
偶尔,一项研究就会自动成为标准。最近发布的LLM新抽样方法就是其中之一。
很快,所有 LLM 都将采用它。
它被称为Min-p抽样,在数学或事实问答等容易出错的任务中,只需几行代码即可立即将 LLM 准确率提高 10/20%。重要的是,与现状相比,它似乎没有明显的缺点。
但如此简单的改变怎么会如此有效呢?
了解大语言模型(LLM)的工作原理
要理解这一点的重要性,我们需要了解大语言模型(LLM) 的运作方式。但不是每个人都告诉你的那样。
它们究竟是如何工作的。
通用任务接口
在训练深度神经网络时,必须定义希望模型优化的任务。
在 LLM 案例中,该任务是下一个单词预测;模型以文本序列的形式接收一组输入词,然后预测下一个标记。
从现在开始,我将把标记称为“单词”,但实际上,它们可以是单词或子单词(类似于音节)。
该标记被添加到序列中,并且整个序列再次通过模型驱动,生成下一个标记,依此类推。
为了训练这样的模型,就像当今所有的神经网络一样,我们需要找到一种方法来衡量每个模型的预测,并使用该信号(预测的好坏)来减少随着时间的推移的“错误”。
幸运的是,互联网上有大量文本,这些文本可以作为训练数据。因此,为了衡量模型的预测能力,我们只需隐藏模型的下一个单词,然后查看 LLM 所知道的所有可能单词中,分配给正确单词的概率百分比是多少。
因此,模型学会为正确的单词分配最高的概率。
此时,您可能会得出结论,模型将始终预测最可能的下一个单词,这是每个人对 LLM 给出的定义。
但事实并非如此。这些模型并不是简单地预测一个词的可信度。
它们对分布进行建模。
他们实际上预测了什么?
因为我们希望我们的模型能够对整个书面语言进行建模,并在需要时发挥创造力,所以这个预测不仅仅是模型认为最合适的单词,而且我们强制它为词汇表中的每个标记分配一个概率。
换句话说(没有双关语的意思),该模型不仅可以预测一个单词,还可以预测按“下一个单词的合理性”排序的整个词汇表。而定义的这种微妙变化改变了一切。
如果我们不这样做,模型将完全确定性,并且根据我们要求学习的内容(最大化下一个单词是它在训练期间看到的实际单词的可能性),它将基本上收敛成为其训练数据的字面体现。
虽然有理由这样做,但它会把模型变成一个模仿互联网数据的无聊单词包,既不智能也不有趣。但通过强迫它模拟其他单词的概率,模型学会生成与原始序列语义相似但不一定相等的替代序列。
事实上,如果你想要一个生成模型(ChatGPT 或 MidJourney)的数学定义,它们都是多元参数曲线函数,可以找到最优参数集,从而最大程度地提高观察训练数据或与原始数据在语义上相似的序列的可能性。
我知道,这个定义有些拗口,但这是我能给出的最严格的定义。
但是请稍等一下。如果模型定义的概率不只是一个单词,而是词汇表中的数千个单词,那么它除了最有可能的单词之外还可以选择其他单词,对吗?
是的,它确实会这么做。但是怎么做呢?嗯……它会随机选择一个。
等一下,什么?
不管是不是鹦鹉,它们都是随机的
由于模型已经看过整个互联网,因此它还学习了语法、同义词等。因此,它隐性地了解到,有多种方法可以生成具有相同语义含义的文本。
重要的是,它还了解到某些预测比其他预测更重要。例如,如果我们问伦敦大火发生在哪一年,尽管模型仍然为其他选项分配概率,但概率分布将极度偏向标记“1666”(或应该是)。
另一方面,如果你要求它写一首诗,该模型就拥有更多的“创作自由”。它可以用不同的方式组合单词,同时仍能满足用户的要求。
因此,根据模型的确定性,分布可能会非常偏向于为一个或两个单词分配极高的概率,而在其他情况下,它可能是“平坦的”,其中数十个单词可能是正确的。
例如,如果我告诉您序列“男孩去了”,如果没有提供额外的上下文,那么该序列之后可能出现的标记至少有数百个。
正如您在下面看到的,该分布为 5 个不同的单词分配了相当高的概率,尽管有些单词可能比其他单词“更可能”,但从语义上来说都是可行的。
