
准确估计 GPU 内存对于防止瓶颈并确保大型语言模型的平稳运行至关重要,直接影响部署效率、性能、可扩展性和成本。
简答的说,一个B的大模型参数要求最低1G的显存要求(8位精度的情况下)。
如果是16位精度,则显存要求*2, 32位精度则再*2. 这个对应关系还是很简单的。


正确确定大型语言模型 (LLM) 的硬件大小不仅是技术上的必要,也是确保高效且经济高效部署的基础步骤。LLM 的计算成本很高,并且其内存需求会因多种因素而有很大差异,包括模型大小、精度和部署配置。如果低估了 GPU 内存,您可能会遇到性能瓶颈、内存不足错误,并最终无法成功部署模型。相反,高估 GPU 内存可能会导致不必要的硬件资源支出。
为了应对这些挑战,了解如何准确估算 GPU 内存至关重要。本节将探讨估算 GPU 内存需求的实用公式,深入研究模型精度的影响,研究量化技术的作用,并讨论影响 GPU 内存使用量的其他因素,例如批次大小、序列长度和硬件考虑因素。
在 Ramendeus,我们专门评估 LLM 绩效,以确保它们在不同指标上表现出色并获得高基准分数。凭借通过监督微调和 RLHF 为基础 LLM 公司改进模型的丰富经验,我们拥有帮助您取得卓越成果的专业知识。
相关配图由微信小程序【字形绘梦】免费生成

那么具体我们来看展开学习下:
估算 GPU 内存的公式
可以使用以下公式估算提供 LLM 所需的 GPU 内存:
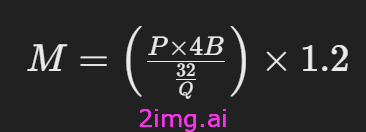
在哪里:
- P:你的 LLM 中的参数数量(例如,LLaMA 为 700 亿)。
- 4B:假设每个参数有 4 个字节(通常为 32 位浮点精度)。
- 问:16 还是 32,取决于您如何加载模型(16 位通常用于减少内存使用)。
- 1.2:在推理(激活等)期间增加 20% 的内存开销。
示例计算
让我们估算使用 16 位精度的 700 亿参数 LLaMA 模型所需的内存:
M=70B×4B16×1.2M = \frac{70B \times 4B}{16} \times 1.2M=1670B×4B×1.2
具体来说:
- 参数(P):700亿
- 每个参数的字节数(4B):4 个字节
- 每个参数的位数(Q):16位
因此,计算如下:
M=70×416×1.2M = \frac{70 \times 4}{16} \times 1.2M=1670×4×1.2 M=17.5×1.2M = 17.5 \times 1.2M=17.5×1.2 M=21GBM = 21 GBM=21GB
然而,如果我们使用 32 位精度重新计算,内存需求就会加倍:
M=70×432×1.2M = \frac{70 \times 4}{32} \times 1.2M=3270×4×1.2 M=35×1.2M = 35 \times 1.2M=35×1.2 M=42GBM = 42 GBM=42GB
因此,在 16 位精度下,700 亿参数的 LLaMA 需要大约 168 GB 的内存。这意味着单个具有 80GB 内存的 NVIDIA A100 GPU 是不够的,在实际场景中,您至少需要两个 GPU 来处理此模型。
实际意义
对于任何部署 LLM 的人来说,此公式都是一个必不可少的工具,因为它提供了一种直接的方法来估计您的硬件设置是否足以满足给定模型的需求。如果估计的内存超出了单个 GPU 的容量,您将需要跨多个 GPU 部署模型,或者考虑使用模型并行或分片等技术。
模型精度
模型精度的选择是影响 GPU 内存使用率的最重要因素之一。较低的精度级别(例如 16 位甚至 8 位)可以大幅减少内存需求,同时保持可接受的准确度水平。下面详细介绍了不同精度级别如何影响内存使用率:
- 32 位浮点精度 (FP32):这是大多数深度学习模型的默认设置,可提供最高的准确度,但需要更多内存。每个参数占用 4 个字节。
- 16 位浮点精度 (FP16):此精度级别占用的内存是 FP32 的一半,被广泛用于 LLM,且准确度不会显著下降。它允许在相同内存中容纳两倍的参数。
