
在本周的文章中,我打算探讨在国际机器学习大会 ICML 上发表的论文,该大会目前于 2024 年 7 月 21 日至 27 日在奥地利首都维也纳举行。与其他顶级人工智能会议一样,每年都会有数千篇论文提交,但录取率相对较低(过去三年不到 28%)。例如,今年的会议共提交了 9,653 篇论文,但只有 2,609 篇被接受,录取率为 27.03%。
闲话少说,让我们直接进入新内容吧!本文将分为几个部分,请看下面的目录:
目录:
- 最佳论文奖获得者
- 时间序列
- 大型语言模型和迁移学习
- 计算机视觉和音频
1. 最佳论文奖获奖者
立场:考虑使用大规模公共预训练进行差异化隐私学习(Kamath 等人):
本届获奖论文由滑铁卢大学教授Gautam Kamath 、苏黎世联邦理工学院计算机科学家Florian Tramèr和 Google DeepMind 研究员Nicholas Carlini撰写。它挑战了迄今为止所有已知的大型语言模型训练范式。
为了提供一些背景信息,作者首先观察到,在数百万个数据点上训练的大型语言模型在这些数据包含私人或敏感信息时会构成威胁。到目前为止,推荐的解决方案是在公共数据上训练模型,然后在私人数据上进行微调。
从网络上抓取的预训练数据本身可能很敏感;因为“隐私保护”的微调模型仍然可以记住其预训练数据,这会造成直接伤害并削弱“私人学习”的含义。(引自论文)
然而,作者认为,所谓的公开数据也可能包含有关个人的敏感或私人信息,这有损害机密性的风险。论文表明,这种训练范式可能导致机密性丧失,主要有两个原因:
- 仅基于公共和私人数据分布重叠的参数来高估公共预训练的价值。
- 这些大型模型的训练需要大量的计算能力,而这些计算能力无法在最终用户的机器上执行,从而导致私人数据的外包。
在法学硕士领域出现越来越多的小型模式之际,对当前私人学习实践持批评态度。通过本文,作者呼吁科学界考虑解决这些问题的解决方案。
2.时间序列
你们中的一些人可能知道(或不知道),但时间序列是我最喜欢的主题之一。因此,当论文列表公布时,我首先要看的是与时间序列相关的创新。今年,ICML 上又有很多关于这个主题的论文,我选了一些:
用于时间序列预测的仅解码器基础模型(Das 等):
“对大量时间序列数据进行训练的大型预训练模型能否学习时间模式,从而对以前未见过的数据集的时间序列进行预测?”这是研究人员在本文中试图回答的问题。
近年来,LLM 和基础模型的快速崛起启发了研究人员提出一种零样本时间序列预测的基础模型,称为 TimesFM(时间序列基础模型)。
零样本学习 (ZSL)是一种模型检测训练期间从未见过的类别的能力。条件是监督学习期间不知道这些类别。(零样本学习 | 带代码的论文)
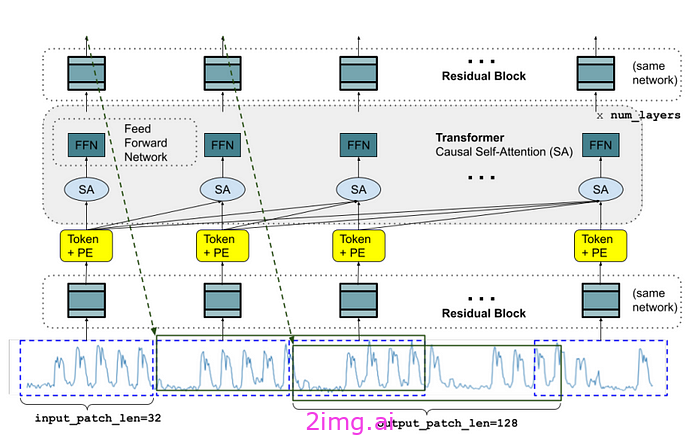
