Google Deepmind、斯坦福和牛津研究团队已经提出了令人信服的证据,证明默认选择“最智能”的法学硕士学位是一个巨大的错误。
当用作猴子时,较小的 LLM 可以自信地超越前沿 AI 模型的威力。它还提供了有关“长推理”模型的一些最深刻的见解,这些见解将使您怀疑围绕 LLM 建立的每一个直觉。
大型语言猴
智力水平
LLM 将通过两种方式提高他们的智力:
- 压缩:通过给模型“学习时间”,它们会通过寻找数据中的模式而天生成为更好的思考者。这种类型的智能使模型能够本能地、快速地、毫不犹豫地进行推理。
- 搜索:通过给模型“思考时间”,它们会在运行时探索可能的解决方案,直到找到最佳解决方案。这是一种缓慢、深思熟虑且“有意识”的解决问题的方法。
您可能已经意识到这些智力类型与已故丹尼尔·卡尼曼提出的著名“思维模式”理论——思维系统 1 和 2 极为相似。
系统 1 快速且自动;系统 2 缓慢、深思熟虑且有意识。
上周,我们看到了 Grokking 如何成为改善压缩和帮助模型从记忆模式到真正理解模式的最令人兴奋的趋势之一。
但是我们如何才能给模型“思考的时间”呢?
搜索的力量
无限猴子定理表明,一只猴子无限长时间地随机按下打字机上的按键几乎肯定会打出任何给定的文本,包括威廉·莎士比亚的全集。
同样,如果我们给法学硕士无限的时间来找出问题的所有可能的解决方案,他们最终会找到一个。这个前提导致所有人工智能实验室都在研究这个想法。
但这对我们来说意味着什么?
当我们要求搜索增强型 LLM 回答给定问题时,模型不会立即回复。事实上,它会进入深度思考阶段,开始生成数十、数百、数千甚至数百万(就Alphacode 2而言)可能的问题解决方案。
但为什么要这么做呢?直觉很简单。
我们并不希望模型第一次尝试就能得到正确的答案,而是最大限度地增加模型的尝试次数,以增加它至少得到正确答案的可能性,这类似于给模型更多的时间来得到正确的答案。
这是评估模型的更公平的方法。每当人类处理复杂问题时,我们都会探索可能的解决方案,例如尝试不同的方法来解决数学问题。在这里,我们将这一原则应用于LLM。
但是一旦我们有了可能的样本列表,我们如何决定哪个是最好的?
验证者问题
假设你的模型为某个问题生成了 1,000 个可能的解决方案。我们如何确定哪一个是最好的?答案是使用验证器。

有三种类型:
- 自动验证器。在代码等情况下,您可能有一组单元测试来验证代码片段是否解决了特定问题。在这些情况下,您可以自动验证解决方案是否正确。
- LLM 验证器。受到OpenAI 在 2021 年开创性工作的启发,我们可以训练额外的 LLM 来充当主 LLM 生成的“想法”的验证器(或使用 LLM 本身)。
- 两者结合。在无法进行自动验证的情况下(例如,当模型为文本生成 100 个可能的摘要时,选择最佳摘要是主观的,因此无法自动决定),您可以使用 LLM 来获取输出并转换其格式以使其可自动验证。
至于最后一种技术,谷歌使用了这种方法来训练 AlphaProof
简而言之,LLM(Gemini)将自然语言中的数学问题重新格式化为可以使用精益编程语言进行验证的正式语句,然后在其上训练模型。
当然,将主 LLM 和验证器结合起来可以产生更复杂的模型架构,其中 LLM 使用验证器探索开放式问题,直到找到答案,如下所示:
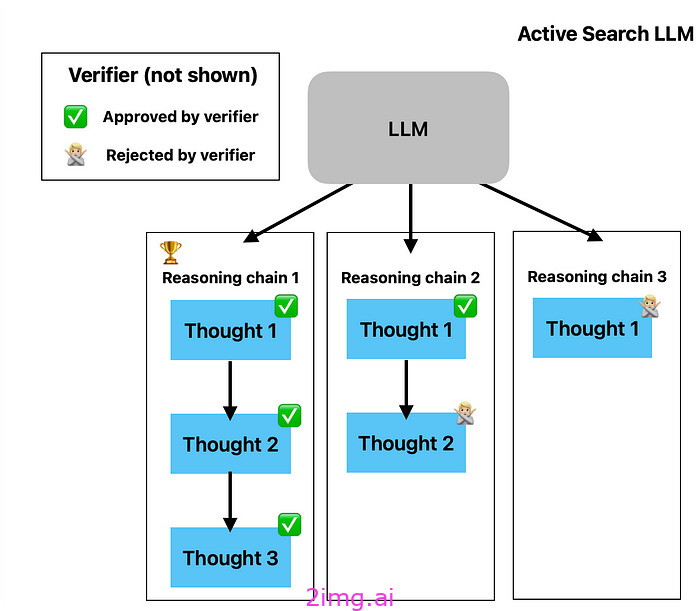
但对多种解决方案进行采样的好处真的那么重要吗?研究人员对这一范例进行了详细探索,并发现了一些有趣的见解。
以新眼光看待LLM
可能最“令人惊讶”的发现是,在很多情况下,追求“最智能”的模型是错误的决定。
最大的并不总是最好的。
为了证明这一点,他们分析了针对给定问题抽样多种解决方案的小型 LLM 是否会胜过没有多重抽样的更大、更智能的 LLM。
研究人员发现了什么?
