


首先,解决问题。然后,编写代码。——约翰·约翰逊
编程并不关乎你知道什么,而是关乎你能弄清楚什么。——克里斯·派恩
大型语言模型已经展现出令人难以置信的能力。最大的公司一直在忙于研究提高这些模型能力的最佳方法。第一个想法是增加参数的数量(所谓的缩放定律)。后来我们意识到数据的重要性,用于训练模型的 token 数量越多,模型最终的性能就越好。最后,我们意识到影响性能的不仅仅是数据的数量,数据的质量也很重要。事实上,数据不仅要有质量,还要多样化。举个例子,数据多样性对于模型中最理想的行为之一——情境学习的出现非常重要。
变形金刚安魂曲?
Transformer 会成为引领我们走向通用人工智能的模型吗?还是会被取代?
您需要了解的有关情境学习的所有信息
大型语言模型是什么?它是如何工作的?是什么让大型语言模型如此强大
数据质量和多样性的定义是通用的。因此出现了一个问题:
数据的哪些特性能够带来最佳的总体性能?
例如,代码也包含在预训练数据中,但模型并未经过明确训练以生成代码。一方面,LLM 需要理解代码的能力,另一方面,代码在结构和纹理特征方面与高质量网络数据集不同。这可能会影响 LLM 的训练。
现代模型需要使用越来越多的代码进行训练。近年来,预训练数据集中的代码量成比例增加。一些研究表明,插入代码对训练有益。事实上,添加代码似乎在可扩展性和数学推理方面有好处
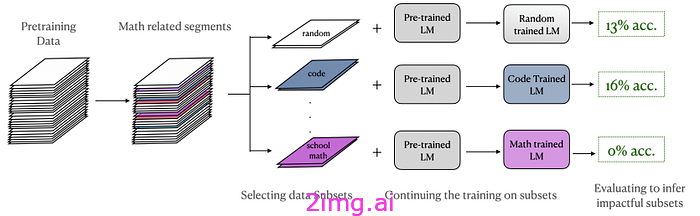
然而,由于缺乏系统的研究,因此仍存在一些悬而未决的问题:
- 代码对预训练有什么影响?
- 比例应该是多少?
- 缩放有何影响?
- 代码有什么影响?
这项新发表的研究试图回答这些问题。
编码还是不编码?探索编码在预训练中的影响
即使对于不是专门为代码设计的模型,在预训练数据混合中包含代码也已成为……
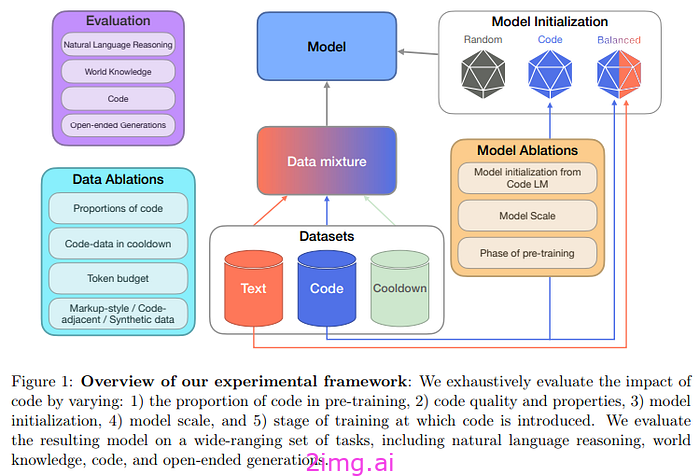
本研究的作者在两种条件下测试了模型:
- 持续预训练。由预训练模型启动,然后用固定数量的 token 进行训练的模型。
- cooldown。在训练结束时,添加高质量的数据集,并在短时间内改变学习率。这种方法表明它可以提升模型的能力。
