
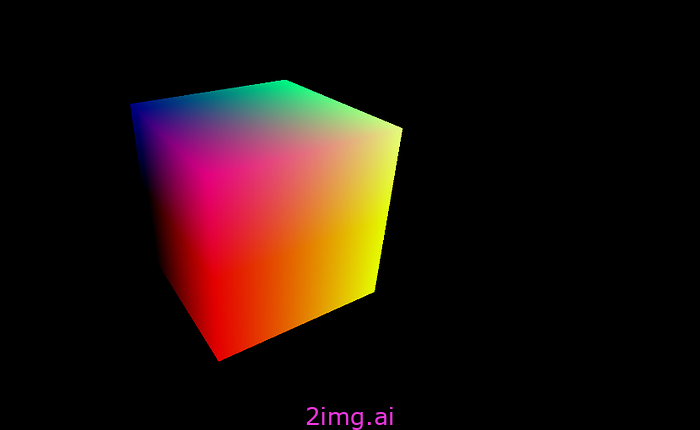

介绍
想象一下:一个动态旋转的立方体无缝呈现在您的网页上,吸引访客的注意力,并展示 WebGPU 解锁的前沿可能性。加入我们,我们将深入研究基础知识,揭开复杂性的神秘面纱,并逐步指导您使用 WebGPU 让旋转的立方体栩栩如生。
WebGPU 是 WebGL 的继任者,它提供了一个低级 API,允许开发人员直接与 GPU(图形处理单元)交互,与 WebGL 等高级抽象相比,它具有更多的控制和更好的性能。它引入了一种更现代、更高效的方法来处理 Web 应用程序中的图形和计算任务,这与下一代图形 API(DirectX 12、Metal 和 Vulkan)更相似。
在本教程中,我们将直接与 WebGPU API 交互,而不是使用 Babylon 和 Three 等包装器 Web 图形库。如果您确实想在生产站点中使用 WebGPU,这些高级包装器会更加友好,并且会是更好的解决方案,但为了深入了解该过程,我们将尽可能低级地进行工作。
一些设置代码
首先,我们需要创建一些设置代码,用于创建旋转立方体。
我们的立方体
const vertex = new Float32Array([
// float3 position
// face1
+1, -1, +1,
-1, -1, +1,
-1, -1, -1,
+1, -1, -1,
+1, -1, +1,
-1, -1, -1,
// face2
+1, +1, +1,
+1, -1, +1,
+1, -1, -1,
+1, +1, -1,
+1, +1, +1,
+1, -1, -1,
// face3
-1, +1, +1,
+1, +1, +1,
+1, +1, -1,
-1, +1, -1,
-1, +1, +1,
+1, +1, -1,
// face4
-1, -1, +1,
-1, +1, +1,
-1, +1, -1,
-1, -1, -1,
-1, -1, +1,
-1, +1, -1,
// face5
+1, +1, +1,
-1, +1, +1,
-1, -1, +1,
-1, -1, +1,
+1, -1, +1,
+1, +1, +1,
// face6
+1, -1, -1,
-1, -1, -1,
-1, +1, -1,
+1, +1, -1,
+1, -1, -1,
-1, +1, -1
])
const vertexCount = 36
export {vertex, vertexCount}这是我们立方体顶点的基本表示,其顺序非常重要,因为 WebGPU 将使用它来确定如何绘制三角形。
请注意,每行都有三个数字,它们代表顶点的 x、y、z 坐标。在我们的表示中,GPU 将使用三个连续的顶点以逆时针方向绘制三角形。要为我们的立方体绘制一个正方形面,我们需要两个三角形,这就是为什么在每个 faceN 注释下,我们都会看到六个顶点。
为什么是三角形?
