
本文是对 NVIDIA 团队发表的一篇精彩论文的总结/回顾,该论文提供了一种创建精炼模型的方法。论文链接。他们还在 Llama 3.1 上使用该方法创建了 Minitron 4B 模型,本文提供了该模型的详细信息。
论文摘要
论文提出了一种将结构化权重剪枝与知识蒸馏相结合的技术,以实现模型压缩。结构化剪枝侧重于从模型中移除整个结构(例如神经元、通道),从而在降低计算成本和保持性能之间保持平衡。知识蒸馏用于通过将知识从较大、更准确的教师模型转移到较小的、经过剪枝的学生模型来保持准确性。这是一种创建较小蒸馏模型的有效方法。
涵盖的内容
- 本文讨论了修剪方法,包括背景、符号和获取修剪模型的过程。
- 它还涵盖了再训练过程,结合知识提炼,这有助于恢复或保留修剪模型的性能。
- 此外,它概述了结构化压缩的最佳实践,包括详细的指南和策略。
剪枝方法与知识提炼
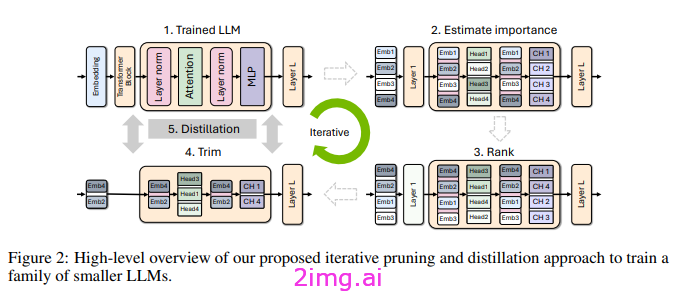

逐步流程
- 计算每一层、神经元、头部和嵌入的重要性。这可以根据权重和深度来完成。
- 根据重要性得分进行排序以获得排名。
- 获取修剪后的模型,使用教师模型进行蒸馏。
使用的符号
这篇论文介绍了结构化剪枝,其中剪枝应用于权重组(例如通道、过滤器),而不是单个权重。数学背景包括定义原始模型的损失函数,然后对其进行修改以包含剪枝约束。
让W表示模型的权重。修剪过程旨在找到W的稀疏版本,表示为W p ,它最小化原始损失函数,并添加正则化项来强制稀疏性。
重要性分数是如何计算的?
- 人们已经研究了多种理解组件重要性的方法,例如使用权重大小来估计重要性、梯度计算等,但对于 LLM 来说可能不是那么有效,因为它们的规模庞大。
- 重要性分数是针对不同结构(例如通道或神经元)计算的。这些分数决定了模型中哪些部分不太重要,可以删除。
- 本文作者提出的有效替代方案如下:
- 宽度(神经元、头部):头部/神经元产生的激活有助于计算分数。为此,使用较小的校准数据集,从而使过程更快。为了汇总轴上的最终分数(来自不同的层),尝试了三种类型的函数:
– 平均值
– L2 范数
– 方差 - 深度(层):这里的重要性以两种方式计算:
–困惑度:要计算某一层的重要性,首先将其移除,然后计算其对修剪模型的困惑度的影响。帮助我们了解该层的敏感度。
–块重要性:此方法使用层的输入和输出之间的余弦相似度来了解特定层对输出的影响程度。敏感度越低,变化越大。 - 迭代重要性:在此过程中,宽度和深度重要性方法交替使用,以使用组合来获得重要性,从而使该过程变得稳健。
- 观察发现,对于批次内 L2 范数和序列聚合,平均值在 8 万亿个标记时表现最佳。
再培训
论文中使用的“再训练”一词指的是“准确度恢复过程”。讨论了两种不同的策略:
- 使用真实标签
- 使用来自教师(未剪枝)模型的软标签进行知识提炼
使用教师模型进行知识蒸馏
知识蒸馏 (KD) 是将知识从较大或较复杂的模型(称为“老师”)转移到较小或较简单的模型(称为“学生”)的过程。这种转移是通过训练学生模型来复制老师模型的输出和/或中间表示来实现的。在我们的上下文中,未压缩的模型充当老师,而修剪后的模型充当学生。该过程使用各种损失函数进行了实验
再培训步骤:
- 使用剪枝后的权重初始化学生模型。
- 使用教师模型生成软标签。
- 使用软标签(来自老师)和硬标签(真实标签)训练学生模型,以最小化组合损失函数。
观察到的最佳实践:
- 首先训练最大的 LLM,然后逐步修剪和提炼它以创建一系列较小的 LLM。
- 为了估计沿宽度轴的重要性,使用(batch=L2,seq=mean)并应用 PPL/BI 进行深度分析。
- 选择单次重要性估计,因为迭代方法不提供额外的优势。
- 对于参数规模高达 15B 的模型,宽度修剪优先于深度修剪。
- 使用 KLD 的蒸馏损失重新训练模型,绕过传统的训练方法。
- 当显著减少深度时,使用 logits、中间状态和嵌入进行蒸馏。
- 当深度减少最小时,使用仅对数蒸馏。
- 修剪尺寸最接近所需目标的模型。
- 应用轻量级再训练来稳定修剪候选者的排名。
- 如果最大的模型经过多阶段训练,则从最后的训练阶段开始修剪并重新训练模型。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/5706