
RAG 管道正迅速成为开发聊天机器人的行业标准,聊天机器人可以检索外部信息并将其注入 LLM 呼叫提示中,以减少幻觉、保持最新信息并利用特定领域的知识。
然而,与任何尖端技术一样,优化 RAG 管道也面临着独特的挑战——从确保检索到的信息的相关性到平衡计算效率和输出质量。


Enter RAGChecker 是针对检索增强生成 (RAG) 系统的综合评估框架。它提供了一套指标来评估 RAG 系统的检索和生成组件。
本文将全面概述 RAGChecker,探讨其主要功能、它所使用的指标、RAGChecker 和 Ragas 之间的区别,以及如何利用 RAGChecker 构建有效的聊天机器人。
什么是RAGChecker
RAGCheker 是一个用于详细诊断检索增强生成 (RAG) 系统并评估每个检索器和生成器模块性能的框架。虽然传统评估指标(例如 Recall@k、BLEU、ROUGE、BERTScore 等)专门用于简短响应,但 RAGCheker 可以详细评估每个声明(RAG 系统生成的响应中的单个断言或信息),并更准确地评估 RAG 系统的性能。

特征
- 目的:RAGChecker 的开发是为了满足对针对 RAG 模型量身定制的强大评估工具的需求,该工具结合了检索和生成功能。它可以帮助研究人员和从业者了解其模型在实际应用中的有效性。
- 评估指标:该框架包括各种评估指标,用于评估检索和生成组件。这些指标包括传统指标,如精度、召回率和 F1 分数,以及特定于生成的指标,如 BLEU 和 ROUGE。
- 基准测试:RAGChecker 允许根据已建立的数据集进行基准测试,使用户能够将其模型的性能与最先进的系统进行比较。这种基准测试能力对于推动该领域的研究至关重要。
- 用户友好界面:该工具设计为可访问的,提供用户友好界面,简化评估流程。这使得具有不同技术水平的用户更容易使用该框架。
- 自定义数据集支持:用户可以输入自己的数据集进行评估,从而根据特定用例或领域进行定制评估。这种灵活性增强了 RAGChecker 在不同应用程序中的适用性。
- 模型改进的见解:用户可以通过分析 RAGChecker 生成的结果来识别其模型的优势和劣势。此反馈回路对于 RAG 系统的迭代开发和优化至关重要。
- 对 NLP 研究的贡献:RAGChecker 的引入为更广泛的自然语言处理(NLP)领域提供了评估 RAG 模型的标准化方法,从而促进该领域的进步和创新。
评估 RAG 管道
检索增强生成 (RAG) 管道由两个主要组件组成:检索器和生成器。评估 RAG 管道涉及评估两个组件的性能及其相互作用。以下是评估 RAG 管道的具体方法:
- 猎犬评价:
- 有效性:衡量检索器从知识库中识别和检索相关文档或信息的能力。可以使用诸如准确率、召回率和 F1 分数等指标来评估检索到的文档的相关性。
- 诊断指标:使用特定指标来识别检索过程中的优势和劣势。例如,评估检索文档的多样性或上下文完整性的指标可以帮助诊断检索错误 2.
2. 生成器评估:
- 响应质量:根据连贯性、相关性和事实准确性评估生成的响应的质量。可以使用 BLEU、ROUGE 等传统指标以及较新的基于嵌入的指标(例如 BERTScore),但它们可能需要更多扩展响应的帮助 1。
- 诊断指标:评估生成器如何很好地利用检索到的上下文。评估生成器处理噪声信息和产生准确响应的能力的指标对于理解至关重要。

RAGChecker 指标
RAGCheker 提供了一组指标,用于评估 RAG 管道的每个组件并从头到尾评估整个管道。
以下是 RAG 系统环境中常用的一些评估指标:
- 总体评价指标
精确
- 定义:评估生成的响应中正确声明(与正确响应相匹配的声明)的百分比。精确度是评估 RAG 系统生成信息准确度的指标。高精度表示大多数生成的声明都是基于正确的信息。
公式 :

记起
- 定义:评估正确响应中生成的声明的比例。召回率是评估系统回忆正确信息能力的指标,在评估系统覆盖率时至关重要。
公式 :
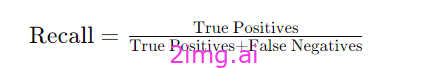
F1 分数
- 定义:它测量准确率和召回率的调和平均值。F1 分数是平衡准确率和召回率的指标,用于评估系统的整体性能,而不会偏向某一方。
公式 :

2. 生成指标
忠诚
- 定义:衡量生成器生成的声明与检索器返回的块的忠实度。忠实度衡量生成器是否根据准确的信息生成响应。值越高,表示生成的虚假信息越少。
公式 :

幻觉
- 定义:衡量生成器根据检索器未返回的信息生成的错误百分比。幻觉衡量生成器生成的错误声明的频率,是评估模型可靠性的指标。值越低,表示生成的错误信息越少。
公式 :

自我认知
- 定义:衡量生成器基于知识生成的正确声明的百分比。自我知识衡量生成器基于其训练数据生成准确响应的能力,而无需依赖检索器的信息。较高的值表示生成器具有可靠的自我知识,可以适当使用。
公式 :

