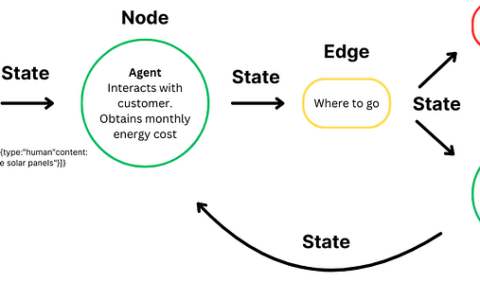
第一部分:问题陈述
在 CVS Health,我们一直在寻找增强电子商务平台cvs.com的方法。一种有希望的途径是在我们的产品描述页面 (PDP) 上实施互补的产品捆绑推荐功能。想象一下,一位顾客浏览牙刷时,看到牙膏、牙线、漱口水、牙齿美白套装等产品的推荐——这些产品自然搭配在一起。您可以在我们网站的每个 PDP 的“经常一起购买 (FBT)”部分下找到此版本。
传统上,关联规则挖掘或购物篮分析等技术已用于识别经常一起购买的产品。虽然这些传统方法很有效,但我们的目标是利用更先进的推荐系统技术来创建更有意义和协同作用的捆绑产品。这涉及利用图神经网络 (GNN) 和生成式 AI 等现代算法。
本文的重点是将FBT功能扩展到FBT Bundles。与常规FBT不同,FBT Bundles提供的推荐较少(一个捆绑包包括源产品和另外两个推荐),捆绑包中的每个项目都与其他项目具有很强的协同作用。我们设想此功能通过算法组装高质量的捆绑包,例如:
- 自我护理套餐(香薰蜡烛+沐浴盐+面膜)
- 旅行套装(颈枕+旅行适配器+洗漱用品)
这一策略不仅可以促进销售,还可以增强客户体验,提高忠诚度。
目前,我们尚未在生产中使用FBT Bundles功能,但我们正在探索开发最小可行产品 (MVP)。本文概述了我们的历程以及我们为实现这一目标所采用的方法。
第二部分:高级方法
我们的解决方案的核心涉及图神经网络 (GNN) 架构。受 Yan 等人 (2022) 的启发,我们调整了他们的 GNN 框架以适应我们的用例,并融入了我们自己的修改和增强功能。
该实施方案由三个主要部分组成:
- 使用 GNN 进行产品嵌入
- 使用转换器的用户嵌入
- 个性化推荐的重新排序方案
以下是我们技术解决方案的概述:
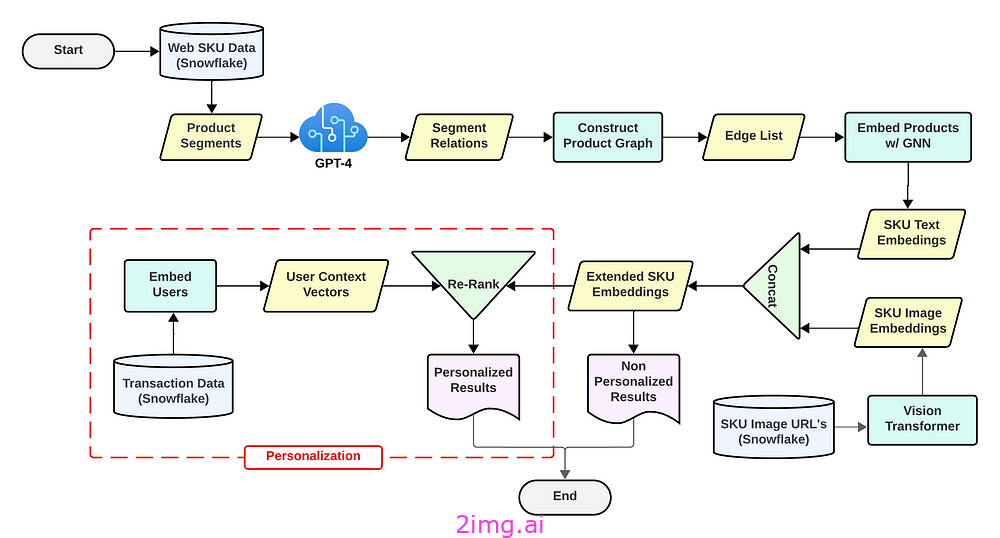
第三部分:深入方法论
第 1 部分:产品嵌入
模块 A:使用 GPT-4 发现产品细分互补关系
嵌入的概念在该解决方案中发挥了重要作用。这项新技术将文本(例如产品名称)转换为数字向量,使机器学习模型能够理解单词之间的语义关系。
我们将使用 GNN 为每件产品生成一个嵌入,这样相关且互补的产品在嵌入空间中就会更接近。要训练这个 GNN,需要产品关系图。
在 Yan et al. (2022) 的论文中,作者引用了 Hao et al. (2020) 的一种方法,该方法基于用户交互数据构建图表。该方法分析了产品共同购买、共同浏览和浏览后购买的模式。我们也尝试了这种实现方式,但由于数据极其嘈杂,结果并不令人满意。具体来说,我们观察到 CVS 顾客在购物时通常有多种目的;因此,在一次会话中购买两件商品并不一定意味着这些商品是互补的。
