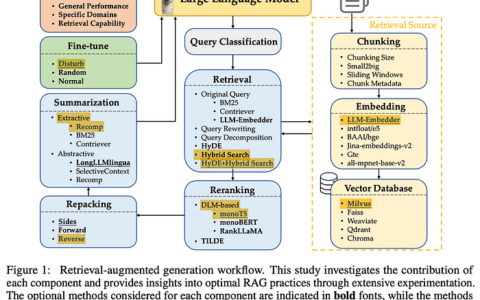
在审判阶段的法律案件中,事实裁定者(无论是法官、陪审团还是行政法庭)的任务是评估证据的证明价值并得出关于事实的结论。但法庭执行该任务的方法是什么?法庭采用多少种方法?任何类型的事实调查机构至少有三个典型阶段。
首先,事实裁定者必须确定哪些现有证据与决定哪些事实问题相关。如果某项证据倾向于使事实命题比没有该证据时更有可能或更不可能成立,则该证据与证明事实命题相关。
其次,对于每个问题和相关证据,事实裁定者必须评估每项证据的可信度。一个人可能会使用各种标准来评估证人证词的可信度、文件内容的可信度或物证的证明价值。确定法庭在评估特定证据的可信度或可信度时倾向于使用哪些因素将很有用。此外,我们能否确定这些因素中的优先次序?
第三,事实裁定者需要权衡相互矛盾的证据。一个人需要权衡不一致但可信的证据,然后确定所有相关证据的净证明力。解决两个不同证人证词之间的冲突,或同一证人在不同时间的证词之间的冲突,可能有不同的方法。或者,在不同文件中的陈述之间,或在证词和书面陈述之间做出决定,可能有不同的方法。我们能否确定进行此类比较的模式或“软规则”?
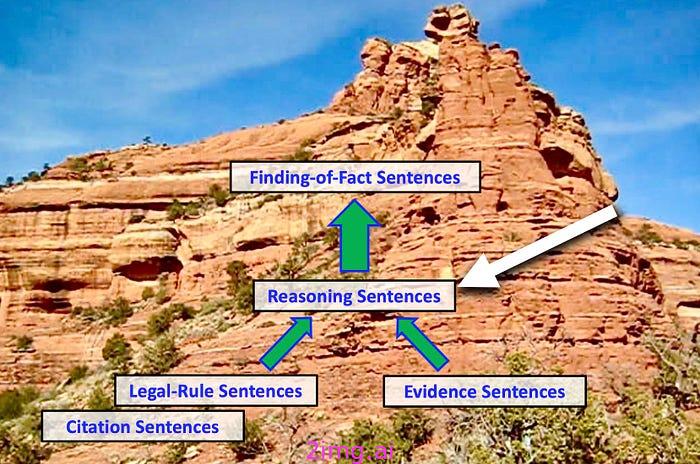
法律判决中发现的一种特殊句子类型为此类问题的答案提供了重要线索。一份写得好的法律判决至少明确陈述了决策者的部分中间推理链。陈述其证据推理的句子尤为重要——我将其称为“推理句子”。
在本文中,我将讨论此类推理句的显著特征和实用性。我还将讨论使机器学习 (ML) 模型能够自动标记法律决策文件中的推理句的语言特征。我将讨论为什么这些模型的性能取决于用例,以及为什么即使是基本的 ML 模型也适合这项任务。最后,我将推理句定位在使用生成式 AI 和大型语言模型来解决论证挖掘挑战的更广泛任务中。
推理句的特点和用处
在事实调查法律裁决中,证据推理陈述解释了证据和法律规则如何支持事实调查结果。因此,推理句是法庭的陈述,描述了这些事实调查结果背后的部分推理。以下句子是退伍军人上诉委员会(BVA) 在申请与服务相关的残疾福利时做出的事实调查裁决中的一个例子:
此外,临床医生的病因意见基于其内部一致性及其提供真实意见的职责而可信。
在其他文章中,我讨论了证据句、法律规则句和发现句。从推理的角度来说,证据和法律规则起前提的作用,而事实发现起结论的作用。你也可以将推理句视为前提,因为它们解释了证据的证明价值。
对于案件中的律师和当事人,推理句提供了关于一方基于证据的论证为何成功或失败的正式解释。当事人有权要求法庭坚持其陈述的理由。当事人的律师可以利用这些陈述的理由来帮助提出反对法庭所用逻辑的论据,或提出对该逻辑的额外支持。此类论据可以在审判阶段或上诉时提出。
对于未参与案件的律师,推理语句可以识别法庭在过去案件中采用的证据评估方法,即使这些方法对法庭来说不是具有约束力的先例。如果律师可以收集展示类似问题和证据的过去案件,那么这些案件中使用的推理可以为新的类似案件提供可能的论据。
对于我们这些挖掘法律论据类型的人来说,我们可以根据所使用的推理或论据类型对案件进行分类。此外,如果机器学习算法能够学会识别陈述法庭推理的句子,我们可能能够在非常大的数据集中自动找到类似的案件。