- 8 位整数精度 (INT8):主要用于量化,让模型即使在边缘设备也能运行。虽然它可以大幅减少内存使用量,但可能会导致模型准确率下降,不过可以通过仔细调整来缓解。
量化技术
量化是指减少用于表示模型权重和激活的位数的过程。这可以显著减少 LLM 的内存占用,使其成为 GPU 内存受限时的一种宝贵技术。
- 动态量化:该技术根据输入数据在推理过程中动态调整权重的精度。它在减少内存和保持模型准确性之间提供了良好的平衡。
- 静态量化:在此,权重和激活在推理之前进行量化。此方法可最大程度地节省内存,但可能需要更仔细地进行调整以避免性能下降。
在内存限制严格但保持高水平模型精度仍然至关重要的生产环境中提供 LLM 时,量化可能特别有效。
用于估算 GPU 内存的工具和库
有几种工具和库可以帮助估计 GPU 内存需求并优化 LLM 部署:
- Hugging Face 的 Transformers 库:该库包含用于计算模型大小和内存需求的实用程序,尤其是在使用 GPT、BERT 及其变体等流行模型时。
- NVIDIA 的 PyTorch 内存分析器:此工具有助于分析模型的内存使用情况,让您更容易了解可以在哪些地方进行优化。
- DeepSpeed:一个优化库,包含 ZeRO(零冗余优化器)等功能,通过在多个 GPU 上划分模型状态来减少内存使用量。
- TensorFlow Profiler:提供有关内存使用情况和性能指标的详细见解,使开发人员能够微调模型配置以匹配可用的硬件资源。
- NVIDIA Nsight Systems:一款全面的性能分析工具,包含 GPU 内存跟踪功能,允许对跨复杂 GPU 架构的 LLM 部署进行深入优化。
这些工具可以显著简化估算和优化 GPU 内存的过程,尤其是在处理大型模型时。
批次大小注意事项
批次大小是指在训练或推理过程中,一次前向和后向传递中处理的样本数量。批次大小是确定 GPU 内存使用量的关键因素:
- 更大的批处理大小:这通常会消耗更多的 GPU 内存。对于 LLM,使用更大的批处理大小可以缩短训练或推理时间,但需要更多的内存。
- 较小的批处理大小:这些批处理大小更节省内存,但会导致更长的训练时间。然而,在有限的硬件上处理大型模型时,它们通常是必要的。
平衡批次大小和可用的 GPU 内存至关重要,以避免内存不足错误,同时确保模型高效运行。
序列长度注意事项
LLM 可以处理的最大序列长度是影响 GPU 内存要求的另一个关键因素:
- 更长的序列:这些序列需要更多内存来存储激活和梯度,从而导致更高的 GPU 内存使用率。例如,1024 个 token 的序列长度将比 512 个 token 的序列长度需要更多的内存。
- 较短的序列:这些序列更节省内存,但可能无法捕捉到准确预测所需的完整上下文,特别是在机器翻译或长文本生成等任务中。
部署 LLM 时,重要的是考虑应用程序所需的典型序列长度,并相应地调整模型配置以优化内存使用情况。
硬件考虑
并非所有 GPU 都生来平等,不同的架构提供不同级别的内存和计算能力。以下是一些流行的 GPU 架构及其内存能力的细分:
- NVIDIA A100:提供 40GB 或 80GB 内存,支持混合精度训练。它针对 LLM 进行了高度优化,常用于训练和推理。
- NVIDIA H100:A100 的后继产品,提供高达 80GB 的内存,为 LLM 带来更高性能。它旨在处理更大的模型和更复杂的任务。
- NVIDIA V100:提供 16GB 或 32GB 内存,仍然被广泛使用,尽管它可能不足以满足没有模型并行性的最大 LLM 的需求。
- Google TPU v4:提供 32GB 高带宽内存 (HBM),并针对 TensorFlow 工作负载进行了优化。TPU 是 LLM 的 GPU 替代品,但需要仔细考虑内存要求。
选择正确的硬件不仅要确保足够的 GPU 内存,还要考虑其他因素,如计算能力、内存带宽以及跨多个 GPU 扩展的能力。