在图形中,我们使用三角形来构建更复杂的形状和网格。正方形、五边形、六边形和所有其他形状都可以通过排列三角形来构建。三角形还可以在 GPU 硬件上更高效地进行光栅化(将基于矢量的颜色转换为像素颜色)。
数学工具
import { mat4, vec3 } from 'gl-matrix'
const CENTER = vec3.fromValues(0,0,0)
const UP = vec3.fromValues(0,1,0)
export function getMvpMatrix(
aspect: number,
position: {x: number, y: number, z: number},
rotation: {x: number, y: number, z: number},
scale: {x: number, y: number, z: number},
) {
// get modelView Matrix
const modelViewMatrix = getModelViewMatrix(position, rotation, scale)
// get projection Matrix
const projectionMatrix = getProjectionMatrix(aspect)
// get mvp matrix
const mvpMatrix = mat4.create()
mat4.multiply(mvpMatrix, projectionMatrix, modelViewMatrix)
// return matrix as Float32Array
return mvpMatrix as Float32Array
}
function getModelViewMatrix(
position = {x:0, y:0, z:0},
rotation = {x:0, y:0, z:0},
scale = {x:1, y:1, z:1}
){
// get modelView Matrix
const modelViewMatrix = mat4.create()
// translate position
mat4.translate(modelViewMatrix, modelViewMatrix, vec3.fromValues(position.x, position.y, position.z))
// rotate
mat4.rotateX(modelViewMatrix, modelViewMatrix, rotation.x)
mat4.rotateY(modelViewMatrix, modelViewMatrix, rotation.y)
mat4.rotateZ(modelViewMatrix, modelViewMatrix, rotation.z)
// scale
mat4.scale(modelViewMatrix, modelViewMatrix, vec3.fromValues(scale.x, scale.y, scale.z))
// return matrix as Float32Array
return modelViewMatrix as Float32Array
}
function getProjectionMatrix(
aspect: number,
fov:number = 60 / 180 * Math.PI,
near:number = 0.1,
far:number = 100.0,
position = {x:0, y:0, z:0}
) {
const cameraView = mat4.create()
const eye = vec3.fromValues(position.x, position.y, position.z)
mat4.translate(cameraView, cameraView, eye)
mat4.lookAt(cameraView, eye, CENTER, UP)
// get a perspective Matrix
const projectionMatrix = mat4.create()
mat4.perspective(projectionMatrix, fov, aspect, near, far)
mat4.multiply(projectionMatrix, projectionMatrix, cameraView)
// return matrix as Float32Array
return projectionMatrix as Float32Array
}我们的数学实用程序将用于帮助我们获取立方体的坐标并将其转换为屏幕坐标,以便我们可以看到它们。
getModelViewMatrix用于将立方体的顶点从其自身的局部坐标投影到世界坐标。我们将向量右乘,因此或运算看起来像 I* T * R * S = TRS。让我们以立方体上的一个点为例 (1,1,1)。现在假设我们对模型进行一些变换,向上移动 1 个单位并缩放 2。我们的点将首先放大 2 到 (2,2,2),它不会旋转,然后向上移动 1 个单位到 (2,3,2)。这将为我们提供该点在世界空间中的位置。但是,对每个点执行此过程效率不高,需要总共五次矩阵乘法才能移动我们的顶点。幸运的是,我们知道立方体中的每个顶点都将应用相同的变换以将其放入世界空间,因此我们可以提前将所有这些组合成一个矩阵,该矩阵将平移、旋转和缩放我们的立方体。
现在我们已经知道了立方体在世界空间中的位置,我们需要将它投影到我们的屏幕上。
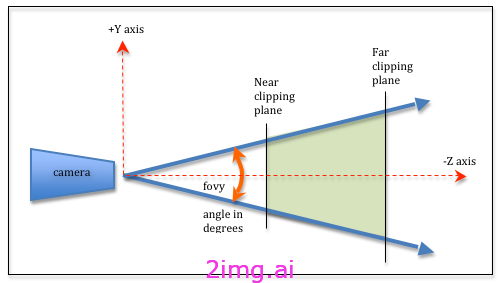
我们的getProjectionMatrix会将世界坐标转换为屏幕坐标。在我们的示例中,我们将使用透视相机(基本上意味着距离越远的东西看起来就越小,就像在现实世界中一样)。在我们的示例中,我们的相机将直接向前看,因此我们将其位置和目标向量设置为它在世界空间中的位置。然后我们应用透视矩阵(gl-matrix 库免费为我们提供了该矩阵)。
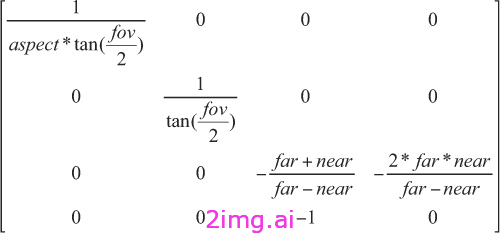
我们需要传入一些相机参数,用于裁剪平面(远和近)、视野和观看者的长宽比。透视矩阵基本上只是沿对角线进行一些奇特的缩放,以补偿我们的梯形视锥体(图中的绿色区域),而对角线外的矩阵则用于压缩 z 维度(因为我们的屏幕是 2D)。结果将应用于我们已有的任何相机变换。
然后我们将 ModelView 矩阵和 Projection 矩阵相乘以获得最终的 ModelViewProjection 矩阵。
WebGPU查看器
