
在这篇文章中,我将重点介绍 KG 和 LLM 结合使用的一种流行方式:使用知识图谱的 RAG,有时也称为Graph RAG、GraphRAG、GRAG或Semantic RAG。检索增强生成 (RAG) 是关于检索相关信息以增强发送给 LLM 的提示,然后 LLM会生成响应。我们的想法是,你不必将提示直接发送给未经过数据训练的 LLM,而是可以使用 LLM 准确回答提示所需的相关信息来补充提示。我在上一篇文章中使用的例子是将职位描述和简历复制到 ChatGPT 中以写求职信。如果我向 LLM 提供我的简历和我申请的职位的描述,它就能对我的提示“给我写一封求职信”做出更相关的回应。由于知识图谱是为了存储知识而构建的,因此它们是存储内部数据和为 LLM 提示补充额外上下文的完美方式,从而提高响应的准确性和上下文理解。
重要的是,我认为经常被误解的是,RAG 和使用 KG 的 RAG(Graph RAG)是结合技术的方法,而不是产品或技术本身。没有人发明、拥有或垄断 Graph RAG。然而,大多数人都能看到这两种技术结合起来的潜力,而且越来越多的研究证明了结合这两种技术的好处。
一般来说,将KG用于RAG的检索部分有三种方式:
- 基于向量的检索:对 KG 进行向量化并将其存储在向量数据库中。然后,如果您对自然语言提示进行向量化,则可以在向量数据库中找到与您的提示最相似的向量。由于这些向量对应于图中的实体,因此您可以在给定自然语言提示的情况下返回图中最“相关”的实体。请注意,您可以在没有图表的情况下进行基于向量的检索。这实际上是 RAG 的原始实现方式,有时称为 Baseline RAG。您可以对 SQL 数据库或内容进行向量化,并在查询时检索它。
- 提示查询检索:使用 LLM 为您编写 SPARQL 或 Cypher 查询,使用该查询查询您的 KG,然后使用返回的结果来增强您的提示。
- 混合(向量 + SPARQL):您可以以各种有趣的方式组合这两种方法。在本教程中,我将演示一些可以组合这些方法的方法。我将主要关注使用向量化进行初始检索,然后使用 SPARQL 查询来优化结果。
然而,有很多方法可以将矢量数据库和 KG 结合起来用于搜索、相似性和 RAG。这只是一个说明性示例,旨在强调每种方法的优缺点以及将它们一起使用的好处。我在这里将它们一起使用的方式——使用矢量化进行初始检索,然后使用 SPARQL 进行过滤——并不是独一无二的。我在其他地方见过这种实现。我听说的一个很好的例子来自一家大型家具制造商的一位员工。他说,矢量数据库可能会向购买沙发的人推荐除毛刷,但知识图谱会了解材料、属性和关系,并确保不会向购买皮沙发的人推荐除毛刷。
在本教程中,我将:
- 将数据集矢量化为矢量数据库,以测试语义搜索、相似性搜索和 RAG (基于矢量的检索)
- 将数据转换为 KG 以测试语义搜索、相似性搜索和 RAG (提示查询检索,但实际上更像是查询检索,因为我只是直接使用 SPARQL,而不是让 LLM 将我的自然语言提示转换为 SPARQL 查询)
- 将知识图谱中的带有标签和 URI 的数据集矢量化到矢量数据库(我将其称为“矢量化知识图谱”)中,并测试语义搜索、相似性和 RAG (混合)
目的是说明知识图谱和矢量数据库在这些功能上的差异,并展示它们可以协同工作的一些方式。下面是矢量数据库和知识图谱如何协同执行高级查询的高级概述。
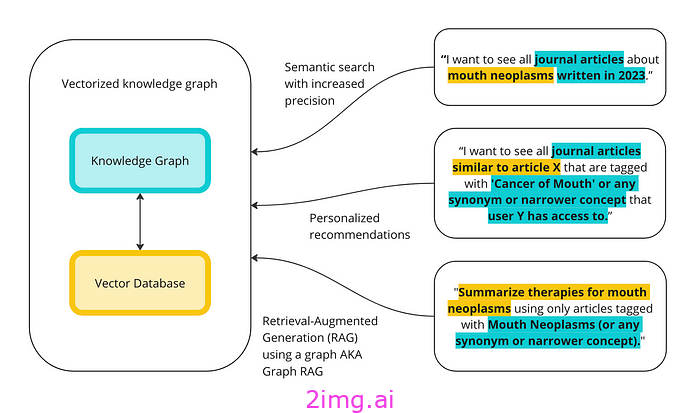

如果你不想继续阅读,以下是 TL;DR:
- 矢量数据库可以很好地运行语义搜索、相似度计算和一些基本形式的 RAG,但有一些注意事项。第一个注意事项是,我使用的数据包含期刊文章的摘要,即它包含大量与之相关的非结构化文本。矢量化模型主要在非结构化数据上进行训练,因此在给定与实体相关的文本块时表现良好。
- 话虽如此,将数据放入矢量数据库并准备进行查询的开销非常小。如果您的数据集中包含一些非结构化数据,您可以在 15 分钟内进行矢量化并开始搜索。
- 毫不奇怪,单独使用矢量数据库的最大缺点之一是缺乏可解释性。响应可能有三个好的结果和一个不太合理的结果,而且无法知道为什么会出现第四个结果。
- 矢量数据库返回不相关内容的可能性对搜索和相似性来说是一个麻烦,但对 RAG 来说却是一个大问题。如果你用四篇文章来扩充你的提示,而其中一篇是关于完全不相关的主题,那么 LLM 的回应就会产生误导。这通常被称为“上下文中毒”。
- 上下文中毒尤其危险的是,回应不一定在事实上不准确,也不是基于不准确的数据,只是使用错误的数据来回答你的问题。我在本教程中找到的示例是针对提示“口腔肿瘤的治疗方法”。检索到的一篇文章是关于直肠癌治疗方法的研究,该研究已发送给法学硕士进行总结。我不是医生,但我很确定直肠不是口腔的一部分。法学硕士准确地总结了这项研究以及不同治疗方法对口腔和直肠癌的影响,但并不总是提到癌症的类型。因此,在用户要求法学硕士描述口腔癌的治疗方法后,用户会在不知情的情况下阅读法学硕士描述直肠癌的不同治疗方案。
- KG 能够很好地进行语义搜索和相似性搜索的程度取决于元数据的质量以及元数据所连接的受控词汇表。在本教程的示例数据集中,期刊文章都已用主题词标记。这些术语是丰富的受控词汇表的一部分,即美国国立卫生研究院的医学主题词(MeSH)。因此,我们可以相对轻松地进行开箱即用的语义搜索和相似性搜索。
- 将 KG 直接矢量化到矢量数据库中以用作 RAG 的知识库可能会有一些好处,但在本教程中我没有这样做。我只是以表格格式矢量化数据,但为每篇文章添加了一个 URI 列,这样我就可以将矢量连接回 KG。
- 使用 KG 进行语义搜索、相似性和 RAG 的最大优势之一是可解释性。您始终可以解释为什么会返回某些结果:它们被标记为某些概念或具有某些元数据属性。
- 我没有预见到的 KG 的另一个好处是有时被称为“增强数据丰富”或“专家图表”的功能——您可以使用 KG 来扩展或优化您的搜索词。例如,您可以找到类似的术语、更窄的术语或以特定方式与您的搜索词相关的术语,以扩展或优化您的查询。例如,我可能从搜索“口腔癌”开始,但根据我的 KG 术语和关系,将搜索范围缩小到“牙龈肿瘤和腭肿瘤”。
- 开始使用 KG 的最大障碍之一是你需要构建一个 KG。话虽如此,有很多方法可以使用 LLM 来加速 KG 的构建(上图 1)。
- 单独使用 KG 的一个缺点是,你需要编写 SPARQL 查询来完成所有操作。因此,上面描述的即时查询检索非常流行。
- 使用 Jaccard 相似度在知识图谱中查找相似文章的结果很差。如果没有指定,知识图谱会返回带有重叠标签的文章,例如“老年人”、“男性”和“人类”,这些文章可能远不如“治疗方案”或“口腔肿瘤”那么相关。
- 我遇到的另一个问题是 Jaccard 相似度计算需要很长时间(比如 30 分钟)才能完成。我不知道是否有更好的方法(欢迎提出建议),但我猜想在一篇文章和 9,999 篇其他文章之间找到重叠标签需要耗费大量的计算资源。
- 由于我在本教程中使用的示例提示很简单,例如“总结这些文章”——LLM 的响应准确性(对于基于向量和基于 KG 的检索方法)更多地取决于检索而不是生成。我的意思是,只要你给 LLM 相关的上下文,LLM 就不太可能搞砸像“总结”这样的简单提示。当然,如果我们的提示是更复杂的问题,情况会大不相同。
- 使用向量数据库进行初始搜索,然后使用知识图谱进行过滤,可以得到最佳结果。这一点显而易见——你不会为了得到更糟糕的结果而进行过滤。但关键在于:知识图谱本身不一定能改善结果,而是知识图谱为你提供了控制输出以优化结果的能力。
- 使用知识图谱过滤结果可以提高基于提示的准确性和相关性,但也可以根据提示的作者自定义结果。例如,我们可能想使用相似性搜索来查找相似的文章以推荐给用户,但我们只想推荐该用户有权访问的文章。知识图谱允许查询时访问控制。
- KG 还可以帮助降低上下文中毒的可能性。在上面的 RAG 示例中,我们可以在矢量数据库中搜索“口腔肿瘤疗法”,然后仅过滤带有口腔肿瘤(或相关概念)标签的文章。
- 在本教程中,我仅关注一个简单的实现,我们将提示直接发送到向量数据库,然后使用图表过滤结果。有更好的方法可以做到这一点。例如,您可以从提示中提取与您的受控词汇表一致的实体,并使用图表丰富它们(使用同义词和更窄的术语);您可以将提示解析为语义块并将它们分别发送到向量数据库;您可以在矢量化之前将 RDF 数据转换为文本,以便语言模型更好地理解它,等等。这些都是未来博客文章的主题。
步骤 1:基于向量的检索
