
是什么让 RAG 系统真正成为顶级系统呢?是组件吗?让我们来看看最好的组件以及它们的工作原理,这样您也可以让您的 RAG 系统成为顶级系统,并获得多模态奖励。
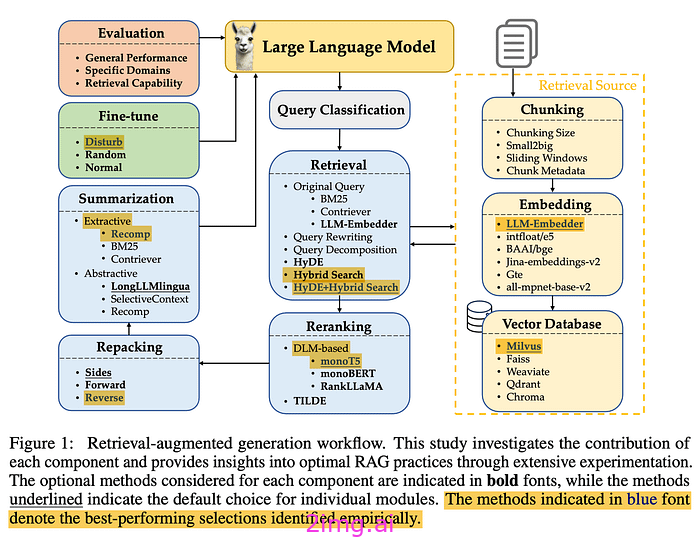

查询分类
让我们从查询分类开始。并非所有查询都是平等的——有些查询甚至不需要检索,因为大型语言模型已经知道答案。例如,如果你问“梅西是谁?”,法学硕士就能帮你回答。无需检索!
Wang 等人创建了 15 个任务类别,确定查询是否提供了足够的信息或是否需要检索。他们训练了一个二元分类器来区分任务,将不需要检索的标记为“足够”,将需要检索的标记为“不足”。在这张图片中,黄色表示不需要,红色表示去获取一些文档!
分块
接下来是分块。这里的挑战是找到适合您数据的完美块大小。太长?您会增加不必要的噪音和成本。太短?您会错过上下文。

Wang 等人发现,块大小在 256 到 512 个标记之间效果最好。但请记住,这会因数据而异 — 因此请务必进行评估!专业提示:使用small2big(从小块开始搜索,然后移动到较大的块进行生成),或尝试滑动窗口在块之间重叠标记。
元数据和混合搜索
利用您的元数据!添加标题、关键词甚至假设问题等内容。将其与混合搜索相结合,后者结合了向量搜索(用于语义匹配)和用于传统关键词搜索的 BM25,您就成功了。
HyDE(生成伪文档以增强检索)很酷,可以带来更好的结果,但效率极低。目前,请继续使用混合搜索 – 它能实现更好的平衡,尤其是对于原型设计而言。
嵌入模型
选择正确的嵌入模型就像找到一双完美的鞋子。你不会想要一双用来打网球的足球鞋。FlagEmbedding的LLM-Embedder最适合这项研究——性能和尺寸的平衡性很好。不是太大,也不是太小——正好合适。
请注意,他们只测试了开源模型,因此 Cohere 和 OpenAI 被排除在外。否则,Cohere 可能是你最好的选择。
矢量数据库