令人印象深刻的是,在运行具有多重采样的小型语言模型 DeepSeek-V2-coder 时,该模型的表现优于 GPT-4o 或 Claude 3.5 Sonnet 等最先进的模型,在 SWE-Bench Lite(评估模型解决 GitHub 问题能力的基准)中达到了 56% 的新最高水平,而这两个模型结合起来达到了 43%(混合模型)。
这说明了多次采样的威力,因为同样的模型每个问题只有一次机会就达到了 15.9% 的覆盖率。
重要的是,此测试是在固定 FLOP 预算下进行的(每秒浮点运算量衡量模型每秒消耗的计算量)。因此,通过确保固定预算,计算量将相等,因为较大的模型仅运行一次,但可以大几个数量级。
我们如何计算 FLOP?
尽管研究人员使用更复杂的公式来估算 FLOP(第 6 页),但应用 OpenAI 提出的公式FLOP = 6*N /训练令牌是一种常见做法,其中 N 指的是非嵌入参数的总量。但是,对于大尺寸,嵌入参数可以忽略不计,因此您可以使用总量。例如,Llama 3.1 405B 有 4050 亿个参数,其中只有 20 亿是嵌入参数(128k 词汇大小,16k 通道),因此您可以简单地四舍五入到总值。
以总训练计算为例,Llama 3.1 8B 在 15 万亿个 token 上进行训练,其成本约为 = 6 x 8 x 10^9 x 15 x 10^12= 720 x 10^21,或720 十亿亿 FLOP(实际数字未公开,但这是一个合理的估计)。
此外,他们还证明,同样的模型,仅采样五次,就能在同一数据集中解决比 GPT-4o 和 Claude 3.5 Sonnet 更多的问题,同时成本至少便宜三倍。

看到这一点,用户和企业都应该自动重新考虑他们所做的每一个 GenAI 实施,因为很有可能他们(你)为他们的(你的)模型支付了过高的费用。
值得注意的是,通过微调,你可以训练小模型,使其表现优于大模型,即使在两种情况下都只有一个样本,正如 Predibase 不久前通过训练25 次 Mistral 7b 微调所证明的那样,所有微调都优于 GPT-4。
但研究人员并没有止步于此。该团队随后探索了可视为可视化推理缩放定律的首次尝试。
被遗忘的解锁器
您可能听说过“缩放定律”,该定律表明模型大小和总计算量的增加是提高性能的重要预测因素。用外行人的话来说,训练运行规模越大(模型越大,总投入计算量越大),结果就越好。
虽然这看起来似乎是真的,但最近“模型智能”的停滞可能是因为我们两年来一直停留在数千万 ExaFLOPs 的计算预算上(据马克·扎克伯格称, Llama 4 是第一个宣布将正式进入数亿 ExaFLOPs 的模型),业界主要关注的是训练方面。
因此,没有人测试过这是否适用于推理计算。因此,我们能否预测随着推理预算的增加,即模型实时运行时间更长,性能会更好?
嗯,这些研究人员已经证明答案是肯定的。
如下所示,无论使用哪种模型,随着每个问题的样本数量的增加,每个模型的覆盖率(可以解决的测试问题数量)都会提高。
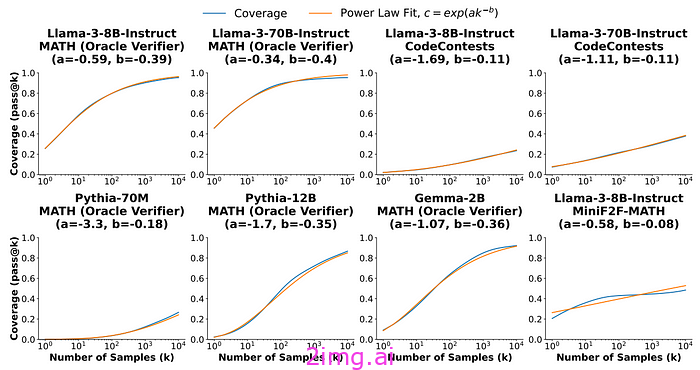
本质上,这意味着每当 LLM 面临需要解决的问题时,通过增加模型解决问题的尝试次数来增加推理计算应该会产生净改进。
总而言之,令人难以置信的是,您知道现在有一种简单易行的方法来改善部署结果:
给模型更多的时间思考。
向更智能的部署过渡
总之,虽然预计增加推理时间会改善结果,但这是我们第一次直观地观察到可测量的缩放定律的这种改进。
重要的是,这项研究还明确指出,在许多情况下,您应该优先考虑多样本实现,而不是“仅仅因为”而使用最佳可用模型。
相反,研究人员指出,当前基于 LLM 的验证器存在致命缺陷。非自动验证器(如 LLM)似乎处于停滞状态,这意味着虽然推理扩展定律可能在所有情况下都成立,但我们尚未创建真正强大的、可以自信扩展的 LLM 验证器。
话虽如此,由于模型智能停滞不前,而且没有迹象表明近期会出现 GPT-5 级模型,长期推理模型可能是投资者迫切寻找的信号,以继续信任大型科技公司在生成人工智能方面进行的巨额资本支出。
承认当前前沿的局限性,但展示一种大规模改善结果的方法,将是一个不炒作的叙述,让人感觉诚实(这在当今很难遇到),而且重要的是,足以让资金不断流入该行业。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/4983