下图从总体上展示了该计划。我们希望将期刊文章的摘要和标题矢量化到矢量数据库中,以运行不同的查询:语义搜索、相似性搜索和简单版本的 RAG。对于语义搜索,我们将测试“口腔肿瘤”之类的术语 — 矢量数据库应返回与此主题相关的文章。对于相似性搜索,我们将使用给定文章的 ID 在矢量空间中查找其最近邻居,即与本文最相似的文章。最后,矢量数据库允许一种 RAG 形式,我们可以在其中用一篇文章补充提示,例如“请像向没有医学学位的人解释这一点一样解释这一点”。

我决定使用来自 PubMed 存储库(许可证CC0:公共领域)的 50,000 篇研究文章的数据集。该数据集包含文章的标题、摘要以及元数据标签字段。这些标签来自医学主题词 (MeSH) 控制词汇词库。在本教程的这一部分中,我们只使用摘要和标题。这是因为我们试图将矢量数据库与知识图谱进行比较,而矢量数据库的优势在于它能够在没有丰富元数据的情况下“理解”非结构化数据。我只使用了数据的前 10,000 行,只是为了使计算运行得更快。
使用向量数据库进行语义搜索
当我们谈论向量数据库中的语义时,我们的意思是使用已在大量非结构化内容上训练过的 LLM API 将术语向量化到向量空间中。这意味着向量会考虑术语的上下文。例如,如果在训练数据中多次提到 Mark Twain 一词,而 Samuel Clemens 一词又在附近出现,则这两个术语的向量在向量空间中应该彼此接近。同样,如果在训练数据中多次出现 Mouth Cancer 一词和 Mouth Neoplasms 一词,我们预计有关 Mouth Cancer 的文章的向量在向量空间中应该靠近有关 Mouth Neoplasms 的文章。
您可以通过运行一个简单的查询来检查它是否有效:
response = (
客户端。查询
。获取(“文章”,[ “标题”,“abstractText” ])
。with_additional([ “id” ])
。with_near_text({ “概念”:[ “口腔肿瘤” ]})。
with_limit(10)
。do ())打印( json.dumps(response,indent= 4))
结果如下:
- 第一篇文章: “牙龈转移是上皮样恶性间皮瘤多器官播散的首发症状。”这篇文章是关于一项针对恶性间皮瘤(一种肺癌)患者进行的研究,该研究已扩散到牙龈。该研究旨在测试不同治疗方法(化疗、去皮和放疗)对癌症的影响。这篇文章似乎很适合回归——它是关于牙龈肿瘤的,是口腔肿瘤的一个子集。
- 第 2 篇文章: “小唾液腺肌上皮瘤。光学和电子显微镜研究。”这篇文章是关于从一名 14 岁男孩的牙龈中切除的肿瘤,该肿瘤已扩散到上颌骨的一部分,由源自唾液腺的细胞组成。这篇文章似乎也是一篇适合回归的文章——它是关于从一名男孩的口腔中切除的肿瘤。
- 文章 3: “下颌骨转移性神经母细胞瘤。病例报告。”这篇文章是对一名下颌癌患者 5 岁男孩的病例研究。这是关于癌症的,但严格来说不是口腔癌——下颌肿瘤(下颌肿瘤)不是口腔肿瘤的一个子集。
这就是我们所说的语义搜索——这些文章的标题或摘要中都没有“嘴”这个词。第一篇文章是关于牙龈肿瘤的,是口腔肿瘤的一个子集。第二篇文章是关于牙龈肿瘤的,这种肿瘤起源于受试者的唾液腺,两者都是口腔肿瘤的子集。第三篇文章是关于下颌肿瘤的——从技术上讲,根据 MeSH 词汇表,下颌肿瘤不是口腔肿瘤的一个子集。尽管如此,矢量数据库知道下颌骨靠近嘴。
使用矢量数据库进行相似性搜索
我们还可以使用向量数据库来查找类似的文章。我选择了一篇使用上面的口腔肿瘤查询返回的文章,标题为“牙龈转移是上皮样恶性间皮瘤多器官播散的第一个征兆”。使用该文章的 ID,我可以查询向量数据库以查找所有类似的实体:
response = (
客户端.查询
。获取(“articles”,[ “title”,“abstractText” ])
.with_near_object({
“id”:“a7690f03-66b9-5d17-b765-8c6eb21f99c8” # 给定文章的 id
})
.with_limit(10)
.with_additional([ “distance” ])
.do ()
)
print(json.dumps(response,indent=2))
结果按相似度排序。相似度是通过向量空间中的距离来计算的。如你所见,最上面的结果是 Gingival 文章 — 这篇文章与它自己最相似。
其他文章如下:
- 第四条:“针对吸烟者的口腔恶性病变筛查可行性研究”。这是关于口腔癌的,但是是关于如何让吸烟者报名参加筛查,而不是关于他们接受治疗的方式。
- 文章 5:“扩大胸膜切除术和胸膜剥脱术治疗恶性胸膜间皮瘤是一种有效且安全的老年性细胞减灭术。”这篇文章是关于在老年人中用胸膜切除术和胸膜剥脱术(切除肺部癌症的手术)治疗胸膜间皮瘤(肺癌)的研究。因此,这篇文章与间皮瘤的治疗类似,但与牙龈肿瘤无关。
- 第三篇文章(从上往下):《下颌骨转移性神经母细胞瘤。病例报告》。同样,这是一篇关于下颌癌的 5 岁男孩的文章。这篇文章是关于癌症的,但严格来说不是口腔癌,而且这篇文章不像牙龈文章那样真正是关于治疗结果的。
有人可能会说,所有这些文章都与我们原来的牙龈文章相似。很难评估它们有多相似,因此很难评估相似性搜索的效果,因为这在很大程度上取决于用户对“相似”的定义。您是否对有关间皮瘤治疗的其他文章感兴趣,而第一篇文章是关于它如何扩散到牙龈的这一事实无关紧要?在这种情况下,第 5 篇文章是最相似的。或者您是否对通过治疗或预防来减少任何类型的口腔癌感兴趣?在这种情况下,第 4 篇文章是最相似的。矢量数据库的一个缺点是它是一个黑匣子——我们不知道为什么返回这些文章。
使用矢量数据库的检索增强生成 (RAG)
以下是如何使用向量数据库来检索结果,然后将结果发送到 LLM 进行汇总的方法(RAG 的一个示例)。
response = (
client.query
. get(“articles”, [ “title”,“abstractText” ])
.with_near_text({ “concepts”: [ “牙龈转移是上皮样恶性间皮瘤多器官播散的第一个征兆” ]})
.with_generate(single_prompt = “请像向没有医学学位的人解释一样解释这篇文章{title}。”)
.with_limit(1)
.do ()
)
print(json.dumps(response,indent = 4))
您可以看到以下响应:
“当然!这篇文章讨论的是患有一种名为上皮样恶性间皮瘤的癌症的病例。这种癌症通常始于肺部或腹部内膜。然而,在这种情况下,癌症扩散到身体其他部位的第一个迹象是在牙龈中发现的。这被称为牙龈转移。\n\n转移意味着癌细胞已从原始肿瘤扩散到身体的其他部位。在这种情况下,癌症在扩散到其他器官之前已经扩散到牙龈。这一点很重要,因为它表明癌症已经发展到晚期,甚至在被发现之前就已经扩散到多个器官。\n\n总的来说,这篇文章强调了早期发现和监测癌症的重要性,以及癌症扩散到身体意想不到的部位的可能性。”
我其实对这个回复很失望。摘要清楚地解释了这是一项跟踪 13 名转移性恶性间皮瘤患者接受不同治疗及其结果的研究。RAG 的输出将这篇文章描述为关于“一个人”的文章,根本没有提到这项研究。
我们不妨尝试总结几篇文章,而不是只总结一篇文章。在下一个示例中,我们使用与上面相同的搜索词(口腔肿瘤),然后将排名前三的文章连同提示“在此以要点形式总结关键信息。让没有医学学位的人也能理解”,发送给法学硕士。
response = (
client.query
. get (collection_name, [ "title" , "abstractText" ])
.with_near_text({ "concepts" : [ "口腔肿瘤" ]})
.with_limit( 3 )
.with_generate(grouped_task= "在此以项目符号总结关键信息。让没有医学学位的人也能理解。" )
. do ()
)
print (response[ "data" ][ "Get" ][ "Articles" ][ 0 ][ "_additional" ][ "generate" ][ "groupedResult" ])
结果如下:
- 转移到口腔的恶性间皮瘤很少见,颌骨中的病例多于软组织
- 此类癌症的平均生存率为 9-12 个月
- 对 13 名接受新辅助化疗和手术的患者的研究表明,中位生存期为 11 个月
- 一名患者的牙龈肿块是间皮瘤多器官复发的第一个迹象
- 对于有间皮瘤病史的患者,即使在罕见部位,对新生长病变进行活检也很重要
- 小涎腺肌上皮瘤可显示出恶性潜能的特征
- 下颌骨转移性神经母细胞瘤非常罕见,可表现为儿童溶骨性颌骨缺损和乳磨牙松动
