
“教学的艺术就是协助发现的艺术。” ——马克·范多伦
大型语言模型 (LLM)展现了卓越的技能,目前已被数百万人使用。另一方面,它们也显示出局限性,并已显示出惊人的失败。事实上,即使在今天,LLM 仍受到幻觉、有害内容以及难以遵循规则和说明的困扰。
这个问题已经尝试通过使用人类反馈强化学习 (RLHF)或其他对齐技术来解决。这些技术可以让模型充分利用其能力,而不会产生有害行为。简而言之,模型通过一系列反馈(或通过监督微调)从一系列示例中学习,了解如果它是人类,它应该如何反应。

变形金刚安魂曲?
Transformer 会成为引领我们走向通用人工智能的模型吗?还是会被取代?
这些示例的实现成本很高,而且取决于生成这些示例的人的技能。这意味着进行对齐需要大量的资金和专业知识。
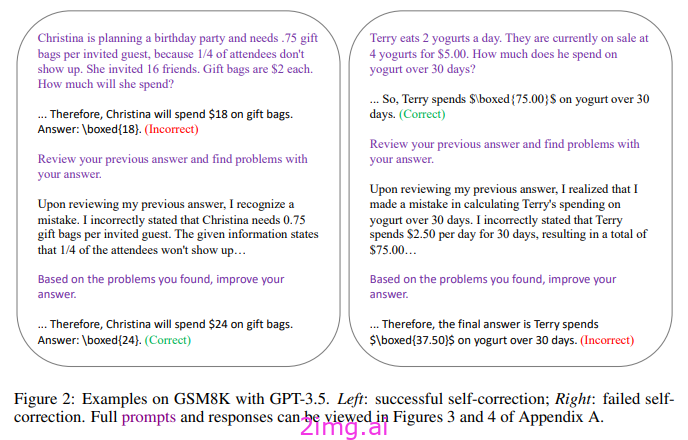
如果这些法学硕士这么有能力,为什么他们不改正自己呢?
这个话题之所以有争议,是因为人们怀疑模型是否能够自我修正。最近的一篇文章问道:“如果法学硕士具有自我修正的能力,为什么它不直接在第一次尝试时给出正确答案呢? ”
矛盾的是,他们指出,有时试图自我纠正,模型性能可能会下降。此外,自我纠正需要对模型进行多次推理调用,因此仍然需要考虑到成本。其次,它还需要对初始查询和后续纠正进行一些及时设计(因此效率不高)。最后,对于复杂的问题,即使是长链反射也可能无法达到收敛或正确答案。
那么,我们不能没有人类的反馈吗?模型可以自我修正吗?或者找到一种让模型可以自我学习的方法?或者至少得到另一个简单模型的帮助?
在本文中,我们探讨了最近发布的两种方法:
- 一种无需人工反馈、外部工具和手工提示即可简化自我纠正过程的方法。
- 一种方法,其中具有有限功能的模型可以有效地指导更先进、更强大的模型的开发。
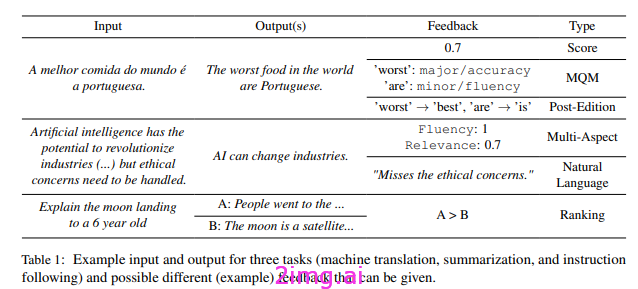
从正确性中学习 (LECO) 是一种最近发布的方法,其灵感来自于这样的想法:法学硕士应该从自己做对的事情中学习,而不是因为自己的错误而受到惩罚。
虽然从错误中学习的洞察力来自于人类学生的学习过程,但我们方法背后的动机来自于渐进式学习,其中正确的推理步骤逐渐积累,最终接近正确答案。——来源
这个过程非常简单,向 LLM 提出一个需要推理的问题,并要求他分步推理。模型开始推理链,并为每个步骤分配一个置信度分数。置信度分数最低的步骤将被确定为最早的潜在错误步骤(如果模型不确定该步骤,则可能是因为它不正确)。此时推理链停止,分数最低的步骤被丢弃,其他步骤被视为正确(丢弃步骤之前的那些步骤)。这些步骤被附加到初始输入并返回到模型,然后重复该过程。
