大型语言模型 (LLM) 并非你所想的那样。你被骗了。LLM 很笨,非常笨。事实上,它们更接近数据库,而不是人类。
这就是为什么人工智能仍然处于征服智能的第一步……如果有的话。
终极煤气灯效应
建立前沿人工智能的成本很高。前沿人工智能需要大量风险资本。前沿人工智能实验室筹集了数十亿美元。前沿人工智能没有达到预期。前沿人工智能实验室撒谎来证明数十亿美元的投资是合理的。
这就是目前的人工智能行业。
(LLM) 不具备推理能力。
要想聪明,你必须具备推理能力。然而,法学硕士不会推理。或者说,几乎不会推理。
那么,LLM 们会怎么做呢?大多数时候,他们会呕吐。
业界最大的错误是接受我们可以使用基准来衡量模型智能,而良好的记忆就足以伪造智能。
常见的基准,如MMLU,是衡量“法学硕士的智力水平”的最流行方式,大部分可以通过简单的记忆来达到。
但就像一个 10 岁的孩子凭记忆做 16 岁孩子的数学题并不意味着他理解了数学;LLM非常擅长伪造他们的智力。
那么,我们如何衡量LLM到底有多聪明呢?只需在死记硬背无法挽救他们的情况下对他们进行测试即可。当你这样做时,现实就会显现出来:
(LLM) 不具备推理能力。
从 ARC-AGI 到爱丽丝梦游仙境
测试 (LLM) 寻找从未遇到过的问题的解决方案的能力的一种好方法是 ARC-AGI 基准,该基准与智商测试非常相似,其中模型有机会看到给定模式的一小部分示例,然后在下一次尝试时完成该模式。
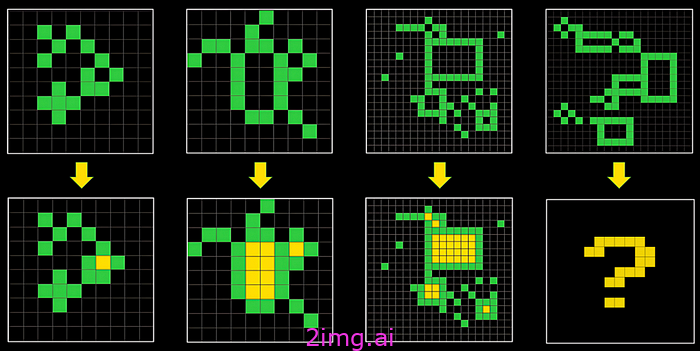
在这种情况下,该图案的解决方法是将四个绿色方块包围的每个方块涂成黄色。
对于 LLM 来说,这是一个非常困难的问题,原因有二:
- 它基于他们以前从未见过的练习,因此它可以从记忆中获取解决方案。
- 这是一个低概率练习;该模型只有少量的例子来概括答案。
当然,LLM 在这些测试中惨败,而普通人可以毫不费力地解决这些问题。但为什么呢?
再次强调,有两个原因:
- 如果他们不能使用记忆,他们就会失败,就是这样
- 与人类不同,它们的样本效率极低,需要大量的例子才能学习新的模式。
一些人通过使用测试时微调大大提高了 LLM 在此基准测试中的结果。他们通过代码生成多个可能的解决方案(有时需要数百万个),直到最终有一个是正确的。然后,他们在该解决方案上微调模型。
然而,这又回到了这两个问题。虽然无休止地生成可能的解决方案可能会让你走运,并且已被证明可以提高覆盖率,但它仍然需要进行微调(大规模进行微调的成本非常高),而且对于开放式问题(不像智商测试)来说,这不是一个可行的过程。
因此,如果采用让·皮亚杰对智能的定义:“智能就是当你不知道该做什么的时候所使用的东西”,那么当前的人工智能是不存在智能的。
但是,在缺乏经验或知识的情况下,他们无法解决新问题(解决“未知的未知数”),这并不是他们唯一的问题:他们也不擅长对已知知识进行推理(解决“已知的已知数”)。
爱丽丝梦游仙境测试
例如,一个简单的归纳推理测试,其中模型必须根据先前陈述的事实推断出一个事实,这足以让这些模型感到羞愧。
