
人工智能最近的成功通常归功于 GPU 的出现和发展。GPU 的架构通常包括数千个多处理器、高速内存、专用张量核心等,特别适合满足人工智能/机器学习工作负载的密集需求。不幸的是,人工智能开发的快速增长导致对 GPU 的需求激增,使其难以获得。因此,机器学习开发人员越来越多地探索用于训练和运行其模型的替代硬件选项。在之前的帖子中,我们讨论了在专用人工智能 ASIC(如Google Cloud TPU、Haban Gaudi和AWS Trainium)上进行训练的可能性。虽然这些选项提供了显着的成本节省机会,但它们并不适合所有机器学习模型,并且与 GPU 一样,也可能受到可用性限制的影响。在这篇文章中,我们回到老式的 CPU,并重新讨论它与机器学习应用程序的相关性。虽然与 GPU 相比,CPU 通常不太适合机器学习工作负载,但它们更容易获得。在 CPU 上运行(至少部分)工作负载的能力可能会对开发效率产生重大影响。
在之前的文章我们强调了分析和优化 AI/ML 工作负载的运行时性能作为加速开发和降低成本的重要性。尽管无论使用哪种计算引擎,这都至关重要,但分析工具和优化技术在不同平台之间可能有很大差异。在本文中,我们将讨论一些与 CPU 相关的性能优化选项。我们的重点是英特尔® 至强® CPU处理器(带有英特尔® AVX-512)和 PyTorch(版本 2.4)框架(尽管类似的技术也可以应用于其他 CPU 和框架)。更具体地说,我们将在带有AWS 深度学习 AMI的Amazon EC2 c7i实例上运行我们的实验。请不要将我们对云平台、CPU 版本、ML 框架或我们提及的任何其他工具或库的选择视为对其替代方案的认可。
我们的目标是证明,尽管在 CPU 上进行 ML 开发可能不是我们的首选,但仍有方法可以“减轻打击”,并且在某些情况下甚至可能使其成为可行的替代方案。
免责声明
我们在本文中的目的是展示 CPU 上可用的一些 ML 优化机会。与大多数关于 CPU 上的 ML 优化主题的在线教程相反,我们将重点关注训练工作负载而不是推理工作负载。有许多专门针对推理的优化工具我们不会介绍(例如,请参阅此处和此处)。
请不要将本文视为我们提到的任何工具或技术的官方文档的替代品。请记住,鉴于 AI/ML 开发的快速发展,我们提到的一些内容、库和/或说明在您阅读本文时可能已经过时。请务必参考最新的可用文档。
重要的是,我们讨论的优化对运行时性能的影响可能会根据模型和环境细节而有很大差异(例如,在官方 PyTorch TouchInductor CPU 推理性能仪表板上查看模型之间的高度差异)。我们将分享的比较性能数字特定于我们将使用的玩具模型和运行时环境。请务必在您自己的模型和运行时环境中重新评估所有建议的优化。
最后,我们将只关注吞吐量性能(以每秒样本数衡量),而不是训练收敛。但是,应该注意的是,某些优化技术(例如,批量大小调整、混合精度等)可能会对某些模型的收敛产生负面影响。在某些情况下,可以通过适当的超参数调整来克服这一点。
示例——ResNet-50
我们将在具有ResNet-50主干的简单图像分类模型(来自深度残差学习图像识别)上运行实验。我们将在虚假数据集上训练模型。完整的训练脚本出现在下面的代码块中(大致基于此示例):
import torch
import torchvision
from torch.utils.data import Dataset, DataLoader
import time
# A dataset with random images and labels
class FakeDataset(Dataset):
def __len__(self):
return 1000000
def __getitem__(self, index):
rand_image = torch.randn([3, 224, 224], dtype=torch.float32)
label = torch.tensor(data=index % 10, dtype=torch.uint8)
return rand_image, label
train_set = FakeDataset()
batch_size=128
num_workers=0
train_loader = DataLoader(
dataset=train_set,
batch_size=batch_size,
num_workers=num_workers
)
model = torchvision.models.resnet50()
