自从大型语言模型 (LLM) 以人工智能聊天机器人的形式出现在世人面前后,它们在我们日常生活中的应用就越来越广泛。它们催生出了一个全新的经济领域,而推动力则来自全新的人工智能业务以及人工智能与现有技术的融合。
对于大多数希望将人工智能融入其技术的企业来说,最大的挑战是使其与特定受众相关。
如果你手头没有数百万美元,或者没有一支才华横溢的人工智能工程师团队,那么从头开始培养自己的大语言模型学位对大多数人来说是不可能的。
那么,我们如何使用现有的 LLM 将 AI 嵌入到现有技术中?答案是利用检索增强生成(简称RAG)。
让我们深入了解 RAG 如何改变 AI 的使用。
什么是检索增强生成 (RAG)?
大多数 LLM 都经过大量数据的训练,可以回答几乎所有主题的问题。然而,模型的所有知识都会被内置到模型中。
这种方法有两个问题。
- 模型的知识很快就会过时。
- 该模型只知道它接受过训练的事物。这通常意味着互联网上可用的信息。
这就是检索增强生成的作用所在。检索增强生成是一种架构模式,用于将 AI 模型与其他现有数据源集成。当您希望模型学习新知识时,无需重新训练模型,而是在向模型提问时用这些新信息对其进行补充。
最简单的例子是 ChatGPT 使用互联网了解最近发生的事件。如果你向 ChatGPT 4 询问有关最近新闻的问题,它无法使用其现有模型提供准确的答案。相反,它使用 RAG 架构从互联网上获取这些数据(通过 Bing 搜索)。然后这些数据作为上下文提供给模型,LLM 将这些新数据与其现有知识一起解析以形成更有用的响应。