首先,预测模型必须能够适应不同的背景和范围,同时具有足够的容量来编码来自大型数据集的所有模式。为了满足这些期望,TimesFM 的架构基于以下几个原则:
- 修补:补丁类似于语言模型中的标记。
- 仅解码器模型:给定一系列输入补丁,该模型经过优化,可以根据所有过去补丁的函数来预测下一个补丁。
- 更长的输出补丁:更长的输出序列,以避免与预测范围长度的先验知识相关的限制。

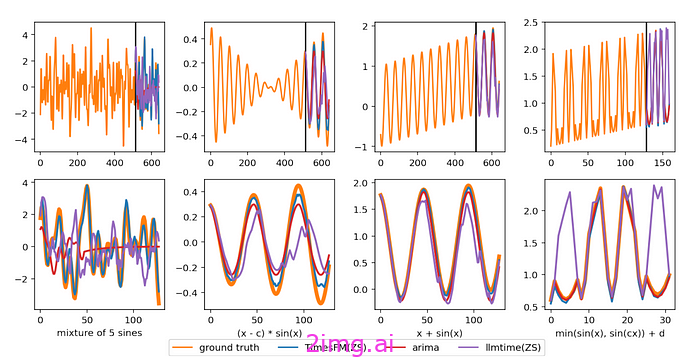
该零样本模型能够达到全监督模型的性能,如以下示例所示:
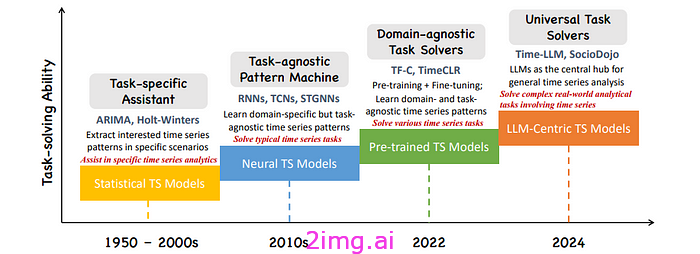
立场:大型语言模型能告诉我们有关时间序列分析的什么信息(Jin,Zhang 等人):
如前所述,法学硕士为这些模型在时间序列数据上的潜在应用打开了大门。在本文中,研究人员强调了法学硕士彻底改变时间序列分析的潜力,并指出其能够“促进有效决策并朝着更通用的时间序列分析智能形式迈进”。
以下是本文的三个主要贡献:
- 为使用 LLM 进行时间序列分析提供了新的视角。
- 对现有方法进行基准测试和审查,并提出将 LLM 集成到时间序列分析中的路线图(见图 3)。
- 发现未来的机会。
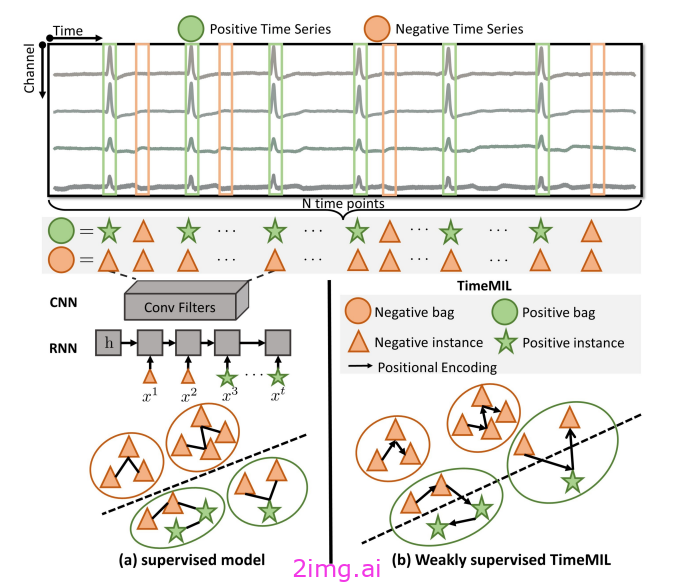
TimeMIL:通过时间感知多实例学习推进多元时间序列分类(Chen, Qiu 等):
借助 Transformer 和卷积网络,多变量时间序列分类得到了极大改进。然而,这些方法通常基于监督学习。监督学习无法捕捉时间序列中的所有模式,也无法捕捉可能发生的罕见事件,因此我们只能从已经看到的内容中学习。
在本文中,研究人员提出了一种称为多实例学习 (MIL) 的新方法,可以更好地捕捉兴趣点并模拟时间序列中的时间依赖性。TimeMIL通过区分时间序列中的正实例和负实例来做出决策,其中每个时间点都是一个在实践中通常没有标签的实例。
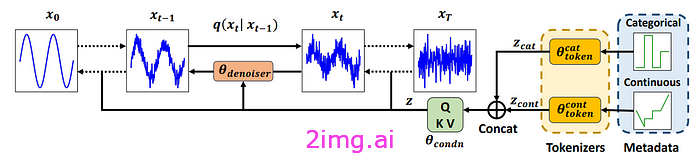
时间编织者:条件时间序列生成模型(Narasimhan 等人):
时间序列生成是一个令人兴奋但又充满挑战的课题。例如,在能源领域,生成相关的时间序列意味着整合天气、位置等元数据,而这在生成模型中并不总是可行的。
在本文中,研究人员提出了一种基于扩散模型的方法,该方法利用分类、连续甚至时间特征形式的元数据来克服上述问题。此外,他们还提出了一种新的评估指标,能够准确捕捉生成的时间序列的真实性。
3.大型语言模型和迁移学习:
趋势肯定是朝着更小的模型发展;比以往任何时候都多的论文几乎都朝着这个方向发展。这包括关于提炼的讨论以及更有效的微调技术:
将知识从大型基础模型转移到小型下游模型(Qiu 等人):