我觉得这个回复比之前的回复好多了——它提到了第 1 条中进行的研究、治疗方法和结果。倒数第二条是关于“小唾液腺肌上皮瘤。光学和电子显微镜研究”的文章,似乎是一行准确的描述。最后一条是关于上面提到的第 3 条的,同样,似乎是一行准确的描述。
第 2 步:使用知识图谱进行数据检索
以下是我们如何使用知识图进行语义搜索、相似性搜索和 RAG 的高级概述:
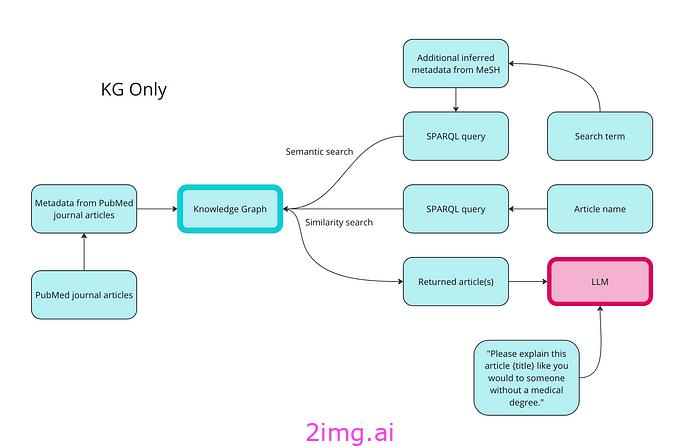
使用知识图谱检索数据的第一步是将数据转换为 RDF 格式。下面的代码为所有数据类型创建类和属性,然后用文章和 MeSH 术语的实例填充它。我还创建了发布日期和访问级别的属性,并用随机值填充它们,仅作为演示。
从rdflib导入Graph、RDF、RDFS、Namespace、URIRef、Literal
从rdflib.namespace导入SKOS、XSD
导入pandas作为pd
导入urllib.parse
导入random
从datetime导入datetime、timedelta
# 创建一个新的 RDF 图
g = Graph()
# 定义命名空间
schema = Namespace( 'http://schema.org/' )
ex = Namespace( 'http://example.org/' )
prefixes = {
'schema' : schema,
'ex' : ex,
'skos' : SKOS,
'xsd' : XSD
}
for p, ns in prefixes.items():
g.bind(p, ns)
# 定义类和属性
Article = URIRef(ex.Article)
MeSHTerm = URIRef(ex.MeSHTerm)
g.add((Article, RDF. type , RDFS.Class))
g.add((MeSHTerm, RDF. type , RDFS.Class))
title = URIRef(schema.name)
abstract = URIRef(schema.description)
date_published = URIRef(schema.datePublished)
access = URIRef(ex.access)
g.add((title, RDF. type , RDF.Property))
g.add((abstract, RDF. type , RDF.Property))
g.add((date_published, RDF. type , RDF.Property))
g.add((access, RDF. type , RDF.Property))
# 清理和解析 MeSH 术语的函数
def parse_mesh_terms ( mesh_list ):
if pd.isna(mesh_list):
return []
return [term.strip().replace( ' ' , '_' ) for term in mesh_list.strip( "[]'" ).split( ',' )]
# 创建有效 URI 的函数
def create_valid_uri ( base_uri, text ):
if pd.isna(text):
return None
sanitized_text = urllib.parse.quote(text.strip().replace( ' ' , '_' ).replace( '"' , '' ).replace( '<' , '' ).replace( '>' , '' ).replace( "'" ,“_”))
返回URIRef(f“{base_uri} / {sanitized_text} " )
# 用于生成过去 5 年内的随机日期的函数
def generate_random_date ():
start_date = datetime.now() - timedelta(days= 5 * 365 )
random_days = random.randint( 0 , 5 * 365 )
return start_date + timedelta(days=random_days)
# 用于生成 1 到 10 之间的随机访问值的函数
def generate_random_access ():
return random.randint( 1 , 10 )
# 在此处加载您的 DataFrame
# df = pd.read_csv('your_data.csv')
# 循环遍历 DataFrame 中的每一行并创建 RDF 三元组
for index, row in df.iterrows():
article_uri = create_valid_uri( "http://example.org/article" , row[ 'Title' ])
if article_uri is None :
continue
# 添加文章实例
g.add((article_uri, RDF. type , Article))
g.add((article_uri, title, Literal (row[ 'Title' ], datatype=XSD.string)))
g.add((article_uri, abstract, Literal (row[ 'abstractText' ], datatype=XSD.string)))
# 添加随机 datePublished 和 access
random_date = generate_random_date()
random_access = generate_random_access()
g.add((article_uri, date_published, Literal (random_date.date(), datatype=XSD.date)))
g.add((article_uri, access, Literal (random_access, datatype=XSD.integer)))
# 添加 MeSH 术语
mesh_terms = parse_mesh_terms(row[ 'meshMajor' ])
for term in mesh_terms:
term_uri = create_valid_uri( "http://example.org/mesh" , term)
if term_uri is None :
continue
# 添加 MeSH 术语实例
g.add((term_uri, RDF. type , MeSHTerm))
g.add((term_uri, RDFS.label, Literal (term.replace( '_' , ' ' ), datatype=XSD.string)))
# 将文章链接到 MeSH 术语
g.add((article_uri, schema.about, term_uri))
# 将图表序列化为文件(可选)
g.serialize(目标= 'ontology.ttl',格式= 'turtle')
使用知识图谱进行语义搜索
现在我们可以测试语义搜索。然而,在知识图谱的上下文中,“语义”一词略有不同。在知识图谱中,我们依靠与文档相关的标签及其在 MeSH 分类法中的关系来获取语义。例如,一篇文章可能是关于唾液腺肿瘤(唾液腺中的癌症),但仍被标记为口腔肿瘤。
我们不仅会查询所有标有口腔肿瘤的文章,还会查找比口腔肿瘤更窄的任何概念。MeSH 词汇表包含术语定义,但也包含更宽和更窄的关系。
从SPARQLWrapper导入SPARQLWrapper、JSON
def get_concept_triples_for_term(term):
sparql = SPARQLWrapper(“https://id.nlm.nih.gov/mesh/sparql”)
query = f“”
PREFIX rdf:<http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs:<http://www.w3.org/2000/01/rdf-schema#>
PREFIX meshv:<http://id.nlm.nih.gov/mesh/vocab#>
PREFIX mesh:<http://id.nlm.nih.gov/mesh/>
SELECT ?subject ?p ?pLabel ?o ?oLabel
FROM <http://id.nlm.nih.gov/mesh>
WHERE {{
?subject rdfs:label " {term} "@en .