为了说明这一点,以下是我们进行的探索性数据分析 (EDA) 的一些亮点:
- 我们从近期 100 万笔涉及多件商品的交易中抽样。平均而言,每笔交易中 85% 的商品来自不同的产品类别。
- 此外,我们手动检查了 500 笔随机选择的交易,并标记了哪些项目是互补的。在这些抽样交易中,81% 的交易至少有一项与其他项目完全无关。
从我们的分析中可以得出的结论是,仅凭交易数据并不能可靠地识别产品互补性。我们需要一种更准确的方法,幸运的是,我们拥有生成式人工智能的力量(此外,CVS 有一个人工智能治理审查程序来评估和降低风险,我们遵守了必要的流程)。通过利用 GPT-4,我们可以从所有可用产品的列表中询问哪些其他产品与给定产品互补。但是,鉴于该电子商务网站精选了超过 25,000 种产品,在提示中包含所有产品标题将耗时且昂贵。因此,我们决定在产品层次结构树的更高级别上工作。以下是可能的示例:
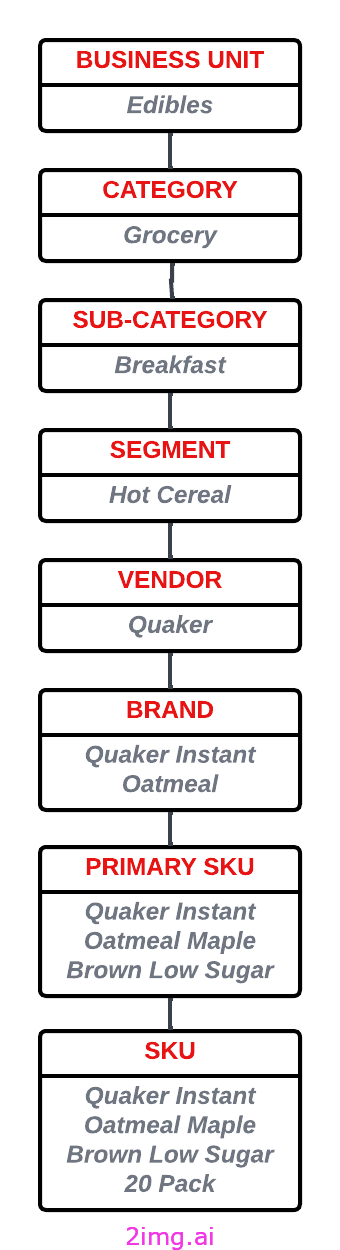
请注意,CVS 的产品目录分为几个层次,SKU位于最底层。随着我们向上移动,我们会遇到诸如品牌、细分、类别等级别。我们确定细分级别提供了有意义的粒度。大约有 600 个不同的产品细分。对于每个细分,我们使用 GPT-4 API 从可用列表中确定前 10 个最互补的细分。在 Mac 上本地运行此过程大约需要 2 个小时,根据 OpenAI API 的公开定价,估计成本为 162 美元:
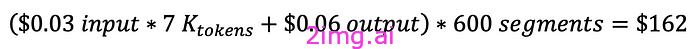
模块 B:评估 GPT-4 输出
为了确保 GPT 输出的准确性和相关性,我们实施了如下概述的全面评估流程。
1.准备精选数据集
- 抽样:我们对所有产品类别进行了约 10% 的抽样。
- 修改后的提示:对于此示例,我们使用修改后的提示运行了 GPT-4 步骤,要求提供 30 个互补片段,而不是通常的 10 个。
- 人工审查:人工审查样本中的每个片段,以过滤掉不相关的片段映射,从而创建真实数据集。
- 最小化偏见:为了最小化偏见,多个审阅者将评估相同的数据集,最终的基本事实是重叠的共识。
2. GPT-4 的完整通过
- 经验映射:然后我们正常运行 GPT-4 以生成经验互补段映射,其中每个源段对应 10 个互补段。
3.计算指标
指标计算:利用经验映射和精选的基本事实,我们计算出以下指标:
- 精度@K(P@K):测量 GPT-4 识别出的与基本事实实际互补的前 k 个片段的比例(k=10)。
- 平均倒数等级(MRR):GPT-4 输出中第一个相关互补段的倒数等级,在所有映射中取平均值。
- 标准化折扣累积增益 (NDCG):为相关段较早出现的列表分配更高的分数。
