
750 部小说。1000 万行代码。这就是您可以提供给 Magic Dev 的新长期记忆 (LTM) 模型的信息量,该模型打破了所有记录(而且无人能及)。
虽然每个人都认为人工智能进步很快,但没有人预料到会出现这样一种模型,它可以将你在一次提示中可以发送的内容量增加到之前最先进水平(Gemini)的 100 倍,可能在一次提示中就可以发送你一生的事实、经历和事件。
当前模型的残酷真相
要理解为什么模型在任何给定时间所能看到的上下文有限,我们需要了解它们的“内部”。所有前沿人工智能模型都是Transformers,这是谷歌在 2017 年开发的一种特定架构。
但为什么 Transformer 会成为主流呢?原因有二:硬件和全球关注。
为我们的时代而生
首先,该架构的设计初衷是利用加速计算硬件。换句话说,研究人员使用 GPU 并自问:我们如何才能为他们量身打造 AI 模型?
这将行业推向了一个新的高度,因为这些模型现在可以以我们从未见过的计算规模进行处理。因此,得益于此,研究人员还为 Transformer 赋予了一个关键的归纳偏差:全局注意力。
归纳偏差是模型根据其设计对数据做出的假设,以便进行预测。在这种情况下,模型假设某些预测需要识别长距离依赖关系,这意味着 Transformers 需要随时访问提供的所有信息。
现在这可能没有多大意义,但一会儿就会有意义了。
换句话说,这些模型可以根据需要回顾过去,以检索进行下一个单词预测所需的上下文。
例如,如果您向模型查询有关一本书的信息,则模型会在每次翻阅时重新阅读整本书,以防执行预测所需的上下文在序列中的位置靠后。
假设你向模型询问本书前面章节中简要提到的一个事实。得益于全局注意力,Transformers 会记住这个事实。
但这是有代价的,而且代价并不便宜。
由于 Transformer 可以完全访问过去的一切,因此其内存不会被压缩。因此,文本/图像/音频/视频序列越长,内存就越大。
因此,为了防止成本变得难以承受,研究人员被迫限制他们在任何给定时间内可以向模型提供的上下文量,也就是我们所知的上下文窗口。
事实上,内存可以增长得如此之大,以至于它成为在野外处理这些模型时的限制因素。
Transformer 还存在外推问题,这意味着在处理比训练期间看到的序列更大的序列时,其预测质量会大大下降;这是限制上下文大小的另一个原因。
例如,处理 Llama 3.1 405B 的一个 1 亿个标记序列(大约 6000 万到 8000 万个单词)需要近 55 TB 的内存,从 GPU 角度来看,需要683 个 NVIDIA H100 GPU才能满足一个文本序列的内存需求。
毫不奇怪,Llama 3.1 405B 的上下文窗口仅限于 10 万个单词,比今天故事的主角少一千倍。
那么,Magic Dev 的 LTM 模型是什么样的?