你不必相信我;你可以自己尝试一下。
当使用著名的爱丽丝梦游仙境测试的一个示例(一组简单的推理示例)进行测试时:该模型(在本例中为 GPT-4o)被证明令人尴尬地无法正确理解,无法推断出爱丽丝应该被纳入“姐妹组”的一部分。
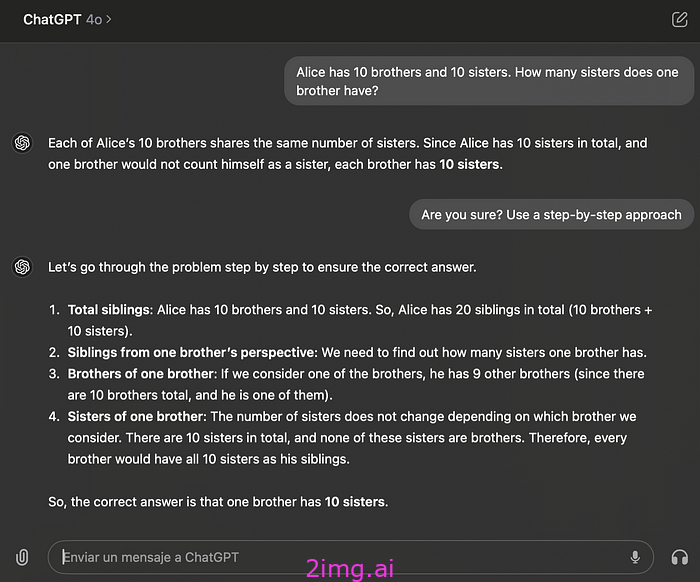
这是一个至关重要的认识。尽管拥有推断正确答案所需的所有信息,但除非你深入研究毫无意义的提示工程兔子洞,否则它仍然找不到答案。
但即便如此,它仍然会失败。

又一次。
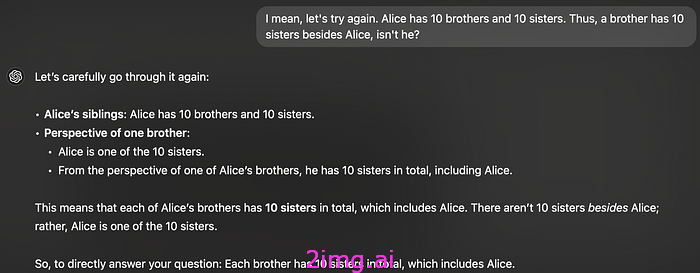
长话短说,大多数这些模型甚至无法对其数据应用最简单的推理链,这再次表明它们只是在重复过去的模式。
这就是它们被称为“数据库”的原因。只有当单词模式(单词如何相互衔接以产生问题的可能解决方案)之前曾出现过时,它们才能正确执行。
即使掌握了所有信息,它仍然无法从已知事实推断出事实……就像数据库一样。
但这是否意味着这些模型不会比数据库更智能呢?并不完全如此。
走向“AI”中的“I”
在迈向真正的智能的道路上,人工智能最终必须征服两个前沿。
压缩
我经常说 LLM 是“数据压缩器”,这种模型擅长获取庞大的数据集(比它们大得多)并将知识压缩到它们的权重中。
虽然这是不可否认的,但我们可以质疑压缩的质量,特别是如果我们将压缩分为两个步骤:
- 记忆:模型记住单词如何相互衔接,但不一定理解它们为什么相互衔接。
- 正则化:模型学习更简单的问题解决方案。模型不仅可以自信地预测单词如何相互衔接,而且还可以用更少的假设(奥卡姆剃刀)做到这一点。
模型倾向于先记忆,然后规范化。换句话说,它们首先学习“如果 x 那么 y”,随着时间的推移,它们学习“y 遵循 x,因为……”,从而捕捉到决定“y”为何遵循“x”的根本因果结构。
例如,如果模型记住了猫的长相,它可能会学到过于具体的结论。例如,它可能会得出“有毛”是必要条件的结论,因为它见过的大多数猫都有毛。
但通过正则化,模型会意识到其他属性(如胡须、狭缝状眼睛和尾巴)在区分猫方面更为重要。简化猫的定义可以使其推广到更广泛的定义,这样无毛猫(如斯芬克斯猫)也包括在内。
值得注意的是,由于机械可解释性技术,我们知道模型内部的推理电路也变得更简单,这意味着正则化在机械上是可见的。
简而言之,基于《爱丽丝梦游仙境》的例子,很明显 LLM 仍然处于压缩的第一步;他们刚刚征服了记忆(而且考虑到他们虚构的频率,这还只是刚刚开始)。
但即使他们最终征服了真正的正则化,他们在接近人类智能的道路上还需要再迈出一步。
长推理模型
这个想法很简单:如果压缩让模型有时间学习,那么长期推理技术就让模型有时间思考。
简而言之,这些模型并不是简单地回答首先想到的事情,而是会迭代数百、数千甚至数百万种可能的解决方案,直到收敛到最佳解决方案。
然而,我不清楚搜索如何成为您唯一需要的东西,因为没有迹象表明 LLM 最终会融合成实际的解决方案。
那么,学术界提出如何解决每个范式?