现在我们要建立一个类来封装一些 WebGPU 操作,使我们的查看器不那么混乱。
export class WebGPUViewer {
private _device: GPUDevice | undefined;
private _context: GPUCanvasContext | undefined;
private _format: GPUTextureFormat | undefined;
private _renderPipeline: GPURenderPipeline | undefined;
private _size: { width: number; height: number; } | undefined;
private readonly _vertexBuffers: GPUVertexBufferLayout[] | undefined;
private readonly _fragShader: string;
private readonly _vertShader: string;
private readonly _withDepth: boolean;
private constructor(vertShader: string, fragShader: string, withDepth: boolean, vertexBuffers?: GPUVertexBufferLayout[]) {
this._vertShader = vertShader;
this._fragShader = fragShader;
this._withDepth = withDepth;
this._vertexBuffers = vertexBuffers;
}
public static async init(canvas: HTMLCanvasElement, vertShader: string, fragShader: string, withDepth: boolean, vertexBuffers?: GPUVertexBufferLayout[]): Promise<WebGPUViewer> {
const webGPUViewer: WebGPUViewer = new WebGPUViewer(vertShader, fragShader, withDepth, vertexBuffers);
await webGPUViewer._initWebGpu(canvas);
await webGPUViewer._initRenderPipeline();
return webGPUViewer;
}
get size(): { width: number; height: number } | undefined {
return this._size;
}
public createBindGroup(buffers: GPUBuffer[]): GPUBindGroup | undefined {
if (!this._device || !this._renderPipeline) { return }
return this._device.createBindGroup({
entries: buffers.map((buffer, index) => {
return {
binding: index,
resource: {
buffer: buffer
}
}
}),
layout: this._renderPipeline.getBindGroupLayout(0)
})
}
public createBuffer(data: Float32Array, usage: number): GPUBuffer | undefined {
if (!this._device) { return }
const buffer = this._device.createBuffer({
size: data.byteLength,
usage: usage,
});
this._device.queue.writeBuffer(buffer, 0, data);
return buffer;
}
public writeToBuffer(buffer: GPUBuffer, data: Float32Array) {
if (!this._device) { return }
this._device.queue.writeBuffer(buffer, 0, data);
}
public draw(numVertices: number, vertexBuffer?: GPUBuffer, bindGroup?: GPUBindGroup) {
if (!this._device || !this._context || !this._renderPipeline) {return}
const commandEncoder = this._device.createCommandEncoder();
const view = this._context.getCurrentTexture().createView();
const colorAttachment: GPURenderPassColorAttachment = {
loadOp: "load",
storeOp: "store",
view: view,
clearValue: {r: 0, g: 0, b: 0, a: 1}
}
const renderPassDescriptor: GPURenderPassDescriptor = {
colorAttachments: [
colorAttachment
],
}
if (this._withDepth && this._size) {
const depthTexture = this._device.createTexture({
size: this._size,
format: 'depth24plus',
usage: GPUTextureUsage.RENDER_ATTACHMENT,
})
const depthView = depthTexture.createView()
renderPassDescriptor.depthStencilAttachment = {
view: depthView,
depthClearValue: 1.0,
depthLoadOp: 'clear',
depthStoreOp: 'store',
}
}
const renderPassEncoder = commandEncoder.beginRenderPass(renderPassDescriptor);
