
ICML 是每年最大的机器学习会议之一,数千名研究人员参加,展示最新的前沿研究。我看到了一些非常好的演讲和海报,遇到了一些有趣的人,我对机器学习研究的现状有了很好的了解。因此,在这篇文章中,我将列出并详细介绍我看到的一些最有趣的事情。这个列表绝不是详尽无遗的,因为同时有这么多会议和研讨会,不可能涵盖所有内容,所以如果你最喜欢的主题没有在这里介绍,请原谅!
GNN
我先简单说一下。我以前对 GNN 很感兴趣,虽然今年有很多关于 GNN 的论文,但它们似乎大多是从更理论的角度出发的。不过,这篇论文是其中最突出的一篇,它及时更新了流行的 GPS 架构。期待尝试一下!
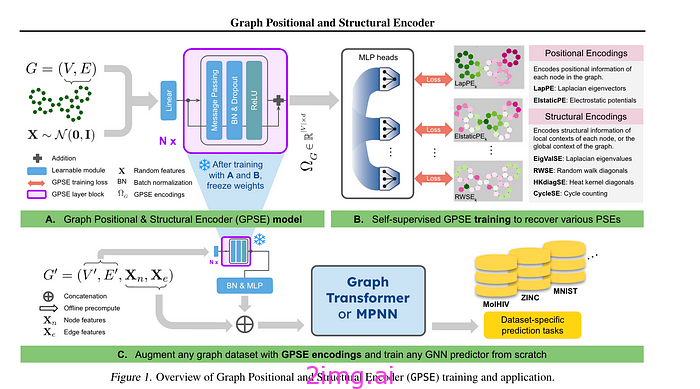
- 图形位置和结构编码器——学习图形的位置和结构编码。https ://arxiv.org/abs/2307.07107

- 请原谅我的自我推销,但如果我不提及我们的论文,那我对我的同事来说就是失职了——𝙼𝚒𝚗𝚒𝙼𝚘𝚕 :一种用于分子学习的参数高效基础模型。https ://arxiv.org/abs/2404.14986
生物化学
正如越来越普遍的情况一样,今年AI4Science的应用方面表现得非常好。特别是,许多人都在尝试更新将语言模型和 GNN 应用于分子/蛋白质问题的方法。
- 训练计算最优蛋白质语言模型——本身并不是一个新想法,但缩放定律与 Chinchilla 不同,并且取决于训练中使用的数据,因此这是一个非常有价值的见解。他们还很好地比较了 MLM 和自回归缩放在相同基础数据集下的表现,以及这些数据集本身的局限性。https ://www.biorxiv.org/content/10.1101/2024.06.06.597716v1
- 制作 Graph2Token:让 LLM 理解分子图— 这是一个有趣的角度,他们添加了一个适配器,将分子图嵌入到预训练的 LLM 中作为输入。基础模型的出色训练后用途。https ://openreview.net/forum?id=oqmbHWAGFM&referrer=%5Bthe%20profile%20of%20Mingqi%20Yang%5D(%2Fprofile%3Fid%3D~Mingqi_Yang1)
- ProtMamba:一种同源性感知但无比对的蛋白质状态空间模型——将 Mamba 模型应用于蛋白质序列,其中它们将多个序列堆叠在一起以利用巨大的上下文窗口。https ://www.biorxiv.org/content/10.1101/2024.05.24.595730v1
- 在变分自动编码器中结合图形注意力和循环神经网络进行分子表征学习和药物设计——这是一种将分子图转换为微笑字符串输出(和一组属性)的巧妙方法。然后他们可以使用可调温度参数来控制生成时要探索的距离原始源分子有多远。https ://openreview.net/pdf ?id=7WYcOGds6R

- Caduceus:双向等变长距离 DNA 序列建模——更多关于生物建模所需的真正长距离上下文窗口的调整工作。https ://arxiv.org/abs/2403.03234
- ESM All-Atom:用于统一分子建模的多尺度蛋白质语言模型——他们在这里训练了一个跨多个长度尺度的 ESM 模型,它使用两个不同的分子和蛋白质编码器将它们嵌入到同一个统一的标记空间中。然后用一个 ESM 主干处理标记序列。这确实一次只能处理一个对象,但这是一种在单个模型中学习两个长度尺度属性的非常有趣的方法。https ://arxiv.org/abs/2403.12995
