
检索增强生成 (RAG) 是一种强大的技术,可以提高大型语言模型 (LLM) 生成的答案的准确性和可靠性。它还提供了检查模型在特定生成过程中使用的源的可能性,从而使人类用户更容易进行事实核查。此外,RAG 可以使模型知识保持最新状态并整合特定主题的信息,而无需进行微调。总体而言,RAG 提供了许多好处和很少的缺点,并且其工作流程易于实施。正因为如此,它已成为许多需要最新和/或专业知识的 LLM 用例的首选解决方案。
生成式人工智能领域的一些最新发展侧重于扩展流行的转换器架构以处理多种输入和/或输出模式,试图复制 LLM 的巨大成功。目前已有多种模型(包括开源和闭源模型)展示了处理多种模式的卓越能力。一种流行的多模式设置,也是最先要解决的问题之一,是视觉语言模型 (VLM),随着 LLaVA、Idefics 和 Phi-vision 等小而强大的模型的发布,它已经看到了有趣的开源贡献。
为多模态模型设计 RAG 系统比纯文本情况更具挑战性。事实上,LLM 的 RAG 系统设计已经很成熟,并且对一般工作流程也达成了一些共识,因为最近的许多发展都侧重于提高准确性、可靠性和可扩展性,而不是从根本上改变 RAG 架构。另一方面,多模态开辟了多种检索相关信息的方式,因此,可以做出几种不同的架构选择,每种都有自己的优点和缺点。例如,可以使用多模态嵌入模型为不同的模态创建共享向量空间,或者选择仅将信息固定在一种模态中。
在这篇博文中,我将讨论一个简单的框架,将 RAG 扩展到视觉语言模型 (VLM),重点关注视觉问答任务。该方法的核心思想是利用 VLM 的功能来理解文本和图像,以生成合适的搜索查询,该查询将用于在回答用户的提示之前检索外部信息。
RAG 用于视觉问答
在本节中,我将描述介绍中提到的框架的一般工作流程。为了便于说明,我将讨论只有一个用户对一张图片提出提示的情况。例如,简单的视觉问答 (VQA) 任务就是这种情况。该方法可以直接推广到多个提示和图像,但流程将变得更加复杂并引入进一步的复杂性。此外,我将仅考虑外部数据仅由文本文档组成的情况。使用多模态嵌入模型进行检索,或更一般地说,使用多模态搜索引擎,也可以将图像包含在外部数据中。
与通常的 RAG 工作流程一样,框架工作流程可以分为两部分:检索相关外部信息和根据提供的外部数据进行生成。
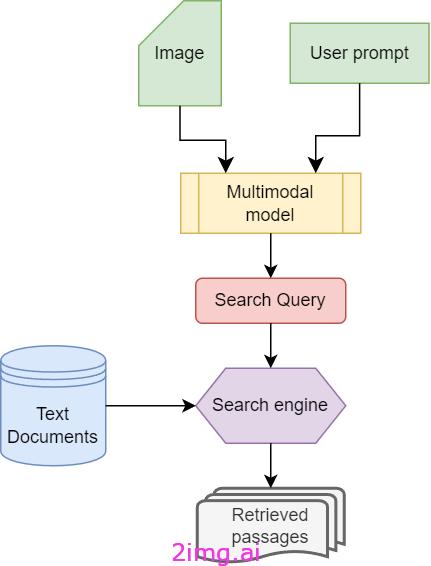
在检索阶段,目标是从外部文本文档中检索一些可以提供有用信息来回答用户提示的段落。为了有效地做到这一点,我们必须确保检索到的段落与提供的图像、提示以及更重要的是两者之间的关系相关。事实上,即使检索到的文档包含有关图像的信息,它们也可能不包含提供用户提示答案所需的特定信息。另一方面,提示只有与它所指的图像配对时才能被正确理解。为了应对这些挑战,本文讨论的框架利用多模态模型来生成适当的搜索查询,该查询经过定制,可在提供的图像上下文中捕获回答用户提示所需的信息。搜索引擎将使用生成的查询从外部数据中检索相关信息。
更详细地说,多模态模型接收用户的提示和图片作为输入,并负责创建与两者相关的搜索查询。此过程可以看作是查询转换的一个特例,旨在考虑问题的多模态性质。事实上,该模型将用户的提示转换为搜索查询,同时还考虑其所指的图片。
与分别处理每种输入模态的其他方法(例如使用多模态嵌入模型进行检索或使用生成的图像标题/描述进行语义相似性)相比,这种方法的优势在于它可以更有效地捕捉提示和图像之间的关系。
检索阶段的流程图如下所示。

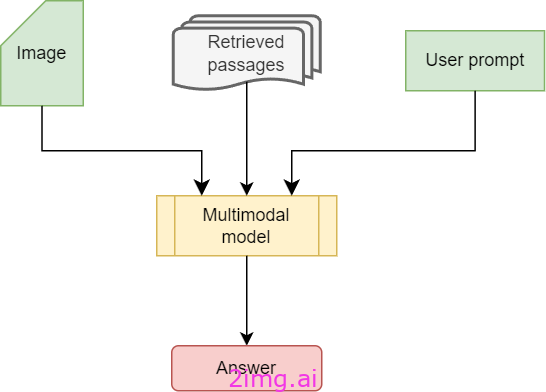
生成阶段与标准的纯文本 RAG 工作流程非常相似,唯一的区别在于,除了提示和检索到的段落之外,模型还会接收上下文中的图像。此过程如下所示。
利用维基百科为 Phi-3.5-vision 赋能