神奇的突破
如上所述,致力于为代码构建下一代前沿 AI 模型的公司Magic Dev声称已经取得了一些惊人的成就:他们训练出了一个可以在一次提示中处理 1 亿个标记的模型,同时提供比 Llama 3.1 405B 等仅限 Transformer 的标准模型高出三个数量级的效率。
这使得模型能够执行出色的操作。例如,在公告中分享的视频中,该模型在广泛的代码库上执行复杂的编码任务,而上下文窗口较小的模型根本无法做到这一点。
令人印象深刻的是,尽管之前没有看到过代码,它还是可以有效地利用代码库提供的广泛上下文来尽职尽责地完成任务,从头开始创建一个计算器,或者修改密码更改网站页面的 HTML / CSS 代码,用户只需要提出请求即可。
重要的是,他们通过展示大多数其他长上下文模型无法做到的功能,证明了自己在大上下文王座上的权威:多跳跟踪。
Induction Heads的重要性
过去,为了衡量模型在处理大量上下文窗口时的表现,我们会执行“大海捞针” (NITH) 问题。此问题会在提示中看似不相关的段落中插入一个随机事实,模型必须能够完全检索到它。
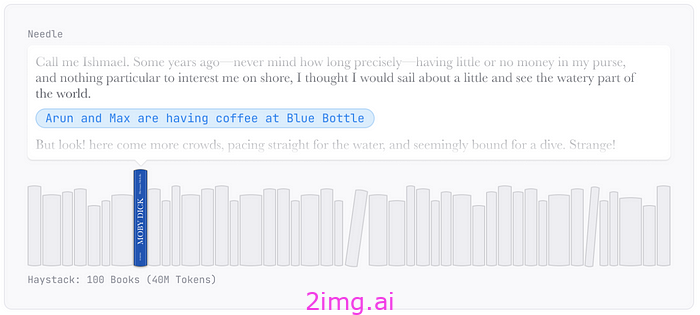
例如,Magic Dev 的研究人员将整整 100 本书(约 4000 万个上下文标记)输入到模型中。然后,他们在《白鲸记》(一本与鲸鱼无关的书)中插入了“阿伦和马克斯在 Blue Bottle 喝咖啡”这一随机事实。
因此,模型必须能够回顾 3000 万个单词,识别这根独特且随机的针,并将其检索出来才能成功。
但是什么内部机制允许模型执行这样的检索?
从机械角度来说,Transformer 开发了称为感应头的内部电路,其本质上是复制/粘贴机器。
如果最后预测的单词是“Harry”,那么模型会返回序列,找到该标记的前一个实例,并查找下一个实例(恰好是“Potter”),这增加了模型再次输出“Potter”以完成模式的可能性。
下面是一个更直观的例子,其中‘:’是最后一个预测的标记,为了预测下一个标记,感应头会回顾序列以找到相同的标记,然后注意接下来的单词(“ _Negative ”/“ _Positive ”)。
接下来,感应头激励模型预测这两个标记中的一个作为下一个完成模式的标记。

一年多以来,人工智能实验室一直使用这种 NITH 方法来证明他们的模型可以处理长序列。然而,一组研究人员发布了一项新的基准提案Ruler,声称 NITH 无法证明模型在处理长序列方面的能力。
标尺基准
具体而言,他们认为,在大多数情况下,检索可能会更加复杂,需要多跳(其中多个针在整个上下文中相互引用,并且模型必须建立连接直到到达最后一个针),这个过程称为多跳跟踪。
多跳追踪任务的一个例子是涉及广泛环境中一系列相互关联的事实。
如果第一个随机事实陈述为“居里夫人发现了镭”,而序列中很远的另一个点陈述为“镭用于治疗癌症”,那么模型就会使用这两个事实在序列的另一部分找到最后的针:“居里夫人的发现有助于治疗癌症”。
这个练习涉及链接这两条信息,要求模型执行多跳推理来连接不同文本部分之间的点。