?subject ?p ?o .
FILTER(CONTAINS(STR(?p), "concept"))
OPTIONAL {{ ?p rdfs:label ?pLabel . }}
OPTIONAL {{ ?o rdfs:label ?oLabel . }}
}}
"""
sparql.setQuery(query)
sparql.setReturnFormat(JSON)
results = sparql.query().convert()
triples = set () # 使用集合避免重复条目
for result in results[ "results" ][ "bindings" ]:
obj_label = result.get( "oLabel" , {}).get( "value" , "No label" )
triples.add(obj_label)
# 将术语本身添加到列表中
triples.add(term)
return list (triples) # 转换回列表以便于处理
def get_narrower_concepts_for_term(term):
sparql = SPARQLWrapper(“https://id.nlm.nih.gov/mesh/sparql”)
query = f“”
PREFIX rdf:<http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs:<http://www.w3.org/2000/01/rdf-schema#>
PREFIX meshv:<http://id.nlm.nih.gov/mesh/vocab#>
PREFIX mesh:<http://id.nlm.nih.gov/mesh/>
选择?narrowerConcept?narrowerConceptLabel
其中 {{
?broaderConcept rdfs:label“ {term} “@en。
?narrowerConcept meshv:broaderDescriptor ?broaderConcept .
?narrowerConcept rdfs:label ?narrowerConceptLabel .
}}
"""
sparql.setQuery(query)
sparql.setReturnFormat(JSON)
results = sparql.query()。convert()
概念 = set () # 使用集合避免重复条目
for result in results[ "results" ][ "bindings" ]:
subject_label = result.get( "narrowerConceptLabel" , {}).get( "value" , "No label" )
ideas.add(subject_label)
return list (concepts) # 转换回列表以便于处理
def get_all_narrower_concepts ( term,depth= 2 ,current_depth= 1 ):
# 创建一个字典来存储术语及其更窄的概念
all_concepts = {}
# 初始获取主要术语
narrower_concepts = get_narrower_concepts_for_term(term)
all_concepts[term] = narrower_concepts
# 如果当前深度小于所需深度,则递归获取更窄的概念
if current_depth <depth:
for concept in narrower_concepts:
# 递归调用以获取当前概念的更窄概念
child_concepts = get_all_narrower_concepts(concept,depth,current_depth+ 1 )
all_concepts.update(child_concepts)
return all_concepts
# 获取替代名称和更窄的概念
term = "Mouth Neoplasms"
alternative_names = get_concept_triples_for_term(term)
all_concepts = get_all_narrower_concepts(term,depth= 2 ) # 根据需要调整深度
# 输出替代名称
print ( "Alternative names:" ,alternative_names)
print ()
# 输出更窄的概念
for broad, narrowerinall_concepts.items ():
print ( f"Broader concept: {broader} " )
print ( f"Narrower ideas: {narrower} " )
print ( "---" )
以下是口腔肿瘤的所有替代名称和狭义概念。
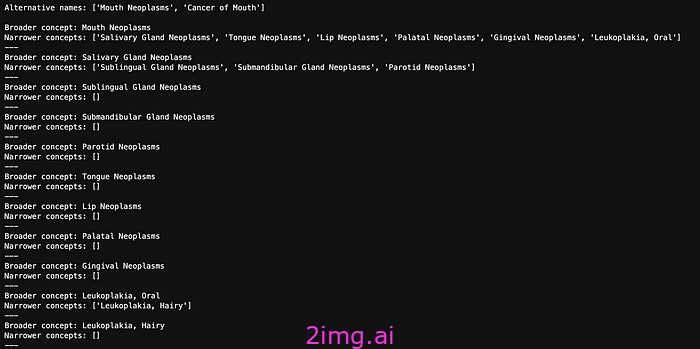
我们将其变成一个简单术语列表:
def flatten_concepts ( concepts_dict ):
flat_list = []
def recurse_terms ( term_dict ):
for term, narrower_terms in term_dict.items():
flat_list.append(term)
if narrower_terms:
recurse_terms( dict .fromkeys(narrower_terms, [])) # 使用空字典进行递归
recurse_terms(concepts_dict)
return flat_list
# 展平概念字典
flat_list = flatten_concepts(all_concepts)
然后我们将这些术语转换为 MeSH URI,以便我们可以将它们合并到我们的 SPARQL 查询中:
# 将 MeSH 术语转换为 URI
def convert_to_mesh_uri ( term ):
formatted_term = term.replace( " " , "_" ).replace( "," , "_" ).replace( "-" , "_" )
return URIRef( f"http://example.org/mesh/_ {formatted_term} _" )
# 将术语转换为 URI
mesh_terms = [convert_to_mesh_uri(term) for term in flat_list]
然后,我们编写一个 SPARQL 查询来查找所有标有“口腔肿瘤”、其别名“口腔癌”或任何较狭义的术语的文章:
从rdflib导入URIRef
查询 = """
PREFIX schema: <http://schema.org/>
PREFIX ex: <http://example.org/>
SELECT ?article ?title ?abstract ?datePublished ?access ?meshTerm
WHERE {
?article a ex:Article ;
schema:name ?title ;
schema:description ?abstract ;
schema:datePublished ?datePublished ;
ex:access ?access ;
schema:about ?meshTerm .
?meshTerm a ex:MeSHTerm .
}
"""
# 用于存储文章及其相关 MeSH 术语的词典
article_data = {}
# 针对每个 MeSH 术语运行查询
for mesh_term in mesh_terms:
results = g.query(query, initBindings={ 'meshTerm' : mesh_term})
# 处理结果
for row in results:
article_uri = row[ 'article' ]
if article_uri not in article_data:
article_data[article_uri] = {
'title' : row[ 'title' ],
'abstract' : row[ 'abstract' ],
'datePublished' : row[ 'datePublished' ],
'access' : row[ 'access' ],
'meshTerms' : set ()
}
# 将 MeSH 术语添加到此文章的集合
article_data[article_uri][ 'meshTerms' ].add( str (row[ 'meshTerm' ]))
# 按匹配的 MeSH 术语数量对文章进行排名
ranked_articles = sorted (
article_data.items(),
key= lambda item: len (item[ 1 ][ 'meshTerms' ]),
reverse= True
)
# 获取前 3 篇文章
top_3_articles = ranked_articles[: 3 ] # 输出 article_uri的
结果,数据在top_3_articles 中:print(f“标题:{data[ 'title' ]} ”)print(“MeSH 术语:”)for mesh_term in data[ 'meshTerms' ]:打印(f“- {mesh_term} ”
)
打印()
返回的文章是:
- 第 2 条(从上至下): “小涎腺肌上皮瘤。光学和电子显微镜研究。”
- 第四条(自上而下): “针对吸烟者的口腔恶性病变筛查可行性研究。”
- 文章 6: “胚胎致死异常视觉样蛋白 HuR 的表达与口腔鳞状细胞癌中的环氧合酶-2 之间的关联。”这篇文章是关于一项研究,旨在确定一种名为 HuR 的蛋白质的存在是否与环氧合酶-2 的更高水平有关,环氧合酶-2 在癌症发展和癌细胞扩散中发挥作用。具体来说,这项研究的重点是口腔鳞状细胞癌,这是一种口腔癌。
这些结果与我们从向量数据库中得到的结果并无不同。这些文章都是关于口腔肿瘤的。知识图谱方法的优点在于我们确实获得了可解释性——我们确切地知道为什么选择这些文章。文章 2 标记为“牙龈肿瘤”和“唾液腺肿瘤”。文章 4 和 6 都标记为“口腔肿瘤”。由于文章 2 被标记为 2 个与我们的搜索词相匹配的词,因此排名最高。
使用知识图谱进行相似性搜索
我们可以依靠与文章相关的标签,而不是使用向量空间来查找相似的文章。使用标签进行相似性计算的方法有很多种,但在本例中,我将使用一种常用方法:Jaccard 相似性。我们将再次使用牙龈文章进行跨方法比较。
从rdflib导入Graph、URIRef
从rdflib.namespace导入RDF、RDFS、Namespace、SKOS
导入urllib.parse
# 定义命名空间
schema = Namespace( 'http://schema.org/' )
ex = Namespace( 'http://example.org/' )
rdfs = Namespace( 'http://www.w3.org/2000/01/rdf-schema#' )
# 计算 Jaccard 相似度并返回重叠项的函数
def jaccard_similarity ( set1, set2 ):
Intersection = set1.intersection(set2)
Union = set1.union(set2)
Similarity = len (intersection) / len (union) if len (union) != 0 else 0
return Similarity, Intersection
# 加载 RDF 图
g = Graph()
g.parse( 'ontology.ttl' , format = 'turtle' )
def get_article_uri ( title ):
# 将标题转换为 URI 安全字符串
safe_title = urllib.parse.quote(title.replace( " " , "_" ))
return URIRef( f"http://example.org/article/ {safe_title} " )
def get_mesh_terms ( article_uri ):
query = """
PREFIX schema: <http://schema.org/>
PREFIX ex: <http://example.org/>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT ?meshTerm
WHERE {
?article schema:about ?meshTerm .