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters())
model.train()
t0 = time.perf_counter()
summ = 0
count = 0
for idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
batch_time = time.perf_counter() - t0
if idx > 10: # skip first steps
summ += batch_time
count += 1
t0 = time.perf_counter()
if idx > 100:
break
print(f'average step time: {summ/count}')
print(f'throughput: {count*batch_size/summ}')在 c7i.2xlarge(具有 8 个 vCPU)和CPU版本的 PyTorch 2.4 上运行此脚本,吞吐量为每秒 9.12 个样本。为了进行比较,我们注意到,在Amazon EC2 g5.2xlarge实例(具有 1 个 GPU 和 8 个 vCPU)上,相同(未优化脚本)的吞吐量为每秒 340 个样本。考虑到这两种实例类型的比较成本(截至本文撰写时,c7i.2xlarge 每小时 0.357 美元,g5.2xlarge 每小时 1.212 美元),我们发现在 GPU 实例上进行训练的性价比大约高出 11 倍(!!)。基于这些结果,使用 GPU 训练 ML 模型的偏好是非常有道理的。让我们评估一些缩小这一差距的可能性。
PyTorch 性能优化
在本节中,我们将探讨一些提高训练工作负载运行时性能的基本方法。虽然您可能从我们关于 GPU 优化的文章中认出了其中一些方法,但重要的是要强调 CPU 和 GPU 平台上的训练优化之间的显著差异。在 GPU 平台上,我们大部分的努力都致力于最大限度地提高 CPU(训练数据预处理)和 GPU(模型训练)之间的并行化。在 CPU 平台上,所有处理都在 CPU 上进行,我们的目标是最有效地分配其资源。
批次大小
通过减少模型参数更新频率,增加训练批次大小可以潜在地提高性能。(在 GPU 上,它具有减少 CPU-GPU 事务(例如内核加载)的开销的额外好处)。但是,虽然在 GPU 上我们的目标是使批次大小能够最大限度地利用 GPU 内存,但相同的策略可能会损害 CPU 上的性能。出于超出本文范围的原因,CPU 内存更为复杂,发现最佳批次大小的最佳方法可能是通过反复试验。请记住,更改批次大小可能会影响训练收敛。
下表总结了几个(任意)批次大小选择的训练工作量的吞吐量:
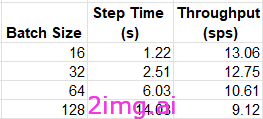

与我们在 GPU 上发现的结果相反,在 c7i.2xlarge 实例类型上,我们的模型似乎更喜欢较低的批量大小。
多进程数据加载
GPU 上的一种常见技术是将多个进程分配给数据加载器,以降低 GPU 出现资源匮乏的可能性。在 GPU 平台上,一般的经验法则是根据 CPU 核心数设置工作器数量。然而,在 CPU 平台上,模型训练使用与数据加载器相同的资源,这种方法可能会适得其反。再次强调,选择最佳工作器数量的最佳方法可能是反复试验。下表显示了不同 num_workers 选择的平均吞吐量:
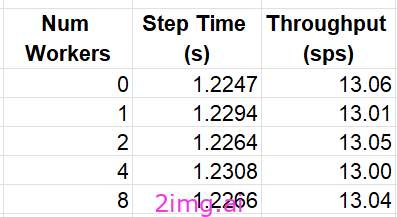
混合精度
另一种流行的技术是使用较低精度的浮点数据类型,例如torch.float16或,torch.bfloat16其动态范围torch.bfloat16通常被认为更适合 ML 训练。当然,降低数据类型精度会对收敛产生不利影响,应谨慎行事。PyTorch 附带torch.amp,这是一个自动混合精度包,用于优化这些数据类型的使用。英特尔® AVX-512 包括对 bfloat16数据类型的支持。修改后的训练步骤如下所示:
for idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
with torch.amp.autocast('cpu',dtype=torch.bfloat16):
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()经过此次优化后的吞吐量为每秒24.34个样本,增加了86%!!