在本节中,我将提供一个实用指南,介绍如何应用讨论的框架,通过让多模态模型访问维基百科来增强多模态模型。我选择了模型Phi-3.5-vision,因为它是一个非常强大但轻量级的开源视觉语言模型。
检索
检索阶段的目标是从维基百科中收集一些可以提供有用信息来回答用户关于图像的问题的段落。在代码实现中,我使用 Python 包wikipedia从维基百科中搜索和检索内容。
以下是检索相关段落的步骤:
- 使用多模态模型生成捕捉图像问题含义的关键词。
- 使用生成的关键词在维基百科上搜索相关页面。
- 将每个检索到的页面的内容分成几块。
- 根据问题和关键词的语义文本相似性选择顶级块。
第一步利用 Phi-3.5-vision 生成适当的搜索查询,用于检索相关的维基百科页面。为此,我要求 Phi-3.5-vision 生成与用户问题和图像相关的关键字。然后,我使用维基百科包的内置搜索功能检索与生成的关键字相关的一些页面。
Phi-vision-3.5通用单轮单图聊天模板结构如下:
<|用户|>\n
<|image_1|>\n
{prompt} <|end|>\n
<|助理|>\n
为了生成关键字,我使用了以下提示:
您的任务是写几个搜索关键词来查找包含
相关信息的维基百科页面,以回答有关所提供图片的问题。
关键词必须尽可能具体,并且必须代表
回答与所提供图片相关的问题所需的信息。不要
写超过 3 个搜索关键词。
问题:{question}
标签{question} 在推理之前被替换为用户问题。
生成关键词后,使用 wikipedia 包的内置搜索功能检索与生成的关键词相关的一些页面。最后,将选定的页面拆分成段落,然后使用嵌入模型和 FAISS 向量存储的 LangChain 实现选择最相关的段落。我使用嵌入模型snowflake-arctic-embed-l来嵌入问题和关键词的串联以及检索到的页面块。实际上,检索阶段实际上是一种“混合搜索”,由两个连续步骤组成:使用 wikipedia 包的内置搜索功能进行关键词搜索,以及使用嵌入模型进行嵌入相似性检索。通过这种方式,检索在使用关键词搜索选择的最相关页面的段落的较小空间上进行,避免了需要构建一个包含维基百科所有内容嵌入的庞大向量存储。在不同的设置中,可以重新建模检索阶段以对整个外部语料库使用相似性检索或使用不同组合的检索方法。
从多页中检索段落可以帮助减少选择错误页面的机会,并且在需要来自多页的信息来得出答案时也很有用。
一代
在生成阶段,用户的问题、检索到的段落和原始图像被用作Phi-3.5-vision的输入来生成答案。
我在 Phi-3.5-vision 的通用聊天模板中使用了以下提示:
您是一位乐于助人的助手,负责回答有关所提供
图片的问题。
回答以下问题:{question}
您可以使用从维基百科中检索到的以下段落来提供
答案:
{passages}
在生成时,标签 {question} 将像以前一样替换为用户问题,而标签 {passages} 将替换为检索到的段落和相应页面的名称,格式如下
来自维基百科页面 {page_name}:“{passage1}”\n\n
来自维基百科页面 {page_name}:“{passage2}”\n\n
来自维基百科页面 {page_name}:“{passage3}”\n\n
...
当段落内容不足以唯一地确定其所指的主题或话题时,提供提取段落的页面名称可以帮助解决歧义。
示例
在本节中,我将展示一些使用上一节讨论的实现所获得的答案的示例,并将基于 RAG 的视觉语言模型的输出与基本版本进行比较。
对于下面的每个示例,我将显示提供给模型的图像、包含问题和 RAG 增强和基础 VLM 的答案的块、包含模型创建的搜索查询的块以及包含从维基百科检索的段落的块。
示例 1

问题:结出这种果实的植物有多高?