?meshTerm a ex:MeSHTerm .
FILTER(?article = <""" + str(article_uri)+ """>)
}
"""
results = g.query(query)
mesh_terms = { str(row[ 'meshTerm' ])for row in results}
return mesh_terms
def find_similar_articles(title):
article_uri = get_article_uri(title)
mesh_terms_given_article = get_mesh_terms(article_uri)
# 查询所有文章及其 MeSH 术语
query = """
PREFIX schema:<http://schema.org/>
前缀 例如:<http://example.org/>
前缀 rdfs:<http://www.w3.org/2000/01/rdf-schema#>
选择?文章?meshTerm
其中{
?文章a ex:文章;
模式:关于?meshTerm。
?meshTerm a ex:MeSHTerm。
}
"""
results = g.query(query)
mesh_terms_other_articles = {}
for row in results:
article = str (row[ 'article' ])
mesh_term = str (row[ 'meshTerm' ])
if article not in mesh_terms_other_articles:
mesh_terms_other_articles[article] = set ()
mesh_terms_other_articles[article].add(mesh_term)
# 计算Jaccard相似度
similarities = {}
overping_terms = {}
for article, mesh_terms in mesh_terms_other_articles.items():
if article != str (article_uri):
similarity, override = jaccard_similarity(mesh_terms_given_article, mesh_terms)
similarities[article] = similarity
overping_terms[article] = override
# 按相似度排序,取前5名
top_similar_articles = sorted (similarities.items(), key= lambda x: x[ 1 ], reverse= True )[: 15 ]
# 打印结果
print ( f"与 ' {title} ' 相似的前 15 篇文章:" )
for article, similarity in top_similar_articles:
print ( f"文章 URI:{article} " )
print ( f"Jaccard 相似度:{similarity: .4 f} " )
print ( f"重叠 MeSH 词条:{overlapping_terms[article]} " )
print ()
# 示例用法
article_title = "牙龈转移是上皮样恶性间皮瘤多器官播散的第一个征兆。"
find_similar_articles(article_title)
结果如下。由于我们再次搜索 Gingival 文章,因此这是最相似的文章,这也是我们所期望的。其他结果如下:
- 第 7 篇文章: “股外侧肌钙化性肌腱炎。三例报告。”这篇文章是关于股外侧肌(大腿肌肉)钙化性肌腱炎(肌腱中形成钙沉积物)。这与口腔肿瘤无关。
- 重叠术语:断层扫描、老年人、男性、人类、X 射线计算
- 第 8 条: “前列腺癌患者在前列腺特异性抗原水平升高时,雄激素剥夺疗法的最佳持续时间是多久。”这篇文章是关于前列腺癌患者应接受多长时间的特定治疗(雄激素剥夺疗法)。这是关于癌症治疗(放射疗法),而不是口腔癌的治疗。
- 重叠术语:放射治疗、老年人、男性、人类、辅助
- 文章 9: CT 扫描大脑半球不对称:失语症康复的预测因素。本文探讨了大脑左右两侧的差异(大脑半球不对称)如何预测中风后失语症的康复情况。
- 重叠术语:断层扫描、老年人、男性、人类、X 射线计算机
此方法最好的部分是,由于我们在此计算相似度的方式,我们可以看到为什么其他文章相似——我们准确地看到哪些术语是重叠的,即哪些术语在 Gingival 文章和每个比较中是常见的。
可解释性的缺点是,根据之前的结果,我们可以看出这些文章似乎不是最相似的文章。它们都有三个共同的术语(老年、男性和人类),但这些术语可能远不如治疗方案或口腔肿瘤那么相关。您可以根据语料库中术语的流行程度重新计算权重——词频-逆文档频率 (TF-IDF)——这可能会改善结果。您还可以在进行相似性分析时选择与您最相关的标记术语,以便更好地控制结果。
使用 Jaccard 相似度对知识图谱中的术语计算相似度的最大缺点是计算工作量——运行一次计算就需要 30 分钟。
使用知识图谱的 RAG
我们还可以仅使用知识图谱进行检索部分来执行 RAG。我们已经有一个关于口腔肿瘤的文章列表,这些文章已保存为上述语义搜索的结果。要实现 RAG,我们只需将这些文章发送给 LLM 并要求其总结结果。
首先,我们将每篇文章的标题和摘要合并为一个大文本块,称为 combined_text:
# 合并标题和摘要的函数
def Combine_abstracts ( Top_3_articles ):
Combined_text = "" .join(
[ f"标题:{data[ 'title' ]}摘要:{data[ 'abstract' ]} " for article_uri, data in top_3_articles]
)
return Combined_text
# 合并前 3 篇文章的摘要
Combined_text = Combined_abstracts(Top_3_articles)
Print (Combined_text)
然后,我们设置一个客户端,以便我们可以将此文本直接发送给 LLM:
导入 openai
# 设置您的 OpenAI API 密钥
api_key = "您的 API 密钥"
openai.api_key = api_key
然后我们给LLM提供上下文和提示:
def generate_summary ( combined_text ):
response = openai.Completion.create(
model= "gpt-3.5-turbo-instruct" ,
prompt= f"在此处以要点形式总结关键信息。让没有医学学位的人也能理解:\n\n {combined_text} " ,
max_tokens= 1000 ,
temperature= 0.3
)
# 获取原始文本输出
raw_summary = response.choices[ 0 ].text.strip()
# 将文本拆分为行并清理空格
lines = raw_summary.split( '\n' )
lines = [line.strip() for line in lines if line.strip()]
# 使用实际换行符将行重新连接在一起
formatted_summary = '\n' .join(lines)
return formatted_summary
# 生成并打印摘要
summary = generate_summary(combined_text)
print (summary)
结果如下:
- 一名 14 岁男孩的上颌前部有牙龈肿瘤,医生将其切除,并用光学和电子显微镜对其进行了研究
- 该肿瘤由肌上皮细胞组成,似乎是恶性的
- 电子显微镜显示肿瘤起源于唾液腺
- 这是唯一一例确诊的具有恶性特征的肌上皮瘤病例
- 进行了一项可行性研究,以提高高发地区口腔癌和癌前病变的早期发现率
- 烟草销售商参与分发传单,邀请吸烟者接受全科医生的免费检查
- 研究中纳入了 93 名患者,其中 27% 被转诊给专科医生
- 63.6% 的转诊患者实际上看了专科医生,15.3% 被证实患有癌前病变
- 一项研究发现,在口腔鳞状细胞癌 (OSCC) 中,蛋白质 HuR 和酶 COX-2 的表达增加之间存在相关性
- 细胞质 HuR 表达与OSCC 中的 COX-2 表达和淋巴结和远处转移
- 抑制 HuR 表达导致口腔癌细胞中 COX-2 表达降低。
结果看起来不错,即它很好地总结了语义搜索返回的三篇文章。仅使用 KG 的 RAG 应用程序的响应质量取决于您的 KG 检索相关文档的能力。如本例所示,如果您的提示足够简单,例如“在此处总结关键信息”,那么困难的部分是检索(为 LLM 提供正确的文章作为上下文),而不是生成响应。
步骤3:使用矢量化知识图谱测试数据检索
现在我们要联合起来。我们将为数据库中的每篇文章添加一个 URI,然后在 Weaviate 中创建一个新集合,在其中我们将文章名称、摘要、与其相关的 MeSH 术语以及 URI 向量化。URI 是文章的唯一标识符,也是我们连接回知识图谱的一种方式。
首先,我们在 URI 数据中添加一个新列:
# 创建有效 URI 的函数
def create_valid_uri ( base_uri, text ):
if pd.isna(text):
return None
# 对要在 URI 中使用的文本进行编码
sanitized_text = urllib.parse.quote(text.strip().replace( ' ' , '_' ).replace( '"' , '' ).replace( '<' , '' ).replace( '>' , '' ).replace( "'" , "_" ))
return URIRef( f" {base_uri} / {sanitized_text} " )
# 为文章 URI 向 DataFrame 添加新列
df[ 'Article_URI' ] = df[ 'Title' ].apply( lambda title: create_valid_uri( "http://example.org/article" , title))
现在我们为新集合创建一个包含附加字段的新模式:
class_obj = {
# 类定义
"class" : "articles_with_abstracts_and_URIs" ,
# 属性定义
"properties" : [
{
"name" : "title" ,
"dataType" : [ "text" ] ,
} ,
{
"name" : "abstractText" ,
"dataType" : [ "text" ] ,
} ,
{
"name" : "meshMajor" ,
"dataType" : [ "text" ] ,
} ,
{
"name" : "Article_URI" ,
"dataType" : [ "text" ] ,
} ,
] ,
# 指定矢量化器
"vectorizer" : "text2vec-openai" ,