- 命中率:GPT-4 根据事实识别出至少一个补充片段正确的片段比例。
4. 指标说明
- 范围:所有指标的范围都是从 0 到 1,值越高,表示性能越好。
- 注意事项:这些指标的有效性依赖于基本事实数据集全面充分的假设。虽然我们通过人工审核和多位审核人员精心挑选了高质量的数据集,以尽量减少偏见,但必须承认,没有任何数据集可以完全没有主观性或错误。
以下是我们的评估输出。

评估结果显示其表现强劲。
模块 C:学习产品嵌入
在细分级别确定了互补关系后,我们现在可以缩小到 SKU 级别来构建图表(每个节点都是一个 SKU)。逻辑是,如果两个细分市场A和B是互补的,那么细分市场A下的所有 SKU都会有一条边连接到细分市场B下的所有 SKU 。
GNN 的主要优势之一是其可扩展性潜力,允许结合节点级和边缘级特征。对于节点级特征,我们考虑了产品销售量和价格等属性。作为边缘级特征,我们纳入了共同购买次数。
在实现方面,我们遵循 Yan 等人 (2022) 中描述的模型架构,利用 GNN 的高级版本,即图注意力网络 (GAT)。为了训练 GAT,我们定义了一个自定义损失函数,该函数优先考虑具有以下特征的节点对:
- 它们之间存在着一条边
- 边缘级特征共同购买数量较高
- 节点级特征销售量值较高
- 节点级特征价格值较低
实际上,我们已经可以仅根据产品嵌入进行推荐,其逻辑如下:对于给定产品,我们检索其嵌入,然后在嵌入空间中找到与其具有最高余弦相似度的前 k 个产品。这种方法很有意义,因为在训练 GAT 之后,嵌入空间的结构使得相关和互补的产品在几何上更接近(见下文对此想法的说明)。值得注意的是,我们在此阶段提出的建议是通用的,而不是针对个人用户的个性化建议。

第 2 部分:用户嵌入
用户嵌入的目的是在用户层面个性化我们的推荐。逻辑如下:
- 检索最近的购买:对于每个用户,我们检索他们最近购买的 10 种产品。
- 编码文本特征:我们使用 Word2Vec 将这些产品的文本特征(标题、描述等)编码为向量。
- 转换为用户上下文向量:这些编码的文本特征向量随后被传递到转换器中,该转换器输出单个向量。我们将其称为用户上下文向量,因为它捕获了用户的近期购买历史并很好地表示了他们的偏好。因此,每个用户都有一个用户上下文向量。
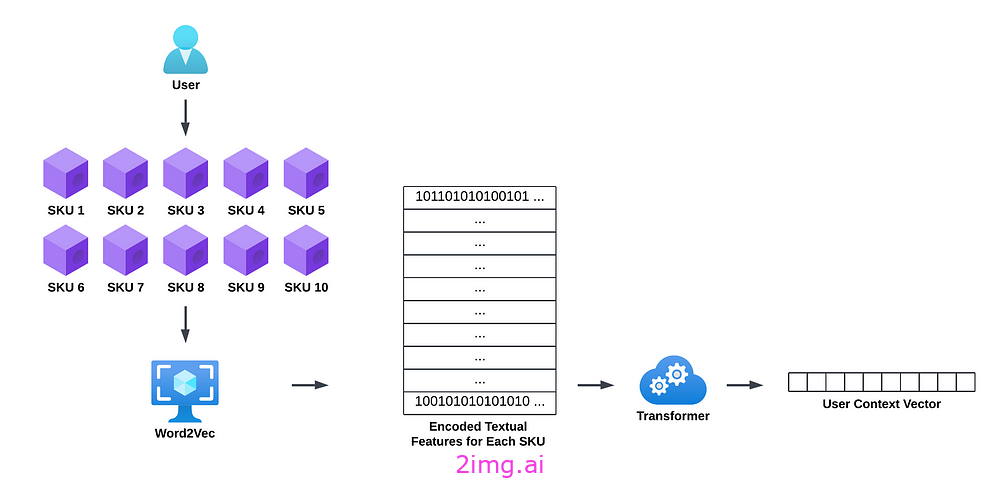
请注意,目前我们仅考虑用户购买历史中最近的 10 件商品来进行个性化设置。未来,我们打算通过纳入人口统计和社会经济变量等其他特征来增强此框架。
第 3 部分:重新排名方案
仅从上一步获得的用户嵌入并不能提供个性化;我们需要额外的步骤来实现这一点。逻辑如下:
- 识别用户上下文嵌入:首先,我们检索想要个性化的用户上下文嵌入。
