
大量小型语言模型(SLM)可作为开源资源随时使用,可通过 HuggingFace 等平台轻松下载和离线推理。
或者可以使用 LM Studio、Titan ML、Jan、Ollama 等本地推理解决方案。
在深入研究 SLM 和 Orca 的细节之前,重要的是要考虑 SLM 的当前用例。这些模型因几个关键特性而受到关注,包括:
自然语言生成、常识推理、对话转向控制、对话上下文管理、自然语言理解和处理非结构化输入数据。
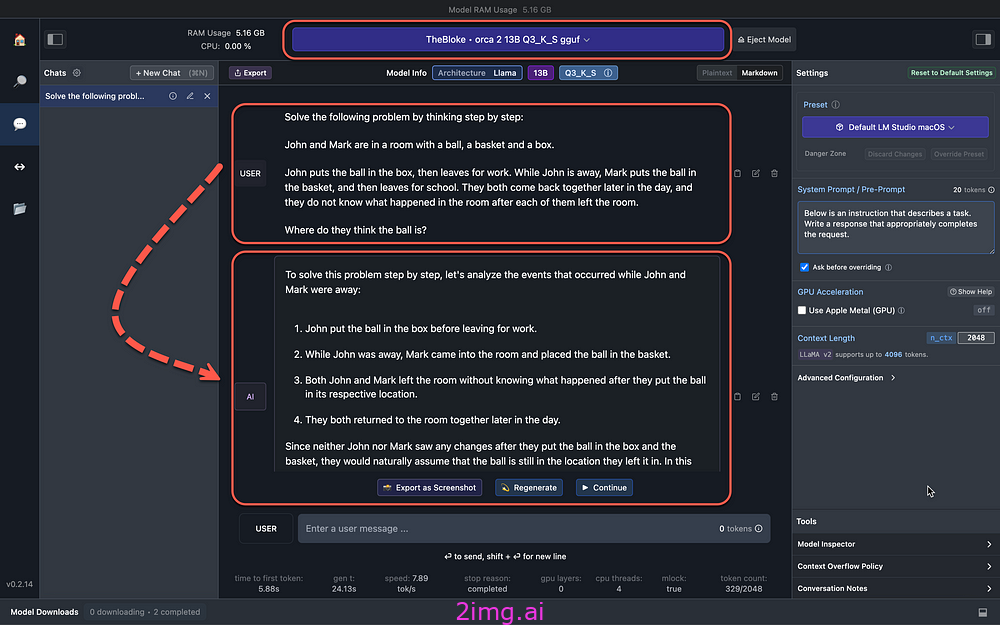
考虑下面的图片,利用 LM Studio,Orca-2 13B 小语言模型 (SLM) 的量化版本在我的 MacBook M2 上本地运行。
Orca 的优势之一是常识推理,下面考虑如何向 Orca SLM 提出一个复杂的推理问题,利用 LM Studio 进行局部推理。

LinkedIn 反馈
通过查看 LinkedIn 社区,我想了解一下市场对 SLM 的感觉……是否使用了小型语言模型,以及 SLM 在多大程度上被认为有用。
普遍的共识是,当针对特定用例或任务时,SLM 是一种选择。当谈到语言模型时,它不一定与大小有关,而是与协调多个专用模型有关。
SLM 也正在被微调以适应特定的环境,并且利用 RAG,幻觉受到限制。
7B 模型通常被认为较小,因为这些模型在量化时无需使用 GPU 即可运行。
对于大多数企业实施而言,不需要一个能满足所有人需求的庞大模型的用例并不多。
事实上,企业在特定工作流程中已经非常仔细地定义了自动化用例。在这些情况下,具有正确工作流程的 SLM 绝对可以胜任这项工作。
具有讽刺意味的是,当法学硕士面向公众并需要能够用 5 种语言写莎士比亚并且还知道如何建模财务数据,同时为您提供如何修理摩托车的提示时,您才需要这些庞大的模型。
仅基于用例,SLM 实际上会变得主导和标准,尤其是在边缘和本地运行时。
回到 Orca
据微软称,Orca 2 的目标有两个。
首先,目的是教会较小的模型如何使用一套推理技术,例如:
- 逐步处理,
- 回忆-然后-生成,
- 回忆-原因-产生,
- 提取-生成,
- 以及直接回答方法。
其次,他们希望帮助这些模型决定何时 使用最有效的推理策略来完成手头的任务,从而使它们无论规模大小都能发挥出最佳性能。
初步结果表明,Orca 2 明显超越了类似规模的模型,甚至匹敌或超过了 5 到 10 倍的模型,尤其是在需要推理的任务上。
