
大语言模型改变了人类搜索日常信息的方式。
尽管 LLM 非常适合一般场景,但在询问医学、法律、金融等专业知识时,会出现幻觉并产生不相关的信息。
他们也没有提供这些不断更新的领域的最新信息,而是提供了过于简单的回答,而没有考虑新颖的见解或发现。
LLM 也无法访问与某个领域相关的现成私有和专业数据,除非对其进行微调。然而,微调是一个复杂的过程,需要领域专业知识、大量时间和计算资源。
为了解决这个问题, 2021 年推出了检索增强生成 (RAG)。这种方法允许 LLM 使用专门的私有数据集来回答用户查询,而无需进行任何微调。
2024 年初,使用图形检索增强生成 (GRAG)使得该过程更加准确。
最后,我们有了MedGraphRAG,这是一个专为医疗领域设计的新型基于图的检索增强生成 (RAG) 框架。
该方法在多个医学问答基准上始终优于最先进的 LLM(即使经过微调)。
它还避免了 LLM 响应生成的“黑箱”方法,确保响应包含源文档,这在医学领域是绝对必要的,因为幻觉响应可能会造成生命损失。



这里我们深入研究了 RAG、GraphRAG 和MedGraphRAG的工作原理并显著提高了专业领域的 LLM 响应的性能。
我们走吧!
让我们从 RAG 开始
RAG 或检索增强生成 (RAG)是一种信息检索技术,它允许 LLM 使用特定于用例的私有数据集生成更准确和最新的响应。
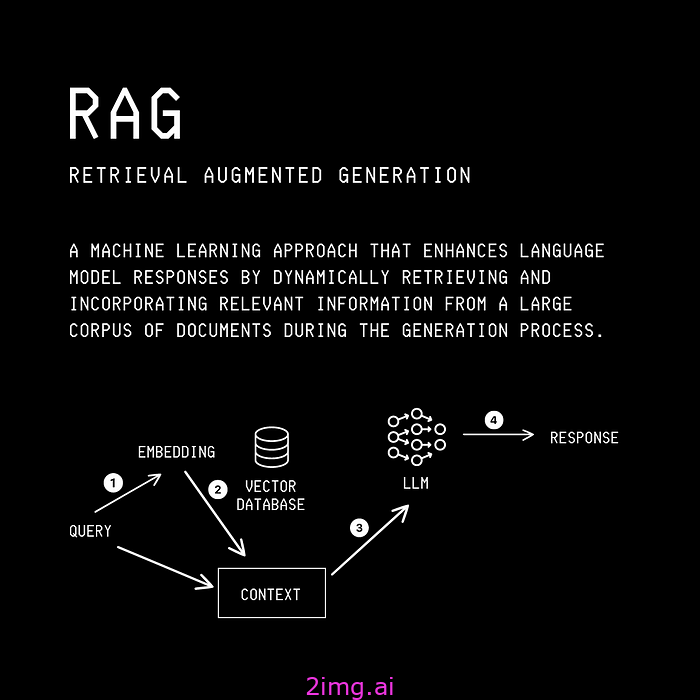
RAG 中的术语含义如下:
- 检索:从知识库/特定私有数据集检索相关信息/文档的过程。
- 增强:将检索到的信息添加到输入上下文的过程。
- 生成:LLM根据原始查询和增强上下文生成响应的过程。
尽管 RAG 非常有用,但它有时很难根据共享属性连接信息。
在需要深入理解大型数据集中总结的语义概念的任务中,它的性能也会受到影响。
为了解决这些限制,Graph RAG 于 2024 年推出。
接下来我们就来说说。
什么是 Graph RAG?
图形 RAG 或图形检索增强生成 (GRAG)通过合并知识图来扩展 RAG 。
虽然 RAG 本质上忽略了文本信息中的拓扑关系,但 GraphRAG 使得使用它成为可能。
GRAG 的核心工作流程分为四个阶段:
- k 跳自我图的索引:此步骤涉及创建以每个节点(称为自我)为中心的可搜索子图,其中包括自我
k步骤内的所有连接节点。 - 图检索:此步骤从索引子图中检索给定查询最相关的自我图。
- 软修剪:此步骤删除检索到的子图中不相关的实体,以减少它们对生成过程的影响。
- 使用修剪的文本子图生成:此步骤涉及使用修剪的子图从 LLM 生成文本。