- 生成非个性化推荐:对于给定的产品,我们根据嵌入空间中的余弦相似度获得前 k 个非个性化推荐。
- 应用个性化:对于每个推荐产品嵌入,我们与用户嵌入向量计算 Hadamard 积(逐元素乘法)。
- 计算重新排序分数:我们对每个结果向量的元素取平均值以获得单个重新排序分数(越高越好)。
- 重新排名推荐:使用这些分数,我们对非个性化推荐进行重新排名,为相关用户创建一组定制推荐。
此过程确保最终的推荐符合用户的特定偏好和最近的购买历史。
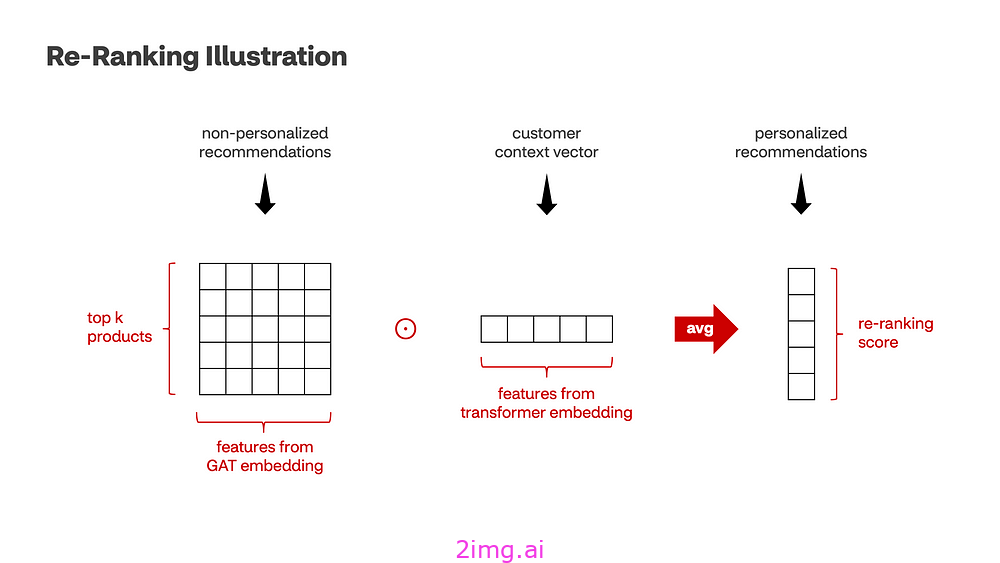
为什么这样做有效?当我们通过元素乘法将非个性化产品嵌入与用户嵌入相结合时,生成的向量会强调用户偏好和产品特征一致的维度(特征)。对结果值取平均值可进一步降低维度,从而提供易于解释的具体分数。该分数反映了用户偏好与产品属性之间的一致程度,使我们能够有效地个性化推荐。
第四部分:推荐输出的评估
请注意,我们使用未标记数据的产品关系图训练模型,因此无法使用准确率或 F1 分数等经典指标进行评估。因此,我们采用了一种略微非传统的离线测试方法,参考了 Chen et al. (2023) 中概述的名为“使用 LLM 进行无参考文本质量评估”的框架。对于我们的FBT Bundles用例,评估逻辑如下:
- 生成建议:我们为每种可用产品生成建议。
- 使用 GPT 进行评估:我们要求 GPT 使用相同的提示对每个捆绑包(1 个源产品 + 2 个推荐)进行评分。GPT 预计会为每个指标返回 1 到 5 之间的分数(5 为最高分):
- 相关性:这些建议是否与源产品相互补充?
- 协同作用:当将捆绑产品作为一个整体考虑时,所有物品是否相互补充?
3. 总分:评估所有捆绑包后,我们对两个指标的分数取平均值,以获得每个捆绑包的总体分数。
结果如下:
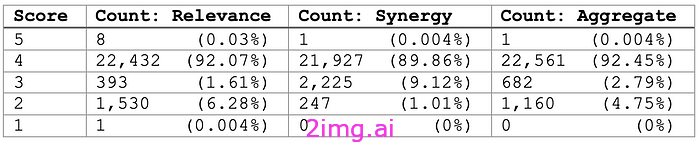
这些结果表明我们的模型能够有效地生成高质量的互补产品包。
第五部分:用例
在 CVS 实施互补产品捆绑推荐系统可为其各个业务领域带来巨大价值。以下是针对公司运营量身定制的两个关键用例:
1. 提高销售和客户体验:在包括店面和药店运营的零售领域,通过推荐相关产品,互补产品推荐可以提高销售量。
2. 高级分析助力决策制定:数据分析团队可以利用互补产品推荐的见解来改进营销策略和库存管理。例如,分析哪些产品经常一起购买可以帮助优化库存水平和促销活动。
第六部分:未来工作
展望未来,有几种途径可以进一步增强我们的互补产品捆绑推荐器:
- 整合更多数据源(例如点击流)
- 广泛的参数微调
- 进行广泛的 A/B 测试
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/5829