- GeoMFormer:几何分子表征学习的通用架构——一种用于分子表征的混合不变/等变注意力机制https://arxiv.org/abs/2406.16853
- 用于联合多配体对接和结合位点设计的谐波自调节流匹配— https://arxiv.org/abs/2310.05764
- CLIPZyme:反应条件酶的虚拟筛选— https://arxiv.org/abs/2402.06748
- MESS:现代电子结构模拟——利用 JAX 原生加速功能对分子电子结构进行 DFT 模拟的现代更新。(https://openreview.net/forum?id=umhWTptx9O)
大型语言模型
有大量的 LLM 论文——我们可以将它们大致分为三类:
- RLHF/RLAIF — 目前正在进行大量工作,试图了解 RL 在调整 LLM 方面究竟有何威力和局限性,并且越来越多的人正在研究如何使用 AI 辅助 RL 来实现这一自动化。
- 一组被广泛归类为分析的论文——研究偏见是如何产生的,通过提示可以维持什么样的控制或调整,在情境中“学习”是如何产生的,以及它对下游任务的影响。
- LLM 中的高效训练和推理。很多人都在研究如何通过数值/算法优化以及开发更强大的小型模型,使 LLM 训练更快、更高效。
话虽如此,这可能是这篇文章中评论最多的部分,在这里我主要只是收录了那些让我印象深刻并想停下来与作者交谈的论文。
- 展望未来还是环顾四周?自回归和掩蔽预训练之间的理论比较——本文的作者研究了自回归和掩蔽语言建模之间的根本区别,我认为这将成为未来真正有价值的参考资料。https ://arxiv.org/abs/2407.00935
- LongRoPE:将 LLM 上下文窗口扩展到 200 万个标记之外— 更新 ROPE 位置编码(几乎所有当前 SOTA LLM 都使用这种编码),以允许更长的序列。我猜明年我们会在更多模型中看到这一点。https: //arxiv.org/abs/2402.13753
- Transformers 是 SSM:通过结构化状态空间对偶实现的通用模型和高效算法 ( Mamba-2) — 随着 SSM 在语言建模领域继续慢慢占据更稳固的地位,Mamba 架构的更新。我们仍在等待最终结果 — https://arxiv.org/abs/2405.21060
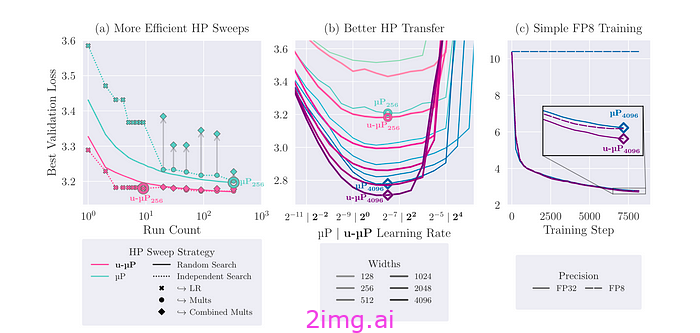
- u-μP:单位尺度最大更新参数化——它们结合了流行的 MuP 方法,可以以低成本将超参数从小模型转移到大模型,以应对真正低精度的训练——https ://arxiv.org/abs/2407.17465
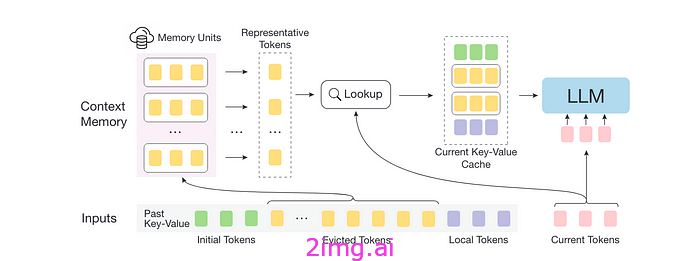
- IInfLLM:具有高效上下文记忆的 LLM 的免训练长上下文外推— 众多论文之一,提出了扩展 Transformer 模型的“工作记忆”以摆脱上下文窗口限制的想法。在这种情况下,他们将正常序列与查找所有先前看到的序列相结合,几乎完美地完成了长距离任务。https ://arxiv.org/abs/2402.04617
- Lightning Attention-2:处理大型语言模型中无限序列长度的免费午餐— 虽然线性注意力具有理论上的计算优势,但充分利用这些算法存在一些常见的瓶颈。此方法重构了一些线性注意力块以绕过这些限制。https ://arxiv.org/abs/2401.04658