renderPassEncoder.setPipeline(this._renderPipeline);
if (vertexBuffer) {
renderPassEncoder.setVertexBuffer(0, vertexBuffer);
}
if (bindGroup) {
renderPassEncoder.setBindGroup(0, bindGroup);
}
renderPassEncoder.draw(numVertices);
renderPassEncoder.end();
this._device.queue.submit([commandEncoder.finish()]);
}
private async _initWebGpu(canvas: HTMLCanvasElement) {
if (!navigator.gpu) {
throw new Error("GPU not enabled");
}
const adapter = await navigator.gpu.requestAdapter({
powerPreference: "high-performance"
});
if (!adapter) {
throw new Error("Could not get adapter");
}
this._device = await adapter.requestDevice();
this._format = navigator.gpu.getPreferredCanvasFormat();
this._context = canvas.getContext("webgpu") as GPUCanvasContext;
const devicePixelRatio = window.devicePixelRatio || 1;
canvas.height = canvas.clientHeight * devicePixelRatio;
canvas.width = canvas.clientWidth * devicePixelRatio;
this._size = {width: canvas.width, height: canvas.height};
this._context.configure({
device: this._device,
format: this._format,
alphaMode: "opaque"
});
}
private async _initRenderPipeline(): Promise<GPURenderPipeline | undefined> {
if (!this._device || !this._format) {return}
const descriptor: GPURenderPipelineDescriptor = {
layout: 'auto',
vertex: {
module: this._device.createShaderModule({
code: this._vertShader
}),
entryPoint: 'main',
buffers: this._vertexBuffers
},
primitive: {
topology: 'triangle-list'
},
fragment: {
module: this._device.createShaderModule({
code: this._fragShader
}),
entryPoint: 'main',
targets: [
{
format: this._format
}
]
}
}
if (this._withDepth) {
descriptor.depthStencil = {
depthWriteEnabled: true,
depthCompare: 'less',
format: 'depth24plus',
}
}
this._renderPipeline = await this._device.createRenderPipelineAsync(descriptor);
}
}让我们从 init 函数和构造函数开始逐一分解代码。
初始化
private constructor(vertShader: string, fragShader: string, withDepth: boolean, vertexBuffers?: GPUVertexBufferLayout[]) {
this._vertShader = vertShader;
this._fragShader = fragShader;
this._withDepth = withDepth;
this._vertexBuffers = vertexBuffers;
}
public static async init(canvas: HTMLCanvasElement, vertShader: string, fragShader: string, withDepth: boolean, vertexBuffers?: GPUVertexBufferLayout[]): Promise<WebGPUViewer> {
const webGPUViewer: WebGPUViewer = new WebGPUViewer(vertShader, fragShader, withDepth, vertexBuffers);
await webGPUViewer._initWebGpu(canvas);
await webGPUViewer._initRenderPipeline();
return webGPUViewer;
}init 函数创建一个新的 WebGPUViewer,初始化其 WebGPU 并设置我们的渲染管道,然后返回 WebGPUViewer 实例。
_initWebGPU
这是我们在构造过程中调用的第一个设置函数。
private async _initWebGpu(canvas: HTMLCanvasElement) {
if (!navigator.gpu) {
throw new Error("GPU not enabled");
}
const adapter = await navigator.gpu.requestAdapter({
powerPreference: "high-performance"
});
if (!adapter) {
throw new Error("Could not get adapter");
}
this._device = await adapter.requestDevice();