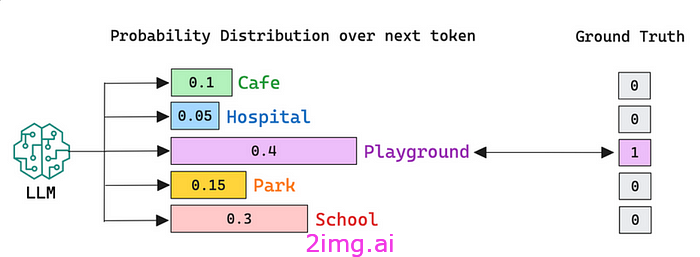

但是,如果我们观察上一个关于伦敦大火的问题的分布,我可以向你保证,“1666”的概率为 +90%,其余的概率仅略高于 1%。
话虽如此,我们仍然没有回答模型实际上是如何选择选项的。最流行的方法是top-p,其中模型从一组最有可能的标记中随机选择,这些标记组合起来达到超过阈值的概率。
例如,回到伦敦大火的问题,如果阈值是 0.9,而分配给 1666 的概率是 0.91,那么模型将别无选择,只能选择该标记。
但是,如果出于某种原因,分配给 1666 的概率是 0.87,如果阈值是 0.9,则模型将包含尽可能多的标记以达到 0.9,然后随机选择。
这是最糟糕的情况,因为模型得出不准确结果的可能性会大幅增加。如果模型必须填写“1987”等选项(可能性为 1%),以及“1573”和“2010”等选项(可能性也各为 1%),那么即使“1666”有 87% 的可能性是正确选择,模型仍会在四个选项之间随机选择。
突然间,模型失败并输出错误年份的可能性高达 75%。
悲剧。那么,如果有更好的方法来防止这种情况发生呢?那就是 min-p。
最小P采样,性能助推器
简单来说,Min-p 通过设置依赖于最高概率值的动态阈值来截断分布。
也就是说,min-p 的最终数字是两个数字相乘的结果:
- 定义为超参数的基值
- 分配给最可能标记的概率
例如,在下图(顶部)中,最有可能的单词的概率为 0.47。如果基础最小 p 为 0.1,则最小 p 阈值将为 0.047(或 4.7%)。换句话说,任何可能性小于该可能性的单词都会被自动拒绝。
因此,除了两个之外,其他都被拒绝了。这很好,因为模型的分布已经明显偏向这两个选项,这意味着我们能做的最好的事情就是拒绝所有其余的。
另一方面,如果我们看第二个分布,它明显“更平坦”。
因此,模型对于下一个单词应该是什么更加不确定,因此,min-p 在拒绝时应该是适度的。
幸运的是,由于 min-p 阈值是动态的并且取决于模型的确定性,截断阈值几乎达到 0.01(1%),因此仍有许多可能的标记可供采样。
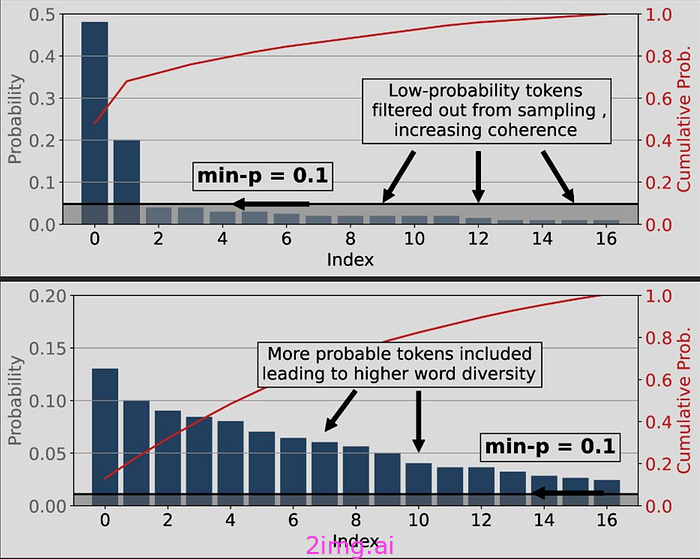
– 当面对事实、数学或选项较窄的事件时,顶部分布更为常见
– 底部分布在创意写作等任务中更为常见,我们期望模型具有创造力。
长话短说,虽然 top-p 采样选择了“最有可能的一个”,但min-p 实际上考虑了分布的结构,在结果明显时激励输出高度可能的标记,并且在分布具有长尾的情况下不会影响模型的创造力。
正如您所想象的,min-p 用途更加广泛,尤其适合对抗幻觉。
如果我们看一下伦敦大火的例子,即使模型不确定,最小 p 值为 0.2 也会自动拒绝除“1666”之外的所有标记。不过,当一个标记比其他标记的可能性大得多时,最小 p 值会严重偏向最有可能的标记,从而挽救局面。
即时经典?
这是最好的研究类型。简单、切中要点,而且立即有用。
在 GSM8k(数学)和 GPQA(生物、物理和化学领域专家编写的多项选择题)等流行基准测试中,该模型仅通过将 top-p 更改为 min-p 就立即获得了 10/20% 的更高结果。
尽管幻觉的风险不会降至零(除非我们找到一种方法在需要时将分布折叠成一个单一的标记,否则它可能永远不会降至零),但min-p 无疑是一种可以自动减少模型幻觉的采样方法。
尽管如此,我确信这是一个经典,它可以像 AdamW 和 MLP 一样成为标准,分别作为神经网络的优化器和构建块。
事实上,谷歌已经确认将很快在其 API 中提供对 min-p 的支持(它已经在 HuggingFace 的 Transformers 库中可用)。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/5208