上下文利用
- 定义:衡量生成器如何有效地利用检索到的上下文信息。上下文利用率衡量生成器利用检索器提供的信息正确生成准确声明的能力。高值表示响应准确反映了从检索器获得的信息。
公式 :

相关噪声敏感度
- 定义:测量对混入正确信息块的噪声的敏感度。该指标测量生成器对噪声(不需要的信息)的敏感性。较低的值表示生成器对噪声具有耐受性。
公式 :

3. 猎犬指标
索赔召回
- 定义:衡量检索器返回的块对正确响应中声明的覆盖程度。声明召回率是评估检索器检索到多少准确信息的指标。值高表示检索器正在选择正确的信息。
公式 :

上下文精度
- 定义:衡量检索器返回的包含正确声明的块的百分比。上下文精度衡量检索器返回信息的相关性。值高表示检索器可以提取准确的信息。
公式 :

Ragas 与 RAGChecker
RAGChecker 和 RAGA 评估检索增强生成 (RAG) 模型,但用途不同。RAGChecker 提供了一个广泛的框架来对整体 RAG 模型性能进行基准测试,重点关注准确性和相关性等指标。另一方面,RAGA 提供特定指标来评估 RAG 管道的各个组件,例如忠实度和上下文精度。RAGChecker 更注重模型的一般评估,而 RAGA 则侧重于详细的组件级评估。这两种工具对于评估和改进 RAG 模型的不同方面都很有价值。
让我们开始编码
使用 RAGCHECKER 评估 RAG 应用程序
首先,我们需要安装依赖项并设置环境
安装所有必要的依赖项
%pip install -qU ragchecker llama-index要使用 RAGChecker,您需要准备一个带有results数组的 JSON 结构。数组中的每个项目都对应一个查询,并包含查询本身、预期答案、RAG 生成的响应以及模型检索到的用于通知该响应的文档等详细信息。
{
"results": [
{
"query_id": "<query id>",
"query": "<input query>",
"gt_answer": "<ground truth answer>",
"response": "<response generated by the RAG generator>",
"retrieved_context": [
{
"doc_id": "<doc id>",
"text": "<content of the chunk>"
}
]
}
]
}满足了这些前提条件后,让我们深入了解一下 LlamaIndex。首先,我们将使用文档集创建索引,然后对其进行查询。在此示例中,我们假设有一个名为“Your documents”的目录,其中包含我们的文档。
该VectorStoreIndex.from_documents()函数获取我们加载的文档并创建索引。然后我们使用该as_query_engine()函数从该索引创建查询引擎。
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
# Load documents
documents = SimpleDirectoryReader("path/to/your/documents").load_data()
# Create index
index = VectorStoreIndex.from_documents(documents)
# Create query engine
rag_application = index.as_query_engine()现在,我们将演示如何使用response_to_rag_results函数,该函数对于将 LlamaIndex 等检索增强生成模型的原始输出转换为结构化格式至关重要,RAGChecker 可以使用该格式对模型的性能进行详细评估,确保检索到的文档的响应准确性和相关性。
from ragchecker.integrations.llama_index import response_to_rag_results
# User query and groud truth answer
user_query = "What is RAGChecker?"
gt_answer = "RAGChecker is an advanced automatic evaluation framework designed
to assess and diagnose Retrieval-Augmented Generation (RAG) systems.
It provides a comprehensive suite of metrics and tools for in-depth analysis
of RAG performance."
# Get response from LlamaIndex
response_object = rag_application.query(user_query)
# Convert to RAGChecker format
rag_result = response_to_rag_results(
query=user_query,
gt_answer=gt_answer,
response_object=response_object,
)
# Create RAGResults object
rag_results = RAGResults.from_dict({"results": [rag_result]})
print(rag_results)RAGChecker 配置为使用特定模型来提取和检查响应,确保评估之间的一致性。使用批处理表明该系统可能旨在有效处理大型数据集。
from ragchecker import RAGResults, RAGChecker
from ragchecker.metrics import all_metrics
# Initialize RAGChecker
evaluator = RAGChecker(
extractor_name="bedrock/meta.llama3-70b-instruct-v1:0",
checker_name="bedrock/meta.llama3-70b-instruct-v1:0",
batch_size_extractor=32,
batch_size_checker=32,
)
# Evaluate using RAGChecker
evaluator.evaluate(rag_results, all_metrics)
# Print detailed results
print(rag_results)此输出提供了 RAG 系统性能的全面视图,详细说明了整体、检索器和生成器指标。
RAGResults(
1 RAG results,
Metrics:
{
"overall_metrics": {
"precision": 66.7,
"recall": 27.3,
"f1": 38.7
},
"retriever_metrics": {
"claim_recall": 54.5,
"context_precision": 100.0
},
"generator_metrics": {
"context_utilization": 16.7,
"noise_sensitivity_in_relevant": 0.0,
"noise_sensitivity_in_irrelevant": 0.0,
"hallucination": 33.3,
"self_knowledge": 0.0,
"faithfulness": 66.7
}
}
)结论 :
RAGChecker 代表了 RAG 模型评估的重大进步。它为研究人员和开发人员提供了必要的工具和指标,以增强他们的系统并为 NLP 技术的持续发展做出贡献。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/5409