this._format = navigator.gpu.getPreferredCanvasFormat();
this._context = canvas.getContext("webgpu") as GPUCanvasContext;
const devicePixelRatio = window.devicePixelRatio || 1;
canvas.height = canvas.clientHeight * devicePixelRatio;
canvas.width = canvas.clientWidth * devicePixelRatio;
this._size = {width: canvas.width, height: canvas.height};
this._context.configure({
device: this._device,
format: this._format,
alphaMode: "opaque"
});
}我们首先检查客户端上是否启用了 WebGPU(很多浏览器都不支持https://caniuse.com/webgpu)。然后我们请求一个适配器,它就像一个虚拟 GPU 设备接口,让我们可以请求并获取实际的 GPU 设备。我们使用提供的画布来获取大小和首选的画布格式——rgba8unorm或者bgra8unorm只是告诉我们读取 f32 的顺序,norm 部分表示值是标准化的(介于 0.0 和 1.0 之间)。
_initRenderPipeline
private async _initRenderPipeline(): Promise<GPURenderPipeline | undefined> {
if (!this._device || !this._format) {return}
const descriptor: GPURenderPipelineDescriptor = {
layout: 'auto',
vertex: {
module: this._device.createShaderModule({
code: this._vertShader
}),
entryPoint: 'main',
buffers: this._vertexBuffers
},
primitive: {
topology: 'triangle-list' // try point-list, line-list, line-strip, triangle-strip
},
fragment: {
module: this._device.createShaderModule({
code: this._fragShader
}),
entryPoint: 'main',
targets: [
{
format: this._format
}
]
}
}
if (this._withDepth) {
descriptor.depthStencil = {
depthWriteEnabled: true,
depthCompare: 'less',
format: 'depth24plus',
}
}
this._renderPipeline = await this._device.createRenderPipelineAsync(descriptor);
} 接下来我们初始化管道本身,我们创建一个描述符,它使用我们的 GPU 设备和片段和顶点着色器字符串,我们在构造时传入这些字符串来创建 ShaderModules。
顶点部分将采用我们的顶点着色器,它将告诉我们将顶点放在哪里,以及一个包含所有顶点的 f32 数组的缓冲区。
原始部分包含一个拓扑字段,告诉我们应如何解释顶点。我们使用三角形列表,以便它期望每个连续的三个顶点集都是一个三角形。
我们的片段着色器将告诉我们如何为屏幕着色的格式,还将告诉我们如何为屏幕上的每个像素着色。
最后,我们创建一个深度模板,它告诉 GPU 哪些片段应该根据其深度实际绘制到屏幕上(即,其他像素“后面”的像素将不会被绘制)。
一旦我们设置了描述符,我们就可以创建渲染管道。
createBuffer 和 writeToBuffer
现在我们已经设置好了管道,但在运行任何程序之前,我们必须将一些数据传递给 GPU,以便 GPU 可以引用这些数据。缓冲区是我们向 CPU 和 GPU 之间传递数据的方式。我们的写入和创建缓冲区方法将让我们能够将数据从 CPU 传递到 GPU。
public createBuffer(data: Float32Array, usage: number): GPUBuffer | undefined {
if (!this._device) { return }
const buffer = this._device.createBuffer({
size: data.byteLength,
usage: usage,
});
this._device.queue.writeBuffer(buffer, 0, data);
return buffer;
}
public writeToBuffer(buffer: GPUBuffer, data: Float32Array) {
if (!this._device) { return }
this._device.queue.writeBuffer(buffer, 0, data);
}createBuffer 接收缓冲区的大小(以字节为单位)以及其用途(即写入数据或读取数据)。如果我们成功创建缓冲区,我们将它返回给调用者。
然后调用者可以 writeToBuffer 并传入他们创建的缓冲区和一些要写入的数据。device.queue.writeToBuffer 接受要写入的缓冲区、开始写入的位置的字节偏移量以及要写入的数据。
创建绑定组
创建缓冲区是不够的,我们需要赋予它某种标识,以便我们的 GPU 可以访问它,这就是绑定组发挥作用的地方。
public createBindGroup(buffers: GPUBuffer[]): GPUBindGroup | undefined {
if (!this._device || !this._renderPipeline) { return }
return this._device.createBindGroup({
entries: buffers.map((buffer, index) => {
return {
binding: index,
resource: {
buffer: buffer
}
}
}),
layout: this._renderPipeline.getBindGroupLayout(0)