这个概念很简单。你不必一遍又一遍地重新学习你的大语言模型RAG 架构如何改变 AI(这会非常昂贵),而是利用来自其他来源的数据来充实它。
RAG 有何用途?
最明显的用例是我们已经与 LLM 构建者讨论过的用例,例如 ChatGPT 使用互联网为模型补充更多最新信息。这使得模型能够生成有关新事件的有用响应,而无需昂贵的重新训练。
第二种用例是针对那些希望将现有 LLM 与自己的数据结合使用的企业。大多数企业无法从头开始训练 LLM,也不想与 ChatGPT 等公共服务公开分享其数据。
相反,企业可以将 LLM 作为其自身云基础设施中的服务。OpenAI在 Azure 中提供服务,而 Anthropic 的 Claude 模型可在 AWS 中使用。
使用这些服务,您可以使用 RAG 架构中的现有数据集,在向模型提问时将业务数据作为上下文提供给模型。这意味着数据永远不会离开您的云网络,也不会被分发 LLM 的公司用于再培训。
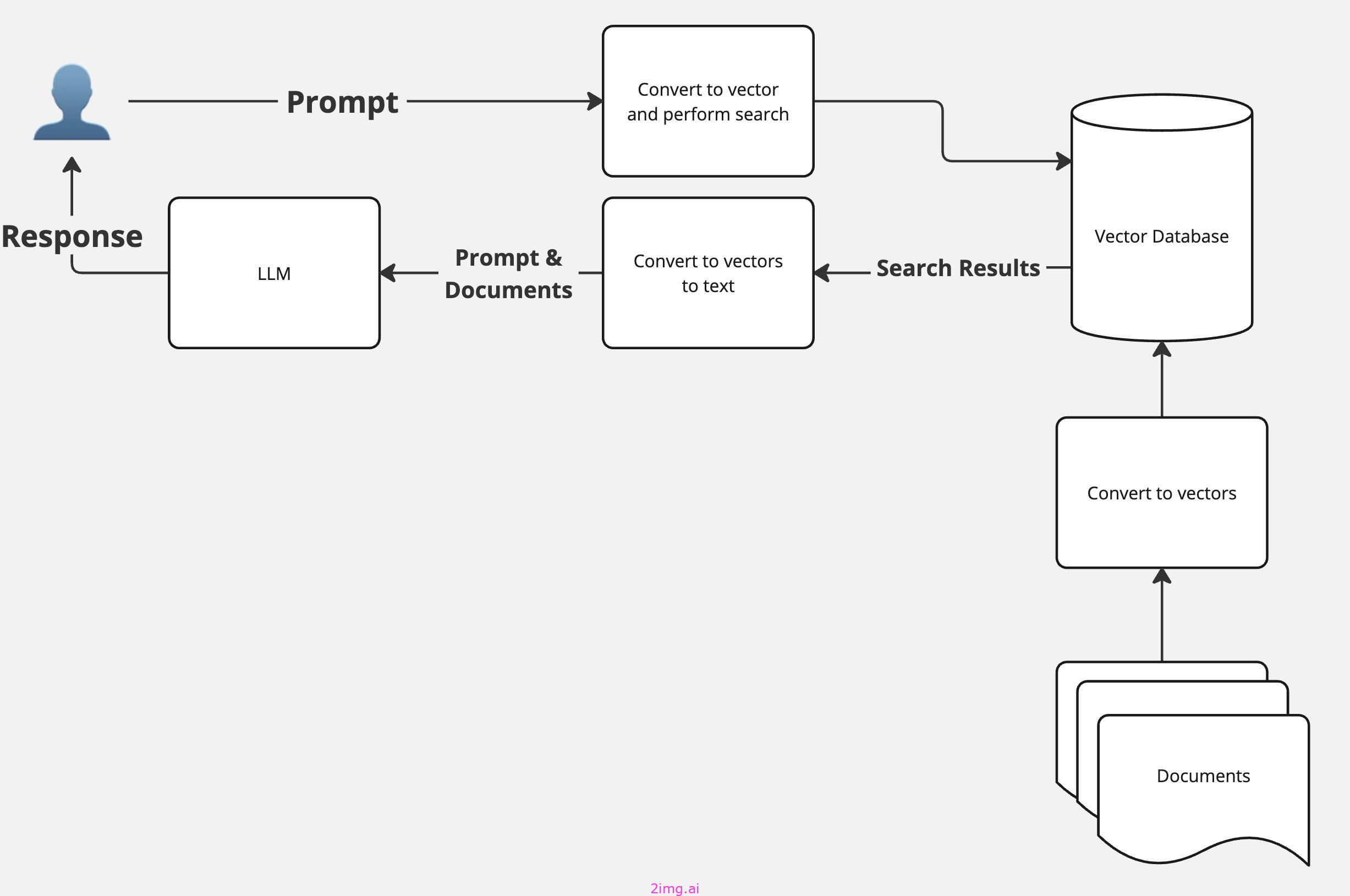
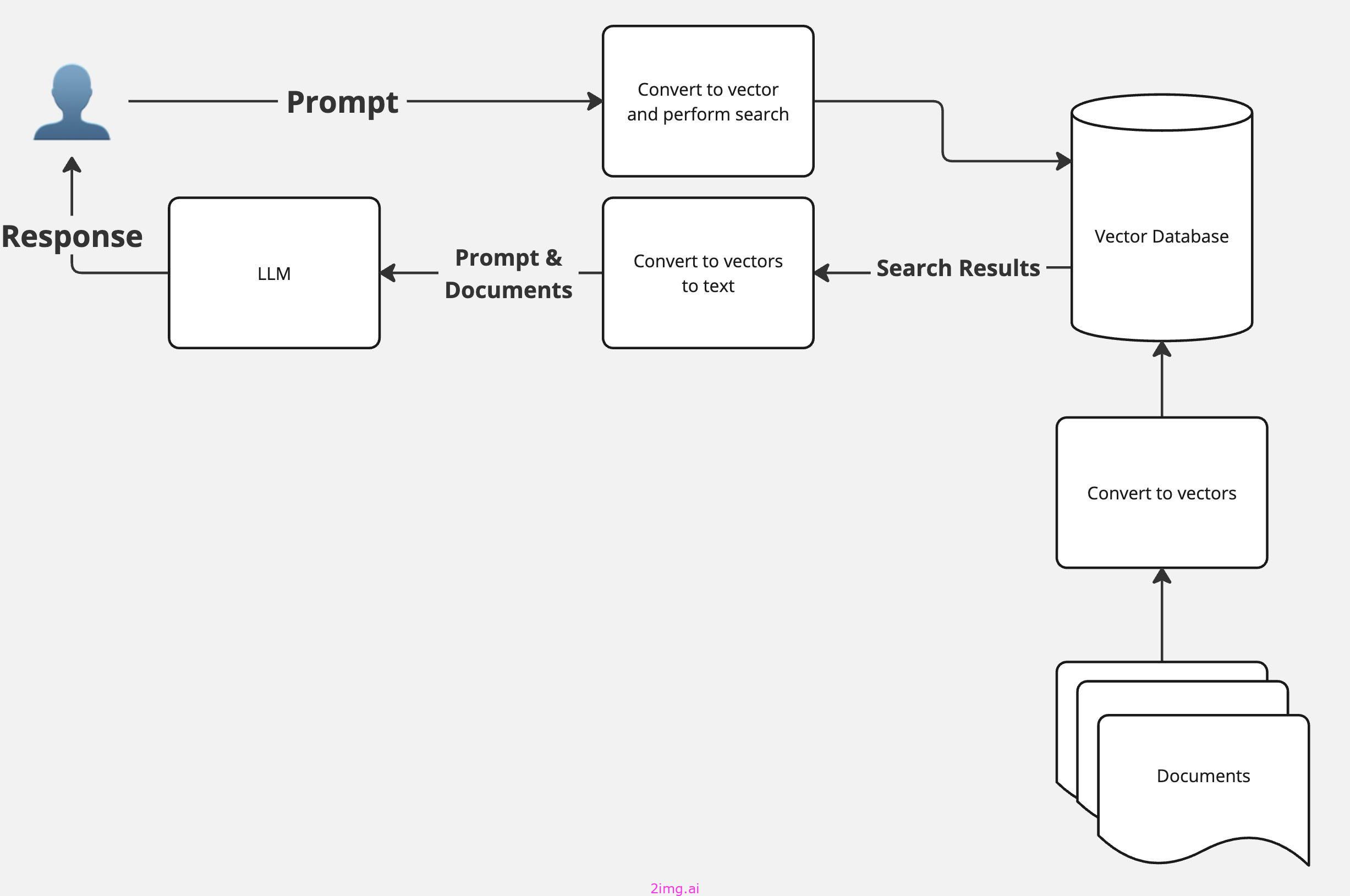
RAG 架构如何工作?