作者使用高质量的文本数据集(SlimPajama),并清除其中的代码和代码相邻的数据源(例如 StackExchange),以便他们可以决定添加多少代码。
作为代码数据集,他们使用:
- 基于 Web 的代码数据。StarCoder 是通过抓取 GitHub 获得的经过清理的数据数据集。
- Markdown 数据、markdown 中的数据以及与代码相关的 HTML 格式。
- 涉及 Python 中的编程问题的高质量合成代码(并且已经过验证)。
- 代码相关数据,包括 GitHub 提交、jupyter 笔记本、StackExchange 线程
然后,他们决定评估训练后的模型在世界知识、自然语言推理和代码性能方面的表现。他们还使用LLM作为评判标准,来评判使用各种代码组合训练的模型。

作者使用 470M 和 2.8B 参数仅解码器自回归Transformer作为模型。
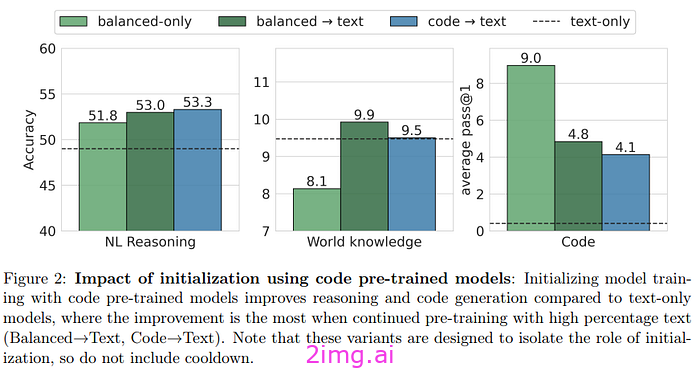
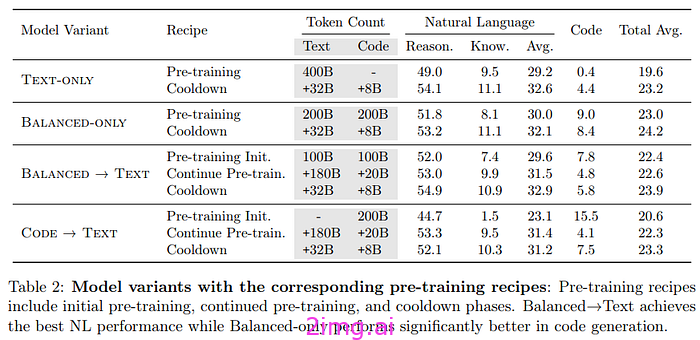
作者首先比较了不同的模型初始化:文本 LM(仅使用文本训练的模型)、平衡 LLM(使用 50% 文本和 50% 代码训练的模型)、平衡初始化文本 LM(首先是平衡系统,然后是纯文本)和代码初始化文本 LM(使用代码(80% 代码数据和 20% 标记样式代码数据)进行预训练,然后是文本)。所有这些模型都使用 400B 总计标记进行初始化,只有组成发生变化。
结果表明:
- 用代码预训练的模型在自然语言任务中表现更好。对于推理任务尤其如此。对于知识任务,平衡的组成更好。
- 在代码生成任务中,代码显然在预训练中很重要,平衡的模型会做得更好。
- 一个有趣的发现是,平衡的模型可以生成更好的文本(根据LLM评委的说法)
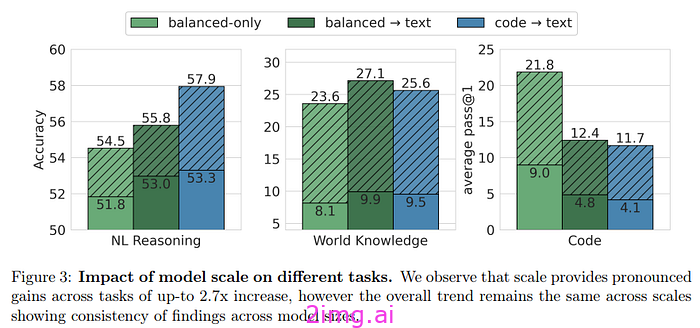
作者还研究了将 4.7 亿模型扩展到 28 亿参数后会发生什么情况:
- 扩展模型显然可以改善自然语言推理和知识任务的结果。
- 它们也证实了之前看到的相同趋势。这两个模型的行为方式相同
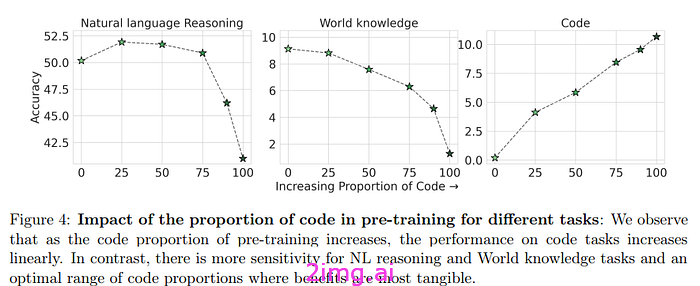