对于监管者或立法者来说,如果从过去的案例中形成了标准的推理模式,他们也许能够将其作为推定编入法规或法令中,以使未来的事实调查更加高效和统一。
法律研究人员和评论员至少可以推荐此类模式作为“软规则”来指导法律推理。
由于所有这些原因,从法律判决中进行论证挖掘的一个重要焦点是识别并学习如何使用陈述判决理由的句子。
推理句的语言特征
在确定哪些判决能够表达法庭的推理时,律师会考虑许多特征。
首先,如果一个句子满足以下一项或多项条件,那么它就更有可能是一个关于推理的句子:
- 明确说明哪些证据与哪些事实问题相关,或缩小被认为与该问题相关的证据范围;
- 包含关于证人的可信度或某项证据的可信度的明确陈述;
- 包含两项证据相互冲突或不一致的陈述;
- 比较两项证据的证明力,或强调哪一项证据比其他证据更重要;或
- 指出证据缺乏、不足或不存在。
第二,推理句必须陈述事实裁定者的推理,而不是其他人的推理。也就是说,我们必须有充分的依据将推理归因于法庭,而不是仅仅是证人给出的推理,或律师或当事人提出的论点。
许多不同的语言特征都可以证明所述推理是决策者所为。有时这些特征就存在于句子本身的内容中。例如,可以证明是决策者所为的短语可能是:董事会认为,或董事会已考虑到。
在其他时候,句子在裁决的段落或章节中的位置足以证明归因于事实裁定者。例如,根据法庭的写作格式,裁决可能包含一个题为“裁决的理由和依据”的部分,或者只是“讨论”或“分析” 。这些部分中的无条件推理句子可能归因于法庭,除非句子本身将推理归因于证人或当事人。
机器学习结果
在我们的实验中,与其他句子类型相比,ML 算法对推理句子进行分类的难度最大。尽管如此,训练有素的模型仍然可以提供关于句子类型的有用预测。我们在霍夫斯特拉法学院的法律、逻辑和技术研究实验室 (LLT Lab)创建的 50 个 BVA 决策数据集上训练了一个逻辑回归模型。该数据集包含预处理后的 5,797 个手动标记的句子,其中 710 个是推理句子。在多类场景中,该模型对推理句子的分类精度为 0.66,召回率为 0.52。我们用后来在相同 BVA 数据集上训练的神经网络 (NN) 模型获得了可比结果,并对 1,846 个句子进行了测试。推理句子的模型精度为 0.66,召回率为 0.51。
人们很容易认为这种机器学习性能太低而无用。在这样做之前,重要的是调查所犯错误的性质,以及在特定用例下错误的实际成本。
实践错误分析
在神经网络模型预测为推理句的 175 个句子中,有 59 个被误分类(准确率 = 0.66)。这里混淆了其他几种类型的句子。在被误分类为推理句的 59 个句子中,有 24 个实际上是证据句,15 个是发现句,11 个是法律规则句。
如果推理句的措辞与所评估的证据、所支持的发现或所适用的法律规则密切相关,这种混淆是可以理解的。证据句也可能使用表示推论的单词或短语,但句子中报告的推论不是事实裁定者的推论,而是证据内容的一部分。
作为假阳性(或精度错误)的一个例子,训练后的 NN 模型错误地将以下内容预测为推理句,而实际上它是证据句(该模型最初分配的背景颜色为绿色,专家审阅者手动将其更改为蓝色)(屏幕截图取自Apprentice Systems 开发的软件应用程序 LA-MPS ):