频道最后记忆格式
通道最后内存格式是一种 beta 级优化(在撰写本文时),主要涉及视觉模型,支持将四维 (NCHW) 张量存储在内存中,使得通道是最后一个维度。这会导致每个像素的所有数据都存储在一起。此优化主要涉及视觉模型。这种内存格式被认为更“对英特尔平台友好” ,据报道可提高英特尔® 至强® CPU上 ResNet-50 的性能。调整后的训练步骤如下所示:
for idx, (data, target) in enumerate(train_loader):
data = data.to(memory_format=torch.channels_last)
optimizer.zero_grad()
with torch.amp.autocast('cpu',dtype=torch.bfloat16):
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()最终的吞吐量为每秒 37.93 个样本 — 与我们的基线实验相比,又提高了 56%,总共提高了 415%。我们做得很好!
火炬汇编
在上一篇文章中,我们介绍了 PyTorch 对图形编译的支持及其对运行时性能的潜在影响。与默认的即时执行模式(其中每个操作都独立运行,也称为“即时”)相反,编译API 将模型转换为中间计算图,然后以最适合底层训练引擎的方式将其 JIT 编译为低级机器代码。该 API 支持通过不同的后端库和多个配置选项进行编译。在这里,我们将评估限制在默认( TorchInductor)后端和来自英特尔® PyTorch 扩展的ipex后端,这是一个专门针对英特尔硬件进行优化的库。请参阅文档以获取适当的安装和使用说明。更新后的模型定义如下所示:
import intel_extension_for_pytorch as ipex
model = torchvision.models.resnet50()
backend='inductor' # optionally change to 'ipex'
model = torch.compile(model, backend=backend)在我们的玩具模型中,torch 编译的影响仅在禁用“channels last”优化时才会显现(每个后端的性能提升约 27%)。当应用“channels last”时,性能实际上会下降。因此,我们在后续实验中放弃了这一优化。
内存和线程优化
有许多机会可以优化底层 CPU 资源的使用。这些包括优化内存管理和线程分配到底层 CPU 硬件的结构。可以通过使用高级内存分配器(例如Jemalloc和TCMalloc)和/或减少较慢的内存访问(即跨NUMA 节点)来改进内存管理。可以通过适当配置 OpenMP 线程库和/或使用Intel 的 Open MP 库来改进线程分配。
一般来说,这些优化需要对 CPU 架构及其支持 SW 堆栈的功能有深入的了解。为了简化问题,PyTorch 提供了torch.backends.xeon.run_cpu脚本,用于自动配置内存和线程库,以优化运行时性能。下面的命令将导致使用专用内存和线程库。当我们讨论分布式训练选项时,我们将回到 NUMA 节点的主题。
我们验证TCMalloc(conda install conda-forge::gperftools)和英特尔的 Open MP 库(pip install intel-openmp)的安装是否适当,并运行以下命令。
python -m torch.backends.xeon.run_cpu train.py
使用run_cpu脚本进一步将我们的运行时性能提升至每秒 39.05 个样本。请注意,run_cpu脚本包含许多控件,用于进一步调整性能。请务必查看文档以最大限度地利用它。
PyTorch 的英特尔扩展
英特尔® PyTorch 扩展通过其ipex.optimize函数提供了额外的训练优化机会。这里我们演示了它的默认用法。请参阅文档以了解其全部功能。
model = torchvision.models.resnet50()
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters())
model.train()
model, optimizer = ipex.optimize(
model,
optimizer=optimizer,
dtype=torch.bfloat16
)结合上面讨论的内存和线程优化,最终吞吐量为每秒 40.73 个样本。(请注意,禁用“通道最后”配置时也会达到类似的结果。)
CPU 上的分布式训练
