
今天,我们将探讨语义分块 — 一种显著改善信息检索的技术。如果您一直在关注 AI 的发展,那么您可能对检索增强生成 (RAG) 很熟悉。让我们来看看语义分块如何增强 RAG 系统。


RAG 系统及其挑战
检索增强生成之所以受到欢迎是有充分理由的。它允许 AI 系统通过将信息检索与语言生成相结合来回答问题。标准 RAG 管道通过提取数据、检索相关信息并使用它来生成响应来实现这一点。
然而,随着数据越来越复杂,查询越来越复杂,传统的 RAG 系统可能会面临局限性。这时语义分块就可以发挥作用了。
理解语义分块
语义分块是一种根据内容和上下文将文本或数据划分为有意义的片段的方法,而不是任意的字数或字符限制。
它的典型工作方式如下:
1.内容分析:系统检查文档以了解其结构和内容。
2.智能分割:根据语义连贯性将内容划分为块(完整的想法或独立的解释)。
3.上下文嵌入:每个块在更广泛的文档中保留有关其上下文的信息。
这种方法有助于保留信息中的含义和关系,这对于准确的检索和生成至关重要。
传统方法的局限性
传统的分块方法虽然计算效率高,但也存在一些缺点:
– 他们可以将重要概念分成多个块。
– 他们常常难以维持跨部门的背景。
– 它们可能导致检索不完整或脱节的信息。
这些限制会影响人工智能生成的响应的准确性和相关性,尤其是在处理复杂或细微的信息时。
语义分块实践:一个例子
让我们考虑一个 AI 系统正在分析法律文件的场景。查询可能是:“总结 Smith vs. Jones 版权侵权案中与合理使用相关的关键论点。”
传统系统可能会返回:
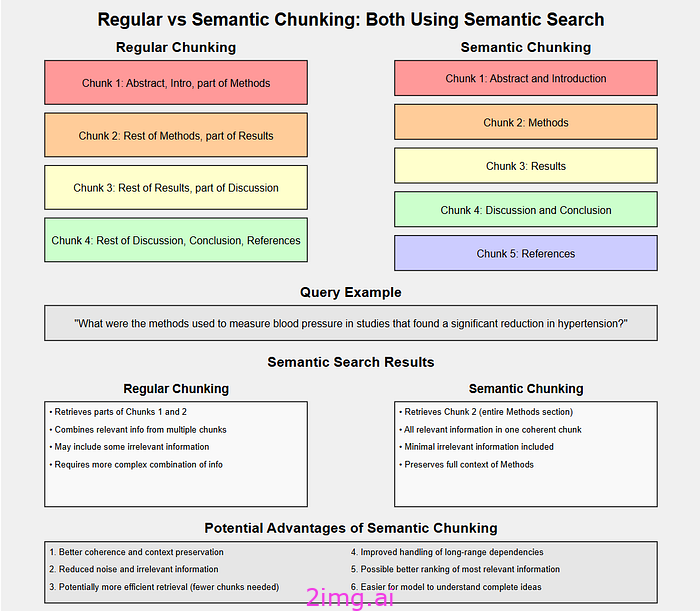
1. 包含案例介绍的块,在中间论点处被切断。2
. 另一个来自合理使用讨论中间的块,缺乏上下文。3
. 与主要论点无关的结论块。
相比之下,使用语义分块的系统将:
1. 识别有关合理使用论点的整个部分。2
. 将相关先例和示例与每个论点放在一起。3
. 在整个分块中保持法律推理的逻辑流畅。
结果是一组更好地保留了原始文档的连贯性和上下文的信息,从而可以做出更准确、更全面的回应。
与原始方法(其中数据是学术论文)进行比较的另一个示例:
实现语义分块:方法
实现语义分块的几种方法很有前景:
1. LLM 支持的分块:
——使用大型语言模型来识别语义边界。——
优点:适用于多种内容类型。——
缺点:计算量大。
2.基于规则的语义分割:
——采用语言规则和启发式方法进行逻辑划分。——
优点:对结构化文档很有效。——
缺点:内容风格多样,灵活性较差。
3.混合方法:
——结合统计方法、机器学习和基于规则的系统。——
优点:平衡效率和适应性。——
缺点:实施起来更复杂。
方法的选择取决于数据的性质、可用资源和具体要求等因素。
语义分块对人工智能系统的影响
将语义分块集成到 RAG 管道中具有以下几个优点:
1.更好地保存上下文:保持思想和论点的完整性。2
.提高检索相关性:返回与查询意图更一致的结果。3
.增强复杂信息处理能力:特别适用于长篇内容和复杂主题。4
.提高人工智能响应的准确性:带来更连贯和全面的输出。
这些改进可以产生更可靠的人工智能系统,能够更精确地处理细微查询。
挑战与未来方向
虽然语义分块有好处,但也带来了挑战:
–计算要求:更复杂的分析可能需要额外的计算资源。
–领域适应:有效的分块策略可能因不同领域和内容类型而异。
–平衡粒度:找到在不牺牲效率的情况下保留含义的最佳块大小。
该领域不断发展,目前正在进行以下领域的研究:
–多模式语义分块:超越文本,理解和分块其他媒体类型。
–动态分块系统:根据查询上下文和内容复杂性调整分块策略。
–与高级 AI 模型集成:增强语义分块和尖端语言模型之间的协同作用。
结论:推进信息检索
语义分块代表了人工智能系统在信息处理和理解方面迈出的重要一步。通过保留数据的语义结构,它能够实现更复杂、更情境感知的信息检索和生成。
随着我们不断开发人工智能能力,语义分块等技术将在创建能够更有效地与复杂信息交互的系统中发挥重要作用。
如果您有兴趣实施这些技术,请查看我的 RAG 技术存储库https://github.com/NirDiamant/RAG_Techniques,获取实际示例和高级方法。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/5684