高效 LLM 部署的架构注意事项
设计一个能够有效利用 GPU 内存同时确保高性能和可扩展性的架构对于部署 LLM 至关重要。部署的架构会对内存占用和系统的整体效率产生重大影响。分享如何使您的架构与讨论的内存估计和优化策略保持一致:
1. 模型并行和分片
当单个 GPU 无法满足 LLM 的内存需求时,模型并行性就成为架构考虑的关键因素。在这种方法中,模型被拆分到多个 GPU 上,每个 GPU 负责模型的一部分参数。这可以减轻单个 GPU 上的内存负担,同时支持部署更大的模型。可以根据内存可用性和工作负载特征,在 GPU 上分配层甚至部分层,从而进一步优化模型分片。
2. 流水线并行
流水线并行通过将模型前向和后向传递的不同阶段分布在多个 GPU 上来补充模型并行。在此架构中,每个 GPU 在顺序流水线中处理模型的不同阶段。这可以更有效地利用 GPU 内存和计算资源,特别是在处理超出单个 GPU 内存容量的超大 LLM 时。
3. 混合精度训练和推理
将混合精度纳入架构中,可以根据计算和内存需求动态调整精度级别(例如,大多数操作使用 FP16,关键层使用 FP32)。此架构不仅优化了内存使用,还加快了训练和推理时间。混合精度的灵活性可确保模型保持准确性,同时显著减少整体内存占用。
4.分布式数据并行
为了处理更大的批次大小和更长的序列长度而不会耗尽内存,可以将分布式数据并行性集成到您的架构中。此方法涉及将数据拆分到多个 GPU 上,每个 GPU 处理数据的一个子集。然后,梯度会在 GPU 之间聚合以更新模型的参数。当批次大小和序列长度对 LLM 的性能至关重要时,此架构特别有用。
5. 内存卸载和交换
尽管进行了其他优化,但 GPU 内存仍然是瓶颈,在这种情况下,采用内存卸载和交换技术可能会改变游戏规则。此架构涉及在训练或推理期间将不常访问的模型参数或中间激活卸载到 CPU 内存甚至磁盘。DeepSpeed 等高级框架提供对内存卸载的内置支持,允许部署原本会超出 GPU 内存限制的 LLM。
6.弹性 GPU 服务
对于大规模部署 LLM 的企业,Elastic GPU Services (EGS) 提供了一种根据实时需求动态分配 GPU 资源的架构。这种架构在混合 GPU 环境中特别有用,在这种环境中,具有不同内存容量的不同 GPU 被编排以最大限度地提高效率并最大限度地降低成本。EGS 还可以与模型并行和内存卸载技术集成,以创建高度可扩展且经济高效的部署架构。
估算 GPU 内存需求的最佳实践
估算 LLM 的 GPU 内存时,请考虑以下最佳实践:
- 从公式开始:使用提供的公式作为基准,根据模型的参数和所需的精度来估算 GPU 内存需求。
- 考虑精度权衡:评估是否可以在不牺牲太多精度的情况下使用 FP16 甚至 INT8 量化。
- 分析内存使用情况:使用 PyTorch 内存分析器等工具获取内存使用情况的实际估计,同时考虑到激活和其他因素的开销。
- 优化批次大小和序列长度:根据可用的硬件调整这些参数,以确保您的模型能够高效运行而不会达到内存限制。
- 开销计划:始终考虑开销裕度以考虑推理期间的额外内存使用,尤其是在使用动态模型或复杂架构时。
- 利用模型并行性:如果单个 GPU 不够用,可以考虑将模型拆分到多个 GPU 上或使用模型分片等技术。
结论
准确估计 GPU 内存对于高效部署 LLM 至关重要,因为它直接影响性能和成本效益。通过利用提供的内存估计公式并考虑模型精度、批量大小和序列长度等因素,您可以战略性地平衡硬件资源以避免瓶颈。量化和模型并行等高级技术进一步增强了您在有限硬件上部署大型模型的能力。将这些考虑因素纳入您的规划过程可确保您的 LLM 顺利运行,优化资源分配并在实际应用中提供预期结果。最终,周到的内存估计是任何企业环境中可扩展、高性能 LLM 部署的基石。
RA/SD 衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/5742