在本文中,AWS AI Lab 的研究人员提出了一种名为自适应特征迁移 (AFT) 的新知识迁移方法。与传统迁移学习中转移权重不同,AFT 直接对特征进行操作,自适应地迁移最有用的特征。这种方法的目标是解决与迁移学习相关的问题,例如:
- 重量转移导致信息传递受限。
- 预训练模型通常很大。
- 无法结合学习互补信息的多个模型。
有关更多详细信息,所有文章的链接均位于参考资料部分。
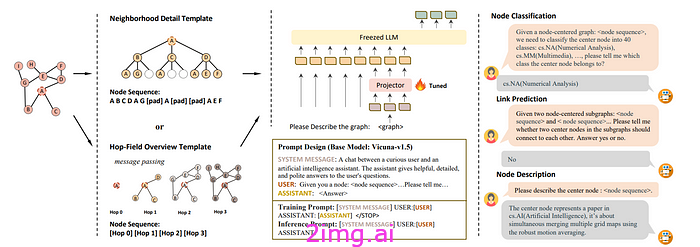
LLaGA:大型语言和图形助手(陈等人):
在 LLaMA 和 LLaVA 进行视觉指导之后,让我介绍一下 LLaGA(在我的文章中找到 LLaxA 似乎已经成为一种传统,不是吗?😜)。
我们再次看到,法学硕士的兴起为深度学习开辟了新途径,图神经网络 (GNN) 也不例外。然而,图结构的复杂性使得用自然语言解释它们变得更加困难。
本文提出了一种名为 LLaGA(大型语言和图形助手)的新模型。该模型能够使用 LLM 处理图形数据。该方法基于将这些图形数据映射到与 LLM 兼容的空间。LLaGA 在各种数据集的泛化和可解释性方面表现出色。
FrameQuant:Transformer 的灵活低位量化(Adepu 等人)
Transformer 非常高效,但仍然占用大量内存。因此,最近引入了多种方法来创建较小的模型,包括量化为 8 位或 4 位。
量化是一种通过使用低精度数据类型(如 8 位整数 (
int8) 而不是通常的 32 位浮点数 (float32))来表示权重和激活,从而降低运行推理的计算和内存成本的技术。量化 (huggingface.co)
在本文中,作者建议进一步采用 2 位量化,同时将性能损失降至最低。该方法基于一种称为“融合帧”的谐波分析。他们表明,关键在于量化的应用位置,不应在原始权重空间中进行,而应在融合帧的表示中进行。
DISTILLM:面向大型语言模型的精简提炼(Ko 等人):
模型蒸馏是指使用较大的模型(称为教师模型)来创建较小的模型(称为学生模型),目的是在保持性能的同时降低成本和内存。这种方法对某些模型很有效,但对 LLM 却不太适用。本文建议将蒸馏应用于 LLM,并介绍 DistiLLM。
本文的主要贡献是:
- 倾斜 KLD(Kullback-Leibler 散度):一种新的目标函数,针对稳定的梯度和最小的近似误差进行了优化。
- 自适应离线策略方法:减少训练时间。
- 先进的性能和效率: DistiLLM 与最先进的性能相媲美。
4.计算机视觉和音频:
Vision Mamba:通过双向状态空间模式实现高效的视觉表征学习(Zhu、Liao 等人):
谈论 Vision Mamba 而不提及Mamba(原始架构)有点离题。简而言之,Mamba 是一种新架构,效率极高,尤其是在处理长序列时(Mistral的最新型号之一基于此架构)。
附言:我将在未来几天发布一篇有关该主题的文章,敬请关注!