})
} 我们获取要添加到组中的缓冲区列表,然后使用 GPU 设备创建一个包含所有缓冲区的绑定组。我们在此示例中使用 bindGroupLayout 0,如果您想创建多个绑定组,我们将更改此值。
我们的 WGSL 代码现在可以通过其绑定组引用我们的缓冲区,如@group(0) @binding({index})。
画
最后,我们可以运行绘制立方体。
public draw(numVertices: number, vertexBuffer?: GPUBuffer, bindGroup?: GPUBindGroup) {
if (!this._device || !this._context || !this._renderPipeline) {return}
const commandEncoder = this._device.createCommandEncoder();
const view = this._context.getCurrentTexture().createView();
const colorAttachment: GPURenderPassColorAttachment = {
loadOp: "load",
storeOp: "store",
view: view,
clearValue: {r: 0, g: 0, b: 0, a: 1}
}
const renderPassDescriptor: GPURenderPassDescriptor = {
colorAttachments: [
colorAttachment
],
}
if (this._withDepth && this._size) {
const depthTexture = this._device.createTexture({
size: this._size,
format: 'depth24plus',
usage: GPUTextureUsage.RENDER_ATTACHMENT,
})
const depthView = depthTexture.createView()
renderPassDescriptor.depthStencilAttachment = {
view: depthView,
depthClearValue: 1.0,
depthLoadOp: 'clear',
depthStoreOp: 'store',
}
}
const renderPassEncoder = commandEncoder.beginRenderPass(renderPassDescriptor);
renderPassEncoder.setPipeline(this._renderPipeline);
if (vertexBuffer) {
renderPassEncoder.setVertexBuffer(0, vertexBuffer);
}
if (bindGroup) {
renderPassEncoder.setBindGroup(0, bindGroup);
}
renderPassEncoder.draw(numVertices);
renderPassEncoder.end();
this._device.queue.submit([commandEncoder.finish()]);
} 我们传入我们的bindGroup(绑定组)、顶点的数量以及要绘制的顶点缓冲区。
我们将要执行的操作写入一个commandEncoder,然后这些命令在该函数结束时提交给GPU执行。
每次绘制之前,我们都会用全白值清除屏幕。然后,我们创建像素要使用的深度纹理。最后,我们传入顶点缓冲区并绑定组,然后将顶点绘制到屏幕上。
查看器 (App.tsx)
现在让我们看一下将使用新类别的查看器。
import {useEffect, useRef} from "react";
import {WebGPUViewer} from "./WebGPUViewer";
import {positionVert} from "./shaders/verts";
import {colorFrag} from "./shaders/frags";
import {vertex as cubeVert, vertexCount as cubeCount} from "./shapes/cube";
import {getMvpMatrix} from "./math";
export const App = () => {
const canvasRef = useRef<HTMLCanvasElement | null>(null);
const setUpViewer = async () => {
const positionAttribute: GPUVertexAttribute = {
//position xyz
shaderLocation: 0,
offset: 0,
format: "float32x3"
};
const vertexBuffer: GPUVertexBufferLayout = {
arrayStride: 3 * 4, // 3 float32,
attributes: [
positionAttribute
]
}
const vertex = cubeVert;
const webGPUViewer: WebGPUViewer = await WebGPUViewer.init(canvasRef.current!, positionVert, colorFrag, true,[vertexBuffer]);
const vertexGPUBuffer: GPUBuffer = webGPUViewer.createBuffer(vertex, GPUBufferUsage.VERTEX | GPUBufferUsage.COPY_DST)!;
const color = new Float32Array([0, 1, 0, 1]);
const colorGPUBuffer: GPUBuffer = webGPUViewer.createBuffer(color, GPUBufferUsage.UNIFORM | GPUBufferUsage.COPY_DST)!;
let aspect = webGPUViewer.size!.width / webGPUViewer.size!.height;
const position = {x:0, y:0, z: -5}
const scale = {x:1, y:1, z:1}
const rotation = {x: 0, y: 0, z:0}