# 模块设置
"moduleConfig" : {
"text2vec-openai" : {
"vectorizeClassName" : True ,
"model" : "ada" ,
"modelVersion" : “002”,
“类型” : “文本”
},
“qna-openai” : {
“模型” : “gpt-3.5-turbo-instruct”
},
“generative-openai” : {
“模型” : “gpt-3.5-turbo”
}
},
}
将该模式推送到矢量数据库:
客户端.schema.create_class ( class_obj )
现在我们将数据矢量化到新的集合中:
import logs
import numpy as np
# 配置日志记录
logs.basicConfig(level=logging.INFO, format = '%(asctime)s %(levelname)s %(message)s' )
# 将无穷大值替换为 NaN,然后填充 NaN 值
df.replace([np.inf, -np.inf], np.nan, inplace= True )
df.fillna( '' , inplace= True )
# 将列转换为字符串类型
df[ 'Title' ] = df[ 'Title' ].astype( str )
df[ 'abstractText' ] = df[ 'abstractText' ].astype( str )
df[ 'meshMajor' ] = df[ 'meshMajor' ].astype( str )
df[ 'Article_URI' ] = df[ 'Article_URI' ].astype( str )
# 记录数据类型
logging.info( f"Title column type: {df[ 'Title' ].dtype} " )
logging.info( f"abstractText column type: {df[ 'abstractText' ].dtype} " )
logging.info( f"meshMajor column type: {df[ 'meshMajor' ].dtype} " )
logging.info( f"Article_URI column type: {df[ 'Article_URI' ].dtype} " )
with client.batch(
batch_size= 10 , # 指定批次大小
num_workers= 2 , # 并行化该过程
) as batch:
for index, row in df.iterrows():
try :
question_object = {
"title" : row.Title,
"abstractText" : row.abstractText,
"meshMajor" : row.meshMajor,
“article_URI”:row.Article_URI,
}
batch.add_data_object(
question_object,
class_name = “articles_with_abstracts_and_URIs”,
uuid =generate_uuid5(question_object)
)
除异常为e:
记录外。错误( f“错误处理行{index}:{e} ”)
使用矢量化知识图谱进行语义搜索
现在,我们可以像以前一样对向量数据库进行语义搜索,但对结果具有更强的可解释性和控制力。
响应 = (
客户端。查询
。获取(“articles_with_abstracts_and_URIs”,[ “title”,“abstractText”,“meshMajor”,“article_URI” ])。
with_additional([ “id” ])
。with_near_text({ “concepts”:[ “口腔肿瘤” ]})。with_limit
(10)
。do ())打印(json.dumps(response,indent = 4))
结果是:
- 第一篇文章: “牙龈转移是上皮样恶性间皮瘤多器官播散的首发征兆。”
- 第 10 条: “血管中心性面部淋巴瘤对老年男性的诊断具有挑战性。”这篇文章讲述了诊断一名患有鼻癌的男性是多么困难。
- 第 11 条: “下颌假癌性增生”。这篇文章对我来说很难理解,但我相信它讲的是假癌性增生如何看起来像癌症(因此名称中带有“假”),但这不是癌症。虽然它似乎与下颌骨有关,但它被标记为 MeSH 术语“口腔肿瘤”。
很难说这些结果是否比单独的 KG 或向量数据库更好或更差。理论上,结果应该更好,因为与每篇文章相关的 MeSH 术语现在与文章一起被向量化了。然而,我们并没有真正对知识图谱进行向量化。例如,MeSH 术语之间的关系不在向量数据库中。
将 MeSH 术语向量化的好处在于可以立即获得一些可解释性——例如,第 11 篇文章也标记为口腔肿瘤。但将向量数据库连接到知识图谱的真正好处在于,我们可以从知识图谱中应用任何我们想要的过滤器。还记得我们之前如何在数据中添加发布日期作为字段吗?我们现在可以对此进行过滤。假设我们想查找 2020 年 5 月 1 日之后发表的有关口腔肿瘤的文章:
从rdflib导入Graph、Namespace、URIRef、Literal
从rdflib.namespace导入RDF、RDFS、XSD
# 定义命名空间
schema = Namespace( 'http://schema.org/' )
ex = Namespace( 'http://example.org/' )
rdfs = Namespace( 'http://www.w3.org/2000/01/rdf-schema#' )
xsd = Namespace( 'http://www.w3.org/2001/XMLSchema#' )
def get_articles_after_date ( graph, article_uris, date_cutoff ):
# 创建一个字典来存储每个 URI 的结果
results_dict = {}
# 使用文章 URI 列表和日期过滤器定义 SPARQL 查询
uris_str = " " .join( f"< {uri} >" for uri in article_uris)
query = f"""
PREFIX schema: <http://schema.org/>
PREFIX ex: <http://example.org/>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
SELECT ?article ?title ?datePublished
WHERE {{
VALUES ?article {{ {uris_str} }}
?article a ex:Article ;
schema:name ?title ;
schema:datePublished ?datePublished .
FILTER (?datePublished > " {date_cutoff} "^^xsd:date)
}}
"""
# 执行查询
results = graph.query(query)
# 提取每篇文章的详细信息
for row in results:
article_uri = str (row[ 'article' ])
results_dict[article_uri] = {
'title' : str (row[ 'title' ]),
'date_published' : str (row[ 'datePublished' ])
}
return results_dict
date_cutoff = "2023-01-01"
articles_after_date = get_articles_after_date(g, article_uris, date_cutoff) # 输出uri的
结果,详情见articles_after_date.items (): print ( f"文章URI: {uri} " ) print ( f"标题:{details[ 'title' ]} “)打印
(f“发布日期:{details[ 'date_published' ]} ”)
打印()
最初的查询返回了 10 条结果(我们将其设置为最大值 10),但其中只有 6 条是在 2023 年 1 月 1 日之后发布的。请参见以下结果:

使用矢量化知识图进行相似性搜索
我们可以对这个新集合进行相似性搜索,就像我们之前对牙龈文章(文章 1)所做的那样:
响应 = (
客户端。查询
。获取(“articles_with_abstracts_and_URIs”,[ “title”,“abstractText”,“meshMajor”,“article_URI” ])。
with_near_object({
“id”:“37b695c4-5b80-5f44-a710-e84abb46bc22”
})。
with_limit(50)
。with_additional([ “distance” ])
。do()
)
打印(json.dumps(response,indent = 2))
结果如下:
- 第三条: “下颌骨转移性神经母细胞瘤。病例报告。”
- 第四条: “针对吸烟者的口腔恶性病变筛查可行性研究。”
- 第 12 条: “伪装成间质性肺病的弥漫性肺内恶性间皮瘤:间皮瘤的一种独特变体。 ” 这篇文章介绍了五名男性患者,他们患有一种看起来很像另一种肺部疾病的间皮瘤:间质性肺病。
由于我们已经将 MeSH 标记矢量化,因此我们可以看到与每篇文章相关的标签。其中一些标签虽然在某些方面可能相似,但与口腔肿瘤无关。假设我们想找到与我们的牙龈文章相似但具体关于口腔肿瘤的文章。我们现在可以将我们之前对知识图谱进行的 SPARQL 过滤与这些结果结合起来。
口腔肿瘤的同义词和狭义概念的 MeSH URI 已保存,但需要向量搜索返回的 50 篇文章的 URI:
# 假设响应是包含文章的数据结构
article_uris = [URIRef(article[ "article_URI" ]) for article in response[ "data" ][ "Get" ][ "Articles_with_abstracts_and_URIs" ]]
现在我们可以根据标签对结果进行排序,就像我们之前使用知识图进行语义搜索一样。
从rdflib导入URIRef
# 使用 FILTER 为文章 URI 构建 SPARQL 查询
query = """
PREFIX schema: <http://schema.org/>
PREFIX ex: <http://example.org/>
SELECT ?article ?title ?abstract ?datePublished ?access ?meshTerm
WHERE {
?article a ex:Article ;
schema:name ?title ;
schema:description ?abstract ;
schema:datePublished ?datePublished ;
ex:access ?access ;
schema:about ?meshTerm .