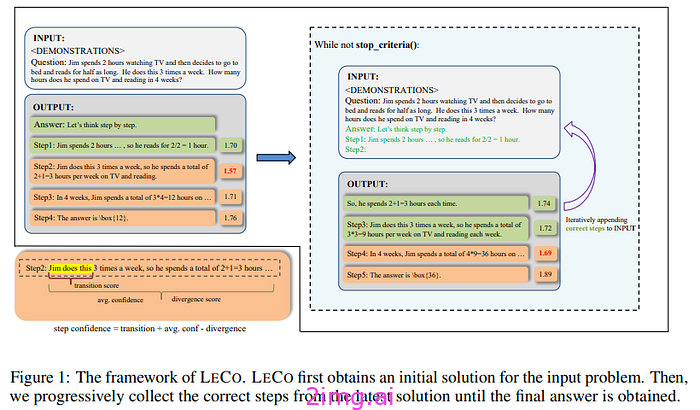
在这种情况下,没有外部工具或基于 token 生成的过度消耗。系统利用了 logits(与生成的文本序列中下一个单词的候选 token 相关的概率)。这里的置信度是指模型对其预测的确定性,因此可以从 logits 中获得。对于作者来说,可以通过以下方式获得置信度分数:
- 平均标记分数。只是对给定步骤的标记概率进行平均。
- 步骤发散分数。平均值可能会产生误导,因为具有较高概率的标记是常用词,但对推理来说信息量很少。这就是为什么您可以在一个步骤内测量标记概率的分布均匀性。换句话说,模型有信心的步骤将产生一个概率分布,该概率分布在所有标记中既高又均匀分布(因此即使对于较少见但通常对推理更重要的词,也具有较高的置信度)。您采用此分布并使用来自均匀分布的Kullback-Leibler 散度。
- 步骤间转换分数。我们关注的不是某个步骤,而是步骤之间的转换。毕竟,我们希望找到置信度分数最低的步骤并保留之前的步骤,因此我们自然会寻找模型有信心的最后一步与可能出现错误的步骤之间的转换。因此,您可以使用方向标记的概率来确定此转换的位置。
作者使用了所有三个分数(最终分数是这三个分数的总和)。
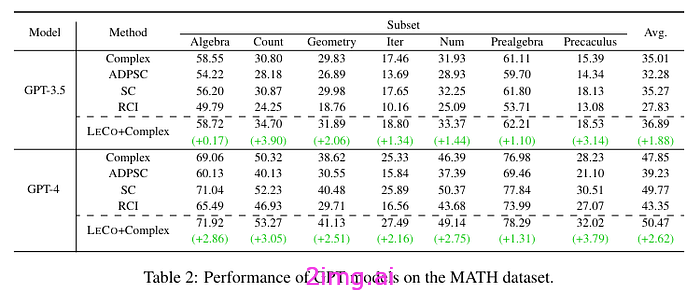
在这项工作中,作者除了提示之外,还从包含更高推理复杂度的思路链 (CoT) 的数据集进行了公开演示,以提高语言模型的多步推理能力(来自复杂 CoT 数据集)。然后,他们在基准推理数据集 ( GSM8K、MATH、SVAMP)上与提示技术(例如思路链、自洽、自适应自洽和 RCI)进行了比较。
您需要了解的有关情境学习的所有信息
大型语言模型是什么?它是如何工作的?是什么让大型语言模型如此强大
结果表明,他们的方法 (LECO) 持续提高了推理性能。特别是在像 MATH 这样通常需要几个推理步骤的复杂数据集上(简单的 CoT 通常会在此数据集上显示局限性):
然而,LECO 通过逐步收集正确的步骤有效地解决了这种复杂性,从而减少了推理困惑并实现了实质性的改进。我们还发现,使用 LECO 时,高质量的演示更受欢迎,因为使用 LECO+Complex 可以持续观察到更大的改进。——来源
然而,如果该技术需要特定的知识来解决任务,这种方法的效果就会差一些。换句话说,它提高了他的推理能力,但显然不会影响特定于模型的知识。
你什么都不知道,ChatGPT。你的法学硕士知道多少?
知识就是力量,但是法学硕士能知道多少?知道多少就够了吗?