此时,作者会问,在非代码任务上,代码量的最佳值是多少,才能最大限度地提高性能。然后,他们训练了六个模型,在预训练中代码的百分比逐渐增加(0%、25%、50%、75%、90% 和 100%)。
- 增加代码百分比可以提高推理任务的性能;然而,与知识任务存在反比关系。不包括代码会严重影响推理性能。由于推理也需要添加一些文本,因此在代码上经过完全训练的模型性能最差。
- 此外,代码对于必须执行编码任务的模型来说很重要
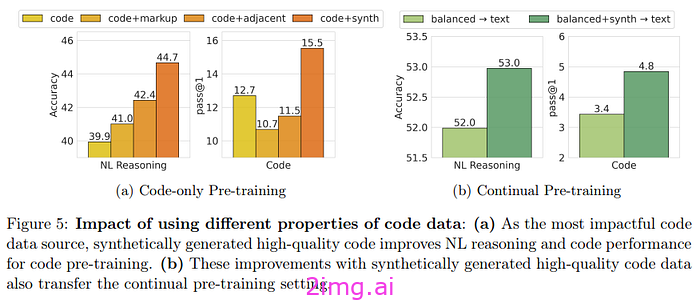
作者希望更好地理解代码在训练中的作用。他们专注于尝试了解代码数据的不同属性的确切影响。其次,了解优质代码(高质量合成代码)是否比通用代码更重要。出于这些原因,他们将标记样式数据(采用标记格式的编程语言)和代码相邻数据与代码分开。结果表明,高质量的合成代码数据,即使比例和预算很小,也会产生很大的影响。这对于编码任务尤其如此,但对于自然语言推理任务也部分如此。
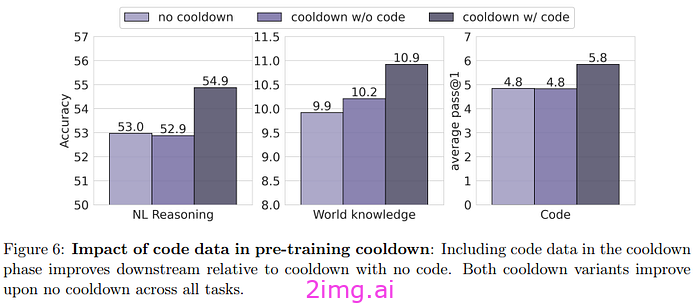
同样,在冷却时间中添加代码也会产生积极的影响。对于作者来说,如果不添加代码(尤其是在推理任务中),冷却时间的积极影响就会降低。冷却时间(即使没有代码)也可以提高法LLM作为法官的生成质量。
作者总结了他们的研究结果:
- 包含代码对模型性能有积极影响。对他们来说,最好的方法是平衡预训练(代码和文本的比例相等,然后对文本进行训练的阶段)和包含高质量文本的冷却阶段。
- 为了使模型在代码上表现最佳,平衡模型似乎是最好的,其次是冷却。
这项研究很有趣,因为它展示了预训练代码的影响。它之所以有趣正是因为它的系统性,并为代码对推理和生成任务的影响提供了一些答案。先前的研究表明,代码的定义和严谨性为生成提供了优势。多年来,培训 LLM 的主要公司购买了收集代码的服务(谷歌收购了 Kaggle,微软收购了 GitHub)。这意味着他们在制作模型方面具有竞争优势。
无论如何,我们需要更多系统性知识,才能了解培养LLM的最佳方法。我们已经了解了规模的重要性,但对于哪些因素会影响培训,仍有许多悬而未决的问题。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/5997