Mamba 是一种新的状态空间模型架构,在语言建模等信息密集型数据上表现出色,而之前的次二次模型则不如 Transformers。它基于结构化状态空间模型的进展路线,具有高效的硬件感知设计和实现,秉承了FlashAttention的精神。(摘自GitHub — state-spaces/mamba:Mamba SSM 架构)
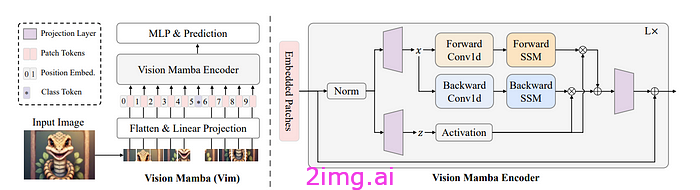
因此,回到 Vision Mamba (Vim),它利用 Mamba 架构使其适应视觉数据。与 Vision Transformers 相比,Vim 在 ImageNet 分类任务、COCO 对象检测和分割方面实现了卓越的性能,同时速度提高了 2.8 倍并节省了 86.8% 的 GPU 内存(这真是太棒了 👊)。
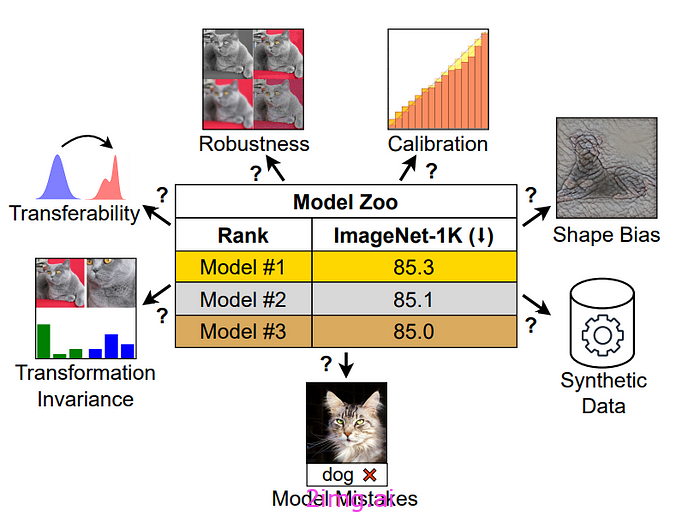
ConvNet 与 Transformer、Supervised 与 CLIP:超越 ImageNet 准确率( Vishniakov 等人):
Meta AI 的这篇论文提出,通过考虑其他参数来捕捉所有可能的细微差别,从而超越计算机视觉任务的准确性。事实上,研究人员认为,尽管 Vision Transformers、ConvNet 架构和 CLIP 之间的性能相似,但许多其他不同方面可能会有所不同。其中包括:错误类型、输出校准、可转移性和特征不变性等。
下图显示了我们在衡量视觉模型性能时可以考虑的参数。
UniAudio:面向大型语言模型的通用音频生成(Yang,Tian 等):
正如我们近几个月所看到的,音频与法学硕士 (LLM) 的融合是一个快速发展的领域,现在越来越多的对话模型能够进行口头讨论(尤其是Kyutai的 Moshi )。
在本文中,研究人员介绍了 UniAudio,这是一个利用 LLM 技术生成各种类型音频的模型,包括声音、语音、音乐和歌唱。该模型经过 165,000 小时音频的训练,拥有 10 亿个参数。
以下是 UniAudio 工作原理的简要概述:
- 首先,它将所有类型的目标音频与其他条件模式一起标记化。
- 然后,它将源-目标对连接为一个序列。
- 最后,它使用 LLM 执行下一个标记预测。
参考
- 最佳论文奖获得者
职位:考虑使用大规模公共预训练进行差异化隐私学习 (mlr.press)
- 时间序列
[2310.10688] 用于时间序列预测的仅解码器基础模型 (arxiv.org)
[2402.02713] 立场:大型语言模型能告诉我们有关时间序列分析的什么信息 (arxiv.org)
[2405.03140] TimeMIL:通过时间感知多实例学习推进多元时间序列分类 (arxiv.org)
[2403.02682] 时间编织者:条件时间序列生成模型 (arxiv.org)
- 大型语言模型和迁移学习
[2406.07337] 将知识从大型基础模型转移到小型下游模型 (arxiv.org)
FrameQuant:Transformer 的灵活低位量化(mlr.press)
DistiLLM:面向大型语言模型的精简提炼(mlr.press)
- 计算机视觉和音频
Vision Mamba:通过双向状态空间模型实现高效的视觉表征学习 (mlr.press)
ConvNet 与 Transformer、Supervised 与 CLIP:超越 ImageNet 准确度 (mlr.press)
UniAudio:利用大型语言模型实现通用音频生成 (mlr.press)
RA/SD 衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/4941