
微软研究人员刚刚宣布,phi-3-mini 在人工智能效率方面取得了突破,这是一种语言模型,其性能接近 GPT-3.5 等行业领先者,同时体积小到可以在智能手机上运行。从表面上看,这是一个令人兴奋的发展——谁不想要一个口袋大小的人工智能助手,它甚至不需要互联网连接就可以进行深入的对话和分析呢?
但一旦你忽略了新颖性因素,就会发现设备上的 LLM 只是一种技术上的奇观,而不是改变游戏规则的进步。在无处不在的连接和云计算的世界中,故意限制 AI 在本地运行几乎总是会成为一种障碍,而不是一种功能。有用的语言模型应用程序几乎总是依赖于对实时信息的访问(或者让你在上下文窗口中提供实时信息)以及与其他系统交互的能力,这从根本上假设了一个联网环境。
在这篇文章中,我将分析 phi-3-mini 论文中的关键主张,并解释为什么我认为设备上的 LLM 最终是一条技术死胡同,至少在实际效用方面是如此。除了令人印象深刻的效率提升之外,无法充分利用云资源的模型将严重限制其为用户提供的价值。
概述
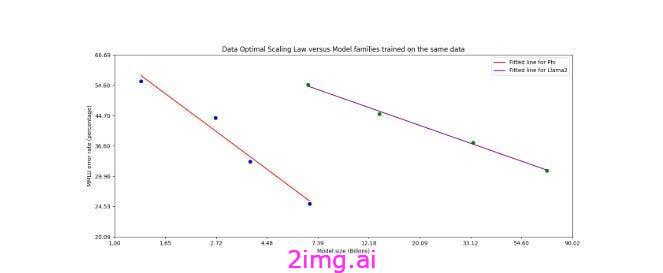
这篇论文的核心主张(更多详情请见此处)是,phi-3-mini 是一个 3.8B 参数的 Transformer 模型,它可以在问答和编码等基准测试中取得与更大的模型(例如 175B 参数的 GPT-3.5)相媲美的结果,同时体积最多只有其 46 倍。这不是通过改变模型架构来实现的,而是通过精心整理训练数据,使其信息更密集、更有针对性,作者将这种方法称为“数据优化”。

在 MMLU(68.8% vs GPT-3.5 的 71.4%)、HellaSwag(76.7% vs 78.8%)和 HumanEval(58.5% vs 62.2%)等常见基准测试中,phi-3-mini 确实取得了与其规模相当的令人印象深刻的结果。通过使用量化和长距离注意力等技术,他们能够在 iPhone 14 上完全本地运行该模型。
作者正确地指出了 phi-3-mini 的几个局限性,包括它仅限于英语、缺乏多模态理解,以及在知识密集型任务上的表现相对较弱(例如 TriviaQA 为 64.0%)。但他们未能解决设备上 LLM 的整个前提下更根本的问题 — —故意限制模型对网络资源的访问会削弱任何现实世界的应用程序。
技术细节
phi-3-mini 的关键创新是“数据优化”训练方法,该方法旨在整理一个数据集,使小型模型能够发挥其最大作用。具体来说,作者对网络数据进行了严格过滤,只保留了最具信息量的示例,并补充了旨在提高推理能力的大型模型的合成数据。假设是,许多自然数据集(如原始网络爬取数据)包含冗余或不相关的信息,浪费了模型容量。
该模型本身在架构上与 Llama-2 类似,使用仅解码器转换器,上下文长度为 4K 个 token(使用 LongRope 方法可调整为 128K)。它使用 bfloat16 精度对总共 3.3T 个 token 进行了训练。量化为 4 位可使模型在智能手机 SoC 上的 2GB 内存中运行。
在安全性和偏见方面,作者指出,通过对训练集进行重点过滤和额外的监督对齐可以带来改进(表 2)。但目前尚不清楚,在模型在数百万用户设备上自主运行且没有集中监控或控制的情况下,这些零碎的缓解措施是否足够(这可能是一个限制,也可能很有吸引力,这取决于您对 AI 安全/审查的看法)。
批判性分析