基本 VLM:番茄通常生长在可以长到 2 到
4 英尺高的植物上,具体取决于品种和生长条件。RAG
VLM:结出这种果实的番茄植物通常长到 1-3 米
(3-10 英尺)高。
VLM 生成了以下搜索关键词:
搜索关键词:番茄植株、番茄植株高度
并检索到以下段落:
摘自第 番茄 (https://en.wikipedia.org/wiki/Tomato) 页:
“一年四季。番茄植株通常长到 1-3
米(3-10 英尺)高。它们是藤蔓,茎弱,蔓生
,通常需要支撑。不确定型番茄植株在
原生地是多年生植物,但作为一年生植物栽培。(确定型,或)。
摘自第 番茄 (https://en.wikipedia.org/wiki/Tomato) 页:
“番茄植株的多种品种在世界各地的温带气候中广泛种植,温室允许一年四季生产番茄。番茄植株通常长到 1-3 米(3-10 英尺)高。它们是藤蔓,茎弱,蔓生,通常需要支撑。不确定型番茄植株在原生地是多年生植物,但作为一年生植物栽培。(确定型,或)。摘自第 番茄 (https://en.wikipedia.org/wiki/Tomato) 页:“番茄植株的多种品种
在世界各地的温带气候中广泛种植,温室允许一年四季生产番茄
。番茄植株通常长到 1-3 米
(3-10 英尺)高。它们是藤蔓,茎弱,蔓生,通常需要支撑。
摘自第 早熟女孩 (https://en.wikipedia.org/wiki/Early_Girl) 页:
“== 另请参阅 ==
番茄品种列表
== 参考资料 ==”。
摘自第 Black Krim (https://en.wikipedia.org/wiki/Black_Krim):“==
参考资料 ==
== 另请参阅 ==
番茄品种列表
Heirloom 番茄”。
来自页面 Celebrity 番茄(https://en.wikipedia.org/wiki/Celebrity_tomato):“==
另请参阅 ==
番茄品种列表
佛罗里达州的番茄生产
== 参考资料 ==”。
来自页面 Fourth of July 番茄
(https://en.wikipedia.org/wiki/Fourth_of_July_tomato):“==
另请参阅 ==
番茄品种列表
== 参考资料 ==
== 外部链接 ==
Google Images 图片库”。
来自页面 Mortgage Lifter(https://en.wikipedia.org/wiki/Mortgage_Lifter):
“== 另请参阅 ==
番茄品种列表
== 参考资料 ==
== 外部链接 ==
Google Images 图片库”。
使用 RAG 增强的模型正确报告了维基百科页面“番茄”上所述的身高范围,而基础模型则以较低的范围回答。
示例 2

问题:该物种的体重是多少?
基本 VLM:北极熊的体重在 900 至 1,600 磅
(408 至 727 公斤)之间。RAG
VLM:该物种北极熊的体重范围为
雄性 300-800 公斤(660-1,760 磅),雌性 150-300 公斤(330-660 磅)。
搜索关键词:北极熊、体重
摘自页面 北极熊 (https://en.wikipedia.org/wiki/Polar_bear):
“雄性通常身长 200–250 厘米 (6.6–8.2 英尺),体重 300–800 公斤
(660–1,760 磅)。雌性体型较小,身长 180–200 厘米 (5.9–6.6 英尺),体重
150–300 公斤 (330–660 磅)。与大多数其他哺乳动物相比,该物种的性别二态性特别
高。雄性北极熊也有”。
摘自页面 北极熊 (https://en.wikipedia.org/wiki/Polar_bear):“==
注释 ==
== 参考文献 ==
== 参考书目 ==
== 外部链接 ==
北极熊国际网站
ARKive — 北极熊 (Ursus maritimus) 的图像和电影”。
摘自页面北极熊 (https://en.wikipedia.org/wiki/Polar_bear):
“体重 150–300 公斤 (330–660 磅)。