Intel® Xeon®处理器采用非统一内存访问 (NUMA)设计,其中 CPU 内存分为多个组,即 NUMA 节点,每个 CPU 核心都分配给一个节点。虽然任何 CPU 核心都可以访问任何 NUMA 节点的内存,但访问其自己的节点(即其本地内存)要快得多。这产生了在 NUMA 节点之间分布训练的概念,其中分配给每个 NUMA 节点的 CPU 核心充当分布式进程组中的单个进程,节点之间的数据分布由Intel® oneCCL(英特尔专用的集体通信库)管理。
我们可以使用ipexrun 实用程序轻松地在 NUMA 节点之间运行数据分布式训练。在下面的代码块中(大致基于此示例),我们调整脚本以运行数据分布式训练(根据此处详述的用法):
import os, time
import torch
from torch.utils.data import Dataset, DataLoader
from torch.utils.data.distributed import DistributedSampler
import torch.distributed as dist
import torchvision
import oneccl_bindings_for_pytorch as torch_ccl
import intel_extension_for_pytorch as ipex
os.environ["MASTER_ADDR"] = "127.0.0.1"
os.environ["MASTER_PORT"] = "29500"
os.environ["RANK"] = os.environ.get("PMI_RANK", "0")
os.environ["WORLD_SIZE"] = os.environ.get("PMI_SIZE", "1")
dist.init_process_group(backend="ccl", init_method="env://")
rank = os.environ["RANK"]
world_size = os.environ["WORLD_SIZE"]
batch_size = 128
num_workers = 0
# define dataset and dataloader
class FakeDataset(Dataset):
def __len__(self):
return 1000000
def __getitem__(self, index):
rand_image = torch.randn([3, 224, 224], dtype=torch.float32)
label = torch.tensor(data=index % 10, dtype=torch.uint8)
return rand_image, label
train_dataset = FakeDataset()
dist_sampler = DistributedSampler(train_dataset)
train_loader = DataLoader(
dataset=train_dataset,
batch_size=batch_size,
num_workers=num_workers,
sampler=dist_sampler
)
# define model artifacts
model = torchvision.models.resnet50()
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters())
model.train()
model, optimizer = ipex.optimize(
model,
optimizer=optimizer,
dtype=torch.bfloat16
)
# configure DDP
model = torch.nn.parallel.DistributedDataParallel(model)
# run training loop
# destroy the process group
dist.destroy_process_group()不幸的是,截至撰写本文时,Amazon EC2 c7i实例系列不包含多 NUMA 实例类型。为了测试我们的分布式训练脚本,我们恢复到具有 64 个 vCPU 和 2 个 NUMA 节点的Amazon EC2 c6i.32xlarge实例。我们验证了PyTorch 的 Intel® oneCCL Bindings的安装并运行以下命令(如此处所述):
source $(python -c "import oneccl_bindings_for_pytorch as torch_ccl;print(torch_ccl.cwd)")/env/setvars.sh