该架构相对简单,有三个核心组件:用户提示、LLM 和数据库。
- 用户写提示。
- 在数据库中执行搜索以查找与该提示相关的任何数据。
- 提示和搜索结果被输入到LLM,然后LLM制定回应。
关键步骤是第 2 步,我们在此执行数据库搜索。如果您使用来自网络的搜索结果,则您在此处使用的是搜索引擎数据库,并且搜索是通过 API 执行的。如果您想使用自己的内部数据,主要模式是使用矢量数据库。
让我们来看一个例子。假设你想创建一个 Medium AI,使用 Medium 文章提炼任何主题的信息。首先,你需要提取你认为有用的文章,也许你会选择那些阅读量、点赞量和评论量高的文章。然后,你将每篇文章的内容转换为向量,并将这些向量存储在数据库中。
使用向量的原因是它们可以捕获语义信息,因此相似的单词或文档会以类似的方式用数字表示。这意味着当搜索查询也转换为向量时,可以轻松查找包含语义相似信息的文档。
假设您的提示是“告诉我 2024 年要学习的最佳数据工程技能”。然后,我们将从向量数据库中查找包含此信息的文档。
然后,我们会将问题连同从向量数据库返回的文档一起提供给 LLM。这里需要进行一些提示工程,向 LLM 指出问题是什么以及上下文信息是什么。然后,LLM 可以使用上下文以及其自己的模型信息为您提供响应。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/5618