
我们原本热切地等待着 GPT 5 的发布,结果却得到了另一种模型。OpenAI 推出了其新的“ Strawberry ”系列,包括 o1 和 o1-mini 模型,旨在提高解决问题的能力。
它之所以不是 GPT 5,可能是因为它没有在更大规模的数据上进行训练,而且可能与 GPT 4 和 OpenAI 的其他模型具有不同的架构。因此,在今天的博客中,我们将看到这个新模型的情况,它声称在架构变化的情况下具有更好的推理能力。


打破草莓 o1
因此,我没有去探索这个新模型能做什么,而是直接询问模型有什么新功能,下面是它的响应。
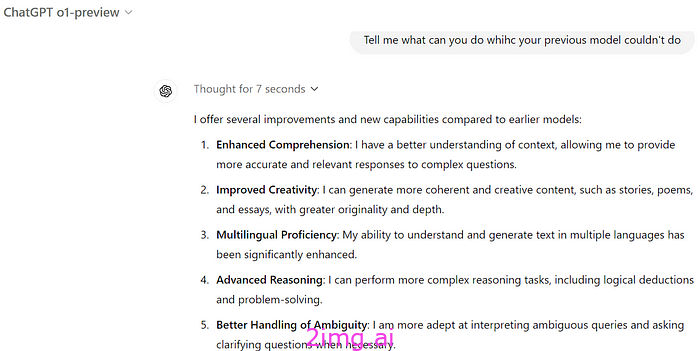
需要明确的是,早期测试人员报告称,o1-preview 并不是在所有方面都做得更好。例如,它并不是比 GPT-4o 更好的编写器。但对于需要规划的任务,变化相当大。
那么,让我们测试一下这个新模型。使用我最喜欢的修改版狼、草和过河的人的例子。
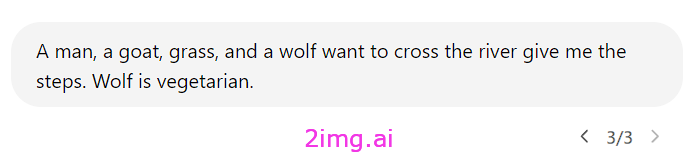
这里我们打破了我们的草莓的推理。

狼是素食主义者,不会吃草。这表明它仍然没有理智,也遭受着同样的问题,但可能程度要轻一些。
这表明,即使这个模型也倾向于给出积极的响应,这与早期模型所显示的问题相同。请不要误会我的意思,我确实认为该模型已经得到了显着改善,但我们不知道改善了多少。
我真的不再相信人工智能基准了。有足够多的研究表明基准存在泄露。
其他人对此有何评价
让我们看看其他人对此有何评论。
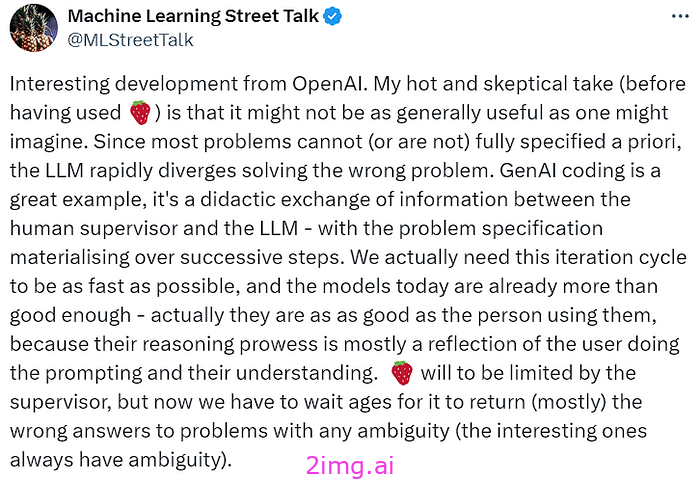


但也有其他方面的争论。有人声称它比普通的博士生更好。好吧,我对此有自己的保留意见。
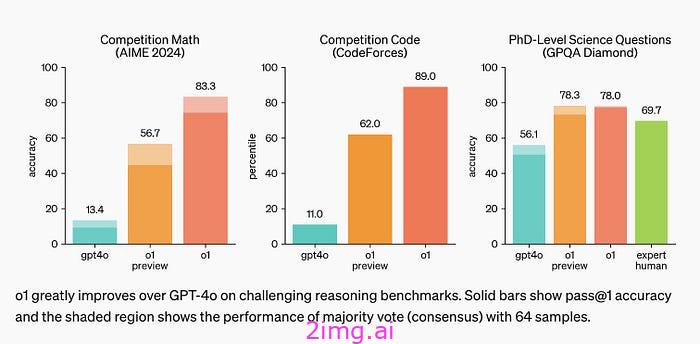
那么,它是 AGI 吗?
让我们直接听听当事人的说法。
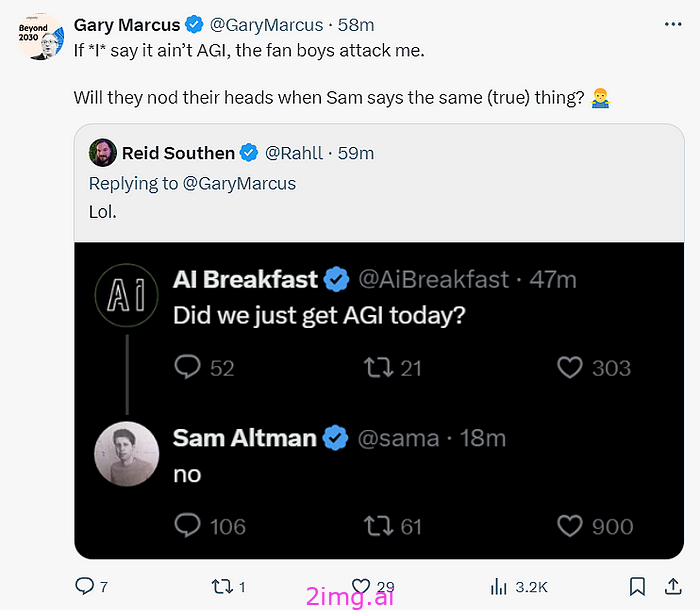