一个有趣的结果是,与其他方法相比,该模型更能纠正其响应。但总体而言,这并不是一个非常明显的效果。它之所以重要,是因为它与之前的研究一致,即该模型无法仅凭自己的反馈进行纠正(RCI 作为一种方法使用自己的反馈,LLM 识别错误,然后使用设计的提示进行自我纠正)
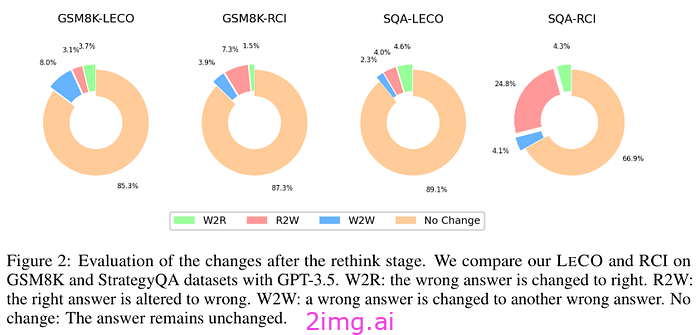
模型无法通过自身的反馈进行自我纠正,如果我们使用来自另一个模型的反馈会怎样?
如果我们采用一个弱模型并使用一个更强的模型,较弱的模型可以学习较强模型的一些技能。这个过程称为知识蒸馏。我们可以说,这与我们使用人类反馈时一样,模型向我们学习。事实上,如果模型可以向较弱的学习者学习,那将是最佳的。换句话说,如果我们可以使用较弱的模型来联合较强的模型。
然而,超人模型将能够做出人类无法完全理解的复杂且富有创造性的行为。例如,如果超人助手模型生成了一百万行极其复杂的代码,人类将无法为关键的对齐相关任务提供可靠的监督,包括:代码是否遵循用户的意图,助手模型是否诚实地回答有关代码的问题,代码执行起来是否安全或危险,等等。——来源

尤其是在未来,模型需要具备从其他(甚至更弱的)模型中学习的能力。这是因为在某些时候,人类可能不再能够纠正具有更强推理能力的模型中的错误。
这不是一个简单的问题,因为强模型可能只是模仿弱模型(性能下降)。我们的目标不是让弱学习者教给强模型一些东西,而是需要弱监督者引出强模型已经知道的东西。简而言之,一个好老师不应该教一个优秀的学习者,而应该帮助他充分发挥自己的潜力。
对于分类或国际象棋等一些任务来说,这已经成为可能。毕竟,今天我们无法教神经模型下国际象棋;让模型与其他模型一起下棋效率更高。
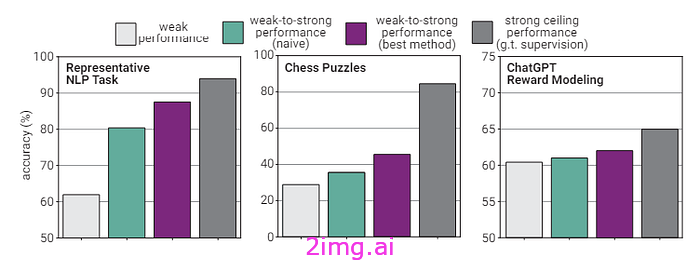
但这是否可以用于提高模型的推理能力仍然是一个悬而未决的问题。
在这项研究中,作者提出了一种渐进式细化学习框架,根据该框架,提高模型能力的方法是专注于初始数据子集,然后迭代地扩大其学习范围。因此,从简单的事情开始,然后使研究复杂化。
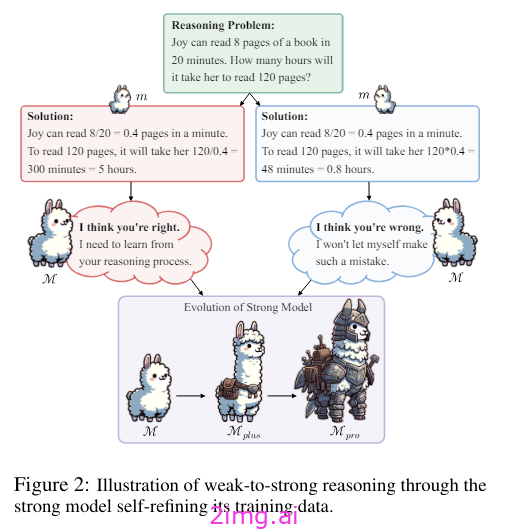
这个想法是从少量可能准确的数据开始的。作者使用弱学习器(参数较少的模型)和利用上下文学习的更高级模型生成的其他数据来生成这些数据。他们使用这些数据对模型进行微调,以获得具有更强推理能力的模型。然后,您可以使用此模型创建对比样本以进行偏好优化,因此在第二步中,模型会从较弱模型的错误中学习。