GRAG 检索与查询相关的子图,而不是像 RAG 那样检索离散文档。
这减少了语义相似但不相关的文档(下图中以红色显示)对生成的负面影响。

然后,我们将 Graph RAG 中的这些概念进一步扩展到医学领域,这就是我们得到MedGraphRAG 的方式。
接下来我们来讨论一下它是如何工作的。
MedGraphRAG 如何工作?
MedGraphRAG 或 Medical Graph RAG 的工作流程可以简单描述为以下三个步骤:
- 医学图谱构建
- 将医疗文档分成几部分
- 从这些块中提取相关实体
- 将它们组织成一个三层图形结构,将这些实体链接起来
2.图检索
- 给出用户查询,检索相关图形和实体
3.文本生成
- 使用检索到的信息生成文本,并引用源文档
让我们更详细地了解每个步骤。
语义文档分割
给定知识库或私有数据集,此步骤将其文档分成块。
传统的 RAG 方法涉及基于 token 大小或固定字符的分块。然而,这些方法会导致语义信息的丢失,因为无法很好地检测到主题的细微变化。
为了解决这个问题,我们使用了不同的分块方法。
首先,换行符用于隔离文档中的不同段落。
然后,使用一种称为命题传输的语义分割技术将每个段落转换成自维持的陈述/命题,如此处所述。
接下来,法学硕士 (LLM) 会按顺序分析每个命题,以确定是否应该将其与现有块合并或从头开始。
该过程每次执行五段,使用滑动窗口技术来减少噪音。
还设置了一个硬阈值,以便最长的块不超过 LLM 的上下文长度限制。
这些步骤将文档分成有意义的块,然后在其上构建图表。
元素提取
此步骤涉及从每个块中识别和提取相关实体(节点)。
提示 LLM 输出每个块中每个实体的名称、类型(来自预定义的专业医学术语列表)和描述。
该提取过程重复多次,以减少噪音并确保完整性和质量。
每个提取的实体也被赋予一个唯一的 ID 来追踪其源文档和段落。
层次结构链接
此步骤可确保 LLM 除了精确的医学术语之外,不会扭曲或添加不相关的信息。
这是通过构建三层 Graph RAG 数据结构将每个提取的实体链接到基础医学知识和术语来实现的。
其顶层/第一级涉及从私人用户提供的文档中提取实体。
研究人员使用MIMIC-IV 数据集(该级别的公开电子健康记录数据集)进行实验。
第二层是通过将这些实体与教科书和学术文章创建的基础医学知识图表相链接而构建的。
在这个层面上使用的MedC-K 语料库包含480 万篇生物医学论文和 30,000 本教科书。
在第三层级中,第二层级图表进一步与来自可靠资源(如统一医学语言系统 (UMLS))的成熟医学术语相连接。
关系链接
此步骤涉及使用 LLM创建加权有向图(称为元图)来识别明确相关的实体之间的所有关系。
这增强了图形结构的丰富性。
标签图的生成和合并
下一步将所有元图链接起来以生成全局图,该全局图可用于有效检索医疗查询的信息。
首先,LLM 根据预定义的医疗类别(例如症状、病史、身体功能和药物)生成元图的摘要。
这将产生一个简洁描述元图中心主题的标签列表。
使用这些标签,可以计算不同元图之间的相似度,从而指导它们合并为单个全局图。
下图显示了上述所有步骤的摘要。

图检索
此步骤涉及 LLM 从全局图中检索信息以响应用户查询。
首先为每个用户查询生成汇总标签。
然后使用这些来识别图表中最相关的部分。
这是使用一种称为U-retrieve的自上而下的匹配方法完成的,其中匹配从较大的图开始然后移向较小的图。
这会在图中找到相关实体及其最k相关的实体来回答用户查询。
文本生成
此步骤涉及 LLM 从检索到的信息生成中间响应表单。
该中间响应以自下而上的方式与更高级别图的汇总标签信息相结合,在沿轨迹扫描所有索引图后生成最终响应。
MedGraphRAG 的性能
MedGraphRAG 显著提高了不同 LLM 在多个医学基准( PubMedQA、MedMCQA和USMLE数据集)上的性能。
较小模型(如 LLaMA2–13B 和 LLaMA3–8B)的性能显著提升,而这些模型本身在这些基准测试中的表现通常不佳。

该方法还提高了 GPT 和 LLaMA3–70B 的准确性,从而获得了最先进的 (SOTA) 结果,甚至超过了临床工作流程中人类专家的准确性。
值得注意的是,MedGraphRAG 甚至比医学领域的微调模型表现更好。

对该方法的消融研究表明,文档分块、分层图构建和 U 检索虽然复杂,但显著提高了其性能。

最后,MedGraphRAG 还通过列出来源,使 LLM 能够对复杂的医学问题生成基于证据的答复。
RA/SD 衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/5219