# This example command would utilize all the numa sockets of the processor, taking each socket as a rank.
ipexrun cpu --nnodes 1 --omp_runtime intel train.py 下表比较了有无分布式训练的c6i.32xlarge实例的性能结果:

在我们的实验中,数据分布并没有提高运行时性能。请参阅ipexrun 文档以获取更多性能调整选项。
使用 Torch/XLA 进行 CPU 训练
在之前的文章(例如,此处)中,我们讨论了PyTorch/XLA库及其对XLA 编译的使用,以便在 TPU、GPU和CPU等XLA 设备上进行基于 PyTorch 的训练。与 torch 编译类似,XLA 使用图形编译来生成针对目标设备优化的机器代码。随着OpenXLA 项目的建立,其中一个既定目标就是支持所有硬件后端(包括 CPU)的高性能(请参阅此处的CPU RFC)。下面的代码块演示了使用PyTorch/XLA进行训练所需的对原始(未优化)脚本的调整:
import torch
import torchvision
import timeimport torch_xla
import torch_xla.core.xla_model as xm
device = xm.xla_device()
model = torchvision.models.resnet50().to(device)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters())
model.train()
for idx, (data, target) in enumerate(train_loader):
data = data.to(device)
target = target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
xm.mark_step()不幸的是,(截至撰写本文时)我们的玩具模型上的 XLA 结果似乎远不如我们上面看到的(未优化)结果(— 高达 7 倍)。我们预计,随着 PyTorch/XLA 的 CPU 支持日趋成熟,这种情况会有所改善。
结果
我们在下表中总结了部分实验的结果。为了便于比较,我们按照本文讨论的优化步骤,添加了在Amazon EC2 g5.2xlarge GPU 实例上训练模型的吞吐量。每美元样本数是根据Amazon EC2 按需定价页面计算的(截至撰写本文时,c7i.2xlarge 每小时 0.357 美元,g5.2xlarge 每小时 1.212 美元)。
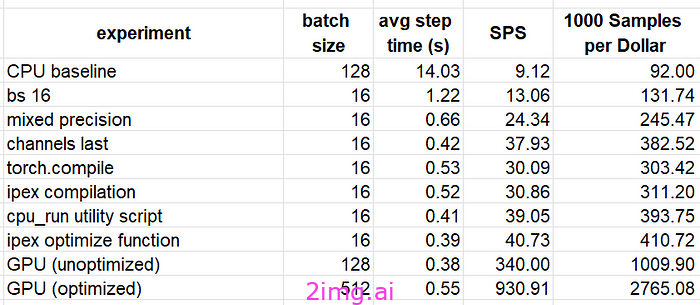
尽管我们成功地将我们的玩具模型在 CPU 实例上的训练性能提升了相当大的幅度(446%),但它仍然不如 GPU 实例上的(优化)性能。根据我们的结果,在 GPU 上进行训练将便宜约 6.7 倍。通过额外的性能调整和/或应用额外的优化策略,我们很可能可以进一步缩小差距。再次强调,我们达到的比较性能结果是该模型和运行时环境所独有的。
Amazon EC2 Spot 实例折扣
基于云的 CPU 实例类型(与 GPU 实例类型相比)可用性的提高可能意味着以折扣价获得计算能力的机会更大,例如通过 Spot 实例利用。Amazon EC2 Spot 实例是来自剩余云服务容量的实例,以高达按需定价 90% 的折扣提供。作为折扣价的交换,AWS 保留在几乎没有警告的情况下抢占实例的权利。鉴于对 GPU 的需求很高,您可能会发现 CPU Spot 实例比 GPU 实例更容易获得。在撰写本文时,c7i.2xlarge Spot 实例价格为 0.1291 美元,这将使我们的每美元样本结果提高到 1135.76 美元,并进一步缩小优化的 GPU 和 CPU 价格性能之间的差距(至 2.43 倍)。
虽然我们的玩具模型(以及我们选择的环境)经过优化的 CPU 训练的运行时性能结果低于 GPU 结果,但将相同的优化步骤应用于其他模型架构(例如,包含 GPU 不支持的组件的模型架构)可能会导致 CPU 性能与 GPU 相当甚至超过 GPU。即使在无法弥补性能差距的情况下,也很可能出现 GPU 计算能力不足的情况,这证明在 CPU 上运行部分 ML 工作负载是合理的。
概括
鉴于 CPU 的普遍性,能否有效地利用它们进行训练和/或运行 ML 工作负载可能会对开发效率和最终产品部署策略产生巨大影响。虽然与 GPU 相比,CPU 架构的性质对许多 ML 应用程序不太友好,但有许多工具和技术可用于提升其性能——我们在本文中讨论并演示了其中的一些。
RA/SD 衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/5688