?meshTerm a ex:MeSHTerm .
# 过滤以仅包含来自 URI 列表的文章
FILTER (?article IN (%s))
}
"""
# 将 URIRefs 列表转换为适合 SPARQL 的字符串
article_uris_string = ", " .join([ f"< { str (uri)} >" for uri in article_uris])
# 将文章 URI 插入查询
query = query % article_uris_string
# 用于存储文章及其相关 MeSH 术语的字典
article_data = {}
# 为每个 MeSH 术语运行查询
for mesh_term in mesh_terms:
results = g.query(query, initBindings={ 'meshTerm' : mesh_term})
# 处理结果
for row in results:
article_uri = row[ 'article' ]
if article_uri not in article_data:
article_data[article_uri] = {
'title' : row[ 'title' ],
'abstract' : row[ 'abstract' ],
'datePublished' : row[ 'datePublished' ],
'access' : row[ 'access' ],
'meshTerms' : set ()
}
# 将 MeSH 术语添加到此文章的集合
article_data[article_uri][ 'meshTerms' ].add( str (row[ 'meshTerm' ]))
# 按匹配的 MeSH 术语数量对文章进行排名
ranked_articles = sorted (
article_data.items(),
key= lambda item: len (item[ 1 ][ 'meshTerms' ]),
reverse= True
)
# 输出
结果article_uri, ranked_articles中的数据:
print ( f"标题:{data[ 'title' ]} " )
print ( f"摘要:{data[ 'abstract' ]} " )
print ( "MeSH 术语:" )
for mesh_term in data[ 'meshTerms' ]:
print ( f" - {mesh_term} " )
print ()
在矢量数据库最初返回的50篇文章中,只有5篇文章被标记为口腔肿瘤或相关概念。
- 文章 2: “小唾液腺肌上皮瘤。光学和电子显微镜研究。”标签:牙龈肿瘤,唾液腺肿瘤
- 文章4: 《针对吸烟者的口腔恶性病变筛查可行性研究》。标签:口腔肿瘤
- 第 13 篇文章: “源自牙龈沟的表皮样癌。”这篇文章描述了一例牙龈癌(牙龈肿瘤)。标签:牙龈肿瘤
- 文章 1:“牙龈转移是上皮样恶性间皮瘤多器官播散的首发症状。”标签:牙龈肿瘤
- 第 14 篇文章: “腮腺淋巴结转移:CT 和 MRI 影像学表现。”这篇文章是关于腮腺肿瘤(主要唾液腺)。标签:腮腺肿瘤
最后,假设我们想将这些类似的文章作为推荐提供给用户,但我们只想推荐该用户可以访问的文章。假设我们知道此用户只能访问标记为访问级别 3、5 和 7 的文章。我们可以使用类似的 SPARQL 查询在我们的知识图谱中应用过滤器:
从rdflib导入Graph、Namespace、URIRef、Literal
从rdflib.namespace导入RDF、RDFS、XSD、SKOS
# 假设您的 RDF 图 (g) 已加载
# 定义命名空间
schema = Namespace( 'http://schema.org/' )
ex = Namespace( 'http://example.org/' )
rdfs = Namespace( 'http://www.w3.org/2000/01/rdf-schema#' )
def filter_articles_by_access ( graph, article_uris, access_values ):
# 使用动态 VALUES 子句构造 SPARQL 查询
uris_str = " " .join( f"< {uri} >" for uri in article_uris)
query = f"""
PREFIX schema: <http://schema.org/>
PREFIX ex: <http://example.org/>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT ?article ?title ?abstract ?datePublished ?access ?meshTermLabel
WHERE {{
VALUES ?article {{ {uris_str} }}
?article a ex:Article ;
schema:name ?title ;
schema:description ?abstract ;
schema:datePublished ?datePublished ;
ex:access ?access ;
schema:about ?meshTerm .
?meshTerm rdfs:label ?meshTermLabel .
FILTER (?access IN ( { ", " .join( map ( str , access_values))} ))
}}
"""
# 执行查询
results = graph.query(query)
# 提取每篇文章的详细信息
results_dict = {}
for row in results:
article_uri = str (row[ 'article' ])
if article_uri不在results_dict 中:
results_dict[article_uri] = {
'title' : str (row[ 'title' ]),
'abstract' : str (row[ 'abstract' ]),
'date_published' : str (row[ 'datePublished' ]),
'access' : str (row[ 'access' ]),
'mesh_terms' :[]
}
results_dict[article_uri]['mesh_terms' ].append( str (row[ 'meshTermLabel' ]))
return results_dict
access_values = [ 3 , 5 , 7 ]
filtered_articles = filter_articles_by_access(g, ranked_article_uris, access_values)
# 输出结果
for uri, details infiltered_articles.items ():
print ( f"文章 URI:{uri} " )
print ( f"标题:{details[ 'title' ]} " )
print ( f"摘要:{details[ 'abstract' ]} " )
print ( f"发布日期:{details[ 'date_published' ]} " )
print ( f"访问:{details[ 'access' ]} " )
print ()
有一篇文章用户无权访问。其余四篇文章如下:
- 文章 2: “小唾液腺肌上皮瘤。光学和电子显微镜研究。”标签:牙龈肿瘤,唾液腺肿瘤。访问级别:5
- 文章 4: “针对吸烟者的口腔恶性病变筛查可行性研究。”标签:口腔肿瘤。访问级别:7
- 文章 1:“牙龈转移是上皮样恶性间皮瘤多器官播散的首发征兆。”标签:牙龈肿瘤。访问级别:3
- 第 14 篇文章: “腮腺淋巴结转移:CT 和 MRI 成像结果。”本文介绍的是腮腺肿瘤(主要唾液腺)。标签:腮腺肿瘤。访问级别:3
具有矢量化知识图谱的 RAG
最后,让我们看看将向量数据库与知识图谱结合起来后 RAG 是如何工作的。提醒一下,您可以直接针对向量数据库运行 RAG,并将其发送到 LLM 以获取生成的响应:
response = (
client.query
. get ( "带有摘要和 URI 的文章" , [ "title" , "abstractText" , 'article_URI' , 'meshMajor' ])
.with_near_text({ "concepts" : [ "口腔肿瘤疗法" ]})
.with_limit( 3 )
.with_generate(grouped_task= "在此以项目符号总结关键信息。让没有医学学位的人也能理解。" )
. do ()
)
print (response[ "data" ][ "Get" ][ "带有摘要和 URI 的文章" ][ 0 ][ "_additional" ][ "generate" ][ "groupedResult" ])
在此示例中,我使用搜索词“口腔肿瘤疗法”,并给出相同的提示,“在此以要点形式总结关键信息。让没有医学学位的人也能理解。”我们仅返回前三篇文章以生成此响应。结果如下:
- 转移到口腔的恶性间皮瘤很少见,平均生存期为 9-12 个月。
- 2012 年 8 月至 2013 年 9 月,13 名患者接受了新辅助化疗和根治性胸膜切除术,随后进行放射治疗。
- 2014 年 1 月,11 名患者仍然存活,中位生存期为 11 个月,8 名患者复发,2 名患者分别于手术后 8 个月和 9 个月死亡。
- 一名 68 岁的男性出现牙龈肿块,后来被确诊为恶性间皮瘤的转移性沉积,导致多器官复发。
- 当有间皮瘤病史时,活检对于新生长的病变非常重要,即使是在不常见的部位。
- 对于局部晚期直肠癌,新辅助放化疗可能是有效的,但有些患者可能反应不佳。
- 基因变异可能与直肠癌对新辅助治疗的敏感性或耐药性有关。
- 在直肠癌肿瘤中发现 1p、8p、17p 和 18q 染色体的丢失以及 1q 和 13q 染色体的增加。
- 特定染色体区域的改变与新辅助治疗的反应有关。
- 肿瘤细胞的细胞遗传学特征可能影响直肠癌对放化疗的反应。
- 鼻咽癌的调强放射治疗在局部控制和总体生存率方面取得了良好的长期结果。
- 急性毒性包括粘膜炎、皮炎和口干症,大多数患者经历 0-2 级毒性。
- 晚期毒性主要包括口干症,随着时间的推移会有所改善。
- 远处转移仍然是治疗失败的主要原因,凸显了对更有效的全身治疗的需求。
作为测试,我们可以准确地看到选择了哪三篇文章:
# 提取文章 URI
article_uris = [article[ "article_URI" ] for article in response[ "data" ][ "Get" ][ "Articles_with_abstracts_and_URIs" ]]
# 用于仅对给定 URI 进行响应过滤的函数
def filter_articles_by_uri ( response, article_uris ):
filtered_articles = []
articles = response[ 'data' ][ 'Get' ][ 'Articles_with_abstracts_and_URIs' ]
for article in articles:
if article[ 'article_URI' ] in article_uris:
filtered_articles.append(article)
returnfiltered_articles
# 过滤响应filtered_articles
= filter_articles_by_uri(response, article_uris) # 输出过滤后
的文章
print ( "Filtered articles:" )
for article infiltered_articles: print ( f"Title: {article[ 'title' ]} " ) print ( f"URI: {article[ 'article_URI' ]} " )打印( f"摘要:{article[ 'abstractText' ]} " )打印( f"MeshMajor:{article[ 'meshMajor' ]} " )打印( "---" )
有趣的是,第一篇文章是关于牙龈肿瘤的,它是口腔肿瘤的一个子集,但第二篇文章是关于直肠癌的,第三篇文章是关于鼻咽癌的。它们是关于癌症的治疗方法,但不是我要搜索的那种癌症。令人担忧的是,提示是“口腔肿瘤的治疗方法”,结果却包含有关其他类型癌症治疗方法的信息。这就是有时所谓的“上下文中毒”——无关或误导性的信息被注入到提示中,导致 LLM 做出误导性回应。
我们可以使用 KG 来解决上下文中毒问题。下图展示了向量数据库和 KG 如何协同工作以实现更好的 RAG 实现:

首先,我们使用相同的提示对向量数据库进行语义搜索:口腔癌疗法。这次我将限制提高到 20 篇文章,因为我们要过滤掉一些文章。
response = (
client.query
.get( "articles_with_abstracts_and_URIs" , [ "title" , "abstractText" , "meshMajor" , "article_URI" ])
.with_additional([ "id" ])
.with_near_text({ "concepts" : [ "therapies for mouth neoplasms" ]})
.with_limit(20)
. do ()
)
# 提取文章 URI
article_uris = [article[ "article_URI" ] for article in response[ "data" ][ "Get" ][ "Articles_with_abstracts_and_URIs" ]]
# 打印提取的文章 URI
print ( "Extracted article URIs:" )
for uri in article_uris:
print (uri)
接下来我们使用与之前相同的排序技术,使用与口腔肿瘤相关的概念:
从rdflib导入URIRef
# 使用 FILTER 为文章 URI 构建 SPARQL 查询
query = """
PREFIX schema: <http://schema.org/>
PREFIX ex: <http://example.org/>
SELECT ?article ?title ?abstract ?datePublished ?access ?meshTerm
WHERE {
?article a ex:Article ;
schema:name ?title ;
schema:description ?abstract ;
schema:datePublished ?datePublished ;
ex:access ?access ;
schema:about ?meshTerm .
?meshTerm a ex:MeSHTerm .
# 过滤以仅包含来自 URI 列表的文章
FILTER (?article IN (%s))
}
"""
# 将 URIRefs 列表转换为适合 SPARQL 的字符串
article_uris_string = ", " .join([ f"< { str (uri)} >" for uri in article_uris])
# 将文章 URI 插入查询
query = query % article_uris_string
# 用于存储文章及其相关 MeSH 术语的字典
article_data = {}
# 为每个 MeSH 术语运行查询
for mesh_term in mesh_terms:
results = g.query(query, initBindings={ 'meshTerm' : mesh_term})
# 处理结果
for row in results:
article_uri = row[ 'article' ]
if article_uri not in article_data:
article_data[article_uri] = {
'title' : row[ 'title' ],
'abstract' : row[ 'abstract' ],
'datePublished' : row[ 'datePublished' ],
'access' : row[ 'access' ],
'meshTerms' : set ()
}
# 将 MeSH 术语添加到此文章的集合
article_data[article_uri][ 'meshTerms' ].add( str (row[ 'meshTerm' ]))
# 按匹配的 MeSH 术语数量对文章进行排名
ranked_articles = sorted (
article_data.items(),
key= lambda item: len (item[ 1 ][ 'meshTerms' ]),
reverse= True
)
# 输出
结果article_uri, ranked_articles中的数据:
print ( f"标题:{data[ 'title' ]} " )
print ( f"摘要:{data[ 'abstract' ]} " )
print ( "MeSH 术语:" )
for mesh_term in data[ 'meshTerms' ]:
print ( f" - {mesh_term} " )
print ()
只有三篇文章被标记为口腔肿瘤术语之一:
- 第四条: “针对吸烟者的口腔恶性病变筛查可行性研究。”标签:口腔肿瘤。
- 第 15 篇文章: “光动力疗法治疗大鼠腭粘膜化学诱发的癌前病变和鳞状细胞癌。”这篇文章介绍了一种在大鼠身上测试的腭癌实验性癌症疗法(光动力疗法)。标签:腭肿瘤。
- 文章 1: “牙龈转移是上皮样恶性间皮瘤多器官播散的首发征兆。”标签:牙龈肿瘤。
我们将这些发送到 LLM 看看结果是否有所改善:
# 过滤响应
filtered_articles = filter_articles_by_uri(response, matching_articles)
# 将标题和摘要合并为一个文本块的函数
def Combine_abstracts ( Filtered_articles ):
Combined_text = "\n\n" .join(
[ f"Title: {article[ 'title' ]} \nAbstract: {article[ 'abstractText' ]} " for article in Filtered_articles]
)
return Combined_text
# 从过滤后的文章中合并摘要
combined_text = Combined_abstracts(Filtered_articles)
# 生成并打印摘要
summary = generate_summary(Combined_text)
print (summary)
结果如下:
- 口腔癌很常见,通常直到晚期才被发现
- 进行了一项可行性研究,以提高高风险地区口腔癌和癌前病变的早期发现率
- 烟草供应商参与向吸烟者分发传单,要求全科医生免费检查
- 研究中包括 93 名患者,其中 27% 被转诊给专科医生
- 63.6% 的转诊患者实际上看过专科医生,其中 15.3% 被诊断出患有癌前病变
- 在患有化学诱发的癌前病变和腭粘膜鳞状细胞癌的大鼠中,研究了光动力疗法 (PDT) 作为一种实验性癌症疗法
- 使用光敏素和两种不同的激活波长进行 PDT,在 514.5 nm 组看到更好的效果
- 恶性间皮瘤的牙龈转移极为罕见,存活率低
- 一项案例研究显示,一名患者的牙龈肿块是恶性间皮瘤多器官复发的第一个迹象恶性间皮瘤,强调了对所有新病变进行活检的重要性,即使是在不常见的解剖部位。
我们确实可以看到进步——这些结果与直肠癌或鼻咽肿瘤无关。这看起来像是对所选三篇关于口腔肿瘤疗法的文章的相对准确的总结
结论
总体而言,向量数据库非常适合快速启动和运行搜索、相似性(推荐)和 RAG 应用程序。所需的开销很少。如果您有与结构化数据相关联的非结构化数据,例如本例中的期刊文章,它可以很好地工作。例如,如果我们没有文章摘要作为数据集的一部分,那么它就不会那么有效。
KG 非常适合准确性和控制。如果您想确保输入到搜索应用程序中的数据是“正确的”,而“正确”是指您根据自己的需求做出的任何决定,那么就需要使用 KG。KG 可以很好地用于搜索和相似性,但它们满足您需求的程度取决于元数据的丰富程度和标记的质量。标记质量也可能意味着不同的事情,具体取决于您的用例——如果您构建的是推荐引擎而不是搜索引擎,则构建分类法并将其应用于内容的方式可能会有所不同。
使用知识图谱过滤矢量数据库中的结果可获得最佳结果。这并不奇怪——我使用知识图谱过滤掉我自己认为不相关或误导的结果,因此在我看来,结果当然更好。但关键在于:知识图谱本身不一定能改善结果,而是知识图谱为您提供了控制输出以优化结果的能力。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/5923