越来越多的猜测
- 它不是 AGI,甚至还差得很远。
- 关于它如何实际工作并没有太多细节,也没有任何关于已进行测试的完整披露。
- 它并未与 GPT-4 的其余部分完全集成。(为什么不呢?)
- 完整的新模型(如图所示)不会向付费用户发布,仅会发布迷你模型和预览模型。因此,申请人必须经过专业培训才能获得学位。
- 从报告来看,它在许多领域都有效,但在某些领域,旧型号实际上更好。
- 改进的程度可能部分取决于特定领域的数据。
- 我们不知道它究竟接受了什么训练,但𝗶𝘁 𝗶𝘀 𝘁𝗲𝗹𝗹𝗶𝗻𝗴 𝘁𝗵𝗮𝘁 𝗲𝘃𝗲𝗻 𝘀𝗼𝗺𝗲 𝗯𝗮𝘀𝗶𝗰 𝘁𝗮𝘀𝗸𝘀 𝗹𝗶𝗸𝗲 𝘁𝗶𝗰-𝘁𝗮𝗰-𝘁𝗼𝗲 𝗮𝗿𝗲 𝘀𝘁𝗶𝗹𝗹非常感谢。
- OpenAI 夸大了他们在法学院考试中取得的明显成功,但仔细检查后,这种成功却黯然失色。仔细的科学审查需要时间。
- 最初的计划是在银石赛道重新开始,但你也会错过奥尔顿公园赛道。最初的计划是在银石赛道重新开始,但你也会错过奥尔顿公园赛道。大多数人不明白这一点。(我还没有看到任何数据表明运行该系统一周与运行一分钟相比有很大差异。)
草莓增强推理能力的秘密

没有人真正知道它是如何训练的,但它可能是这样的。
我们终于看到了推理时间扩展范式的普及和在生产中的部署。正如 Sutton 在《苦涩的教训》中所说,只有两种技术可以无限扩展计算:学习和搜索。
现在是时候将焦点转移到后者了。
- 推理并不需要庞大的模型。许多参数专门用于记忆事实,以便在琐事问答等基准测试中表现良好。可以从知识中分离出推理,即一个知道如何调用浏览器和代码验证器等工具的小型“推理核心”。预训练计算可能会减少。
- 大量计算被转移到推理服务而不是训练前/后。LLM 是基于文本的模拟器。通过在模拟器中推出许多可能的策略和场景,模型最终将收敛到良好的解决方案。这个过程是一个经过充分研究的问题,就像 AlphaGo 的蒙特卡洛树搜索 (MCTS)。
- OpenAI 肯定早就搞清楚了推理扩展定律,而学术界最近才发现这一点。上个月,两篇论文相隔一周在 Arxiv 上发表:— 大型语言猴子:通过重复采样扩展推理计算。Brown 等人发现,DeepSeek-Coder 在 SWE-Bench 上从一个样本的 15.9% 提高到 250 个样本的 56%,击败了 Sonnet-3.5。— 扩展 LLM 测试时间计算的最佳效果可能比扩展模型参数更有效。Snell 等人发现,PaLM 2-S 在测试时间搜索方面击败了 MATH 上 14 倍大的模型。
- 生产 o1 比达到学术基准要困难得多。对于自然推理问题,如何决定何时停止搜索?奖励函数是什么?成功标准是什么?何时在循环中调用代码解释器等工具?如何将这些 CPU 进程的计算成本考虑在内?他们的研究帖子没有分享太多内容。
- Strawberry 很容易成为数据飞轮。如果答案正确,整个搜索轨迹就会变成一个包含正向和负向奖励的训练示例迷你数据集。这反过来又改善了 GPT 未来版本的推理核心,类似于 AlphaGo 的价值网络(用于评估每个棋盘位置的质量)随着 MCTS 生成越来越精细的训练数据而得到改进。
更多结果
它是否让人感觉过度设计了,您觉得呢?
但它应该得到应有的回报。它能够解答填字游戏。

因此,o1-preview 可以做到如果没有 Strawberry 就不可能做到的事情,但它仍然不是完美无缺的:错误和幻觉仍然会发生,并且仍然受到作为底层模型的 GPT-4o 的“智能”的限制。
我还期待什么这类新模型呢?
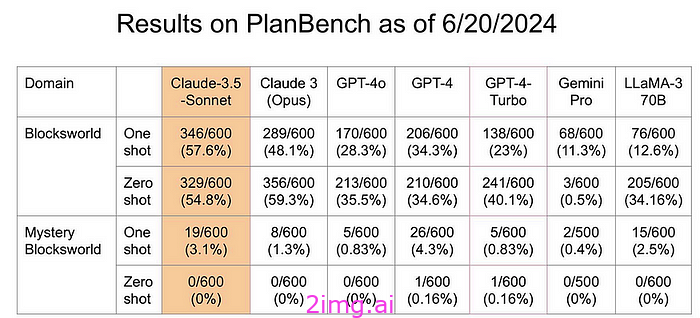
规划的最佳测试之一是神秘方块世界,之前的模型在这项任务中表现相当糟糕。看看这个模型的表现会很有趣。
今天就讲到这里,随着本周的展开,我们将看到更多关于 o1 的功能。请继续关注,我们很快就会介绍可能构成这一新模型类别主干的论文,这些模型在推理时扩展了 LLM。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/5967