但是在评估此类任务的长上下文模型时,研究人员发现它们在处理长上下文方面并不擅长,无法在数据中找到这些更复杂的模式。
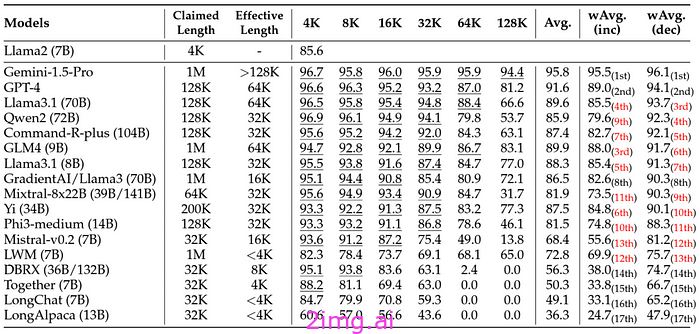
然而,这正是 Magic Dev 团队声称已经解决的问题。
尽管它的上下文窗口比其最直接的竞争对手 Gemini 大 100 倍,但它仍拥有高达 1 亿分之一的近乎完美的准确率。
即使进行多达 6 次跳跃(玛丽居里的例子,但增加了 4 个事实),该模型仍然有 90% 的时间能正确完成。
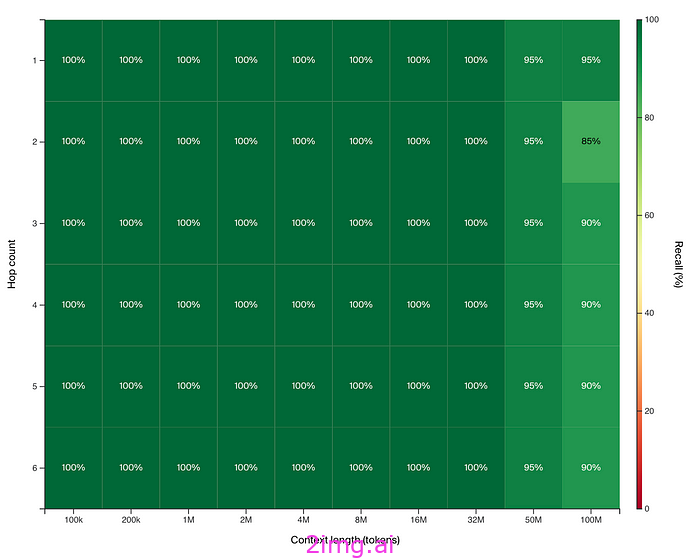
因此,Magic Dev 似乎实现了不可能的事情——一个拥有比其他模型多 100 倍上下文且检索能力更佳的模型。
但这怎么可能呢?只有一种可能的选择:状态压缩。
混合架构
让我说清楚一点:我只是猜测,因为 Magic Dev 没有透露他们是如何做到这一点的。
他们声称可以在大序列上提供这种性能,并且效率比独立的 Transformer 高三个数量级,这表明这不是标准的 Transformer。
毫无疑问,我们谈论的一定是压缩状态的模型。换句话说,与 Mamba、TTT 或 LSTM 等架构类似,该模型具有固定大小的内存,不会随着上下文按比例增长。
正如我们之前所讨论的,Transformers 不会压缩状态,它拥有巨大的内存缓存,可以及时回顾每个细节。但这些压缩状态模型只会努力保留最重要的内容,而忘记其余内容。
当然,这带来了一个问题,即模型必须主动决定将哪些信息保留在记忆中以及将哪些信息忘记(就像人类一样)。
这似乎是一个显而易见的选择,但牺牲变形金刚所提供的全球召回率尚未带来足够值得的权衡,以至于看不到任何与变形金刚不相似的东西被用作秤。
这让我相信 Magic Dev 的 LTM 是一种混合架构,结合了:
- 高效基线解码:使用 Mamba 或其他具有固定大小内存的状态空间模型层以经济高效的方式提供大上下文预测。
- 完美检索,注意:使用 Transformer 层也可以确保模型识别长距离依赖关系并检索固定大小内存可能忘记或忽略的关键数据(例如,我们之前看到的书中示例或我们讨论过的其他 NITH 任务)。
这是一件大事
解锁“无限”的背景可能会深刻改变行业的现状,从使 RAG 应用程序变得无用到释放 AI 模型的真正力量,从而有可能访问人类曾经创造的每一点信息。
有了长背景,代码或生物学(DNA 序列)等模态最终可能被人工智能模型所访问,从而使它们能够发现我们数据中人类肉眼无法发现的新模式。
此外,Magic Dev 的 LTM 模型能否成为最终迫使 AI 实验室永久转变为混合架构的模型?
如果真是这样,它可能会一劳永逸地解决最引人注目的架构之争,转而支持混合架构,从而使人工智能实验室远离在过去五年中取得巨大成功的单纯 Transformer 路径。
RA/SD 衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/5612
