
Transfusion 是 Meta 团队开发的一种新模型,使用统一模型生成文本和图像。该模型在文本和图像数据的均等混合上进行预训练,应用不同的目标:文本的下一个标记预测和图像的扩散。该模型同时处理这两种模式,将文本转换为向量,将图像表示为补丁序列。因果注意力用于文本,双向注意力用于图像。对于推理,该模型结合了文本和图像生成的技术。
与 Chameleon 的方法 [ link ]相比,Transfusion 在所有模式下的扩展效果都更佳。在文本转图像任务中,Transfusion 以极低的计算成本取得了更好的结果,同时 FID 和 CLIP 得分也得到了提升。在图像转文本任务中,它仅用 21.8% 的计算量就达到了 Chameleon 的性能。即使在纯文本任务中,Transfusion 也仅用 Chameleon 计算负载的 50% 到 60% 就达到了类似的困惑度。
消融研究表明,图像内双向注意力对于性能至关重要,因为用因果注意力代替它会降低文本到图像任务的效率。添加用于图像处理的 U-Net 块可让模型高效压缩图像,将服务成本降低多达 64 倍,同时对性能的影响极小。
Transfusion 的功能通过在包含 1T 文本标记和 1T 图像块的大规模数据集上训练 7B 参数转换器得到进一步展示。该模型生成的图像与 DALL-E 2 和 SDXL 等顶级扩散模型相当,同时还实现了与 Llama 1 类似的文本生成性能。这凸显了 Transfusion 作为生成文本和图像的强大多模态模型的潜力。
对于想要了解详细信息的读者,可以在此处查看该论文。此外,还有一个使用 PyTorch 编写的与本文相关的非官方存储库,可以在此处找到。这个存储库的功劳归功于Phil Wang,因为他做了出色的工作。
语言建模
语言建模语言模型预测来自封闭词汇表V的离散标记序列 y = y_1, y_2,…..,y_n 的概率。该模型将总体概率 P(y) 分解为条件概率的乘积,如下所示:
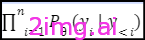

上述等式属于一种称为自回归建模的方法,其中每个标记 y_i 的概率取决于前面的标记 y< i,并使用由 θ 参数化的单一分布 P_θ 进行预测。
通过最小化预测分布 Pθ 与数据的实际经验分布之间的交叉熵来优化模型。此优化过程通常称为下一个标记预测目标或语言建模 (LM) 损失,数学上表示为:
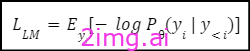
扩散
去噪扩散概率模型 (DDPM) 是一种生成模型,专注于学习逆转应用于数据的噪声添加过程。虽然语言模型通常处理离散标记,但 DDPM 专为连续数据而设计,使其成为图像处理的理想选择。该框架包括两个主要过程:
- 前向过程:一种系统地将高斯噪声添加到数据中,最终将其转换为纯噪声的方法。
- 逆过程:一种去噪机制,其中模型学习从噪声版本中重建原始数据。
正向过程:
前向过程通过逐步添加高斯噪声,在 T 步中创建一系列逐渐增加噪声的原始数据版本,表示为 x1、x2、…、xT。每一步都遵循以下分布:
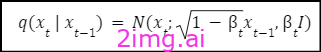
这里,t控制每一步的噪声水平,并按照预定义的时间表增加。
逆向过程:
逆向过程旨在去噪,从噪声数据 xt 开始,逐步预测原始数据。模型 ϵθ(xt, t, c) 经过训练,可估计每一步 t 中存在的噪声,其中通过最小化均方误差来优化预测:
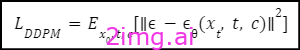
这种方法使得模型能够有效地从噪声数据中重建原始数据。
噪音一览表:
每一步t添加的噪声的方差由“α bar”控制(如下所示)。该模型通常使用余弦调度器,其近似为:
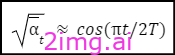
这种调度有助于在转发过程中增加的噪声中保持平衡。
推理:
在推理过程中,模型从纯高斯噪声开始,并在每一步迭代降低噪声。模型(屏幕截图中给出的符号)预测要减去的噪声,从而生成更清晰的数据,直到重建原始数据。
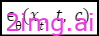