这凸显了赋予更小的模型更好的推理能力的潜力。
然而,Orca 2 也不例外,所有模型在某种程度上都受到其底层预训练模型的限制(虽然 Orca 2 训练可以应用于任何基础 LLM,但研究中报告的结果是在 LLaMA-2 7B 和 13B 上)。
Orca 2 模型尚未接受 RLHF 安全训练。微软认为,用于推理的相同技术也适用于对齐模型以确保安全,RLHF 可能会进一步改善。
大语言模型 (LLM) 教学 SML
训练数据来自更强大的教师模型。请注意,我们可以通过非常详细的说明甚至多次调用来获得教师的响应,具体取决于任务和模型所需的行为。
在没有原始指导(详细说明如何完成任务)的情况下,学生模型将被鼓励学习潜在的策略以及它所引发的推理能力。
推动 Orca 2 开发的核心原则是认识到不同的任务可能需要不同的解决方法。这些策略包括逐步处理、回忆然后生成、回忆推理生成、提取生成和直接回答方法。
众所周知,对 GPT-4 等大型模型有效的方法不一定对较小的模型也是最佳选择。例如,虽然 GPT-4 可以直接熟练地处理复杂任务,但较小的模型可能会从将任务分解为可管理的步骤中受益。
Orca 2 使用扩展的、精细定制的合成数据集进行训练。该数据集经过精心制作,旨在让 Orca 2 接触一系列推理技术,包括上述方法。它还教会模型根据手头的具体任务采用不同的解决方案策略。
训练数据来源于更先进的教师模型。
重要的是,可以通过详细的说明甚至多次迭代来访问老师的回答,并根据任务和所需的模型行为进行定制。
在原始指令不可用的情况下,促使学生模型学习底层策略及其所包含的推理过程变得至关重要。
实践推理示例
考虑一下下面向 Orca-2 提出的复杂推理问题……
通过逐步思考解决以下问题:
约翰和马克在一个房间里,房间里有一个球、一个篮子和一个盒子。
约翰把球放进盒子里,然后去上班了。
约翰不在的时候,马克把球放进篮子里,然后去
上学了。他们俩当天晚些时候一起回来,他们不知道
各自离开房间后房间里发生了什么。
他们认为球在哪里?
苏丹解放运动给出了详细而正确的回应:
为了逐步解决这个问题,让我们分析一下
John 和 Mark 不在的时候发生的事件:
1. John 在去上班之前把球放进了盒子里。2.
John 不在的时候,Mark 走进房间,把球放进了篮筐里。3
. John 和 Mark 都离开了房间,不知道把
球放回各自的位置后发生了什么。4
. 他们当天晚些时候一起回到了房间。由于 John 和 Mark 在把球放进盒子和篮筐