- 用更少的资源获得更多:使用 KV 缓存压缩合成递归以实现高效的 LLM 推理— 作者在此提供了一种维护缓存的新方法,无需增加内存或直接删除缓存中的项目。这对于我们可能需要考虑所有先前标记(而不仅仅是“最重要的标记”)的任务尤其重要。https ://arxiv.org/abs/2402.09398
- 当线性注意力遇到自回归解码:迈向更有效、更高效的线性化大型语言模型——作者分析了线性注意力的有效性,并将其与推测解码有效结合起来。—— https://arxiv.org/abs/2406.07368
- MobileLLM:针对设备用例优化十亿分之一参数语言模型— 这是一篇非常棒的论文,他们介绍了创建高性能小型 LLM 的过程。他们的重点是使 LLM 适用于移动用例,但对于普通读者来说,他们提供的最有价值的见解是他们做出的每个模型选择如何影响性能和包含每个模型的成本。https ://arxiv.org/abs/2402.14905
- 拼贴:用于 LLM 训练的轻量级低精度策略— 真正的 fp16 训练,无需任何精细操作即可达到更高的精度。他们使用一种新颖的方法来实现这一点,即使用复合浮点数跟踪模型中各种状态的值。https ://arxiv.org/abs/2405.03637
- DiJiang:通过紧凑内核化实现高效的大型语言模型——用于 LLM 的高效紧凑内核。https ://arxiv.org/abs/2403.19928
对比学习
- Jina CLIP:你的 CLIP 模型也是你的文本检索器——他们提供了一种训练方法来改进 CLIP 模型中的文本编码器,使其成为更好的独立模型。https ://arxiv.org/abs/2405.20204
- OT-CLIP:通过最佳传输理解和概括 CLIP — CLIP 损失重新格式化为最佳传输。https ://openreview.net/forum ?id=X8uQ1TslUc
- 谨慎行事:对 CLIP 进行预训练,以防有针对性的数据中毒和后门攻击— 他们有一个安全的 CLIP 预训练方案来防止对抗性攻击,在 VLM 中,这对于安全很重要,但也包括错误标记的数据。关键是他们发现永久“毒害”CLIP 模型以重复错误所需的不正确数据量比传统的监督设置要少几个数量级(即一次出现一个错误)。https ://arxiv.org/abs/2310.05862
- EMC2:具有全局收敛性的对比学习高效 MCMC 负采样— 他们使用 MCMC 方法生成对比学习的负样本 — 并发现他们可以在线完成此操作,并且与批量大小的选择无关。https ://arxiv.org/abs/2404.10575
- 用于选择性分类的置信感知对比学习——除了传统的距离度量之外,它们还包括置信度的测量。https ://arxiv.org/abs/2406.04745
其他讲座
- 有一场关于在高能物理中使用机器学习的精彩演讲,非常有趣,我既能看到它自我到那里以来取得了多大的进步,也能看到它在与机器学习研究的主要分支略有不同的轨道上取得了怎样的进展。
- Max Jaderberg 关于 Alphafold-3 的演讲,非常精彩。该论文已在《自然》杂志上全面更新。不再是预印本。也许最有趣的是,他们希望 v4 能够预测功能并能够生成假设。我不确定这到底意味着什么,但可能更接近于设计的快速迭代。(https://www.nature.com/articles/s41586-024-07487-w)
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/5280