现在来看看数据库。对于长期使用,Milvus是他们的首选矢量数据库。它是开源的、可靠的,是让您的检索系统顺利运行的绝佳选择。我也在下面的描述中链接了它。
查询转换
在检索之前,您必须转换这些用户查询!无论是通过查询重写来提高清晰度,还是通过查询分解将复杂问题分解为较小的问题并检索每个子问题,甚至生成伪文档(如HyDE 所做的那样)并在检索过程中使用它们——这一步对于提高准确性至关重要。请记住,更多的转换会增加延迟,尤其是 HyDE。
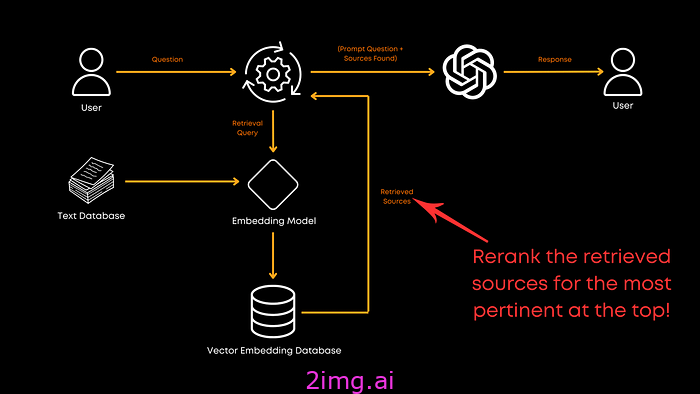
重新排名
现在我们来谈谈重新排序。检索文档后,您需要确保最相关的文档位于最顶部。这就是重新排序的作用所在。
在这项研究中,monoT5脱颖而出,成为平衡性能和效率的最佳选择。它对 T5 模型进行了微调,根据文档与查询的相关性对文档进行重新排序,确保最佳匹配优先。RankLLaMA总体上表现最佳,但TILDEv2速度最快。如果您有兴趣,论文中还有更多关于每个模型的信息。
文件重新包装
重新排序后,您需要进行一些文档重新打包。Wang 等人推荐“反向”方法,即按相关性升序排列文档。Liu等人 (2024)发现这种方法(将相关信息放在开头或结尾)可以提高性能。重新打包优化了在重新排序过程发生后向 LLM 呈现信息以供生成的方式,以帮助 LLM 以更好的顺序(而不是理论上的相关顺序)更好地理解所提供的信息。
总结
然后,在打电话给 LLM 之前,你需要用Summarization来删减多余的内容。发送给 LLM 的长篇提示很昂贵,而且往往是不必要的。Summarization 将有助于删除冗余或不必要的信息并降低成本。
使用Recomp等工具进行提取压缩以选择有用的句子,并使用抽象压缩来合成来自多个文档的信息。但是,如果您优先考虑速度,您可以考虑跳过此步骤。
微调生成器
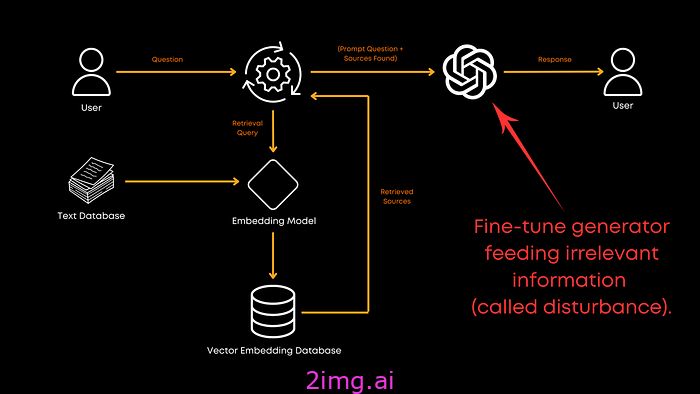
最后,您是否应该对用于生成的LLM 进行微调?当然!使用相关和随机文档的混合进行微调可以提高生成器处理不相关信息的能力。它使模型更加健壮,并有助于它整体上提供更好的响应。论文中没有提供确切的比例,但结果很明显:微调是值得的!不过,这显然也取决于您的领域。
多模态
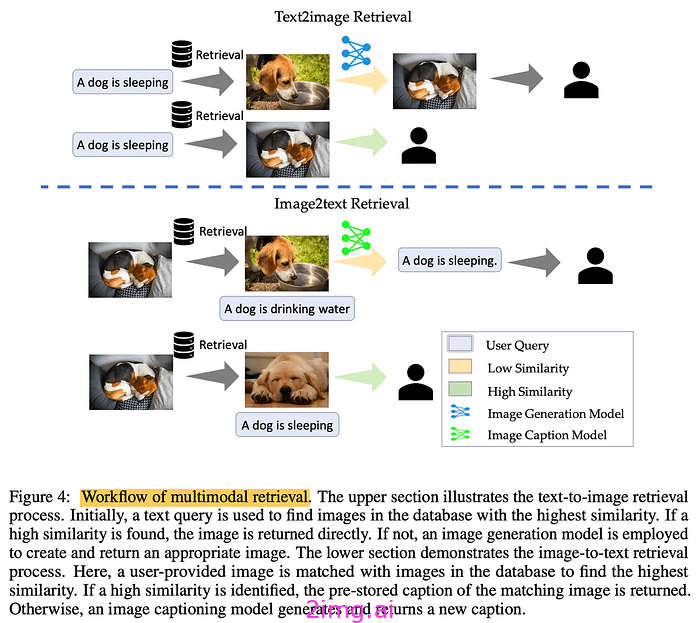
处理图像?实施多模态检索。对于文本转图像,查询数据库中的类似图像可加快该过程。在图像转文本中,匹配类似图像可检索准确的预存字幕。一切都与基础有关 — 检索真实、经过验证的信息。
结论
简而言之,Wang 等人的这篇论文为我们提供了构建高效 RAG 系统的可靠蓝图。但请记住,这只是一篇论文,并未涵盖 RAG 流程的各个方面。例如,检索器和生成器的联合训练尚未探索,这可能会释放更多潜力。由于成本原因,他们也没有深入研究分块技术,但这是一个值得探索的方向。
我强烈建议您查看完整论文以获取更多信息。我们最近还发布了我们的书“为生产构建 LLM ”,其中充满了 RAG 和微调见解、技巧和实际示例,可帮助您构建和改进基于 LLM 的系统。实体书和电子书版本的链接也在下面描述中。
一如既往,感谢您的阅读。如果您觉得本分析有用或有任何意见,请在下方评论中告诉我,我们下期再见!
参考
构建用于生产的 LLM:https://amzn.to/4bqYU9b
Wang 等人,2024 年(论文参考):https://arxiv.org/abs/2407.01219
LLM-Embedder(嵌入模型):https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/llm_embedder
Milvus(矢量数据库):https://milvus.io/
Liu 等人,2024(文档重新打包):https://arxiv.org/abs/2307.03172
Recomp(摘要工具):https://github.com/carriex/recomp
RA/SD 衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/6027