从数据增强到搜索
如果你问一个 LLM 爱好者,他们会告诉你“搜索就是你所需要的一切”,并且只需让模型具有搜索解决方案空间的能力就足以达到 AGI(通用人工智能,或上帝 AGI)。
一些研究人员,例如 Leopold Aschenbrenner,更进一步声称“计算就是你所需要的一切”,并且只需将我们当前的模型扩大到更大的尺寸就足够了。
但事实真是如此吗?
就我个人而言,我觉得这太离谱了,因为正如我们之前看到的,当前的模型即使掌握了所有事实,推理能力仍然很差。
更糟糕的是,我们已经达到了百万 exaFLOP 计算级别(这是 1,000,000,000,000,000,000,000,000,000,000 次浮点运算数量级的计算量,相当大的数字)。
我们还需要多少个零才能让(LLM) 能够解决像爱丽丝梦游仙境这样的简单推理问题?
幸运的是,大多数研究人员并不天真,并提出了几种方法:
- 数据增强。为了让模型更好地推理,它们需要看到更好的推理数据。因此,人工智能实验室投入了大量资金来构建合成数据集,帮助模型将问题分解为改进推理的步骤,例如OpenAI 的 PRM800k数据集。这种方法的另一个近期成功案例是Cosine 的 Genie 代理,几天前发布了非常令人印象深刻的演示。
- 过度扩展训练:当模型规范其推理电路,将推理过程内化而不是记忆时,真正的压缩就会发生。一种越来越流行的方法是 grokking,我们通过过度扩展训练,让模型有时间找到更简单的问题解决方案。
- 测试时计算:正如在长推理模型部分中提到的,我们允许模型在回答之前搜索解决方案。重要的一点是,我们需要一种方法来在两个可能的解决方案之间做出决定。尽管像谷歌这样的公司已经测试了可计算的比较(测量两个响应的熵并保留最低的一个,即更简单的解决方案),但这里最流行的方法是使用验证器,即批评生成器解决方案的附加模型,以帮助它搜索解决方案空间(这是一个非常复杂的问题)。
总而言之,大多数新模型都会属于这些类别中的一个或多个,并且我们很快就会看到推理能力的提升。
然而,最后一点仍然成立:
这三种方法是否足以让模型克服其训练数据?这些方法是否足以让模型创新,或产生以前从未见过的新解决方案?
不。就这一点而言,我觉得还缺少两点:
- 深度。 正如 Andrej Karpathy 在最近的一条推文中所言,我们仍然没有找到一种深度训练 LLM 的方法,这使得 LLM 无法在任何任务上表现出超人水平。主要问题是,与 Alphazero 等在围棋或国际象棋比赛中达到超人水平的模型不同,由于缺乏一种直接的方法来衡量其行动的质量并从反馈中学习,因此在开放式问题上实现超人能力要困难得多。如今的 LLM 在很多方面都很擅长,但没有一个方面是卓越的。
- 主动推理。我们目前最好的模型只在训练过程中学习,这使得它们完全无法应对不断变化的现实世界。因此,我们需要找到一种机制,让它们能够在预测世界的同时进行学习。
让我们少说废话
不管怎样,有一点是清楚的:人工智能仍有很大的发展空间,而且当前人工智能的能力被大大夸大了。
然而,这些模型的采用率较低(尤其是在企业层面),主要是因为公司和客户对如何使用这些模型的认识不足。
但这不是社会的错,因为大型科技公司及其附属的人工智能实验室正在兜售一种想法和许多承诺,但到了关键时刻,这些承诺就无法实现。
我们仍处于人工智能的起步阶段,接受这一点是在当今人工智能的正确使用场景中最好的方式,即使这意味着它们的市场价值远远高于顶峰。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/4971