const mvp = getMvpMatrix(aspect, position, rotation, scale);
const mvpGPUBuffer: GPUBuffer = webGPUViewer.createBuffer(mvp, GPUBufferUsage.UNIFORM | GPUBufferUsage.COPY_DST)!;
const bindGroup: GPUBindGroup = webGPUViewer.createBindGroup([colorGPUBuffer, mvpGPUBuffer])!;
let multiplier = 1;
const frame = () => {
rotation.x += 0.005;
rotation.z += 0.005;
webGPUViewer.writeToBuffer(mvpGPUBuffer, getMvpMatrix(aspect, position, rotation, scale));
color[0] += 0.005 * multiplier;
if (color[0] > 1 || color[0] < 0) {
multiplier *= -1;
color[0] = Math.min(1, Math.max(0, color[0]));
}
webGPUViewer.writeToBuffer(colorGPUBuffer, color);
webGPUViewer.draw(cubeCount, vertexGPUBuffer, bindGroup);
requestAnimationFrame(frame)
}
frame();
}
useEffect(() => {
if (!canvasRef.current) {
return;
}
setUpViewer();
}, [])
return (
<canvas ref={canvasRef} style={{width: "100%", height: "100%"}}/>
);
}首先,我们创建顶点缓冲区布局,告诉 GPU 顶点数据将包含一个 float32x3 的位置数据,并提供一个字节步长,表示每个顶点为三个 float32(3 x 4)。我们创建 WebGPUViewer 实例并将实际顶点数据加载到缓冲区中。
我们创建一个只包含绿色的颜色缓冲区(目前)。
我们为立方体赋予默认比例和旋转,并将其推送到屏幕的五个单位,我们使用纵横比(来自画布)以及立方体的位置、旋转和比例来获取 ModelViewProjection 矩阵,该矩阵将立方体中的顶点从其局部坐标转移到屏幕空间。
我们将颜色和 MVP 矩阵放入绑定组,并将其添加到 GPU 中。
我们使用 requestAnimationFrame 以环境的原生帧速率调用我们的帧函数。在帧中,我们稍微旋转立方体 — 并更新 MVP 矩阵。我们还更新 r 通道以使颜色在 0 和 1 之间振荡(因此我们的立方体将从绿色变为黄色,然后变回绿色)。这是我们调用 draw 函数的地方,最后我们递归调用 requestAnimationFrame 以在环境准备就绪时再次运行帧。
着色器
着色器让我们可以将自定义代码注入到下面显示的 GPU 管道中。我们将使用两种类型:Vertex(用于在屏幕空间中排列顶点)和 Fragment(用于绘制像素)。
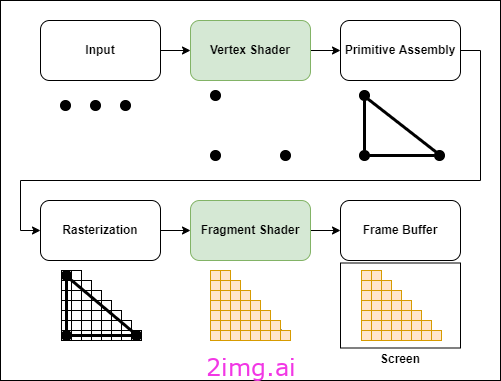
现在让我们看一下着色器。为了导出为字符串,我将着色器的内容放在 .ts 文件中,然后像这样导出内容。
export const redFrag: string = "@fragment\n" +
"fn main() -> @location(0) vec4<f32> {\n" +
" return vec4<f32>(1.0, 0.0, 0.0, 1.0);\n" +
"}\n";为了在本教程中实际展示着色器代码,我将把它们放在 .wgsl 文件中。
顶点着色器
我们的顶点着色器首先出现,并告诉我们如何将顶点放置在屏幕上(这是 MVP 矩阵的用武之地)。
@group(0) @binding(1) var<uniform> mvpMatrix : mat4x4<f32>;
struct VertexOutput {
@builtin(position) Position : vec4<f32>,
@location(0) fragPosition: vec4<f32>
};
@vertex
fn main(@location(0) position : vec3<f32>) -> VertexOutput {
var output : VertexOutput;
output.Position = mvpMatrix * vec4<f32>(position, 1.0);
output.fragPosition = vec4<f32>(position, 1.0);
return output;
}我们将定义一个 vertexOutput 结构,它将具有两个 vec4,用于表示顶点位置,这些顶点位置将传达给汇编器和光栅化器,而 fragPosition 是我们应用 MVP 矩阵变换之前的原始位置,因此我们的片段着色器可以为我们的模型着色相同的颜色,而不管相机的移动或立方体上的变换如何。
我们从绑定组中获取 MVP 矩阵并相应地构建输出。
片段着色器
@group(0) @binding(0) var<uniform> color : vec4<f32>;
@fragment
fn main(@location(0) fragPosition: vec4<f32>) -> @location(0) vec4<f32> {
return (color + fragPosition) * 0.5;
}我们的片段着色器从顶点获取光栅化结果和任何绑定组数据的值,并使用它们绘制屏幕。颜色缓冲区对于所有像素都是相同的(这就是它被称为统一的原因),fragPosition 是一个变化的值,它通过使用重心坐标在封闭顶点之间进行插值来确定,重心坐标通过使用用 P 替换 V 的三角形面积来确定 P 与顶点 V 的距离。
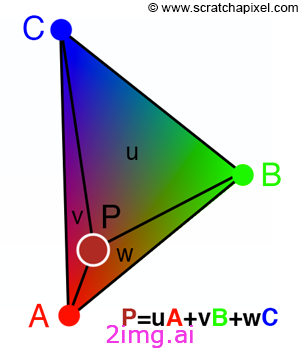
在我们的示例中,我们一半根据顶点的位置为像素着色,另一半使用振荡色调颜色。
结论
完成本教程后,您应该对 WebGPU API 和着色器的工作原理以及使用 WebGPU 渲染 3D 场景所需的过程有充分的了解。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/6222