设备上的 LLM 的核心问题是:无论模型多么高效或训练有素,故意限制它在智能手机或平板电脑上本地运行意味着切断它与真正有用所需的绝大多数信息和功能之间的联系。
想想如今大型语言模型最具影响力的应用——搜索、内容生成、分析、编码、任务自动化。所有这些都利用了 LLM 与外部数据库、知识库和实时信息源交互的能力,这是绝对必要的组成部分。在手机本地运行的模型没有这些——它在孤岛中运行,与重要背景隔绝。
想象一下使用 GPT-3 撰写有关最近事件的报告或文章。该模型将利用来自网络搜索(您执行并输入的搜索或它自己执行的搜索)、新闻提要甚至实时社交媒体聊天的最新信息来构建其输出。现在想象一下尝试使用在您的 iPhone 上本地运行的 phi-3-mini 执行相同操作,由于某种原因没有与外界连接,即使您的手机可能有手机服务或 wifi。它所拥有的只是它的静态预训练知识和您的静态预训练知识,这两者都几乎立即变得陈旧。这甚至还没有涉及需要主动输出的任务,例如检索文件或写您想给另一个人的消息。
即使我们让当地的法学硕士来工作,你仍然需要一个网络来使这项工作发挥作用!
作者通过展示使用手机本地搜索的 phi-3-mini 的 PoC(图 4)来解决这个问题,但这远远不能弥补放弃云资源所造成的损失。语言模型从根本上来说是一个知识检索和组合引擎——为什么要刻意限制它对知识的访问呢?

设备上 AI 的倡导者经常指出隐私、安全和可访问性方面的优势。但实际上,云端支持的模型可以设计为隐私保护和安全,同时由于运行在集中式基础设施上而不是功能各异的用户硬件上,因此更容易访问。
从 AI 安全和道德角度来看,设备上的部署似乎适得其反。在用户设备上运行的 LLM 无人监督,没有集中监控,很容易发生滥用和偏见事件。当发现新的安全问题时,如何更新或修补这样的模型?如何防止对手提取模型权重并将其重新用于垃圾邮件和欺诈?对于云模型来说,这些问题已经够难的了,更不用说在不受信任的边缘设备上了。
结论
Phi-3-mini 在语言模型效率和压缩方面绝对是一项真正的成就。如果“数据优化”训练方法被证明是可靠的,那么它可以让我们以更少的计算和环境占用空间来训练高性能模型。这是一个有意义的进步,我不想贬低它。
但设备上的 LLM 的使用案例是技术上的死胡同。无论它们变得多么高效,无法与网络和外部工具和服务交互的模型在实际应用中总是会受到限制,因此您不妨为云使用开发 LLM。由于您需要互联网来获取输入和输出,因此您也应该在云中运行模型。
此外,将这些模型直接部署给用户似乎会使现有的安全性和偏见方面的挑战变得更加困难,而不是更容易(尽管您可能不会发现这是一个缺点)。
这里开创的技术的真正潜力在于使云模型更便宜、更高效,而不是实现本地部署。如果我们能够通过数据质量的提高,以更少的训练量获得 GPT-3 级别的能力,那么这将对未来 AI 进步的成本、可访问性和可持续性产生巨大影响。
因此,让我们为 phi-3-mini 欢呼吧——这是一个令人印象深刻的语言模型压缩演示,它挑战了我们对大小/能力权衡的假设。但我们也要清醒地认识到,设备上的 LLM 虽然作为技术演示引人注目,但并不是现实世界 AI 影响的未来。那个未来是云原生、多模式和深度网络化的。本地推理对于延迟和离线功能很有用,但它永远只是我们希望这些模型实现的一个有限子集。
RA/SD 衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/4977