虽然这是一个证据句,主要叙述了退伍军人事务部 (VA) 审查员报告中反映的调查结果,但 NN 模型将该句子归类为陈述法庭本身的推理,部分原因可能是因为出现了“董事会注意到”这句话。然而,该模型的预测分数表明,混淆相当接近(见下面的句子文本):推理句(53.88%)与证据句(44.92%)。
作为假阴性(或回忆错误)的一个例子,NN 模型将以下句子错误地归类为证据句,而显然它是一个推理句(模型最初分配的背景颜色为蓝色,专家审阅者手动将其更改为绿色):

这句话提到了证据,但这样做是为了解释法庭的推理,即 VA 证据的证明价值超过了私人治疗证据的证明价值。可能的句子角色的预测分数(显示在句子文本下方)表明,NN 模型错误地将其预测为证据句子(分数 = 45.01%),尽管推理句子也获得了相对较高的分数(33.01%)。
事实上,句子的措辞可能会使其真正的分类变得非常模糊,甚至对律师来说也是如此。一个例子是将以下句子归类为法律规则句子还是推理句子:
只要所声称的压力源“与退伍军人服役的情况、条件或困难相符”,就不需要进一步发展或确凿的证据。
考虑到判决中的直接背景,我们手动将此句标记为陈述有关何时需要进一步发展或佐证的法律规则。但此句也包含与案件具体情况中事实裁定者推理一致的措辞。然而,仅根据句子措辞,即使是律师也可能合理地将此句归入任一类别。
分类错误的成本取决于用例和错误类型。为了提取和呈现法律推理的示例,上述精确度和召回率可能对用户来说是可以接受的。精确度为 0.66 意味着每 3 个被预测为推理句子的句子中大约有 2 个被正确预测,而召回率为 0.51 意味着大约一半的实际推理句子被正确检测到。如果高召回率不是必需的,并且目标是对过去的推理进行有益的说明,那么这样的表现可能是可以接受的。
如果将推理句与证据句或法律规则句相混淆,而后者仍包含对案件推理的见解,则错误可能代价特别低。如果用户有兴趣查看可能论点的不同示例,那么归类为推理、证据或法律规则的句子可能仍然是说明性论点模式的一部分。
然而,如果我们的目标是汇编涉及特定推理的论证发生的准确统计数据,那么如此低的精确度和召回率是不可接受的。对于基于从一组决策中抽取的样本的描述性或推理性统计数据,我们的信心会非常低,这些决策中的推理句子是使用此类模型自动标记的。
概括
总之,推理句可以包含有关决策中所采用的论据类型和推理的极其有价值的信息。
首先,它们表明了过去案件中事实裁定者所认识到的推理模式,它们可以暗示未来案件中可能出现的论证模式。我们可以收集类似案件的说明集,研究证据和法律规则的结合使用,并说明它们作为论证的成功或失败。
其次,如果我们从大型数据集中提取一组推理句,我们可以对它们进行调查,以制定评估单个证据的因素列表,并制定比较冲突证据的软规则。
值得注意的是,如果我们的目标是大规模自动论证挖掘,那么识别和提取整个论证就不仅仅依赖于推理句子的分类器。我在其他文章中提出,自动分类器适用于标记证据句子、法律规则句子和查找句子的某些用例。也许在过去的判决中自动标记这些句子类型可以帮助大型语言模型解决论证挖掘中的挑战——即帮助它们总结过去案例中的推理并在新案例中推荐论证。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/6022