在第一步中,作者使用弱模型(LLaMA 7B或其他类似模型)生成推理链 c 来回答推理问题 q。答案可能不正确(目的是在没有基本事实的情况下工作)。该数据集用于对强模型进行微调(选择了一些随机示例)。该数据集由强模型生成的推理示例补充(同样,我们不知道答案 a 是否正确,但强模型应该比弱模型更强大)。为了完善数据集,我们选择两个模型答案一致的那些示例(理论上是两个不同的模型,如果它们得出一个共同的答案,那么它可能是正确的)。此时我们进行微调(可以使用使用此数据集微调的模型重复此过程,现在可以为新一轮的微调生成更多数据)。
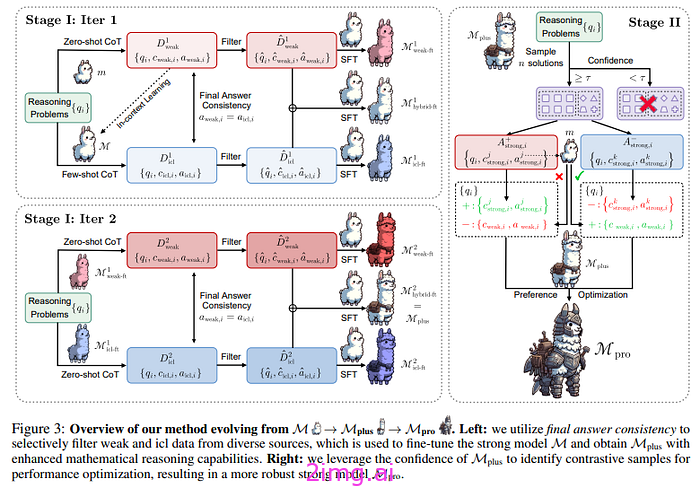
现在,我们需要创建正例和反例,以便进行第二步。同样,我们希望找到一种自动创建正例和反例的方法。
在无法获得基本事实的情况下,当前具有增强推理能力的强模型会根据其置信度确定最有可能的正确答案。——来源
我们利用模型的置信度,高于某个阈值,我们认为该模型能够解决问题,低于该阈值,则该模型不可靠。然后,我们使用强模型和弱模型来创建正例和反例

经过这一过程后,强大的模型表现出了改进的能力,如果只对正确答案进行微调,其能力会得到进一步提高。对于作者来说,这意味着模型可以更好地从错误中学习。
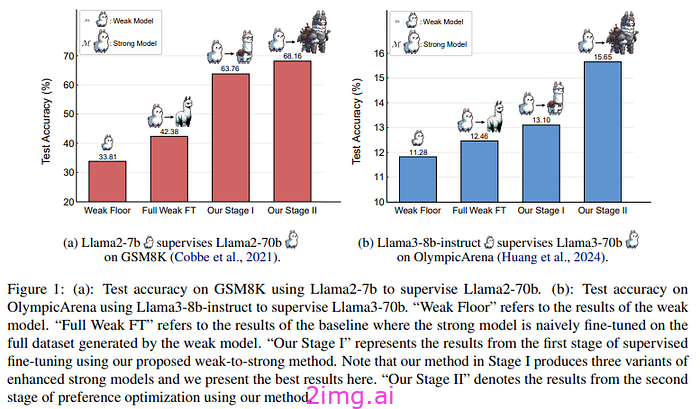
我们刚刚介绍的这些方法旨在尽量减少推理任务中的人工输入。在第一种情况下,我们利用模型对回答问题的信心。任何优秀的学习者都知道,如果他不确定答案,他的答案很可能是错误的。无论如何,这并不意味着模型可以自我修正(鉴于模型的自回归性质,这个过程很复杂)。
聊天堂吉诃德与风车:在通往准确性的道路上驾驭人工智能幻觉
提高大型语言模型可靠性的策略和工具
另一种方法则利用了模型可以从错误中学习而不是仅仅从正确答案中学习的想法。在这种情况下,弱模型是一位老师,帮助天才学生充分发挥自己的能力。
基本上,这两种方法都无法提高推理能力。模型并没有变得更具表现力,只是错误减少了,模型更好地运用了它们的技能。
驾驭理性海洋:提升法学硕士推理能力的几何奥德赛
探索大型语言模型中自注意力图和内在维度的深度
无论如何,这两种方法特别有趣,因为它们不使用基本事实。考虑到这些数据集的注释成本很高,而且需要经验丰富的人员,这是一个很大的优势。此外,从弱到强的学习理念理论上可以让模型自我改进。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/4848