输血
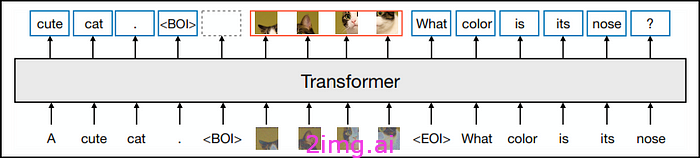
Transfusion 是一种创新的训练方法,它使统一的模型能够处理离散(如文本)和连续(如图像)数据类型。这种方法的关键突破是使用针对每种模态量身定制的不同损失函数——对文本采用语言建模,对图像采用扩散过程——同时共享相同的基础数据和模型参数。这使得模型能够在单一框架内有效地理解和生成不同模态。上图给出了 Transfusion 的完整概念。
数据准备
这种方法中的数据表示涵盖离散文本和连续图像。文本根据固定词汇被标记为整数序列。图像使用变分自动编码器 (VAE) 编码为连续向量块,按顺序排列。对于混合模态数据,图像序列在合并到文本序列之前用特殊的 BOI(图像开头)和 EOI(图像结尾)标记括起来,从而产生包含离散元素和连续元素的组合序列。
模型架构
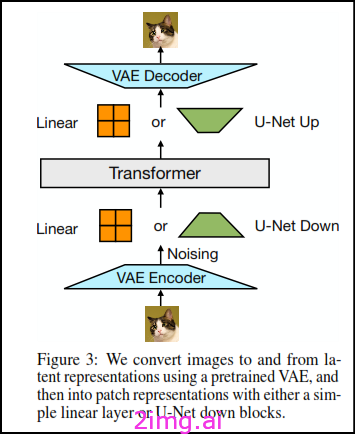
该模型主要依靠单个转换器来处理不同模态的序列。它对高维向量进行操作,并使用特定于模态的组件将数据转换为此向量空间。对于文本,嵌入矩阵将整数映射到向量,并将向量映射回离散分布。对于图像,两种方法将 kxk 补丁向量压缩为转换器向量:线性层和 U-Net 上下块。
输血注意事项
Transfusion Attention 集成了两种注意力机制,可有效管理文本和图像。语言模型使用因果掩蔽来处理没有未来标记信息的序列,非常适合文本的顺序结构。另一方面,图像通常使用双向注意力来实现图像内的完全交互。Transfusion 在整个序列中应用因果注意力,并在每个图像内应用双向注意力。这允许每个图像块在其自己的图像内完全交互,同时仅关注序列中的前一个文本或图像,从而显着提高性能。

培训目标
该模型的训练目标集成了两个损失函数:用于文本标记的语言建模损失 LLM 和用于图像块的扩散损失 LDDPM。语言建模损失是按标记计算的,而扩散损失是按图像计算的,图像可能包括多个块。在将清晰图像分成块之前,根据扩散过程将噪声添加到清晰图像中,然后计算图像级扩散损失。这两个损失通过将它们与平衡系数 λ 相加而组合在一起:
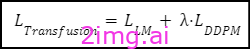
这种方法代表了一种更广泛策略的具体实例,该策略将离散和连续分布损失结合在一个模型中。未来的工作可能会探索替代方案,例如用流匹配代替扩散。
优化
优化使用 AdamW,参数为 β1=0.9、β2=0.95、=0.9 和 ϵ= 1×10^–8。学习率从 3×10^–4 开始,经过 4000 步预热,然后使用余弦调度程序衰减至 1.5×10^–5。训练涉及 250k 步的 2M 令牌批次中的 4096 个令牌序列,总计 0.5T 个令牌。更大规模的实验使用 500k 步的 4M 令牌批次,达到 2T 个令牌。正则化包括 0.1 权重衰减和范数 1.0 的梯度裁剪。系数 λ 设置为 5,计划进行未来调整。
推理
推理过程在语言建模 (LM) 和扩散模式之间交替进行。在LM 模式中,标记是从预测分布中按顺序采样的。当出现图像开头 (BOI) 标记时,模型将切换到扩散模式,将噪声 xT 作为图像补丁附加并在 T 步中进行去噪。该模型在每个步骤中预测和更新序列,以最后一步为条件。生成图像后,添加图像结尾 (EOI) 标记,然后模型返回到 LM 模式。此方法可以无缝生成混合文本和图像序列。
完整代码请移步 Phil Wang 的repo。
结论
这篇评论论文探讨了一个旨在整合离散和连续模态的模型的关键方面,重点是文本和图像处理。通过利用输血注意、特定于模态的组件和统一的训练目标等创新,该模型展示了有效的跨模态学习的潜力。优化策略(包括使用 AdamW 和精心安排学习率)进一步提高了模型的稳健性和可扩展性。随着该领域的不断发展,仍有机会增强这些模型,例如改进损失函数和探索流匹配等替代方法。这里回顾的工作为多模态学习的未来发展奠定了坚实的基础,并为在单一模型架构中集成不同数据类型的复杂性提供了宝贵的见解。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/5694