行基于角色的 LLM 微调是有意义的——创建特定于角色的小型语言模型 (SLM)。模型路由器有助于执行提示分段(评分)并将提示路由到最相关的角色 SLM。
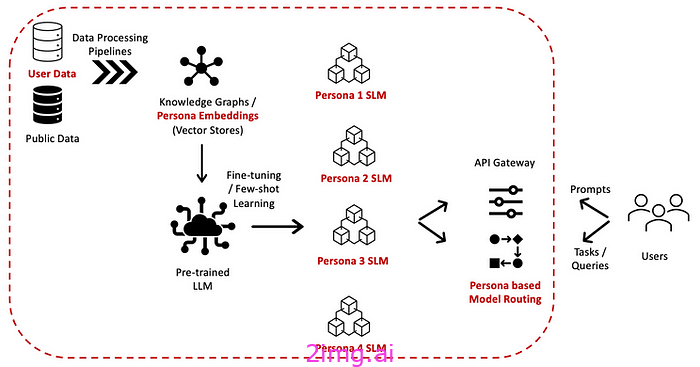
微调过程包括首先参数化(聚合)人物数据和对话历史,并通过适配器将其作为内存存储在 LLM 中 [4],然后对 LLM 进行微调以生成个性化响应。例如,请参阅 [5, 6] 分别了解教育和医学背景下基于人物的 LLM 微调的详细信息。
- [5] 考虑在教育语料库上预训练模型来建立基础知识库,然后针对个性化任务(例如论文评估)对其进行微调。
- [6] 将参数高效微调(PEFT)与记忆检索模块相结合,以生成个性化的医疗反应。
LLM — 用户嵌入
在本节中,我们重点生成用户对话嵌入,这是微调和/或实时 RAG 提示上下文增强的先决条件。
对原始用户数据进行 LLM 微调通常过于复杂,即使是在(聚合)角色级别。
- 对话数据通常跨越多个旅程,具有稀疏的数据点、各种交互类型(多模式)以及潜在的噪音或与不完整的查询(响应)的不一致。
- 此外,有效的个性化通常需要深入了解用户行为背后的潜在意图/情感,这可能会给通用(预训练)LLM 带来困难。
- 最后,微调需要大量计算。用户对话数据可能很长。使用 LLM 处理和建模如此长的序列(例如多年的对话历史)实际上并不可行。
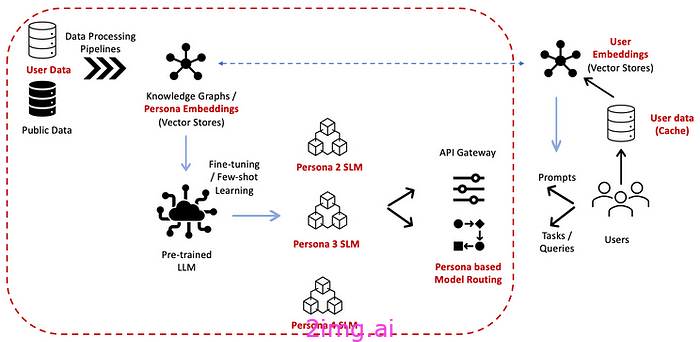
克服上述问题的一个很好的解决方案参考是 Google 在 User-LLM 方面的工作。根据 [7] 中的作者所述,
USER-LLM 从多样化和嘈杂的用户对话中提取压缩表示,有效地捕捉用户在各种交互模式下的行为模式和偏好的本质。
这种方法使 LLM 能够更深入地了解用户的潜在意图(包括情绪)和历史模式(例如,用户查询 – 响应的时间演变),从而使 LLM 能够定制响应并生成个性化结果。解决方案架构如下图所示。
基于强化学习的大语言模型个性化
在本节中,我们将展示如何根据基于强化学习的推荐引擎对 LLM 生成的响应进行个性化。
强化学习 (RL) 是一种强大的技术,它能够通过实时最大化奖励函数来实现复杂的目标。奖励函数的工作原理类似于用糖果和打屁股来激励孩子,当算法做出错误决定时会受到惩罚,而当算法做出正确决定时会得到奖励——这就是强化。
我们概述了下面的高级步骤,以使基于强化学习的推荐引擎能够个性化 LLM 生成的响应。
1. 使用可用的传感器收集用户对话上下文和情绪,以计算“当前”用户反馈,
2. 然后将其与用户对话历史相结合,量化用户情绪曲线并忽略用户情绪的任何突然变化;
3. 得出与向用户提供的最后一个 LLM 响应相对应的总奖励值。
4. 然后将该奖励值作为反馈提供给 RL 代理——选择下一个最佳 LLM 生成的响应提供给用户。
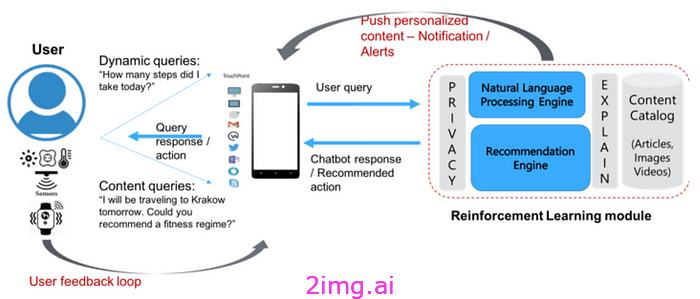
更具体地说,我们可以将支持 RL 的推荐引擎 [8] 与基于 LLM 的聊天应用程序 [9] 的集成制定如下:
动作(a):在这种情况下,动作 a 对应于作为正在进行的对话的一部分,响应用户查询/提示而传递给用户的 LLM 生成的响应。
代理 (A):执行操作的代理。在本例中,代理是向用户提供 LLM 响应的聊天应用程序,其中根据其策略选择操作(如下所述)。
环境:指代理与之交互并对代理的操作做出响应的世界。在我们的案例中,环境对应于与聊天应用程序交互的用户U。U通过提供不同类型的反馈来响应A的操作,包括显式反馈(以聊天响应的形式)和隐式反馈(例如,用户情绪的变化)。
Policy(𝜋):是代理用来选择下一个基本动作 (NBA) 的策略。给定用户资料Up、(当前) 情绪Us和查询Uq;策略函数分别计算 NLP 和推荐引擎返回的响应分数的乘积,选择得分最高的响应作为 NBA:
- NLP 引擎 (NE) 解析查询/提示并输出响应的排序列表。
- 推荐引擎 (RE) 根据奖励函数为每个响应提供分数,并考虑用户个人资料、偏好、对话历史/上下文和情绪。策略函数可以形式化如下:

奖励 (r):指我们用来衡量代理推荐操作(响应)成功或失败的反馈。例如,反馈可以指用户阅读推荐文章所花的时间,或收到响应后用户情绪的变化。我们考虑一个 2 步奖励函数计算,其中首先将收到的与推荐操作相关的反馈fa映射到情绪分数,然后将其映射到奖励
r(a,fa) = s(fa)
其中r和s分别表示奖励函数和情绪函数。RL 公式如下图所示:

结论
在本文中,我们考虑了基于用户数据的 LLM 生成响应的个性化。个性化有可能通过提高用户满意度来显著加速 LLM 的采用。我们提出并详细介绍了三种 LLM 个性化技术:(a) 基于角色的 LLM 微调,(b) 生成用于推理的用户 LLM 嵌入,以及 © 基于强化学习的 LLM 个性化。作为未来的工作,我们正在探索一种综合方法,根据用例需求和用户数据可用性应用多种个性化技术。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/6372