与大多数其他哺乳动物相比,该物种的性别差异特别大。雄性北极熊
的头部也比雌性大。北极熊的体重
在一年内会波动,因为它们会增重并增加体重”。
摘自页面 熊科动物列表 (https://en.wikipedia.org/wiki/List_of_ursids):
“长,加上 3–20 厘米(1–8 英寸)的尾巴,尽管北极熊
长 2.2–2.44 米(7–8 英尺),棕熊的一些亚种可以长达 2.8 米(9 英尺)。
体重范围很大,从最低 35 公斤(77 磅)的马来熊到
最高 726 公斤(1,600 磅)的北极熊。种群”。
摘自页面 Knut (polar bear) (https://en.wikipedia.org/wiki/Knut_(polar_bear)):“==
另请参阅 ==
Binky (polar bear)
个体熊列表
== 参考资料 ==
== 外部链接 ==”。
摘自页面北极熊 (https://en.wikipedia.org/wiki/Polar_bear):
“北极熊是现存最大的熊类和陆地食肉动物,
尽管一些棕熊亚种(如科迪亚克熊)的体型可以与其媲美。雄性北极熊通常身长 200-250 厘米(6.6-8.2 英尺),体重 300-800 公斤(660-1,760 磅)。雌性体型较小,身长 180-200 厘米(5.9-6.6 英尺),
体重 100-250 公斤(660-1,760 磅)。”摘自页面 棕熊亚种(https://en.wikipedia.org/wiki/Subspecies_of_brown_bear):“雄性,三年内平均体重可能增加三倍,预计平均体重在 360 至 545 公斤(794 至 1,202 磅)之间。据报道,北极熊两性的成年平均体重与半岛巨熊和科迪亚克熊非常相似。由于它们大致相同”。
同样,RAG 模型使用维基百科页面“北极熊”中报告的权重正确回答了问题,而基础模型则使用略有不同的权重范围回答了问题。
示例 3
LLaVA-1.5 模型如何产生幻觉。让我们看看在该示例中使用带有和不带有 RAG 增强的 Phi-3.5-vision 模型会发生什么。特别是,如果检索到任何误导性段落,该模型现在可能更容易产生幻觉。

问题:告诉我这张图片中的鱼的种类
基本 VLM:图片中不包含任何鱼或水生环境,因此
我无法提供鱼的种类。
RAG VLM:图片中不包含任何鱼或水生环境。这是
一张有沙丘的沙漠景观照片。
因此,我无法根据这张图片提供鱼的种类。
基础模型和 RAG 模型都没有因误导性提示而产生幻觉,这表明 Phi-3.5 视觉的稳健性可能比 LLaVA-1.5 更好。特别是,RAG VLM 没有从维基百科检索任何页面。事实上,当被要求生成关键词时,该模型回答
提供的图片中看不到鱼。图片展示了一片
有沙丘的沙漠景观。因此,与图片
内容相关的搜索关键词更适合沙漠或沙丘相关的主题。
此搜索查询未通过 wikipedia 包搜索功能产生任何结果。
注意:在后一个示例中,在早期使用 Idefics 2 进行的实验中,基础 VLM 和 RAG VLM 模型都受到幻觉的影响,用图像中不存在的鱼类物种名称来回答。特别是,RAG 模型检索了与各种鱼类相关的误导性段落。幻觉现象依赖于模型,RAG 框架可能不足以在所有情况下消除幻觉。
限制
该框架的主要限制是,它要求模型至少对所提供的图像和问题有一般了解(而确切的细节将通过 RAG 检索),以便生成有用的搜索查询。在某些特定领域的设置中,可能需要对模型进行微调以生成搜索查询。
本文讨论的框架也存在传统纯文本 RAG 系统常见的局限性。生成过程中常见的错误来源是对外部信息的错误检索。在某些情况下,模型无法正确识别检索阶段的失败,并根据不正确、不相关或误导性的信息生成答案。特别是,不相关段落的存在有时会引发幻觉,否则模型不会出现这种幻觉。
另一个常见的错误来源是忽略检索到的段落或错误地引用它们。这有时会导致检索到的段落和生成的答案之间存在细微的差异,乍一看可能很难发现。
例子
在这个例子中,我将展示模型错误地引用检索到的段落的一个例子。

问题:这种动物的平均体重是多少?