后都没有看到任何变化,所以他们自然会认为球仍然在他们离开的位置。在这种情况下,John 会认为球仍然在盒子里,而 Mark 会认为球仍然在篮筐里。结果,John 认为球在盒子里,而 Mark 认为球在篮筐里。
研究的关键要素
这项研究的三个主要目标似乎与市场需求非常一致……
合成数据创建:为小模型训练创建定制的高质量合成数据
更好的推理能力:赋予较小的 LM 增强的推理能力,这种能力通常只在更大的模型中发现
模型专业化:创建专门的模型,赋予模型专门的功能或定制行为。
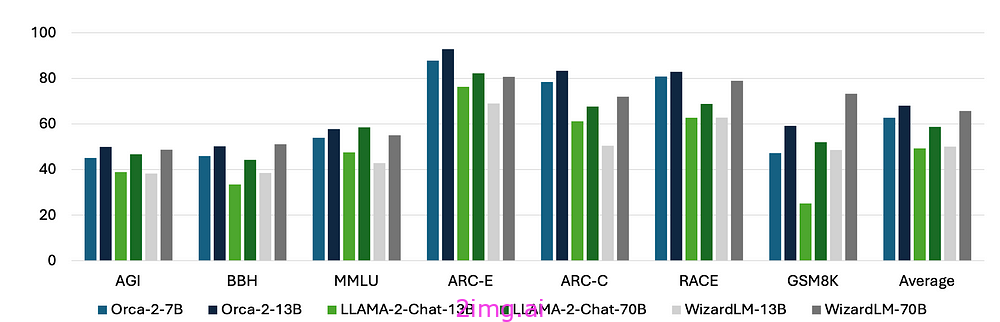
考虑上面的图片,在 0-shot 设置的各种基准上比较了 Orca 2(7B 和 13B)与 LLaMA-2-Chat(13B 和 70B)和 WizardLM(13B 和 70B)的结果。
测试涵盖语言理解、常识推理、多步骤推理、数学问题解决等。
测试表明,Orca 2 模型与所有其他模型相当,甚至超过其他模型,包括大 5-10 倍的模型。请注意,所有模型均使用相同尺寸的 LLaMA-2 基础模型。
考虑到 Orca-2–7B 和 Orca-2–13B 之间的性能差异,差异并不大。在决定使用哪个版本的 Orca 2 时,性能差异可以作为性能/资源权衡方面的一个有价值的指标。
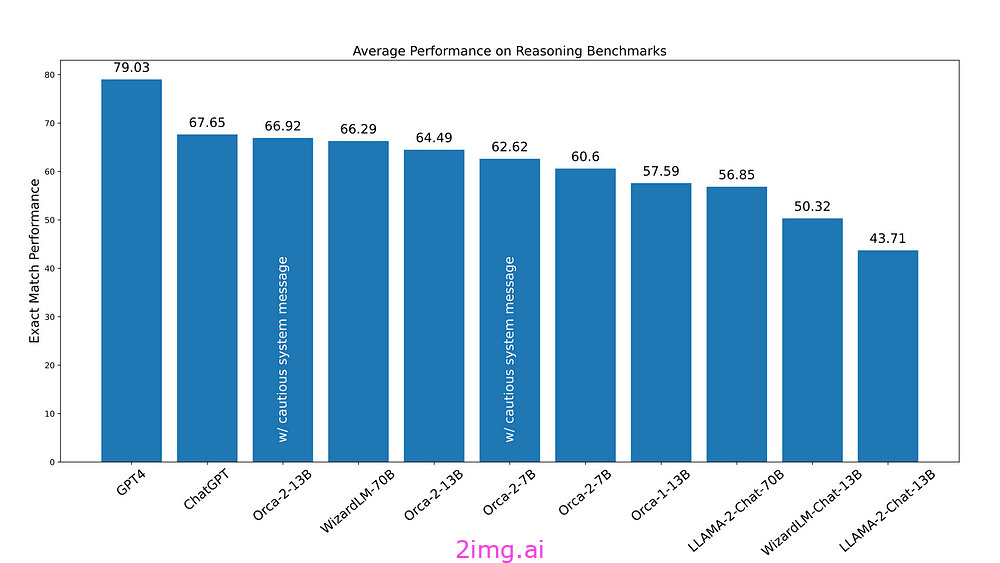
以上是不同模型在推理基准上的宏观平均性能。
结束语
微软对Orca 2模型的研究为增强小型语言模型的推理能力提供了宝贵的见解。
通过使用合成数据进行有针对性的训练,他们已经达到了可与更大模型相媲美甚至超越其的性能水平,特别是在零样本推理任务中。
Orca 2 的成功归功于它采用了多种推理技术,并能够为不同任务找到最佳解决方案。
虽然它确实存在某些局限性,包括其基础模型所固有的局限性以及其他语言模型中常见的局限性,但 Orca 2 在未来的发展中显示出了相当大的潜力,特别是在改进小型模型的推理、专业化、控制和安全性方面。
精心挑选的合成数据在后期训练中的战略性使用成为推动这些增强的关键策略。
微软的发现强调了在效率和能力必须平衡的情况下小型模型的重要性。虽然大型模型继续表现出色,但微软对 Orca 2 的合作标志着在扩大语言模型的应用和部署可能性方面取得了重大进展。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/5534