基本 VLM:雄狮的平均体重在 160 至 310 公斤之间,而
雌狮的体重通常在 120 至 180 公斤之间。RAG
VLM:根据文章中提供的信息,
南非雄狮的平均体重为 187.5 公斤(386 磅),东非雄狮的平均体重为 174.9 公斤(386 磅)
。
搜索关键词:狮子、体重、平均体重
摘自页面 美洲狮 (https://en.wikipedia.org/wiki/American_lion):
“雄性美洲狮重 518 至 1153 磅,雌性重 175 至 365 公斤 (385 至 805 磅)。2008
年,美洲狮的体重估计可达 420 公斤 (930 磅)。2009
年的一项研究表明,雄性美洲狮的平均体重为 256 公斤 (564 磅),
所分析的最大标本重 351 公斤 (774 磅)。
摘自页面 狮子 (https://en.wikipedia.org/wiki/Lion):“===
大小 ===
在猫科动物中,狮子的体型仅次于老虎。
成年狮子的大小和体重在其分布范围和栖息地各不相同。非洲和印度有少数
个体比平均水平大。
=== 鬃毛 ===”。
摘自 Panthera leo leo (https://en.wikipedia.org/wiki/Panthera_leo_leo) 页面:
“狮子的皮毛颜色从浅黄色到深棕色不等。它有圆
耳朵和黑色尾簇。雄狮的平均头体长为
2.47–2.84 米(8 英尺 1 英寸 – 9 英尺 4 英寸),体重为 148.2–190.9 公斤
(327–421 磅)。雌狮体型较小,体重较轻。动物学狮子标本”。
摘自 Panthera leo melanochaita 页面
(https://en.wikipedia.org/wiki/Panthera_leo_melanochaita):
“雄狮的平均头体长为 2.47–2.84 米(8 英尺 1 英寸 – 9 英尺
4 英寸),体重范围为 150–225 公斤(331–496 磅),
南部非洲平均体重为 187.5 公斤(413 磅),东非为 145.4–204.7 公斤(321–451 磅),平均体重为 174.9 公斤
(386 磅)。雌狮平均体重为 83–165 公斤(183–364 磅)”。
摘自页面 亚洲狮 (https://en.wikipedia.org/wiki/Asiatic_lion):
“成年雄性亚洲狮平均体重 160.1 公斤(353 磅),极限
为 190 公斤(420 磅);野生雌性体重 100 至 130 公斤(220 至 285 磅)
。[1]”。
摘自页面 最大的哺乳动物列表
(https://en.wikipedia.org/wiki/List_of_largest_mammals):“==
另请参阅 ==
最大的陆地食肉动物列表
最大的生物
最大的史前动物 最大
的鸟类列表 最大的
猫科动物列表
最大的鱼类列表 最大
的植物
列表 最大的爬行动物
列表 最大的昆虫
列表 最重的陆地哺乳动物列表
最小的生物
== 注释 ==”。
来自页面古代美索不达米亚计量单位
(https://en.wikipedia.org/wiki/Ancient_Mesopotamian_units_of_measurement):“==
另请参阅 ==
亚述狮子重量
巴比伦数学
历史度量衡 度量衡
==
参考文献 ==
=== 引用 ===”。
虽然答案中以公斤为单位的重量是正确的,但模型错误地将南部非洲雄狮的平均体重转换为磅,尽管从维基百科中提取的相应段落报告了正确的数量。
结论
在这篇文章中,我介绍了一个简单的框架,该框架可用于通过检索增强生成功能增强视觉问答。该方法的核心思想是利用视觉语言模型生成查询,然后标准 RAG 管道将使用这些查询从外部语料库中检索信息。我还介绍了该框架的一个实现,该框架授予 Phi-3.5-vision 访问维基百科的权限。
虽然所讨论的方法简单有效,但它并不能避免所有 RAG 系统都存在的局限性,也不能避免多模态设置复杂性带来的新挑战。一方面,检索某些特定问题的相关信息可能很困难。由于搜索查询是使用视觉语言模型创建的,因此检索准确性进一步受到 VLM 识别图像和理解问题所指细节的能力的限制。另一方面,即使检索到了正确的信息,也不能保证模型在生成答案时不会产生幻觉。在多模态设置中,这种情况可能会因模型必须将正确的含义与文本和图像相关联并理解它们之间的相互作用而加剧。
本文中讨论的框架是 vanilla RAG 管道的直接扩展,适用于视觉问答任务。可以轻松包含标准的高级 RAG 技术,例如查询转换、对检索到的段落进行重新排序以及假设文档嵌入 (HyDE),以提高性能。此外,使用多模态嵌入模型(如 CLIP)会出现新的机会:图像嵌入可用于按相似性搜索相关文本文档,也可以检索与原始图像和问题相似和/或相关的图像。例如,当需要从不同的角度来回答提示时,后者可能很有用。另一个改进方向是进行微调以获得更专业和更有效的模型。考虑到多模态模型在检索和生成过程中的作用,可以执行两个不同的微调过程:一个是获得专门用于编写搜索查询的模型,另一个是提高模型在基础生成任务上的性能。最后,该框架可以整合到专门的代理系统中,以进一步提高其性能和稳健性。例如,代理系统可以通过对检索到的段落提供反馈并提出后续问题或仅在需要时专注于搜索有关图像特定细节的信息来迭代地优化生成的查询。它还可以处理更复杂问题的多跳问答任务,并决定何时需要检索更多外部信息来回答用户的查询。
RA/SD 衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/5638